Юрий Насретдинов (youROCK, Badoo)

Расшифровка доклада Юрия Насретдинова на конференции HighLoad++ 2015. Юрий расскажет про то, как Badoo (крупнейшая социальная сеть для знакомств с новыми людьми) сделали практически идеально ровную балансировку нагрузки на нашем кластере. Передаём ему слово...
Чтобы обслуживать то количество пользователей, то количество реквестов в секунду, которые мы получаем, у нас около трех тысяч серверов, и на PHP-FPM конкретно приходится 70 тысяч в пике.
О том, как мы эти запросы распределяем по нашему кластеру, я расскажу.

Кратко — о чем я буду рассказывать. Во-первых, я расскажу, как «с высоты птичьего полета» устроен роутинг запросов на нашем сайте. Потом расскажу, какие, вообще, существуют алгоритмы балансировки; про то, как мы делали балансировку до того, как мы сделали автоматическую систему. Расскажу про эту автоматическую систему, ну и будут кое-какие выводы. Также хотел сказать, что эта система будет выложена в open-source после этого доклада.
Давайте начнем с архитектуры.

На этом слайде изображен путь, который проходит запрос, когда вы набираете badoo.com и, соответственно, попадаете на наш сайт. Для начала, поскольку у нас больше, чем один дата-центр, есть система от компании «F5», которая называется «Global Traffic Manager». Она умеет для разных континентов резолвить DNS-запросы на соответствующий дата-центр. Потом, когда IP-адрес уже получен, трафик приходит на систему «Local Traffic Manager» той же самой компании. Это просто «железка», которая умеет принимать на себя весь трафик и распределять по тем правилам, которые вы задаете, распределяете его по разным кластерам. И у нас есть два вида трафика — это мобильный трафик и трафик на веб-сайтах. Для мобильного трафика у нас есть еще отдельный прокси, который принимает соединения от мобильных клиентов и держит их. Он не показан на слайде, но именно он общается с Nginx, который в свою очередь раздает запросы на PHP-FPM. Для веб-сайта LTM умеет балансировать такие запросы напрямую.

Таким образом, все это обслуживается либо PHP-FPM, либо в случае веб — это Nginx + PHP-FPM.
Зачем, вообще, нужна балансировка и что это такое?

Если количество запросов у вас на сайт больше, чем может выдержать один сервер, то, в принципе, вам нужна балансировка нагрузки для того, чтобы распределить трафик по нескольким серверам. И также, в принципе, достаточно очевидно, но это все-таки стоит отметить, что чем равномернее распределение нагрузки по тем серверам, которые стоят в бэкенде, тем меньше вам серверов нужно, чтобы обслуживать пики трафика, и тем лучше User Experience, потому что, как правило, время ответа зависит от загрузки сервера, и она тем выше, чем меньше сервера загружены.
Какие, вообще, существуют алгоритмы?

Я рассматриваю часто используемые алгоритмы, которые используются для балансировки именно веб-трафика. Я их разделил на четыре категории.
Первый вид балансировки я отнес к категории «тупых».

Самый простой алгоритм балансировки — это не балансировать нагрузку вообще, т.е. у вас нагрузка прекрасно держится одним сервером, и вы передаете всю нагрузку на этот сервер.
Далее, весьма простой алгоритм — это Sticky sessions, когда запросы с одного и того же IP-адреса или же от одного и того же клиента попадают на один и тот же сервер. Это простой в реализации алгоритм и, в принципе, у него есть большое количество плюсов, особенно если ваше приложение не на PHP. Но у его также есть много подводных камней, о которых я сейчас рассказывать не хотел бы, это тема отдельного доклада.
Ну и, конечно же, есть очень простой способ балансировки — это случайный выбор сервера. Он, в принципе, хорошо работает, особенно если у вас не очень много серверов и простые запросы. Но возможны всплески загрузки на какие-то конкретные сервера из-за того, что вы выбираете их случайно, и может прийти 10 запросов на один и тот же сервер, а второму серверу ничего не достанется.

И, что более распространенно, это алгоритм Round-robin. Этот алгоритм более сложный, чем случайная балансировка, но обладает самым главным достоинством по сравнению с ней — это равномерность нагрузки, т.е. если у вас одинаковые сервера и у вас одинаковые запросы, то вы с помощью этого алгоритма получите идеально ровную балансировку. Т.е. этот алгоритм заключается в том, что вы посылаете каждый следующий запрос на следующий сервер, и таким образом достаточно легко показать, что загрузка будет равномерной, не будет никаких всплесков.
Но жизнь немного сложнее и на практике такой алгоритм используют, но с некоторой модификацией.

Мы его тоже используем, это взвешенный Round-robin, когда сервера неодинаковые, и вы должны каким-то образом делать так, чтобы больше запросов попадало на те сервера, которые мощнее и могут держать большую нагрузку. Это можно реализовать разными способами, например, повторять один и тот же сервер несколько раз в обычном Round-robin. Таким образом, чем больше вес машины, тем больше повторений.

Группа алгоритмов, которые, грубо говоря, я отнес к категории «умных», которые каким-то образом должны следить за состоянием системы и балансировать нагрузку, исходя из этого. Например, очень распространенный алгоритм, который много где используется — Least Connections, когда ваш балансировщик отдает следующие запросы на сервера, с которыми установлено меньше всего соединений. Это тоже позволяет достичь равномерной нагрузки, потому что предполагается, что пока соединение открыто, то реквест обрабатывается.
Поскольку сервера неодинаковые, есть модификация этого алгоритма, которая учитывает веса — Weighted Least Connections.
Взвешенный Round-robin предполагает статические веса для серверов, которые задаются один раз и не меняются после этого. Но, строго говоря, вы можете их менять со временем. И это то, о чем я расскажу дальше.
Есть еще некоторые другие алгоритмы, которые тоже можно упомянуть.

Как мы распределяли нагрузку до того, как мы написали автоматическую систему? Это делалось руками администраторов — грубо говоря, приходит системный администратор, добавляет 10, 20, сколько-то серверов на наш кластер и «на глаз» смотрит, какой вес ему присвоить на основании частоты процессора, количества ядер, таймингов памяти и т.д. Он редактирует конфиг, который выглядит в Nginx примерно таким образом:

Можно понять, что здесь достаточно сложно что-то увидеть и тем более сложно что-то сделать, чтобы загрузка была ровной. Вот график нагрузки за несколько месяцев на разных серверах:

Для разных серверов загрузка процессора показана разным цветом. Можно видеть, что линии разного цвета находятся строго друг над другом. Т.е. загрузка стабильная, но у разных серверов она отличается довольно существенно. Отличается где-то на 20-30%.

Вы, наверное, спросите: а почему админы не могли затюнить веса руками? На самом деле тут причин очень много. Основная причина — это то, что очень большое количество времени проходит между внесением изменений и получением какого-то результата. Т.е. вы можете выровнять каждую линию отдельно, но вам нужно будет сделать 200 итераций и обновление не стоит делать слишком часто, например, мы делаем не чаще, чем раз в 15 минут. В общем, это очень большое усилие и ручная работа, которую не очень хотелось бы делать. Поэтому мы решили сделать по-другому.

Когда на нашем сайте начал расти трафик, особенно на мобильном кластере, мы решили сделать автоматическую балансировку, которая позволила, помимо выравнивания нагрузки, иметь меньшее количество серверов для того, чтобы обслуживать трафик в пике, и чтобы не упираться в 100% процессора, а то и желательно держать загрузку меньше, чем 75% (условно).

Я, опять же, выделил два основных подхода к тому, чтобы делать подбор весов для балансировщика:
- Это высчитывание какого-то индекса производительности и задание статического веса серверам;
- И противоположность первому — на основании состояния системы оценивать, какие веса нужно дать, и соответственно выдавать веса в процессе работы, наблюдая за тем, как она себя ведет.
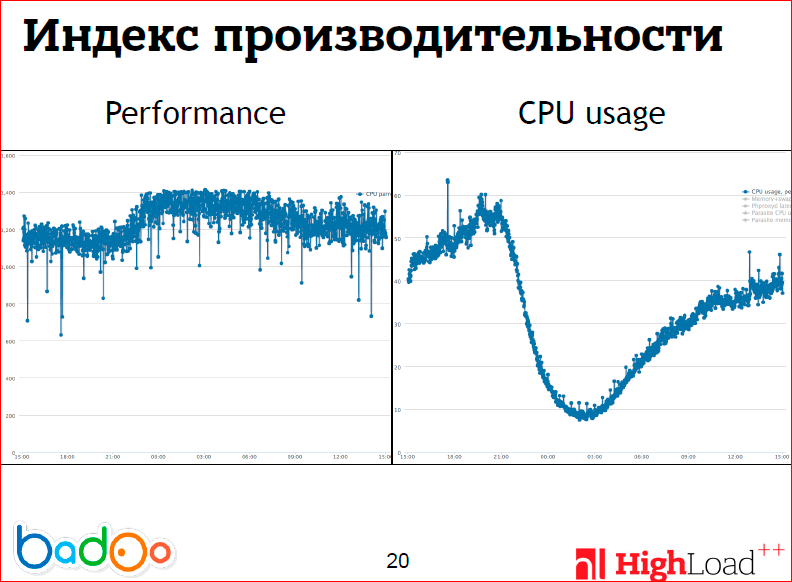
На этих двух графиках я попытался изобразить проблемы с первым подходом. На левом графике изображена дневная производительность машины, т.е. мы написали скрипт, который прогоняет некоторое количество циклов нашего приложения и измеряет, сколько их было за единицу времени (за одну секунду), и это гоняется на одном ядре. Можно видеть, что производительность как таковая, по крайней мере, для одного ядра, зависит от загрузки на системе, и это очень странно. Например, на процессорах AMD вы такого не увидите, но мы используем процессоры Intel, в которые включен hyper-threading. На слайдах не очень хорошо видно, но проседание производительности начинается где-то после 50 %, при этом сервер продолжает обслуживать все увеличивающуюся нагрузку и делает это вполне успешно, и hyper-threading в нашем случае очень хорошо работает, мы его оставляем включенным. Т.е. я хотел сказать, что выдать какой-то один вес на самом деле довольно проблематично, потому что производительность машины меняется со временем.

И не стоит забывать про то, что многие используют виртуальные машины, у которых понятие производительности очень плавающая величина, т.е. не очень понятно какой вес брать.
К сожалению, такой подход, несмотря на то, что он очень надежный (т.е. там нечему ломаться, нечему выходить из строя), он не очень работал в наших условиях. И, собственно, этот алгоритм ничем не отличается от ручного подбора весов, который должны были админы делать. Поэтому после многих итераций мы придумали следующий алгоритм.

Предположим, что загрузка процессора зависит линейно от веса, что, в принципе, должно выполняться в большинстве случаев. Т.е. ваше приложение начинает пропорционально больше «есть» процессора, чем больше запросов в секунду оно получает, если оно в состоянии их обработать. И тогда получим очень простую формулу — мы умножаем текущий вес на отношение средней загрузки по кластеру на среднюю загрузку машины. Получается очень простая линейная формула. Таким образом мы стараемся внести такой сигнал в систему, который бы привел ее в устойчивое состояние, т.е. уменьшил разницу. Понятно, что когда разницы нет, коэффициент будет единицей, и веса меняться не будут.
Напомню, как выглядел график (правда, 3-хмесячный, у нас, к сожалению, нет более точных данных, чтобы дать дневные графики) до того, как мы внедрили эту систему:

И вот как стал выглядеть график после:
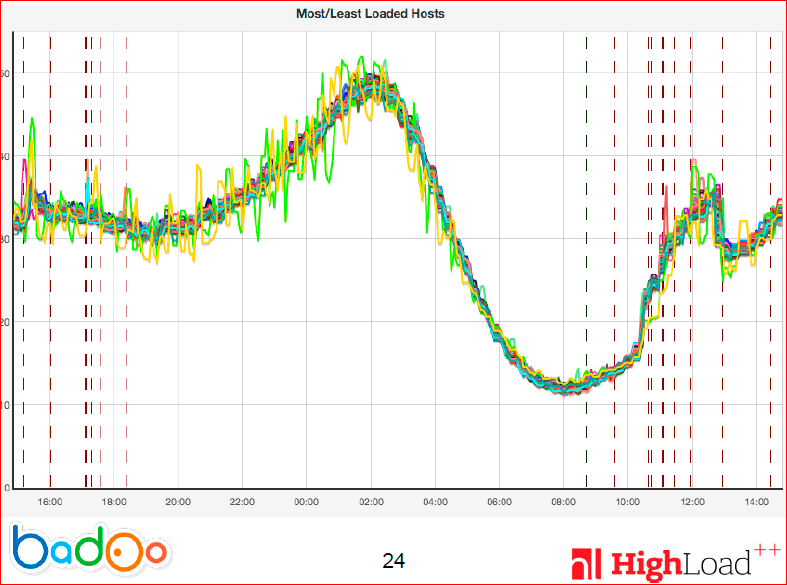
Это дневной график.
Можно видеть, что, за исключением пары серверов, загрузка на которых больше похожа на синус, чем на что-то другое, почти все сервера (а там их около 200 штук) слились в одну линию. В принципе, это наблюдалось постепенно — как только мы включили эту систему, оно начало сходиться в очень тоненький промежуток, и разницу между самым нагруженным и самым ненагруженным сервером очень сложно увидеть на графике.

У этого подхода, на самом деле, есть очень много проблем, т.е. несмотря на то, что он дает хорошие результаты, было бы странно закончить доклад на этом и не рассказать о том, что с этой системой «не так».
Во-первых, понятно, что поскольку вы регулируете веса динамически, то вы можете случайно задать вес на машину такой, что машина не справиться с нагрузкой, и она будет выключена из кластера. Если в этом алгоритме есть какие-то проблемы, то вы можете вырубить кластер, несмотря на то, что он способен обслуживать нагрузку.
Потом, есть интересная проблема — то, что этот алгоритм довольно проблематично встроить в LTM и сам Nginx, т.е. наверное, в Nginx можно, а LTM — это просто закрытая «железка», которой можно сообщать новые веса каким-то внешним образом.
И есть такая проблема — эти веса могут, в принципе, не применяться, т.е. вы даете системе какие-то новые веса, но она продолжает работать со старыми, вы продолжаете применять свою формулу, а ничего не получается.
Потом отдельная проблема — как удалять машины? Она, в принципе, не связана конкретно с ровной балансировкой, просто это проблема, которая здесь не решается никак.
Еще — у LTM есть ограничения на максимальный вес в 100 и, возможно, с этим тоже есть какие-то проблемы.

Во-первых, как сделать из такой очень простой формулы что-нибудь более стабильное, что не подвержено перегрузкам, т.е. если ваш сервер 15 минут назад имел загрузку 50%, вы на него дали загрузку в два раза больше, то это, скорее всего, значит, что у него загрузка 100%, но не факт, что он будет обслуживать все запросы корректно при этом.
Идея очень простая: не стоит менять веса слишком сильно за единицу времени. В нашем случае мы получаем более-менее ровную линию загрузки серверов, если строить одну точку за 15 минут. Т.е. обновление весов должно происходить не чаще, чем в 15 минут в наших условиях, иначе там очень большие временные погрешности из-за неравномерности пользовательской нагрузки получаются. Соответственно, мы накладываем ограничения на коэффициент, на который мы умножаем вес. Это, опять же, подобрано эмпирическим путем — мы добавляем не больше 5% к весу каждый раз, и поскольку это целое число, то значит, что минимальный вес должен быть 20, т.е. 5% от него — единица. А также, чтобы не было ситуаций, когда кластер не нагружен, например, серверы временно ошибаются в запросах или еще какие-нибудь проблемы, не скидывает нагрузку с тех серверов, которые в состоянии обслуживать то, что слишком быстро…

Что делать, если у вас таки нарушилась обратная связь, т.е. веса не применяются? Довольно легко понять, что приведенная мной формула будет тем сильнее увеличивать разницу между загрузкой процессора, чем больше времени прошло. Смысл в том, что если веса не применяются, вы будете видеть разницу, которой нет, и будете все дальше и дальше увеличивать нагрузку на слабые сервера и наоборот недодавать нагрузку на сильные. Это совсем не то, что нужно.
В нашем случае, мы решили проблемы тем, что мы поставили ограничения как на минимальный вес, который приходится на одно ядро машины, так и на максимальный. Т.е. мы считаем, что разница между ядрами — самой мощной машиной и самой слабой — будет не больше, чем в три раза. Кажется, что это довольно логично, т.е. зачем держать сервера, которые отличаются в три раза по производительности? И так мы лимитируем проблемы, которые возникнут в случае нарушения обратной связи. Т.е. это не решает проблему, но если у вас, например, меньше чем 30% нагрузка, то этот подход будет работать.
Так же на общий вес и на число ядер — просто потому, что они не должны быть слишком большие.

Еще один вопрос: что делать, если нужно удалить машину из кластера, т.е. машина больше не отвечает на запросы, но такое возможно в двух случаях — если машина перегружена, т.е. на нее дается слишком много запросов, и вторая проблема — машина действительно «умерла». Дело в том, что когда вы достигнете пика трафика, и если у вас вдруг в этот момент возникнут какие-то проблемы на кластере, то скорее всего, они будут на всех серверах. И просто, потому что серверы не отвечают по heartbeat’у, не стоит удалять сервера, т.к. вы можете таким ообразом каскадно отключить весь кластер.
В нашем случае мы решили использовать просто информацию, которая у нас есть о загрузке процессора в пике. Мы смотрим, справится ли система, если убрать этот сервер из балансировщика, и справится ли она с нагрузкой в пике трафика. Если нет, то мы сервер оставляем. В принципе, этой логики должно быть достаточно для того, чтобы у вас не было проблемы с перегрузкой процессора.

И напоследок кратко о том, что я хотел сказать.
Для веб-запросов взвешенный round-robin работает очень хорошо. По крайней мере, для наших запросов, т.е. когда у вас запросы более-менее одинаковые, вам не нужно больше ничего придумывать, это работает.
Опять же, в нашем случае, чтобы подобрать веса статически, нужно приложить довольно много усилий, и не всегда этот подход хорошо работает. Я не привел цифры, сколько на самом деле разброс составил после того, как мы все сделали. Это 2.5%. Для двухсот серверов, мне кажется, это весьма неплохая цифра, т.е. разница между максимальной и минимальной загрузкой очень маленькая.
Также мы решили проблему того, что админы должны править конфиги вручную. И за счет количества серверов, которые у нас есть для того, чтобы обслуживать в пике трафика, нам теперь нужно примерно на 50 серверов меньше, что, кажется, весьма существенным.

Этот балансировщик будет выложен по адресу на слайде.
Также у нас есть очень большое количество других проектов, о которых, возможно, вы слышали. Это PHP-FPM, Pinba и Blitz. Есть и много мелких, о которых, возможно, вы не слышали — это, например, наш форматер для кода, инструменты для аналитики на клиенте под названием Jinba. Инструмент для того, чтобы запускать много параллельно через SSH под названием GoSSHa (написан на языке Go, соответственно). И разные другие вещи, например, библиотека для Android, которая позволяет избежать утечек памяти.
Контакты
y.nasretdinov@corp.badoo.com
youROCK
Блог компании Badoo
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++. Сейчас мы активно готовим конференцию 2016 года — в этом году HighLoad++ пройдёт в Сколково, 7 и 8 ноября.
В этом году Юрий также будет выступать на HighLoad++ с докладом "5 способов деплоя PHP-кода в условиях хайлоада". В этом докладе он расскажет о том, как Badoo деплоились в течение 10 лет, о том, какую новую систему для деплоя PHP-кода разработали и внедрили в production, а также проведёт обзор решений для масштабного деплоя кода на PHP и анализ их производительности.
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
