
Особенности создания синтаксического анализатора русского текста
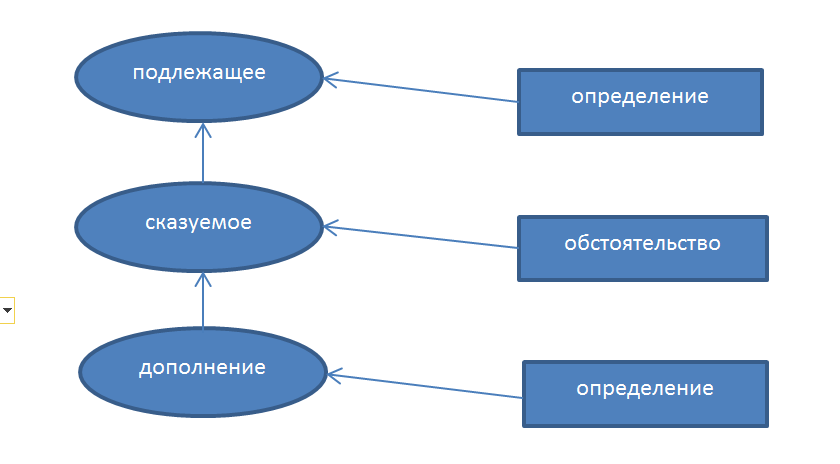
В данной статье приводится краткое описание основных особенностей, проблем и сложностей, которые автору пришлось решать при реализации программы морфологической и синтаксической обработки текстов на русском языке.
Была поставлена задача создания программы морфологической и синтаксической обработки грамотно составленных текстов на русском языке с перспективой последующего объединения с семантическим анализатором. В связи с тем, что русский язык имеет некоторую логику построения, то виделось возможным обработать данную языковую логику классическим программным способом (без использования нейросетей), при этом учитывались следующие соображения. Классическая программа обладает максимальной гибкостью при создании изощренных алгоритмов обработки; сами алгоритмы ориентируются на формализованные конструкции словосочетаний, обрабатывают не конкретные слова, а типы слов, что позволяет легко справляться с новыми словами, возникающими в языке достаточно часто. Данный подход видится целесообразным и при дальнейшем развитии программы – включение семантического анализатора в общий сквозной процесс обработки текстов.
В результате данная задача была в целом выполнена (пока без семантической обработки). Резюмируя пройденный этап, важно отметить ключевые технические задачи в рамках синтаксического разбора, которые требовали решения: выделение из всего множества единственно верной (наиболее вероятной) связи главного и зависимого слова плюс параллельный с этим выбор единственной морфологической формы слова среди множества возможных омонимов.