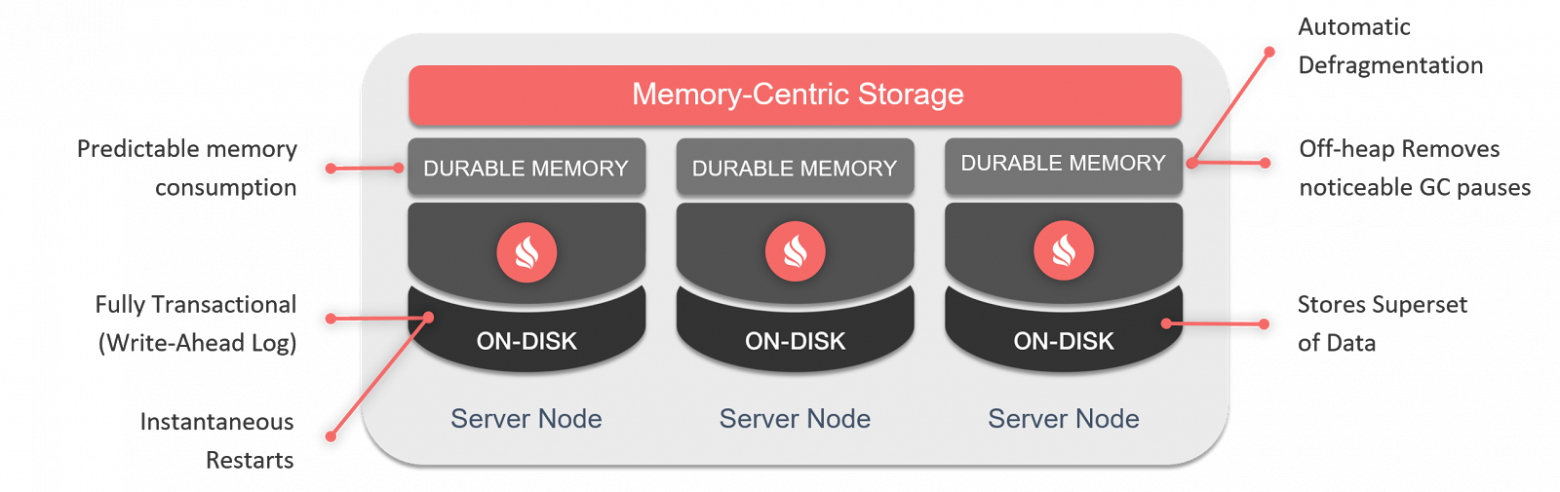
В Apache Ignite, начиная с версии 2.1 появилась собственная реализация Persistence.
На то, чтобы построить этот механизм в современном его исполнении, ушли десятки человеколет, которые были в основном потрачены на построение распределенного отказоустойчивого транзакционного хранилища с поддержкой SQL.
Всё началось с фундаментальных проблем предыдущего механизма, который позволял интегрировать In-Memory Data Grid с внешними постоянными хранилищами, например, Cassandra или Postgres.
Такой подход накладывал определенные ограничения — например, было невозможно выполнять SQL или распределенные вычисления поверх данных, которые находятся не в памяти, а в таком внешнем хранилище, был невозможен холодный запуск и низкий RTO (Recovery Time Objective) без существенных дополнительных усложнений.
Если вы используете Apache Ignite Persistence, то оставляете себе все обычные возможности Apache Ignite — ACID, распределенные транзакции, распределенный SQL99, доступ через Java/.NET API или интерфейсы JDBC/ODBC, распределенные вычисления и так далее. Но теперь то, что вы используете, может работать как поверх памяти, так и поверх диска, который расширяет память, на инсталляциях от одного узла до нескольких тысяч узлов.
Давайте посмотрим, как устроен Apache Ignite Persistence внутри. Сегодня я рассмотрю его основу — Durable Memory, а в следующей публикации — сам дисковый компонент.
Терминология
Сделаю ремарку по поводу терминологии. В контексте кеша на кластере Apache Ignite я буду использовать понятия «кеш» и «таблица» как взаимозаменяемые. «Кеш» я буду употреблять чаще применительно к внутренней механике, а «таблица» — к SQL. В общем случае, за пределами Apache Ignite эти понятия могут иметь несколько иной смысл, а за пределами этой статьи могут быть не всегда равноценными. Так, c учетом наличия постоянного хранилища «кеш» Apache Ignite уже далеко не всегда вписывается в общепринятую семантику этого слова. А что касается «таблицы», то на основе кеша Apache Ignite может быть определено несколько «таблиц» с возможностью обращения с использованием SQL, либо не определено таблиц вовсе (тогда обращение будет возможно лишь через Java/.NET/C++ API и производные от них).
Durable Memory
Для построения эффективного смешанного хранилища в памяти и на диске, не дублируя огромное количество кода, что значительно повысило бы стоимость поддержки продукта, пришлось значительно переработать архитектуру хранения данных в памяти.
Новая архитектура — Durable Memory — как и Persistence, обкатывалась на крупных клиентах GridGain c конца прошлого года, а публично дебютировала начиная с Apache Ignite 2.0. Она обеспечивает хранение данных в off-heap в страничном формате.
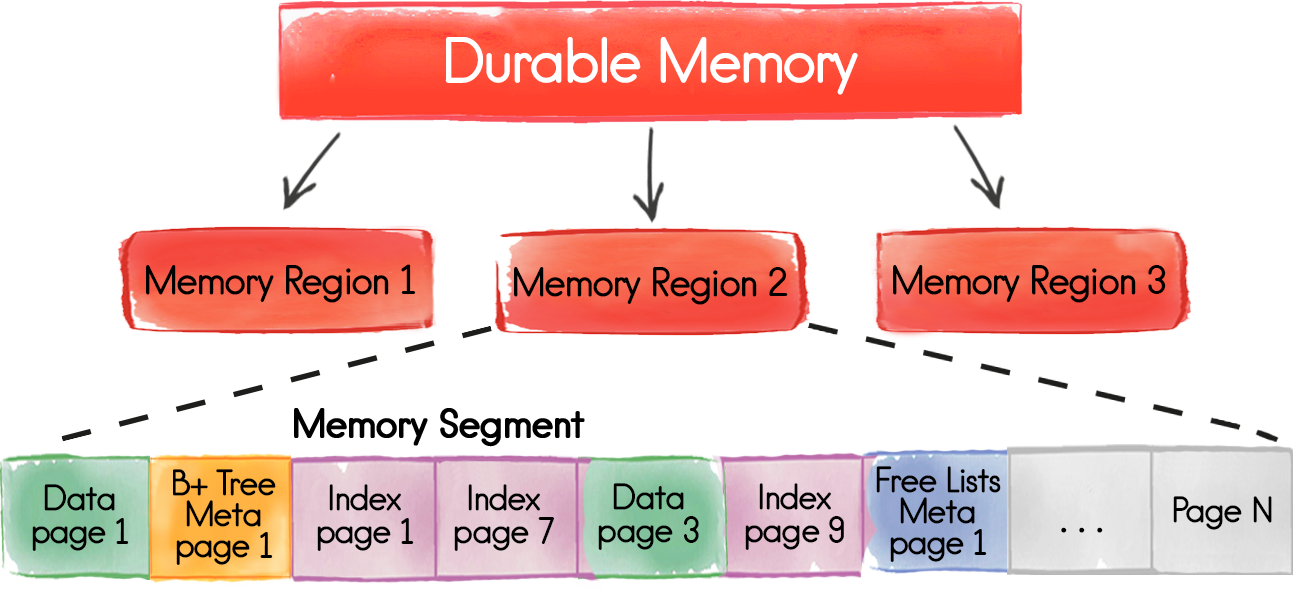
Страницы памяти / Pages
Базовой единицей хранения является «страница», которая содержит фактические данные или метаданные.
Когда при исчерпании выделенного объема памяти данные вытесняются на диск, это происходит постранично. Поэтому размер страницы не должен быть слишком большим, иначе пострадает эффективность вытеснения, так как в больших страницах к холодным данным с большей вероятностью окажутся подмешаны горячие, которые постоянно будут тянуть страницу наверх, в память.
Но когда страницы становятся небольшими, возникают проблемы сохранения массивных записей, которые не помещаются на одну страницу, а также проблемы фрагментации и выделения памяти (слишком дорого запрашивать память у операционной системы на каждую маленькую страницу, в которую поместятся 1-2 записи).
Первая проблема — с большими записями — решается через возможность «размазывать» такую запись на несколько страниц, каждая из которых хранит только какой-то сегмент. Обратная сторона этого подхода — более низкая производительность при работе с такими записями за счет необходимости обхода нескольких страниц для получения полной информации. Поэтому если для вас это частый случай, то имеет смысл рассмотреть увеличение размера страницы «по умолчанию» (изначально — 2 KiB с возможностью варьировать в пределах 1-16 KiB) через
MemoryConfiguration.setPageSize(…).В большинстве ситуаций имеет смысл переопределять размер страницы также если он отличается от размера страницы на вашем SSD (чаще всего это 4 KiB). В ином случае можно наблюдать некоторую деградацию производительности.
Вторая проблема — с фрагментацией — частично решается онлайн-дефрагментацией, встроенной в платформу, которая оставляет только какой-то небольшой «несгораемый остаток» в странице данных, который слишком мал, чтобы уместить в него ещё что-либо.
Третья проблема — высокая стоимость выделения памяти под страницы при их большом количестве — решается через следующий уровень абстракции, «сегменты».
Сегменты памяти / Segments
Сегменты — это непрерывные блоки памяти, которые являются атомарной единицей выделяемой памяти. Когда выделенная память заканчивается, и если ограничение по использованию еще не достигнуто, у ОС запрашивается дополнительный сегмент, который далее внутри уже делится на страницы.
В текущей реализации предполагается выделение до 16 сегментов памяти на один регион с объемом сегмента не менее 256 MiB. Фактический объем сегмента определяется как разность максимально разрешенной памяти и исходно выделенной, делённая на 15 (16-й сегмент — изначально выделенная память). Например, если ограничение сверху — 512 GiB на узел, и изначально выделено 16 GiB, то размер выделяемых сегментов будет равен (512 — 16) / 15 ≈ 33 GiB.
Когда мы говорим о сегментах, то нельзя не упомянуть про ограничения по потреблению памяти. Рассмотрим подробнее их реализацию.
Неоптимально делать глобальные настройки на все релевантные параметры: максимальный и исходный объемы, вытеснение и так далее, поскольку у разных данных могут быть разные требования к хранению. Один из примеров — оперативное и архивное хранилище данных. Мы можем желать хранить заказы за последний год в оперативном хранилище, которое большей частью находится в памяти, потому что там могут быть горячие данные, но при этом старую историю заказов и прошедшие внутренние транзакции мы можем хотеть хранить на диске, не занимая, пусть даже временно, драгоценную память.
Можно было бы сделать настройку ограничений на уровне каждого кеша, но тогда мы бы попали в ситуацию, когда при большом количестве таблиц — нескольких сотнях или тысячах — пришлось бы каждой выделять считанные крохи памяти, или делать overbooking, быстро получая ошибку нехватки памяти.
Был выбран смешанный подход, который позволяет определять лимиты для групп таблиц, что подводит нас к следующему уровню абстракции.
Регионы памяти / Regions
Верхним уровнем архитектуры хранения Durable Memory является логическая сущность «регион памяти», которая группирует таблицы, разделяющие единую область хранения со своими настройками, ограничениями и так далее.
Например, если у вас в приложении есть кеш товаров с критичными к надежности данными и ряд производных кешей агрегатов, которые активно наполняются, но не очень критичны к потере, то можно определить два региона памяти: к первому, с ограничением потребления в 384 GiB и строгими гарантиями консистентности, привязать кеш товаров, а ко второму, с ограничением в 64 GiB и с ослабленными гарантиями, привязать все временные кеши, которые будут разделять между собой эти 64 GiB памяти.
Регионы памяти накладывают ограничения, определяют настройки хранения и группируют кеши в связанные с точки зрения выделенного под хранения пространства группы.
Типы страниц и получение данных
Страницы памяти делятся на несколько типов, ключевыми из которых являются страницы данных и индексов.
Страницы данных хранят непосредственно данные, они уже в общих чертах обсуждались выше. Если запись не помещается в одну страницу, то будет размазана по нескольким, но это не бесплатная операция. И если больших записей в сценарии применения много, то имеет смысл увеличить размер страницы через
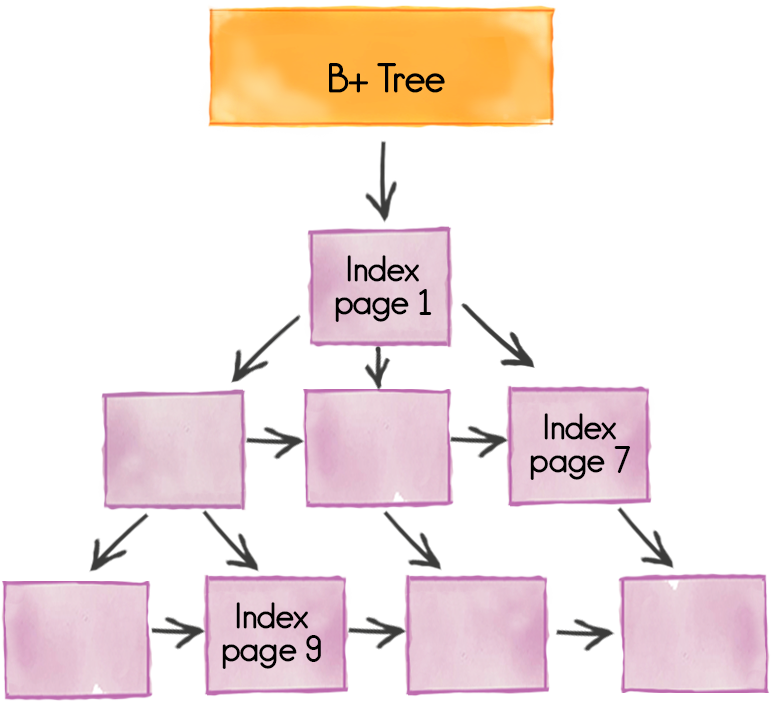
MemoryConfiguration.setPageSize(…). Вытеснение данных на диск осуществляется постранично: страница либо полностью находится в RAM, либо полностью на диске.Страницы индексов хранятся в виде B+-деревьев, каждое из которых может быть распределено по нескольким страницам. Страницы индексов всегда находятся в памяти для максимально оперативного доступа при поиске данных.
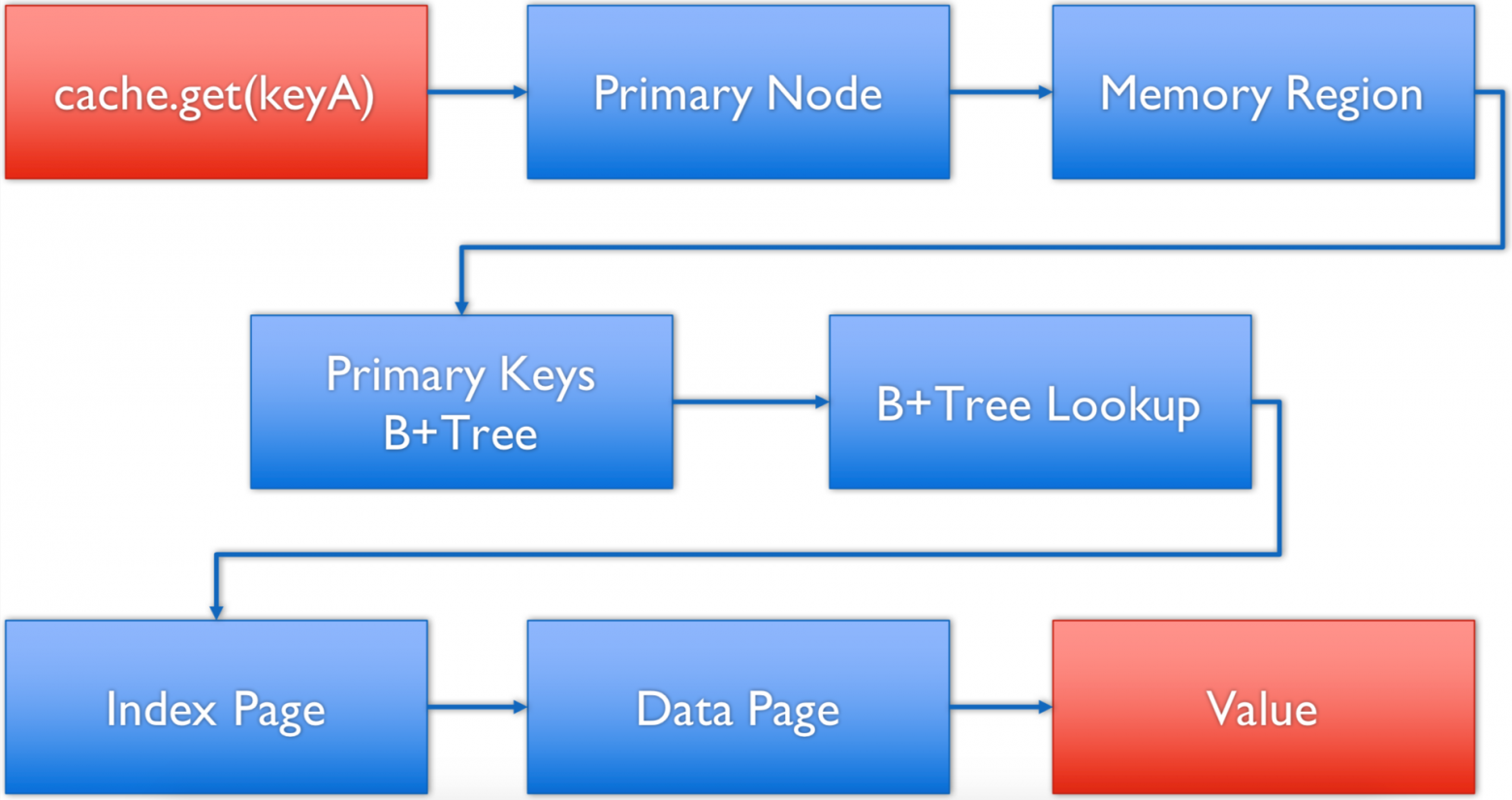
В такой схеме для получения данных по ключу мы проходим следующий процесс:
- на клиенте вызывается метод
cache.get(keyA); - клиент определяет серверный узел, который отвечает за данный ключ, используя встроенную affinity-функцию, и делегирует запрос по сети на этот серверный узел;
- серверный узел определяет регион памяти, который отвечает за кеш, по ключу, в котором идет запрос;
- в соответствующем регионе идет обращение к странице мета-информации, которая содержит точки входа в B+-деревья по первичному ключу данного кеша;
- выполняется поиск нужной страницы индексов для данного ключа;
- в странице индекса выполняется фактический поиск ключа и определяется страница данных, которая его содержит, а также смещение в этой странице;
- идет обращение к странице данных, и из нее по ключу считывается значение.
SQL
SQL-запросы с помощью H2 порождают двухэтапный план выполнения (в общем случае), который, по сути, сводится к MapReduce-подобному подходу. Первый этап плана «разливается» на все узлы, которые отвечают за таблицу, где аналогично выполняется определение региона памяти, ответственного за таблицу. Далее, если отбор идет по индексу, ищется нужная страница индексов, определяются месторасположения отобранных значений, и выполняется итерирование по ним. В случае полного сканирования происходит полное итерирование по первичному индексу и, соответственно, обращение ко всем страницам.
Вытеснение
Начиная с версии 2.0 вытеснение работает постранично, с удалением страницы из памяти. Если настроен Persistence, то копия страницы и запись в индексах останутся нетронутыми, что даст возможность позднее поднять нужную информацию с локального диска. Если Persistence явно выключен или не настроен, то вытеснение приведет к полному удалению соответствующих данных с кластера.
Постраничное вытеснение лишает возможности легко работать с парами ключ-значение, но намного лучше ложится на возможности Persistence, и при достаточно малом размере страниц дает хорошие результаты.
В версии 2.1 поддерживается 3 режима вытеснения:
- disabled — вытеснения не происходит, при нехватке памяти выбрасывается ошибка;
- random lru — при вытеснении в цикле выбираются случайные 5 страниц данных, после чего удаляется одна — та, у которой метка времени доступа является наименьшей (обращались наиболее давно). Подход с отбором 5 случайных страниц был выбран из-за сложности высокопроизводительной реализации полной упорядоченности меток времени доступа;
- random 2 lru — аналогично предыдущему варианту, но у каждой страницы хранятся две метки времени доступа — последнего и предпоследнего, — и для выбора используется минимальная из них. Такой подход позволяет эффективнее отрабатывать ситуации, например, с редким полным сканированием или редкими запросами по большой части массива данных, которые с random lru могут создавать видимость того, что какие-то холодные страницы — горячие.
DataPageEvictionMode
/**
* Defines memory page eviction algorithm. A mode is set for a specific
* {@link MemoryPolicyConfiguration}. Only data pages, that store key-value entries, are eligible for eviction. The
* other types of pages, like index or meta pages, are not evictable.
*/
public enum DataPageEvictionMode {
/** Eviction is disabled. */
DISABLED,
/**
* Random-LRU algorithm.
* <ul>
* <li>Once a memory region defined by a memory policy is configured, an off-heap array is allocated to track
* last usage timestamp for every individual data page. The size of the array is calculated this way - size =
* ({@link MemoryPolicyConfiguration#getMaxSize()} / {@link MemoryConfiguration#pageSize})</li>
* <li>When a data page is accessed, its timestamp gets updated in the tracking array. The page index in the
* tracking array is calculated this way - index = (pageAddress / {@link MemoryPolicyConfiguration#getMaxSize()}</li>
* <li>When it's required to evict some pages, the algorithm randomly chooses 5 indexes from the tracking array and
* evicts a page with the latest timestamp. If some of the indexes point to non-data pages (index or system pages)
* then the algorithm picks other pages.</li>
* </ul>
*/
RANDOM_LRU,
/**
* Random-2-LRU algorithm: scan-resistant version of Random-LRU.
* <p>
* This algorithm differs from Random-LRU only in a way that two latest access timestamps are stored for every
* data page. At the eviction time, a minimum between two latest timestamps is taken for further comparison with
* minimums of other pages that might be evicted. LRU-2 outperforms LRU by resolving "one-hit wonder" problem -
* if a data page is accessed rarely, but accidentally accessed once, it's protected from eviction for a long time.
*/
RANDOM_2_LRU;
// ...
}* * *
В следующей публикации я рассмотрю подробнее, как Durable Memory ложится на реализацию дискового хранения (WAL + Checkpointing), а также остановлюсь на возможностях создания снепшотов, которые дают проприетарные расширения GridGain.
