Comments 14
<rage>
ИМХО BI это магическая плюшка которую придумали маркетологи что бы можно было написать и продать кучу никому ненужного ПО, которое должно магическим образом решить очень много важных проблем… в общем что бы руководству без мозгов было на что щёлкать, да квази-графики-отчёты глядеть, что бы «деятельность имитировать» и «казаться важными», хотя на самом деле эти метрики дикий шлак и не имеют ничего общего с реальными проблемами которы. Нужно понимать потребности психологической компенсации и использовать это как возможность продажи продуктов :3
</rage>
Офисные знатоки совсем забыли что есть Microsoft Access с мифическим SQL-конструктором который отлично дружит с MySQL / PostgreSQL посредством ODBC, и ним много чего можно решить на уровне общих прикладных задач (2-3 статистических MOLAP отчёта без сложной аналитики). Офисный планктон до пол-сотни персонала такое вполне переваривает…
Для вещей посложнее есть вполне приемлемые открытые решения по типу JasperReports или Pentaho Mondrian / Weka.
Хотя большинство всей этой OLAP мути можно реализовать материализованными представлениями в БД и своими кастомными агрегирующими функциями
В проприетарщину стоит скатываться когда вам нужна вменяемая поддержка, но все задачи должны быть оч. шаблонны.
Как показывает практика кастомизация проприетарных решений без должного тестирования и организации труда
Вспоминаются ужасы XML-RPC over FTP в поделках
На счет маркетологов, отчасти согласен. Еще и самые хитрые задачи, обычно, исходят с их стороны.
Получается, что сами придумали сложные задачи и, в последствии, продовать дорогое ПО для их решения.
Но это наше с вами мнение. А вообще, так про многие вещи можно сказать, что они никому не нужны и все это от маркетологов.
Про Access. Вы забываете, что он тоже не бесплатный и в стандартном наборе Office его нет. Но он, действительно, позволит решать многие задачи, до определенного времени. Про это я как-то и забыл. Простите.
Про замену OLAP-мути представлениями и кастомными функциями. Специалист, который сделает это хорошо, скорее всего, обойдется заметно дороже среднего BI-разработчика. Я не так много знаю таких, но в Москве ЗП тех, кому бы я все это доверил может быть на 1,5тыс.$ больше. За год, с налогами, это больше 20тыс., за такие деньги можно много чего купить, плюс, как раз — внятная поддержка. Opensource-ный же OLAP может быть лишен таких приятных вещей, как write-back через Excel-евский «Анализ „что если“», с помощью которого легко создается система планирования. В общем, такая экономия в итоге может привести к сопостовимым затратам.
Получается, что сами придумали сложные задачи и, в последствии, продовать дорогое ПО для их решения.
Но это наше с вами мнение. А вообще, так про многие вещи можно сказать, что они никому не нужны и все это от маркетологов.
Про Access. Вы забываете, что он тоже не бесплатный и в стандартном наборе Office его нет. Но он, действительно, позволит решать многие задачи, до определенного времени. Про это я как-то и забыл. Простите.
Про замену OLAP-мути представлениями и кастомными функциями. Специалист, который сделает это хорошо, скорее всего, обойдется заметно дороже среднего BI-разработчика. Я не так много знаю таких, но в Москве ЗП тех, кому бы я все это доверил может быть на 1,5тыс.$ больше. За год, с налогами, это больше 20тыс., за такие деньги можно много чего купить, плюс, как раз — внятная поддержка. Opensource-ный же OLAP может быть лишен таких приятных вещей, как write-back через Excel-евский «Анализ „что если“», с помощью которого легко создается система планирования. В общем, такая экономия в итоге может привести к сопостовимым затратам.
Обычно на всех OLAP решениях принято ставить надпись «для Big Data», но вот почему-то я не видел OLAP'ов обрабатывающих по терабайту логов в сутки… Тем более там часто нужны различные Spatial индексы на всяких там MVP-деревьях и прочих интересностях, которые обычно недоступны простым смертным.
Чаще всего рядовые козлят логами в популярных СУБД, и это просто напрочь выносит мозг…
Проблема в том что местные B-tree индексы, при любых размерах таблиц, отчасти хранятся в памяти, с расчёта что вероятность обращения ко всем данным подлежит нормальному распределению. Профилятор конечно может там заоптимизировать индексы всякими Adaptive Radix Tree и проч. но собственно ситуацию это никак не меняет: чем выше количество инфы в таблицах — тем больше памяти кушает база. Естественно OLTP-провайдеры могут обработать местное MVCC в СУБД (контроль транзакций) на обобщённом уровне, но FullTable или Partition Scan'ы для синхронизации и пережимки журнала рано или поздно прокатывают, что приводит к диким лагам )
Использовать двумерные R-tree или многомерные X-tree индексы и т.п., которые получше подходят для таких задач, обычно не позволяетотсутствие совести разработчиков СУБД отсутствие знаний и практики в организации подобных решений. Им ничего не нужно хранить в памяти, и с range запросами они справляются на ура, так как пересчитывают все возможные пересечения множеств уже при вставке.
В MySQL вроде отдельно есть ENGINE ARCHIVE для логов с R-tree по-умолчанию, правда туда лучше писать уже обработанные данные, а актуальные продолжать держать в InnoDB etc… естественно многомерных выборок там нет.
Обработка самого whatever-SQL'я довольно медленная обычно агрегацию можно ускорить в 10-30 раз написав расширения с низкоуровневыми SIMD оптимизациями на С, возможно даже и в 100 раз с GPGPU :3
Естественно в проприетарщине такого никогда не будет — никому не выгодны абсолютные приемущества на рынке, а в опенсорсе не так много желающих заниматься подобным извратом — для совести проще писать прикладные решения.
Ставка абстрактного разработчика в вакууме с вменяемым опытом работы в час может составить 20-30$, это ~2500-3500$ (по себе сужу). За меньшие суммы обычно работать не принято…
Проприетарщина будет дешевле пока решаете шаблонные (обобщённые) задачи.
Как только нужно будет дёргать кластерные анализы да кастомную классификацию — обычно начинается шаманизм и отсебятинка.
Лучше со старту определить требования, учитывая возможность нанять джедаев и объём информации который нужно обработать.
Чаще всего рядовые козлят логами в популярных СУБД, и это просто напрочь выносит мозг…
Проблема в том что местные B-tree индексы, при любых размерах таблиц, отчасти хранятся в памяти, с расчёта что вероятность обращения ко всем данным подлежит нормальному распределению. Профилятор конечно может там заоптимизировать индексы всякими Adaptive Radix Tree и проч. но собственно ситуацию это никак не меняет: чем выше количество инфы в таблицах — тем больше памяти кушает база. Естественно OLTP-провайдеры могут обработать местное MVCC в СУБД (контроль транзакций) на обобщённом уровне, но FullTable или Partition Scan'ы для синхронизации и пережимки журнала рано или поздно прокатывают, что приводит к диким лагам )
Использовать двумерные R-tree или многомерные X-tree индексы и т.п., которые получше подходят для таких задач, обычно не позволяет
В MySQL вроде отдельно есть ENGINE ARCHIVE для логов с R-tree по-умолчанию, правда туда лучше писать уже обработанные данные, а актуальные продолжать держать в InnoDB etc… естественно многомерных выборок там нет.
Обработка самого whatever-SQL'я довольно медленная обычно агрегацию можно ускорить в 10-30 раз написав расширения с низкоуровневыми SIMD оптимизациями на С, возможно даже и в 100 раз с GPGPU :3
Естественно в проприетарщине такого никогда не будет — никому не выгодны абсолютные приемущества на рынке, а в опенсорсе не так много желающих заниматься подобным извратом — для совести проще писать прикладные решения.
Ставка абстрактного разработчика в вакууме с вменяемым опытом работы в час может составить 20-30$, это ~2500-3500$ (по себе сужу). За меньшие суммы обычно работать не принято…
Проприетарщина будет дешевле пока решаете шаблонные (обобщённые) задачи.
Как только нужно будет дёргать кластерные анализы да кастомную классификацию — обычно начинается шаманизм и отсебятинка.
Лучше со старту определить требования, учитывая возможность нанять джедаев и объём информации который нужно обработать.
> XML-RPC over FTP в поделках умников некоторых умельцев 1С
Вспомнил CSV-RPC over Floppy Disk для обмена с 1С, брр.
Вспомнил CSV-RPC over Floppy Disk для обмена с 1С, брр.
Какие olap системы в качестве серверов и клиентов порекомендуете?
Стандартный набор — MS SSAS + Excel 2010+ идеальный начальный вариант.
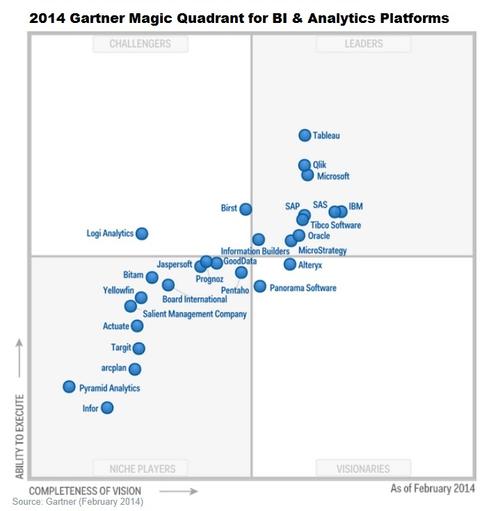
Согласно гартнеру, лучшей BI платвормой является Табло. По личномы опыту общения и сотрудничества с Кимбалл Групп — для OLAP Табло таки лучшее. Но, все равно, решение выбора нужно принимать под каждую задачу.
Согласно гартнеру, лучшей BI платвормой является Табло. По личномы опыту общения и сотрудничества с Кимбалл Групп — для OLAP Табло таки лучшее. Но, все равно, решение выбора нужно принимать под каждую задачу.
{kind=link}
Некое общее замечание, в контексте статьи лучше бы разделить системы на следующие отдельные части:
1. Источники данных — как правило это учетные системы (1C, Axapta, OEBS, SAP etc), которые уже существуют.
2. ETL средства, с помощью которых данные из источников перегружаются в…
3. Хранилище (в узком смысле слова). Которым может быть как обычная реляционная БД, так и настоящая многомерка типа essbase (прошу прощения у поклонников olap options etc) и которое предоставляет данные…
4. ПО «генерации отчетов» (звучит не красиво, не нашел другого перевода reporting software), для получения отчетов конечными пользователями.
Смешивать п.3 и 4 ошибочно, например вы можете иметь хранилище на SAP BW, но получать из него отчеты средствами Oracle BI EE. Или получать данные из Oracle Hyperion Essbase с помощью Microsoft Excel.
Иногда п. 2-3 можно пропустить и забирать данные например с помощью Excel или BOBJ сразу из учетной системы. Но у такого подхода есть несколько минусов:
— При большом объеме данных в учетной системе и\или большом числе отчетов, отчеты могут «убить» учетную систему создав слишком большую нагрузку.
— Если данные лежат в нескольких источниках (1С, CRM, HR), то объединение данных «на лету» без хранилища или технологически\организационно сложно, или опять же может быть ресурсоемко (читай дорого по железу, или медленно по времени генерации отчетов). Но, повторюсь, чисто теоретически строить отчеты прямо на учетной системе можно.
Исходя из этого замечания, а также потребностей (количество пользователей, их подготовки, потребности в отчетах) а также возможностей компании (финансовых) выбирают пункты 2-4.
Поэтому ad-hoc, это прямая противоположность регламентным отчетам, которые имеют заранее установленную форму и не меняются.
Собственно ad-hoc отчеты можно делать прямо на OLAP источниках (если под OLAP автор понимает многомерные источники-«кубы»).
По поводу ценников: цена складывается не только из цен на лицензии, но и включает, например, и стоимость дальнейшей поддержки решения. Да, лицензии на Oracle BI действительно дороги в редакции EE, но для малых предприятий есть Standard Edition One с более умеренным ценником. А вот если сравнить количество резюме специалистов на hh.ru по QlikView и Oracle BI, то выяснится, что спецов по последнему в разы больше, чем по QlikView.
В заключении хотелось бы сказать, что если у заказчика нет собственной сильной команды, то лучше таки потратить время на встречи с интеграторами, чем внедрить «не то и не так». Если говорить о крупных (ТОП-5) интеграторах, то от запроса до контракта может пройти месяц, но очень редко год (не повезло). Длительность внедрения зависит от масштабов проекта и уже мало зависит от размера внедренца.
Отвечая на заголовок:
тогда, когда владельцы хотят иметь отчетность быстро, с прозрачными и проверяемыми цифрами и готовы за это платить. Все остальное — выбор софта, внедренцев и прочее, это уже детали, главное понять, что иногда ручками в excel долго, неточно, и в конечном счете «дорого» за счет не верно принятых на основе таких отчетов, решений.
1. Источники данных — как правило это учетные системы (1C, Axapta, OEBS, SAP etc), которые уже существуют.
2. ETL средства, с помощью которых данные из источников перегружаются в…
3. Хранилище (в узком смысле слова). Которым может быть как обычная реляционная БД, так и настоящая многомерка типа essbase (прошу прощения у поклонников olap options etc) и которое предоставляет данные…
4. ПО «генерации отчетов» (звучит не красиво, не нашел другого перевода reporting software), для получения отчетов конечными пользователями.
Смешивать п.3 и 4 ошибочно, например вы можете иметь хранилище на SAP BW, но получать из него отчеты средствами Oracle BI EE. Или получать данные из Oracle Hyperion Essbase с помощью Microsoft Excel.
Иногда п. 2-3 можно пропустить и забирать данные например с помощью Excel или BOBJ сразу из учетной системы. Но у такого подхода есть несколько минусов:
— При большом объеме данных в учетной системе и\или большом числе отчетов, отчеты могут «убить» учетную систему создав слишком большую нагрузку.
— Если данные лежат в нескольких источниках (1С, CRM, HR), то объединение данных «на лету» без хранилища или технологически\организационно сложно, или опять же может быть ресурсоемко (читай дорого по железу, или медленно по времени генерации отчетов). Но, повторюсь, чисто теоретически строить отчеты прямо на учетной системе можно.
Исходя из этого замечания, а также потребностей (количество пользователей, их подготовки, потребности в отчетах) а также возможностей компании (финансовых) выбирают пункты 2-4.
Избавление ИТ от ad-hoc или рождение OLAP. Начало проекта BI.Противопоставлять ad-hoc и OLAP по меньшей мере странно, это понятия из разных областей: ad-hoc это, упрощенно, отчет который является ответом на вопрос, который (вопрос) родился здесь и сейчас.
Поэтому ad-hoc, это прямая противоположность регламентным отчетам, которые имеют заранее установленную форму и не меняются.
Собственно ad-hoc отчеты можно делать прямо на OLAP источниках (если под OLAP автор понимает многомерные источники-«кубы»).
По поводу ценников: цена складывается не только из цен на лицензии, но и включает, например, и стоимость дальнейшей поддержки решения. Да, лицензии на Oracle BI действительно дороги в редакции EE, но для малых предприятий есть Standard Edition One с более умеренным ценником. А вот если сравнить количество резюме специалистов на hh.ru по QlikView и Oracle BI, то выяснится, что спецов по последнему в разы больше, чем по QlikView.
В заключении хотелось бы сказать, что если у заказчика нет собственной сильной команды, то лучше таки потратить время на встречи с интеграторами, чем внедрить «не то и не так». Если говорить о крупных (ТОП-5) интеграторах, то от запроса до контракта может пройти месяц, но очень редко год (не повезло). Длительность внедрения зависит от масштабов проекта и уже мало зависит от размера внедренца.
Отвечая на заголовок:
Когда пора задуматься о внедерении BI-системы?
тогда, когда владельцы хотят иметь отчетность быстро, с прозрачными и проверяемыми цифрами и готовы за это платить. Все остальное — выбор софта, внедренцев и прочее, это уже детали, главное понять, что иногда ручками в excel долго, неточно, и в конечном счете «дорого» за счет не верно принятых на основе таких отчетов, решений.
Спасибо за интересные замечания.
Соглашусь с вашим ответом на заголовок. Кратко и в точку.
А OLAP и ad-hoc я, собственно, и не хотел противопоставить. Скорее, неверно выразился, имея в виду, что избавляем ИТ от написания каждый раз запросов для получения ответов, а даем в руки аналитиков (пользователей) удобное средство для самостоятельного извлечения необходимых данных — OLAP-кубы.
Соглашусь с вашим ответом на заголовок. Кратко и в точку.
А OLAP и ad-hoc я, собственно, и не хотел противопоставить. Скорее, неверно выразился, имея в виду, что избавляем ИТ от написания каждый раз запросов для получения ответов, а даем в руки аналитиков (пользователей) удобное средство для самостоятельного извлечения необходимых данных — OLAP-кубы.
Пришёл в тему по поиску «Tableau», ибо заинтересовался, что же люди про него пишут. Столкнулся с ним вынужденно, ибо в компании, куда я пришёл работать, на этом продукте основана система хранения данных и BI, а мои задачи плотно с BI пересекаются (я психолог-исследователь — массовые опросы, user research и всё такое).
Удивился, что продукт, имеющий индекс версии 8.2 выглядит настолько сырым. Я сперва думал, что идеология продукта плохо усваивается мной, ибо я мыслю в духе IBM SPSS и других статистических пакетов (где строка — это случай и т.п.). Но оказалось, что разработчики баз данных тоже имеют с этой таблой какие-то сложности. Идиотизм, например, в том. что чтобы сделать разбивку между группами столбиков, приходится скриншот из Tableau нарезать в офисной программе на кусочки и раздвигать вручную.
Есть ли у кого-то опыт с QlikView? Там тоже всё плохо?
Удивился, что продукт, имеющий индекс версии 8.2 выглядит настолько сырым. Я сперва думал, что идеология продукта плохо усваивается мной, ибо я мыслю в духе IBM SPSS и других статистических пакетов (где строка — это случай и т.п.). Но оказалось, что разработчики баз данных тоже имеют с этой таблой какие-то сложности. Идиотизм, например, в том. что чтобы сделать разбивку между группами столбиков, приходится скриншот из Tableau нарезать в офисной программе на кусочки и раздвигать вручную.
Есть ли у кого-то опыт с QlikView? Там тоже всё плохо?
C QlikView, в плане оформления отчетов и вообще визуализации, все очень даже хорошо. Есть другие недостатки, например, цена. Еще, я вот привык к разработке в MS Visiual Studio, и после этого сложно перестроиться на QlikView, где все надо прописывать вручную, а не мышкой «набрасывать» элементы. Это, конечно, касается только разработки самой модели данных и механизмов ETL, создавать отчеты ничуть не сложнее, чем в других системах
Sign up to leave a comment.
Когда пора задуматься о внедерении BI-системы?