Кто из нас не хочет сделать большое приложение с правильной архитектурой? Все хотят.
Чтобы была гибкость, переиспользуемость и четкость логики. Чтобы были домены, сервисы, их взаимодействие.
И даже иногда хочется чтобы было почти как в Erlang.
Идея создания фреймворка для микросервисов для NodeJs удачно воплощалась не единожды — так у нас как минимум есть Seneca и Studio.js, которые безусловно хороши, но они определяют большие логические единицы. С другой стороны у нас есть обычные объекты, разделяемые в системе посредством Dependency Injection или подобной техники, но они не дают должной четкости границ.
Иногда нужны "нано-сервисы".
За термином "нано-сервис" закрепим такое определение - "самостоятельные компоненты, взаимодействующие друг с другом в пределах одного процесса по контракту, при этом не использующие сеть".
Фактически это самые обычные объекты, однако отличия все же есть — компонент "нано-сервиса" явно описывает какие именно функции других сервисов ему требуются и однозначно перечисляет все экспортируемые функции. Компонент не может запросить у другого компонента выполнить что-то вне контракта.
Разрешением всех зависимостей будет заниматься фреймворк, которому будет безразлично, что и в какой последовательности было запрошено, единственное условие — граф зависимостей не должен быть циклическим и все требуемые сервисы должны по итогу быть зарегистрированы до старта системы.
" — Стоп! — скажете вы. — А что не так с микросервисами?"
Микросервисы — отличное решение для разделения монолитного приложения и они могут оказаться полезны для разнесения задач на несколько процессов. Однако, использование сети для взаимодействия снижает производительность, добавляет накладные расходы, накладывает ограничения на стиль взаимодействия и может быть небезопасным.
Далее — ситуации недоступности сервиса требуют обработчиков в каждом потребителе. Кроме того сразу же встает вопрос кто будет обслуживать инфраструктуру из десятков сервисов (процессов), отслеживать их статусы, каков сценарий их перезапуска, утилизации и т.п.
Например, микросервисы не подойдут если требуется разделить на компоненты обычное приложение — выделение модуля логирования, обращения к базе, валидатора в отдельные микросервисы выглядит неверным решением проблемы. Микросервисы слишком велики и дороги для таких задач.
" — Хорошо, тогда почему не классическая DI?"
Да, инверсия зависимостей позволяет переложить работу по созданию объектов на фреймворк, но никак не может ограничить их использование. Кроме того частенько в запале вместо конкретного сервиса в зависимости может оказаться сам контейнер, из которого динамически может быть запрошено что угодно. Такой стиль жестко блокирует компонент в системе, делая его вынесение и переиспользование фактически невозможным.
" — И альтернатива — нано-сервисы?"
Верно, нано-сервис вполне может оказаться инструментом подходящего размера.
Сначала я кратко опишу фреймворк Antinite, созданный для реализации данного подхода, а затем приведу код.
Схематически концепция выглядит следующим образом:

Имеются компоненты Foo и Bar, которые соответственно расположены в доменах Services и Shared. Компоненты экспортируют методы doFoo и getBar, которые могут быть запрошены другими компонентами.
Домены, в свою очередь, регистрируются фреймворком и становятся доступны в пределах процесса, при этом все взаимодействия происходят через ядро.
Кроме того фреймворк предоставляет метод для доступа к компонентам "извне", позволяя центральной точке запуска приложения взаимодействовать с компонентами.
Так же упомянем что существует механизм разделения прав доступа к методам компонентов, о нем позднее.
// first service file aka 'foo_service' class FooService { getServiceConfig () { return ({ require: { BarService: ['getBar'] }, export: { execute: ['doFoo'] }, options: { injectRequire : true } }) } doFoo (where) { let bar = this.BarService.getBar() return `${where} ${bar} and foo` } } export default FooService
// first layer file aka 'services_layer' import { Layer } from 'antinite' import FooService from './foo_service' const LAYER_NAME = 'service' const SERVICES = [ { name: 'FooService', service: new FooService(), acl: 711 } ] let layerObj = new Layer(LAYER_NAME) layerObj.addServices(SERVICES)
// second service file aka 'bar_service' class BarService { getServiceConfig () { return ({ export: { read: ['getBar'] } }) } getBar () { return 'its bar' } } export default BarService
// second layer file aka 'shared_layer' import { Layer } from 'antinite' import BarService from './bar_service' const LAYER_NAME = 'shared' const SERVICES = [ { name: 'BarService', service: new BarService(), acl: 764 } ] let layerObj = new Layer(LAYER_NAME) layerObj.addServices(SERVICES)
// main start point aka 'index' import { System } from 'antinite' // load layers, in ANY orders import './services_layer' import './shared_layer' let antiniteSys = new System('mainSystem') antiniteSys.onReady() .then(function() { let res = antiniteSys.execute('service', 'FooService', 'doFoo', 'here') console.log(res) // -> `here its bar and foo` })
Как видно из кода, компоненты являются обычными объектами, с несколькими дополнительными методами, домены используют экземпляры компонентов, а центральная точка импортирует слои и обращается через системный вызов к конкретному компоненту в конкретном домене.
Кроме того, вызов методов в компонентах-зависимостях — это простой вызов метода объекта, если он синхронный — его можно вызывать синхронно, если асинхронный — то в соответствии с реализацией метода, фреймворк не накладывает никаких ограничений в этом отношении.
В репозитории имеются дополнительные примеры сервисов.
" — А что с накладными расходами?"
Основная работа фреймворка происходит в момент запуска приложения, когда происходит разрешение всех зависимостей. Время задержки будет зависеть от размеров системы, но в целом оно незаметно. Дополнительные задержки возможны при асинхронной инициализации компонентов, тут задержка будет обуславливаться скоростью выполнения задачи (коннекта к базе, открытия порта и т.п.).
Накладные расходы стартовавшей системы минимальны. Выполнение метода другого компонента происходит как выполнение поиска функции-обертки по ключу в словаре, после чего выполняется непосредственно метод компонента из функции-обертки.
Теперь о механизмах прав доступа. Во-первых компонент, экспортируя методы, явно указывает категорию экспорта — 'read', 'write', 'execute', таким образом можно разделить их по степени воздействия на систему. Во-вторых слой, регистрируя компонент, указывает маску доступа к компоненту, например '174' — говорит о том, что системным вызовам доступны только методы категории 'execute', компонентам, находящимся в том же домене — полный набор прав 'read', 'write', 'execute' и компонентам из других доменов — только методы категории 'read'.
Следовательно, метод на запись, экспортированный компонентом в одном домене, не может быть вызван компонентом в другом домене. Если ошибочно записать подобную схему в зависимости — фреймворк откажет в ее разрешении.
Фреймворк имеет помощник для legacy-кода, который может облегчить процесс переноса кода.
Кроме того дизайн фреймворка может помочь упростить отладку системы. Имеется дебагер процесса разрешения всех зависимостей, с его помощью станет понятно где разрешение зависимостей выдает ошибку.
Важной особенностью фреймворка так же является то, что есть возможность в любой момент включить аудит системы, получая подробную информацию о том, какие компоненты взаимодействуют между собой и какие параметры при этом передаются.
И в дополнению ко всему система может предоставить текущий граф зависимостей, который несложно визуализировать.
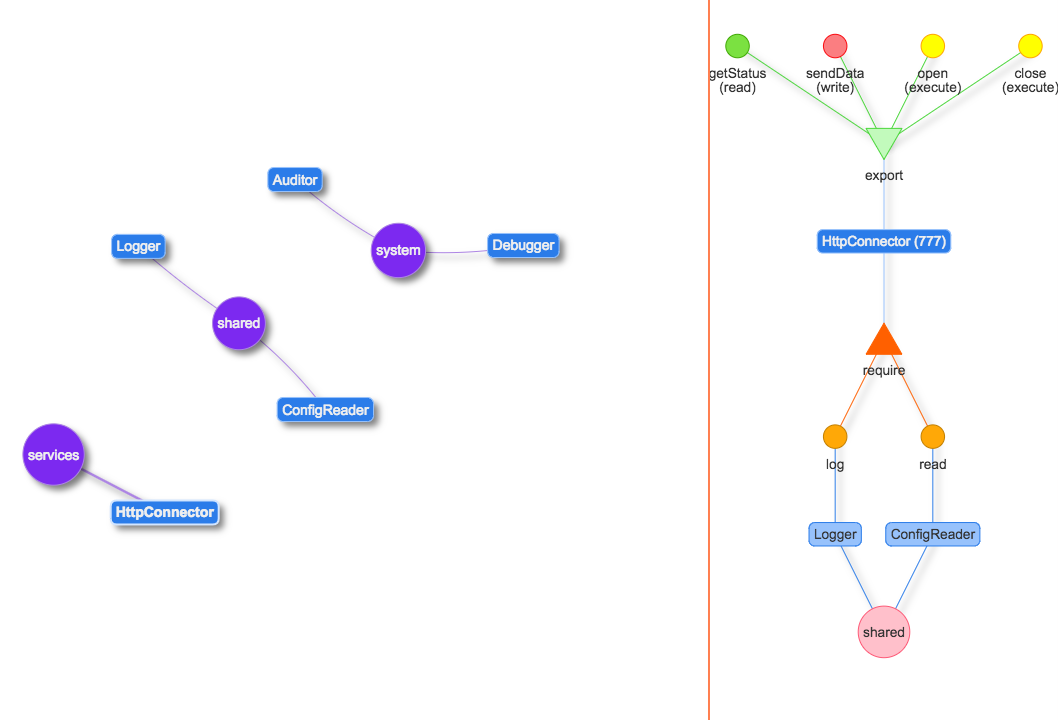
Есть простейший помощник для визуализации, Antinite Visual Toolkit. Данная библиотека была сделана как пример возможной визуализации, возможно не самый удачный.
Вот так вкратце выглядит концепция нано-сервисов, реализация фреймворка и тулкита к нему.
Если у вас есть вопросы, пожелания, дополнения, критика и предложения — пожалуйста отразите это в комментариях. Кроме того у проекта имеется gitter-чат. На данном моменте мне очень нужна обратная связь для улучшения прототипа.
Antinite доступен на github, и для установки через npm под лицензией MIT. У проекта имеется подробная документация и набор тестов.
PS. В настоящее время активно разрабатывается рабочий проект с использованием данного фреймворка, подробности, увы, разгласить не могу, но проблем на данном этапе не выявлено.
Архитектура позволила вынести в отдельный процесс оказавшуюся ресурсоемкой задачу, полностью переиспользуя часть общего кода и внедрив в зависимости мок сервиса, скрывающий межпроцессное взаимодействие.
