Ещё раз хочу вас по благодарить за участие в мастер классе. Для мне было очень приятно увидеть такой интерес к теме с вашей стороны.
Как и обещал раскрываю секрет последнего кейса с мастер класса.
Вы могли заметить что в параметрах запуска JVM был параметер -Dlogback.level.org.optaplanner=debug. Логи пишутся в файл target/optaplanner.log. Вы легко можете убедиться, что один запуск бенчмарка создаёт около 50 мегабайт лога (в консоль при этом печатаются сообщения с уровнем INFO и выше).
При изменении параметра на -Dlogback.level.org.optaplanner=info время оптимизации модели на моей машине сократилось с 35.7 до 9.3 секунд.
Mission Control не лучший инструмент для анализа подобного рода узких мест. Тем не менее, некоторые улики найти было можно.
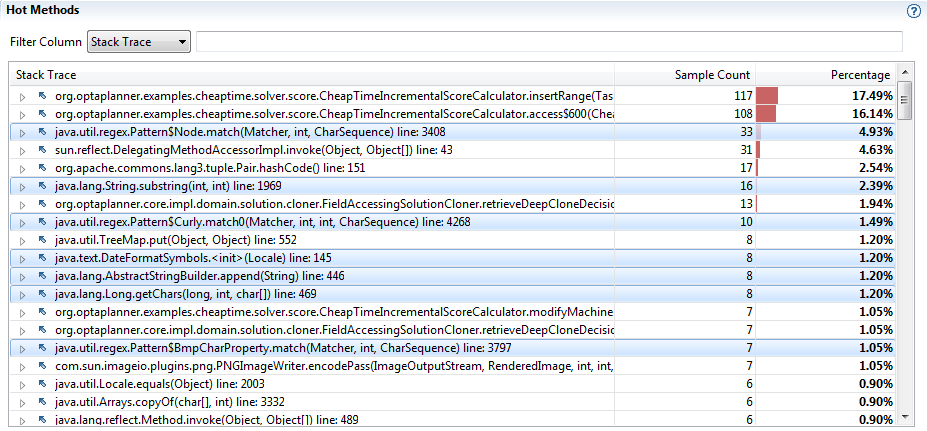
“Длинный след” логгера на гистограмме горячих методов
На гистограмме ниже выделено несколько горячих. Каждая из них если раскрутить дерево вывода имеет отношение к легированию. В сумме выделенные строки уже дают 13.5%, что сопоставимо в временем работы наиболее горячих методов модели.
Активное использование исключений логгером
Во вкладке исключений мы видим не малое число java.lang.Throwable, которые растут из логгера.
Файловые операции на таймлайне потока
Если посмотреть на таймлайн поток выполняющего оптимизацию, но плотно заполнен записью в файл. Заметьте что скриншот сделан с зумом в 650 миллисекунд.
Суммарное "чистое" время всех файловых операций всего 1.6 секунды (из 30 секунд записи), что само по себе. Однако большая плотность коротких IO операций обычно является поводом задуматься об их природе.
Все эти "улики" косвенные. Mission Control хорош тогда когда вы хорошо понимаете природу проблемы, которую вы хотите решить.
Почему же я выбрал этот кейс для мастер класса? Отчасти чтобы у вас был стимул испробовать все возможности Mission Control, a остановиться на первом скрине показавшем правильный результат. Отчасти чтобы показать как используя профйлер можно потерять лес за деревьями.
Как правило, после того как заявка прошла через ордер менеджер, на неё начинают приходить сделки с рынка. Так что, в приведённом примере, шанс найти заявку в кэше неплохой.
Но, в общем случае, оперативный объём данных к кэш не помещается и в память сходить придётся. Один поход в память это 50-100 наносекунд, что само по себе не много. Но что бы достать, допустим, заявку по ID, нужно прочитать целую цепочку объектов из памяти (контейнер транзакции, коллекцию индексов, поиск в хэше и т.п.). Кроме этого надо загрузить мэппинги виртуальный памяти для всех страниц памяти, которые мы читаем. Часть этих структур, хорошо кэшируется и, за счёт прогретых кэшей, мы экономим реальные микросекунды.
Файл дампа представляет из себя непрерывную последовательность записей (в основном Java объекты). Объекты в графе ссылаются друг на друга по оригинальным адресам в памяти. Основная функция индекса — поиск смещения в файле дампа по логического адресу объекта.
Интерактивные анализаторы (Visual VM, Eclipse MAT) так же строят индекс обратных ссылок и некоторые другие вспомогательные индексы. Для пакетной обработки эти индексы не так важны, в своей версии я использую только индекс из адреса объекта в смещение.
Построение индекса требует последовательно чтения файла. Потребление памяти при построении индекса — это не фундаментальная проблема, а скорее особенность реализации конкретного профайлера.
Map Reduce теоретически применим для построения дополнительных индексов, но с ними больших проблем и так нет. Параллельный анализ самого графа в теории возможен, но это не задача такого масштаба. 150GiB не такой большой объём, чтобы получить существенный выигрыш от распределённой обработки
Eclipse MAT, кстати, позволяет построить индекс в пакетном режиме через командную строку. Такой индекс можно построить на сервере и скопировать потом на декстоп.
Хороший вопрос. Открыть coredump можно только на той же версии OS, используя сторого идентичный билд JVM (для Open JDK ещё требуется установка debug символов). JVM Heap dump не зависит от версии JVM и более компактный.
Иногда я снимаю coredump как промежуточный шаг, чтобы сделать из него heap dump (команда jmap может работать с coredump'ами). Если JVM большая, а памяти на системе впритык, такой путь менее болезненый для системы.
Но в целом, использование Servicability Agent — тема интересная. У меня давно крутится идея анализа памяти не по дампу на диске, а по образу памяти. Servicability Agent, в теории, позволяет это сделать.

Я набираю группу для двух дневного тренинга 21-22 Мая (программа). По вопросам участия пишите в личку или на почту.
Слайды, которые я использовал по ходу мастер класса доступны тут.
Ещё раз хочу вас по благодарить за участие в мастер классе. Для мне было очень приятно увидеть такой интерес к теме с вашей стороны.
Как и обещал раскрываю секрет последнего кейса с мастер класса.
Вы могли заметить что в параметрах запуска JVM был параметер
-Dlogback.level.org.optaplanner=debug. Логи пишутся в файлtarget/optaplanner.log. Вы легко можете убедиться, что один запуск бенчмарка создаёт около 50 мегабайт лога (в консоль при этом печатаются сообщения с уровнем INFO и выше).При изменении параметра на
-Dlogback.level.org.optaplanner=infoвремя оптимизации модели на моей машине сократилось с 35.7 до 9.3 секунд.Mission Control не лучший инструмент для анализа подобного рода узких мест. Тем не менее, некоторые улики найти было можно.
“Длинный след” логгера на гистограмме горячих методов
На гистограмме ниже выделено несколько горячих. Каждая из них если раскрутить дерево вывода имеет отношение к легированию. В сумме выделенные строки уже дают 13.5%, что сопоставимо в временем работы наиболее горячих методов модели.
Активное использование исключений логгером
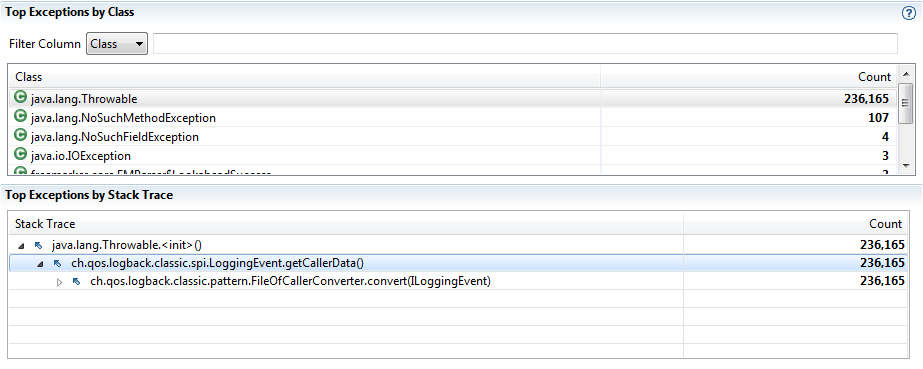
Во вкладке исключений мы видим не малое число
java.lang.Throwable, которые растут из логгера.Файловые операции на таймлайне потока
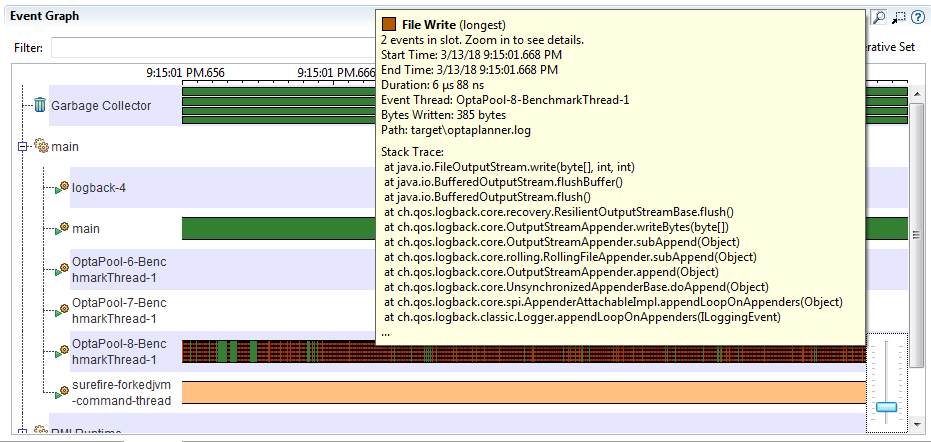
Если посмотреть на таймлайн поток выполняющего оптимизацию, но плотно заполнен записью в файл. Заметьте что скриншот сделан с зумом в 650 миллисекунд.
Суммарное "чистое" время всех файловых операций всего 1.6 секунды (из 30 секунд записи), что само по себе. Однако большая плотность коротких IO операций обычно является поводом задуматься об их природе.
Все эти "улики" косвенные. Mission Control хорош тогда когда вы хорошо понимаете природу проблемы, которую вы хотите решить.
Почему же я выбрал этот кейс для мастер класса? Отчасти чтобы у вас был стимул испробовать все возможности Mission Control, a остановиться на первом скрине показавшем правильный результат. Отчасти чтобы показать как используя профйлер можно потерять лес за деревьями.
Но, в общем случае, оперативный объём данных к кэш не помещается и в память сходить придётся. Один поход в память это 50-100 наносекунд, что само по себе не много. Но что бы достать, допустим, заявку по ID, нужно прочитать целую цепочку объектов из памяти (контейнер транзакции, коллекцию индексов, поиск в хэше и т.п.). Кроме этого надо загрузить мэппинги виртуальный памяти для всех страниц памяти, которые мы читаем. Часть этих структур, хорошо кэшируется и, за счёт прогретых кэшей, мы экономим реальные микросекунды.
Интерактивные анализаторы (Visual VM, Eclipse MAT) так же строят индекс обратных ссылок и некоторые другие вспомогательные индексы. Для пакетной обработки эти индексы не так важны, в своей версии я использую только индекс из адреса объекта в смещение.
Построение индекса требует последовательно чтения файла. Потребление памяти при построении индекса — это не фундаментальная проблема, а скорее особенность реализации конкретного профайлера.
Map Reduce теоретически применим для построения дополнительных индексов, но с ними больших проблем и так нет. Параллельный анализ самого графа в теории возможен, но это не задача такого масштаба. 150GiB не такой большой объём, чтобы получить существенный выигрыш от распределённой обработки
Eclipse MAT, кстати, позволяет построить индекс в пакетном режиме через командную строку. Такой индекс можно построить на сервере и скопировать потом на декстоп.
https://wiki.eclipse.org/MemoryAnalyzer/FAQ#How_to_run_on_64bit_VM_while_the_native_SWT_are_32bit
Иногда я снимаю coredump как промежуточный шаг, чтобы сделать из него heap dump (команда jmap может работать с coredump'ами). Если JVM большая, а памяти на системе впритык, такой путь менее болезненый для системы.
Но в целом, использование Servicability Agent — тема интересная. У меня давно крутится идея анализа памяти не по дампу на диске, а по образу памяти. Servicability Agent, в теории, позволяет это сделать.