Руководство «Быстрый старт по StarRocks Lakehouse» помогает быстро разобраться с технологиями Lakehouse (лейкхаус): ключевые особенности, уникальные преимущества, сценарии использования и то, как со StarRocks оперативно собрать решение. В финале — лучшие практики на основе реальных сценариев.
В этой статье представлены лучшие практики StarRocks Hive Catalog на примере прикладной задачи управления заказами.
Введение в Apache Hive
Apache Hive — распределённая, отказоустойчивая система хранилища данных, поддерживающая масштабную аналитику. Hive Metastore (HMS) предоставляет репозиторий метаданных, которые можно анализировать для принятия решений на основе данных; потому HMS — ключевой компонент во многих архитектурах озёр данных.
Hive построен поверх Apache Hadoop и через HDFS поддерживает управление данными в хранилищах S3, Azure Data Lake Storage (ADLS), Google Cloud Storage (GCS) и др. Hive позволяет с помощью SQL читать, записывать и управлять данными объёмов до петабайт.
Архитектура и ключевые особенности
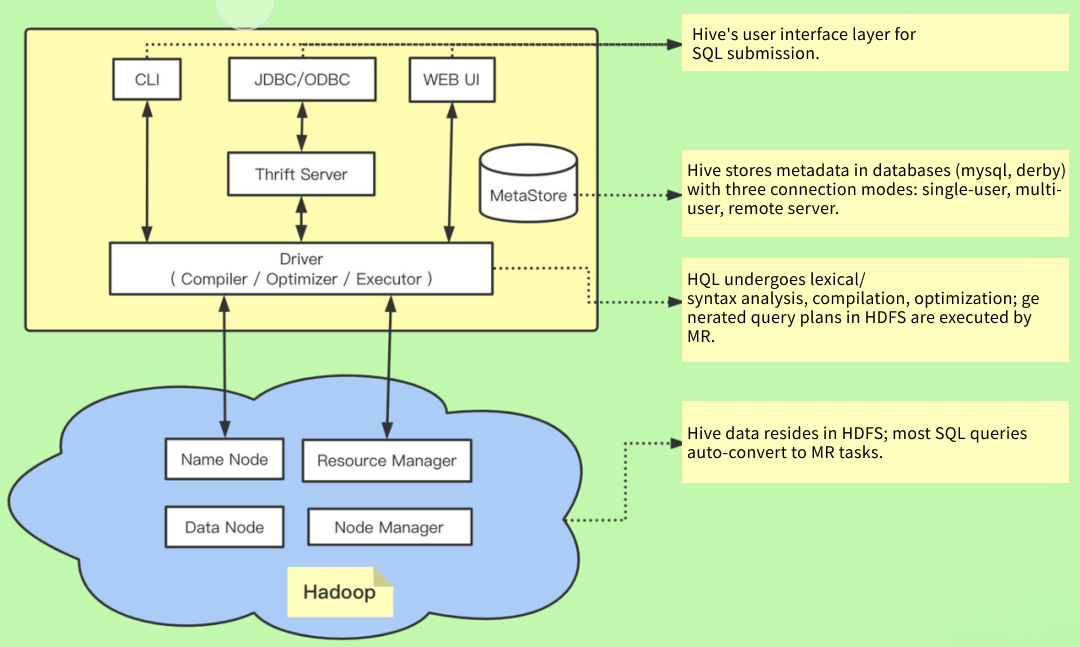
HiveServer2 (HS2): поддержка параллельной работы множества клиентов и аутентификации; улучшенная поддержка JDBC и ODBC.
Hive Metastore Server (HMS): хранение метаданных таблиц и партиций; поддержка множества OSS‑инструментов (Spark, Presto и др.); важная часть озера данных.
Hive ACID: полная поддержка ACID для таблиц ORC; поддержка только вставок для других форматов.
Hive Iceberg: нативная поддержка таблиц Apache Iceberg через Hive StorageHandler; подходит для облачных высокопроизводительных сценариев.
Безопасность и наблюдаемость: поддержка Kerberos, интеграция с Apache Ranger и Apache Atlas.
Hive LLAP: интерактивные SQL‑запросы с низкой задержкой; оптимизация кэширования и ускорение запросов.
Оптимизация запросов: оптимизатор на основе стоимости (CBO) на базе Apache Calcite.
Преимущества Apache Hive
Функции DWH: базы данных, таблицы, партиции и др. упрощают управление и запросы.
Несколько движков выполнения: MapReduce, Tez, Spark — можно выбирать для нужной производительности.
Расширяемость: пользовательские функции (UDF), интеграция с инструментами экосистемы Hadoop — гибкость обработки.
Пакетная обработка: особенно подходит для крупномасштабной аналитики, отчётности и ETL.
Простая интеграция: Flume, Sqoop, Oozie и др. — расширение возможностей обработки больших данных.
Сценарии использования Apache Hive
Хранилище данных: преобразует данные Hadoop в SQL‑представление, предоставляя функции DWH.
Аналитика данных: HiveQL‑запросы, агрегирование и фильтрация для масштабной аналитики.
Интеллектуальный анализ данных (data mining): интеграция с ML‑инструментами для добычи знаний и поиска паттернов.
ETL‑операции: анализ логов и обработка исторических данных для оптимизации производительности и понимания поведения пользователей.
Офлайн‑обработка: подходит для офлайн‑сценариев обработки больших данных; пакетные движки поддерживают крупные задания.
Интеграция инструментов: бесшовная работа с Apache Spark, Mahout и др. для ускорения запросов и моделирования данных.
StarRocks Hive Catalog
Hive — классический движок на базе MapReduce, широко применяемый для пакетной и офлайн‑аналитики. В задачах аналитики в реальном времени ему часто не хватает производительности запросов и эффективности использования ресурсов.
StarRocks — это MPP‑СУБД, которая быстро обрабатывает сложные запросы на больших наборах данных, поддерживает аналитику в реальном времени и обеспечивает быстрый отклик — для сценариев, где важна мгновенная обратная связь.
StarRocks не только эффективно анализирует локально хранимые данные, но и выступает вычислительным движком для прямого анализа данных в озере (data lake). С помощью External Catalog пользователи могут без миграции данных запрашивать данные из Apache Hive, Apache Iceberg, Apache Hudi, Delta Lake и др. Поддерживаемые системы хранения: HDFS, S3, OSS; форматы — Parquet, ORC, CSV.
Благодаря StarRocks Hive Catalog достигается бесшовная интеграция StarRocks и Hive, объединяющая их сильные стороны. В аналитике по озеру данных StarRocks отвечает за вычисления и анализ, а озеро — за хранение, организацию и поддержку данных. Преимущества озера — открытые форматы хранения и гибкая схема (schema), что обеспечивает для BI/AI/ad‑hoc/отчётности единый источник истины (single source of truth). В роли вычислительного движка для озера StarRocks задействует векторизованный движок и CBO, существенно ускоряя аналитику.
Модель данных

Эволюция технической архитектуры
StarRocks Hive Catalog может эволюционировать так:
Прямые запросы к данным таблиц Hive →
Ускорение запросов к таблицам Hive с помощью Data Cache →
Ускорение с помощью Data Cache и асинхронных материализованных представлений.
Прямые запросы к результатам через StarRocks Hive Catalog: весь ETL выполняется в Hive; StarRocks через Hive Catalog запрашивает витрины DWD, DWS и ADS.
Запросы «на лету» с использованием StarRocks Hive Catalog + Data Cache: в Hive формируются только ODS и DWD; уровни DWS и ADS считаются на лету (on the fly) через Hive Catalog StarRocks.
Ускорение асинхронными материализованными представлениями: в Hive остаётся лишь ODS; уровни DWD и DWS строятся асинхронными MVs StarRocks; ADS запрашивается напрямую.

Быстрый старт
1. Базовая среда
Component | Version |
Zookeeper | 3.5.7 |
HDFS | 3.3.4 |
Hive | 3.1.2 |
StarRocks | 3.3.0 |
Node | Deployed Services | Machine Specifications |
StarRocks-BE | 8C32G 2T High-performance Cloud Disk | |
Zookeeper | ||
DataNode | ||
JournalNode | ||
NameNode | ||
StarRocks-FE | 8C64G 2T High-performance Cloud Disk | |
StarRocks-BE | ||
Zookeeper | ||
DataNode | ||
JournalNode | ||
NameNode | ||
HiveServer | ||
HiveMetaStore | ||
StarRocks-BE | 8C64G 1T High-performance Cloud Disk | |
Zookeeper | ||
DataNode | ||
JournalNode | ||
NameNode |
2. Создание таблиц в Hive
CREATE DATABASE orders; -- ODS: вспомогательная внешняя таблица для загрузки локально сгенерированных тестовых данных CREATE EXTERNAL TABLE IF NOT EXISTS ods_orders_text ( order_id STRING, user_id STRING, order_time STRING, product_id STRING, quantity INT, price DECIMAL(10, 2), order_status STRING ) COMMENT 'Таблица хранения операционных данных заказов' ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; CREATE TABLE IF NOT EXISTS ods_orders ( order_id INT, user_id INT, order_time STRING, product_id INT, quantity INT, price DOUBLE, order_status STRING ) COMMENT 'Таблица хранения операционных данных заказов' PARTITIONED BY (order_date STRING) STORED AS PARQUET; CREATE TABLE IF NOT EXISTS dim_products ( product_id INT, product_name STRING, category_id INT, price DECIMAL(10, 2), product_description STRING ) COMMENT 'Таблица измерений продуктов' STORED AS PARQUET; CREATE TABLE IF NOT EXISTS dim_categories ( category_id INT, category_name STRING, category_description STRING ) COMMENT 'Таблица измерений категорий' STORED AS PARQUET; -- DWD CREATE TABLE IF NOT EXISTS dwd_order_facts ( order_id STRING, user_id STRING, order_time STRING, product_id STRING, quantity INT, price DECIMAL(10, 2), order_status STRING, product_name STRING, category_id STRING, category_name STRING ) COMMENT 'Фактовая таблица заказов' PARTITIONED BY (order_date DATE) STORED AS PARQUET;
3. Генерация данных
3.1 Таблицы измерений
-- Вспомогательная таблица для генерации последовательности CREATE TABLE aux_order_data (seq_num INT);
#!/usr/bin/env python3 with open('aux_order_data.txt', 'w') as f: for i in range(1, 10000001): f.write("{}\n".format(i))
LOAD DATA LOCAL INPATH '/home/disk1/sr/aux_order_data.txt' INTO TABLE aux_order_data; INSERT INTO dim_products SELECT floor(RAND() * 10000) + 1 AS product_id, CONCAT('Название продукта', floor(RAND() * 10000) + 1) AS product_name, floor(RAND() * 1000) + 1 AS category_id, ROUND(100 + RAND() * 5000, 2) AS price, CONCAT('Описание продукта', floor(RAND() * 100)) AS product_description FROM aux_order_data a CROSS JOIN aux_order_data b LIMIT 10000; INSERT INTO dim_categories SELECT floor(RAND() * 1000) + 1 AS category_id, CONCAT('Название категории', floor(RAND() * 1000) + 1) AS category_name, CONCAT('Описание категории', floor(RAND() * 100)) AS category_description FROM aux_order_data a CROSS JOIN aux_order_data b LIMIT 1000;
3.2 Данные ODS
Отдельно формируем данные за 3–5 августа 2024 года.
#!/usr/bin/env python3 import random import time def generate_order_data(num_records): with open('ods_orders.txt', 'w') as f: for i in range(1, num_records + 1): order_id = i user_id = random.randint(1, 1000) # временные метки охватывают 3–5 августа order_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(random.randint(1722614400, 1722700800))) product_id = random.randint(1, 10000) quantity = random.randint(1, 10) price = round(random.uniform(10, 1000), 2) order_status = '已完成' if random.random() < 0.9 else '已取消' f.write(f"{order_id},{user_id},{order_time},{product_id},{quantity},{price},{order_status}\n") generate_order_data(10000000)
LOAD DATA LOCAL INPATH '/home/disk1/sr/ods_orders.txt' INTO TABLE ods_orders_text; INSERT OVERWRITE TABLE ods_orders PARTITION (order_date) SELECT CAST(order_id AS INT), CAST(user_id AS INT), order_time, CAST(product_id AS INT), CAST(quantity AS INT), CAST(price AS DOUBLE), order_status, substr(order_time, 1, 10) AS order_date FROM ods_orders_text;
3.3 Данные DWD
INSERT OVERWRITE TABLE dwd_order_facts PARTITION (order_date) SELECT o.order_id, o.user_id, o.order_time, o.product_id, o.quantity, o.price, COALESCE(o.order_status, 'UNKNOWN'), p.product_name, p.category_id, c.category_name, o.order_date FROM ods_orders o JOIN dim_products p ON o.product_id = p.product_id JOIN dim_categories c ON p.category_id = c.category_id WHERE o.price > 0;
3.4 Данные DWS
CREATE TABLE IF NOT EXISTS dws_order_aggregates ( user_id STRING, category_name STRING, order_date DATE, total_quantity INT, total_revenue DECIMAL(10, 2), total_orders INT ) COMMENT 'Агрегированная витрина заказов' STORED AS PARQUET; INSERT OVERWRITE TABLE dws_order_aggregates SELECT user_id, category_name, order_date, SUM(quantity) AS total_quantity, SUM(price * quantity) AS total_revenue, COUNT(DISTINCT order_id) AS total_orders FROM dwd_order_facts WHERE order_status = '已完成' GROUP BY user_id, category_name, order_date;
3.5 Данные ADS
CREATE TABLE IF NOT EXISTS ads_product_order_report ( category_name STRING, report_date STRING, total_orders INT, total_quantity INT, total_revenue DECIMAL(10, 2) ) COMMENT 'Таблица отчёта по топ‑товарам' STORED AS PARQUET; WITH ranked_category_sales AS ( SELECT category_name, order_date, total_quantity, total_revenue, total_orders, ROW_NUMBER() OVER (PARTITION BY order_date ORDER BY total_revenue DESC) AS revenue_rank FROM dws_order_aggregates ) INSERT OVERWRITE TABLE ads_product_order_report SELECT category_name, order_date, total_quantity, total_revenue, total_orders FROM ranked_category_sales WHERE revenue_rank <= 10;
4. Подключение Hive Catalog
Скопируйте конфигурацию Hive/Hadoop и перезапустите службы StarRocks:
scp hive-site.xml hdfs-site.xml core-site.xml sr@node:/home/disk1/sr/fe/conf scp hdfs-site.xml core-site.xml sr@node:/home/disk1/sr/be/conf ./bin/stop_be.sh ./bin/start_be.sh --daemon ./bin/stop_fe.sh ./bin/start_fe.sh --daemon
5. Аналитика по озеру данных
5.1 Запрос результатов Hive через Hive Catalog
CREATE EXTERNAL CATALOG `hive_catalog_krb5_sr` PROPERTIES ( "hive.metastore.type" = "hive", "hive.metastore.uris" = "thrift://cs02.starrocks.com:9083", "type" = "hive" ); SET CATALOG hive_catalog_krb5_sr; USE orders; -- DWS SELECT * FROM dws_order_aggregates; -- ADS SELECT * FROM ads_product_order_report;
5.2 Запросы «на лету» с использованием StarRocks Hive Catalog + Data Cache
Включите Data Cache и при необходимости выполните предзагрузку кэша.
-- включить Data Cache на уровне сессии SET enable_scan_datacache = true;
В конфигурации BE (be.conf):
datacache_disk_path = /data2/datacache datacache_enable = true datacache_disk_size = 200G
Предзагрузка кэша:
CACHE SELECT * FROM hive_catalog_krb5_sr.orders.dwd_order_facts;
Онлайновые витрины:
SET CATALOG hive_catalog_krb5_sr; USE orders; -- DWS WITH dwd AS ( SELECT user_id, category_name, order_date, quantity, price, order_id, order_status FROM dwd_order_facts ) SELECT user_id, category_name, order_date, SUM(quantity) AS total_quantity, SUM(price * quantity) AS total_revenue, COUNT(DISTINCT order_id) AS total_orders FROM dwd WHERE order_status = '已完成' GROUP BY user_id, category_name, order_date; -- ADS WITH dws_order_aggregates AS ( SELECT user_id, category_name, order_date, SUM(quantity) AS total_quantity, SUM(price * quantity) AS total_revenue, COUNT(DISTINCT order_id) AS total_orders FROM dwd_order_facts WHERE order_status = '已完成' GROUP BY user_id, category_name, order_date ), ranked_category_sales AS ( SELECT category_name, order_date, total_quantity, total_revenue, total_orders, ROW_NUMBER() OVER (PARTITION BY order_date ORDER BY total_revenue DESC) AS revenue_rank FROM dws_order_aggregates ) SELECT category_name, order_date, total_quantity, total_revenue, total_orders FROM ranked_category_sales WHERE revenue_rank <= 10;
5.3 Ускорение за счёт асинхронных материализованных представлений
SET CATALOG default_catalog; USE orders; CREATE MATERIALIZED VIEW dwd_order_facts_mv PARTITION BY str2date(order_date, '%Y-%m-%d') DISTRIBUTED BY HASH(`order_id`) BUCKETS 12 PROPERTIES ("replication_num" = "3") REFRESH ASYNC START('2024-08-01 01:00:00') EVERY (interval 1 day) AS SELECT o.order_date, o.order_id, o.user_id, o.order_time, o.product_id, o.quantity, o.price, COALESCE(o.order_status, 'UNKNOWN') AS order_status, p.product_name, p.category_id, c.category_name FROM hive_catalog_krb5_sr.orders.ods_orders o JOIN hive_catalog_krb5_sr.orders.dim_products p ON o.product_id = p.product_id JOIN hive_catalog_krb5_sr.orders.dim_categories c ON p.category_id = c.category_id WHERE o.price > 0;
Автоматическое обнаружение новых партиций (пример с 6 августа):
#!/usr/bin/env python3 import random import time def generate_order_data(num_records): with open('ods_orders_0806.txt', 'w') as f: for i in range(1, num_records + 1): order_id = i user_id = random.randint(1, 1000) order_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(random.randint(1722873600, 1722959999))) product_id = random.randint(1, 10000) quantity = random.randint(1, 10) price = round(random.uniform(10, 1000), 2) order_status = '已完成' if random.random() < 0.9 else '已取消' f.write(f"{order_id},{user_id},{order_time},{product_id},{quantity},{price},{order_status}\n") generate_order_data(10000000)
На стороне Hive:
LOAD DATA LOCAL INPATH '/home/disk1/sr/ods_orders_0806.txt' INTO TABLE ods_orders_text; -- Добавляем новые данные с автоматическим формированием значения партиции INSERT OVERWRITE TABLE ods_orders PARTITION (order_date) SELECT CAST(order_id AS INT), CAST(user_id AS INT), order_time, CAST(product_id AS INT), CAST(quantity AS INT), CAST(price AS DOUBLE), order_status, substr(order_time, 1, 10) AS order_date FROM ods_orders_text WHERE substr(order_time, 1, 10) = '2024-08-06';
Обновление и проверка MV:
-- ручной запуск обновления REFRESH MATERIALIZED VIEW dwd_order_facts_mv; -- проверяем статус обновления (должен быть SUCCESS) SELECT * FROM information_schema.task_runs ORDER BY CREATE_TIME DESC LIMIT 1; -- проверяем, что MV видит новые данные SELECT order_date, COUNT(1) FROM dwd_order_facts_mv GROUP BY order_date;
DWS на основе MV:
SET CATALOG default_catalog; USE orders; SELECT user_id, category_name, order_date, SUM(quantity) AS total_quantity, SUM(price * quantity) AS total_revenue, COUNT(DISTINCT order_id) AS total_orders FROM dwd_order_facts_mv WHERE order_status = '已完成' GROUP BY user_id, category_name, order_date;
ADS на основе MV:
SET CATALOG default_catalog; USE orders; CREATE MATERIALIZED VIEW dws_order_aggregates_mv PARTITION BY str2date(order_date, '%Y-%m-%d') DISTRIBUTED BY HASH(`user_id`) BUCKETS 12 PROPERTIES ("replication_num" = "3") REFRESH ASYNC START('2024-08-01 04:00:00') EVERY (interval 1 day) AS SELECT user_id, category_name, order_date, SUM(quantity) AS total_quantity, SUM(price * quantity) AS total_revenue, COUNT(DISTINCT order_id) AS total_orders FROM dwd_order_facts_mv WHERE order_status = '已完成' GROUP BY user_id, category_name, order_date; -- ручной запуск обновления REFRESH MATERIALIZED VIEW dws_order_aggregates_mv; -- проверяем статус обновления (должен быть SUCCESS) SELECT * FROM information_schema.task_runs ORDER BY CREATE_TIME DESC LIMIT 1; WITH ranked_category_sales AS ( SELECT category_name, order_date, total_quantity, total_revenue, total_orders, ROW_NUMBER() OVER (PARTITION BY order_date ORDER BY total_revenue DESC) AS revenue_rank FROM dws_order_aggregates_mv ) -- топ‑10 категорий SELECT category_name, order_date, total_quantity, total_revenue, total_orders FROM ranked_category_sales WHERE revenue_rank <= 10;
Итоги
В большинстве случаев связка StarRocks Hive Catalog + Data Cache отлично покрывает потребности аналитики по озеру данных.
Асинхронные материализованные представления StarRocks упрощают ETL‑процессы, снижают сложность бизнес‑логики и обеспечивают высокую производительность запросов.

