Event storming — метод, который смещает акцент у событий с технического на организационный и бизнес уровни и помогает создать устойчивую модульную систему. Он нередко используется в контексте моделирования микросервисов. Но как применить его на практике?
При создании системы на микросервисах можно легко получить распределенный монолит. Event Storming не уберегает от этого на 100%, но позволяет существенно снизить риск этого события. О том, как именно этого добиться, рассказал в своем докладе на конференции TechLead Conf 2020 практикующий консультант по архитектуре, процессам разработки и продуктовым практикам Сергей Баранов.
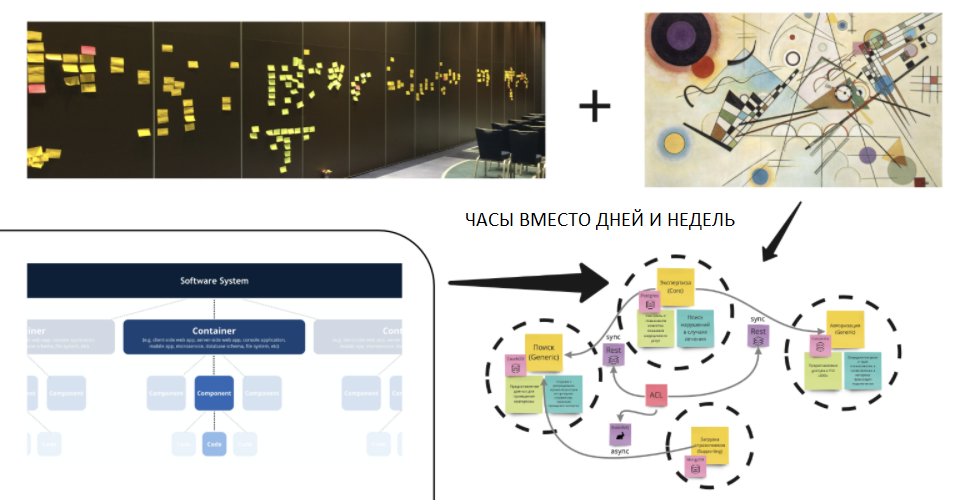
Как строить нашу микросервисную архитектуру быстрее, а команды делать более автономными при помощи Event storming?
Автор метода, итальянский программист Альберто Брандолини, дал свое определение.
Event storming — это увлекательный способ собрать вместе разработчиков и экспертов в бизнесе для быстрого, совместного исследования сложной предметной области бизнеса. Часы вместо дней и недель.
Ключевое слово здесь — «исследование», потому что вначале Event Storming выглядит как своего рода хаос, со временем обретающий четкую структуру.
Альберто Брандолини достаточно смело заявил, что подобное исследование может занять часы вместо дней и недель. И практика показывает, что это действительно так. На момент написания статьи, Сергей провел сессии Event Storming уже более 150 раз: для больших предметных областей, для небольших стартапов и для крупных энтерпрайзов. И каждый раз это работало достаточно эффективно.
Структура
Структура Event Storming достаточно проста и многое взяла из DDD:
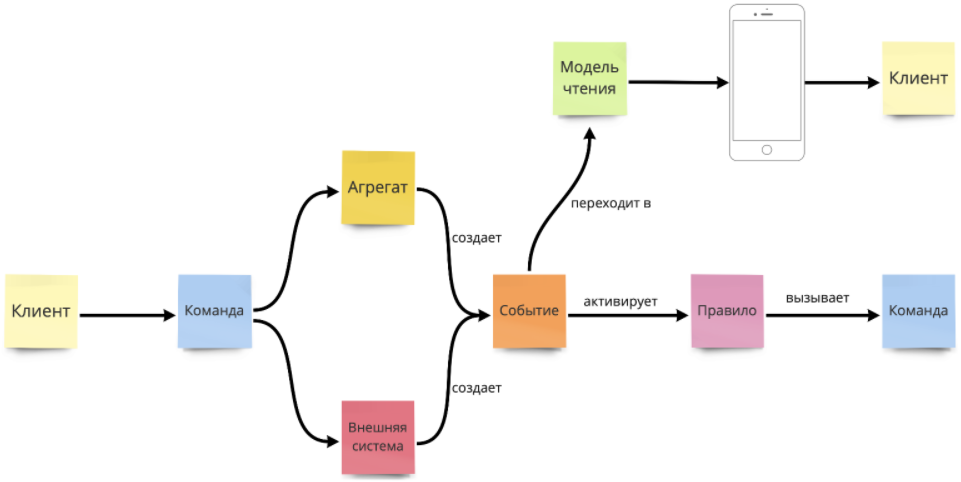
Клиент инициирует выполнение команды. Команда всегда формулируется в будущем времени: это запрос на выполнение действия. Оно еще не выполнено и может быть отменено.
Допустим, речь идет о том, чтобы добавить товар в корзину. Команда приходит в агрегат (термин из DDD), либо уходит во внешнюю систему. Если команда может быть выполнена без нарушения инварианта агрегата, создается событие. Событие — это факт и действие, произошедшие в прошлом. В отличие от команды, событие не может быть отменено («Товар добавлен в корзину»).
На основе событий, например, обновляется модель чтения, цель которой — помочь пользователю в принятии решений («Купи еще на 1000 рублей и получи скидку 10%») и выполнении последующих команд. Или же событие может активировать некое бизнес-правило. Которое, в свою очередь, вызовет команду, и цикл повторится.
Альберто Брандолини называет эту схему «картинкой, которая объясняет все». По большому счету, так и есть: при повторении таких цепочек и получается наш конечный дизайн.
Процесс
На сессию приходят и технические и бизнес-специалисты. Вместе они размещают происходящие в бизнесе события в хронологическом порядке, попутно уточняя их смысл и избавляясь от предположений о происходящем в бизнесе.

Это абсолютно все события, происходящие в домене. Их могут быть сотни, и даже тысячи.
Примеры событий:
Товар добавлен в корзину;
Товар оплачен;
Доставка оформлена.
Затем к этим событиям мы приписываем команды.

Все очень просто. Товар добавлен в корзину. Команда, которая относится к этому событию: «Добавить товар в корзину».
Постепенно идет усложнение и появляются определенные бизнес-правила.
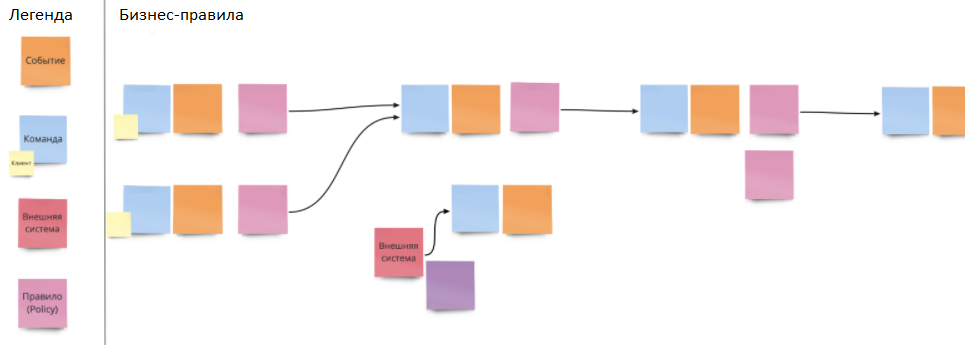
Здесь очень хорошо помогают именно представители бизнеса, потому что программисты, по сути, переводят эти бизнес-правила в код. И важно здесь не то, как технически это выглядит, а то, как продукт работает в реальном бизнесе.
Появляются агрегаты. Агрегат — это сущность или кластер сущностей, которые мы рассматриваем как единое целое. Допустим, у сущности «Заказ» есть свои сущности: «Товары», «Адрес доставки» и пр. Наш интерес в том, что агрегат является транзакционной границей и отвечает за целостность и непротиворечивость всех данных, которые в него входят.
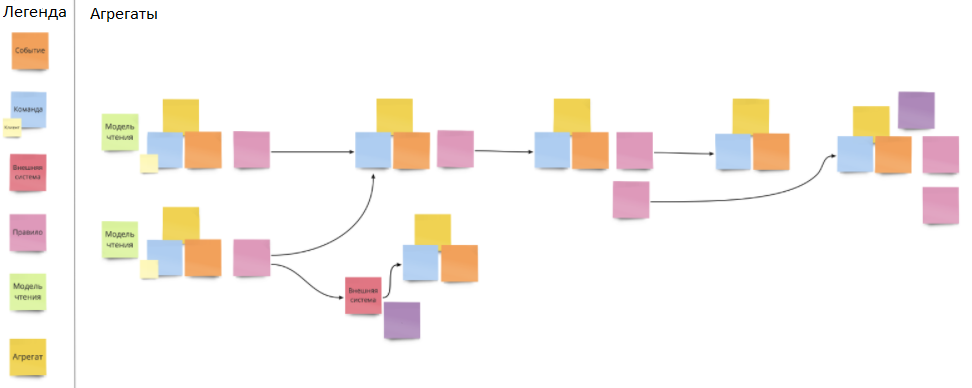
В нотации Event Storming агрегаты обозначаются желтыми стикерами. Вначале мы можем оставить эти стикеры пустыми, без названия. Мы пока не знаем, что это за агрегат. Просто будем собирать вокруг него те команды и события, которые, как нам кажется, должны обрабатываться вместе. А уже потом назовем его.
Агрегаты сбиваются вместе и образуют то, что в терминах DDD называется ограниченными контекстами. Они представляют из себя модель + общий словарь.
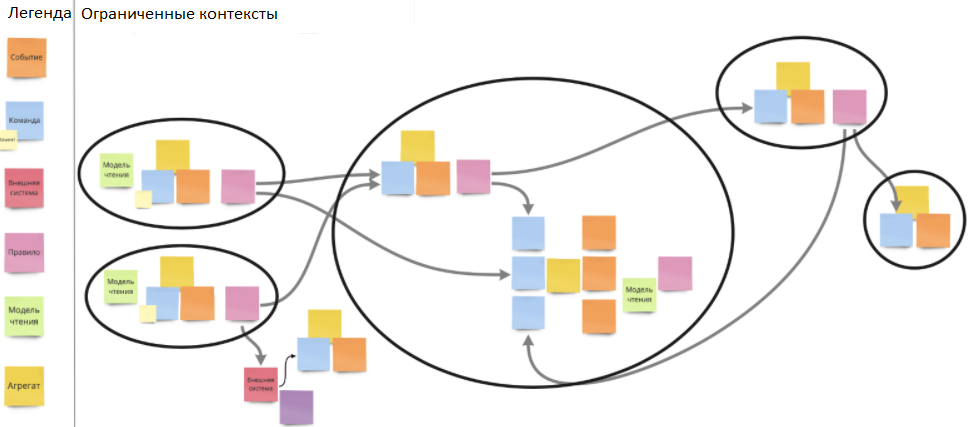
Ограниченные контексты должны быть максимально автономными. Такая автономность помогает в их рамках делать независимые друг от друга микросервисы. Хочу показать вам, как это выглядит на живом примере.
Стикеры на скрине мелкие. Но такая детализация выбрана не случайно: я хочу продемонстрировать объем происходящего.
Над этой схемой работали около пяти часов. Вначале выявили события, затем команды, добавили бизнес-правила. Со временем результатом командной работы стал сбор некоторых команд и событий в контексты. Например, контекст работы с ботами, контекст диалога с клиентом, контекст закрытия заявки.
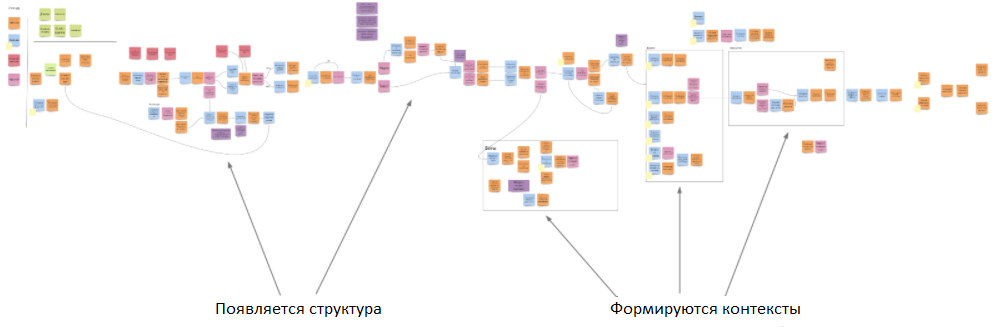
В этом примере показана работа службы поддержки. Это промежуточный вариант. Но даже тут видно, что стратегия уже начинает вырисовываться.
В оффлайн это выглядит примерно так: перед нами огромная пустая стена, и около 40 человек генерируют:
События — оранжевые стикеры;
Команды — синие стикеры;
Агрегаты — большие желтые стикеры. В данном случае агрегаты являются нашими потенциальными микросервисами.

Некоторые микросервисы включают в себя несколько агрегатов. Преимущество в том, что все они могут разрабатываться автономно. Можно было сделать это и в Big Design Up Front, долго собирая предметную область с помощью архитектора или гвардии аналитиков. Но, собравшись все вместе, участники получили этот результат примерно за 8-9 часов.
Выглядит немного хаотично, но все великолепно оцифровывается, складывается в общую базу знаний, и у любого сотрудника компании есть доступ к этим данным.
Контексты
Посмотрим на контексты чуть ближе:
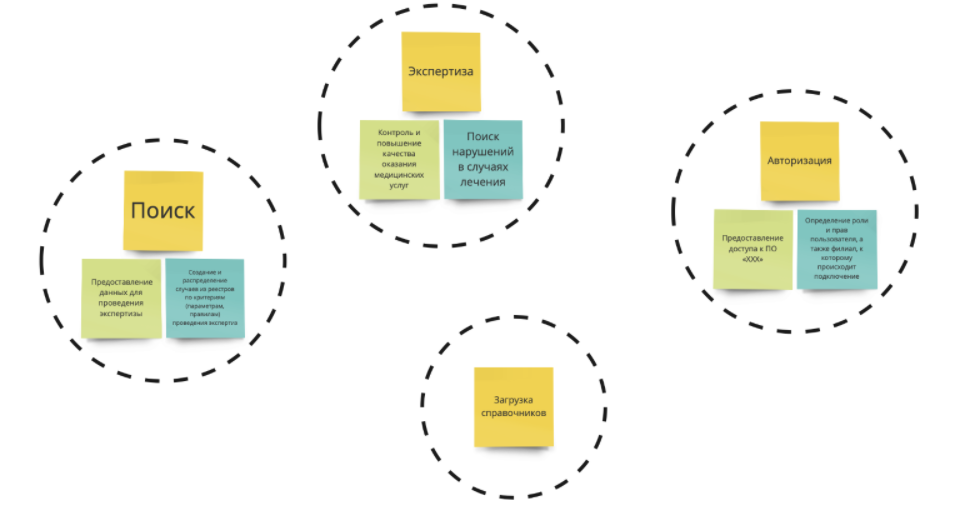
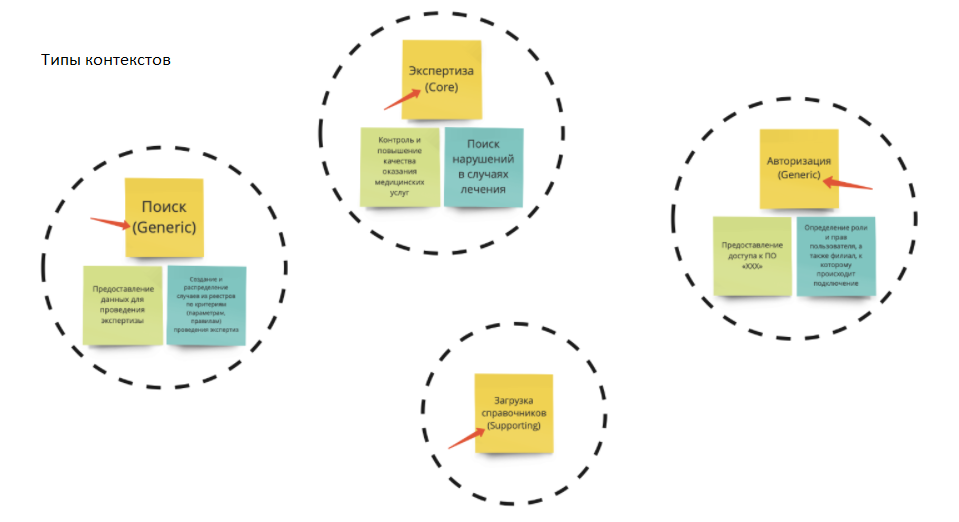
В примере выше речь идет о страховании. Разберем 4 контекста:
Поиск;
Экспертиза;
Авторизация;
Загрузка справочников.
У них есть свои цели и своя ответственность. Например, цель экспертизы — контроль повышения качества оказания услуг, а ответственность — это поиск нарушений.
Проставим типы этих контекстов. В общем случае их три:
Core — основной контекст;
Supporting — поддерживающий контекст;
Generic — общий для всех.
Зачастую типы достаточно сложно определить. Люди в команде начинают о них спорить. Чтобы этого не произошло, можно использовать простую практику:
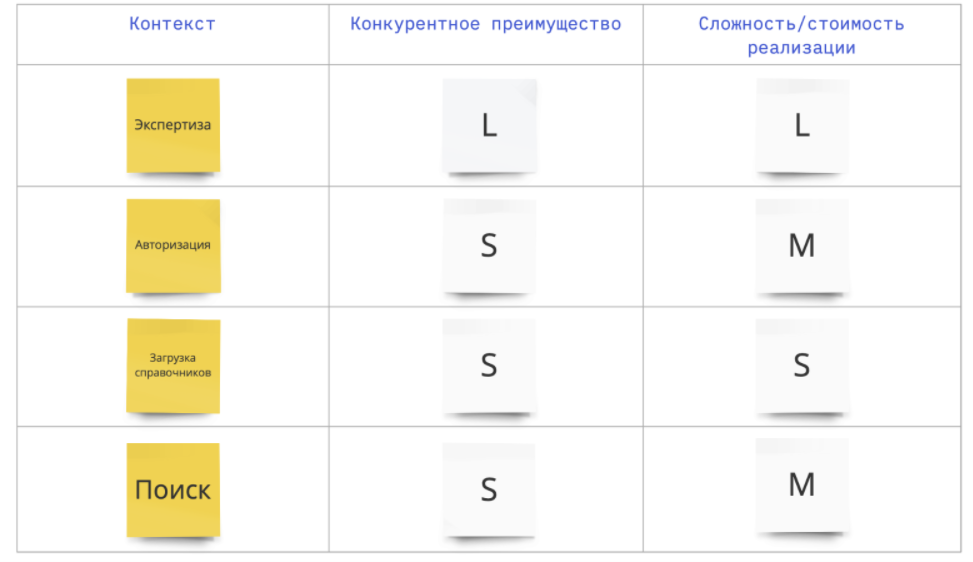
Выписываем контексты и спрашиваем, насколько «Экспертиза» обеспечивает наше конкурентное преимущество/насколько сложна ее реализация:
L — сильное влияние/сложная реализация;
M — среднее влияние/средняя сложность;
S — слабое влияние/низкая сложность.
Получаем набор значений. Нас интересует в первую очередь строчки с двумя L — то, что обеспечивает конкурентное преимущество, но может быть сложно реализовано. Кажется, что мы не можем отдать это на аутсорс или использовать внешнее ПО: это сердце нашего бизнеса.
Дальше проставляем:
Core туда, где есть, как минимум, (L,L), (L,M);
Supporting туда, где нет особого конкурентного преимущества. В данном случае это загрузка справочников;
Generic (S, M).
Получаем такую картинку:
Казалось бы — зачем нам все это нужно?
Решения по разработке
По очень простой причине: мы можем принять ряд решений.
«Экспертиза» останется во внутренней разработке. Здесь будут сосредоточены основные микросервисы с основной бизнес-логикой.
Загрузку справочников есть смысл либо отдать на аутсорс, либо оставить для прокачки джуниоров.
Generic (поиск и авторизация) — это то, что можно использовать повторно. Здесь открываются новые варианты: купить решение, закрутить его в контейнер, и пусть оно там живет с небольшой кастомизацией.
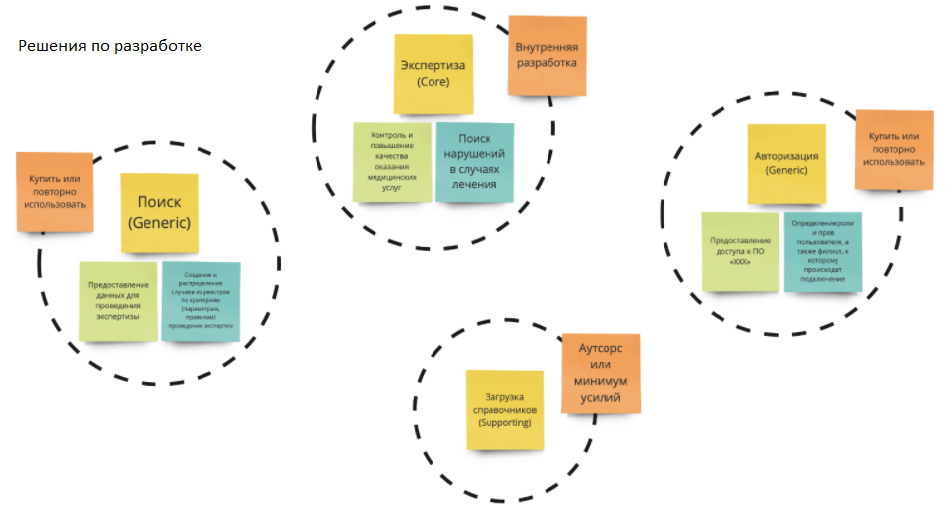
Таким образом мы не распыляем силы, а видим, что у нас есть авторизация, экспертиза, поиск, загрузка справочников; понимаем, на что мы бросаем максимальное количество усилий и где будем прорабатывать предметную область дальше.
Стили коммуникации
Определяем, какими должны быть связи:
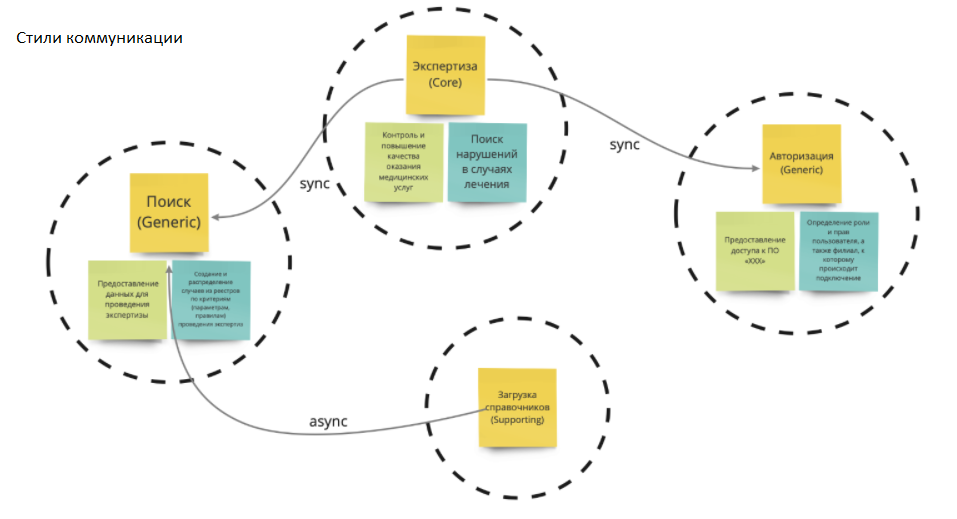
Это делается достаточно быстро. Здесь же мы обычно рассматриваем нефункциональные требования.
Например, для экспертизы они таковы: как часто экспертиза будет обращаться к авторизации, и какую пропускную способность должна авторизация держать.
У нас уже есть предметная область для экспертизы. И мы можем сказать, каким из этих элементов предметной области требуется постоянная авторизация доступа, или какие объемы данных будут передаваться из справочников. То есть появляются интеграционные связи. И на то, чтобы этого добиться, потребовалось меньше двух дней.
Протоколы взаимодействия
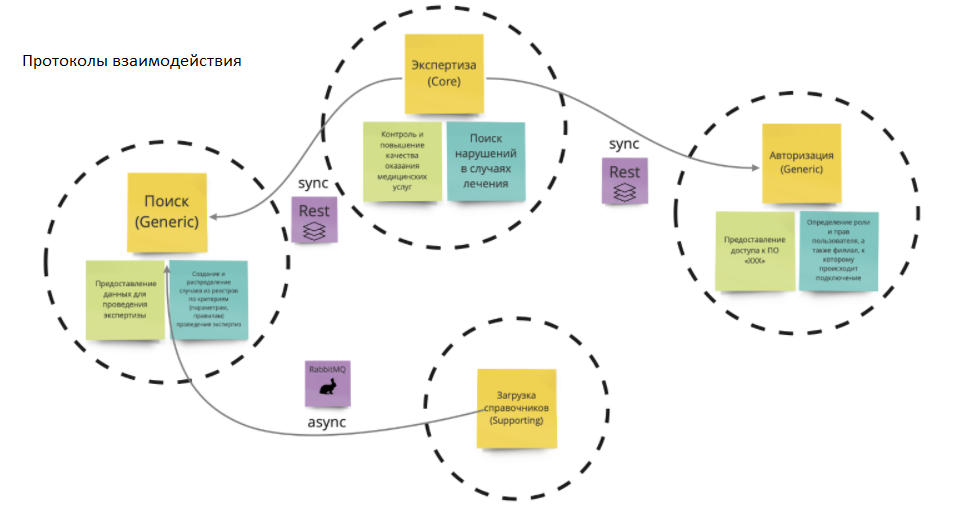
В качестве протоколов взаимодействия мы будем использовать Rest и RabbitMQ. Почему RabbitMQ? При загрузке справочников понадобится трансформация данных, не только чисто техническая, но и обеспечивающая защиту предметной области от протекания абстракций.
В DDD для защиты модели мы можем использовать шаблон ACL (nti-Corruption Layer). По сути, это дополнительный слой адаптеров между контекстами, позволяющий осуществлять взаимодействие в обоих направлениях и снимающий зависимость контекстов друг от друга. То есть он защищает вашу предметную область, чтобы туда не попадали специфичные для других контекстов данные.
Сами справочники могут храниться абсолютно в любом виде. Важно, чтобы в конкретных микросервисах мы работали со своей предметной областью, то есть брали из справочников только то, что нам нужно, и переводили эти данные в нашу предметную область. А еще важно придерживаться простого правила: именовать микросервисы и переменные в коде терминами, понятными бизнесу. Тогда нам не нужно будет переводить данные из одного языка в другой. Эти термины мы выявили еще на этапе поиска событий, команд и агрегатов.
На протоколы взаимодействия по-прежнему ушло меньше двух дней.
Детали реализации
Ограниченные контексты мы строим так, чтобы они были автономными. Внутри каждого из них мы можем использовать легковесные подходы, вроде C4 от Саймона Брауна, для того, чтобы спроектировать каждый из этих контекстов в отдельности.
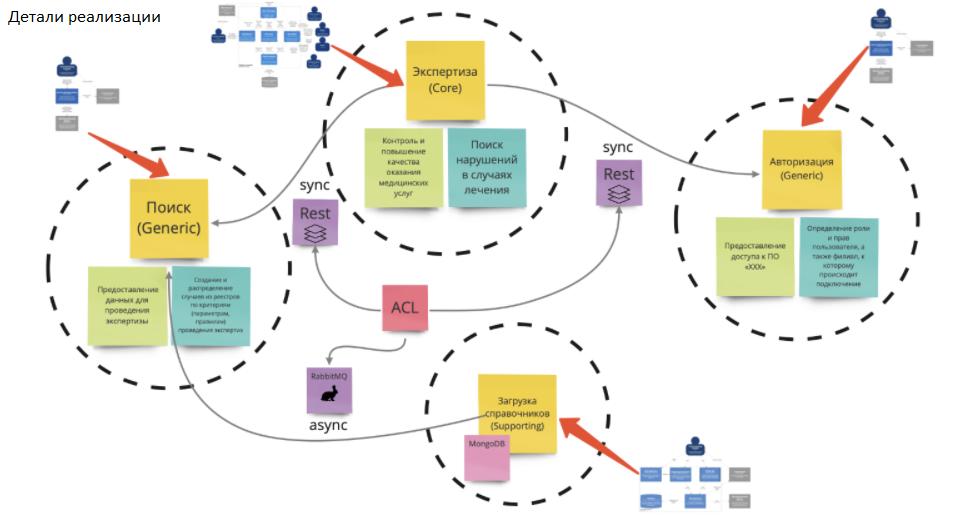
Важно, что внутри каждого из контекстов команда самостоятельно может провести дальнейшую декомпозицию и проектирование. При том, что на ранних этапах мы уже определили основные нефункциональные требования.
У нас есть общая картинка, сформулированные архитектурные ограничения. В рамках таких ограничений команды могут самостоятельно принимать инженерные решения.
Команды закончили работу. Допустим, каждая решила использовать свою собственную базу данных:
Экспертизе подходит Postgres;
Авторизации — Cassandra;
Загрузке справочников — MongoDB;
Для поиска будем использовать CockroachDB.
У нас появляется свобода выбора и возможность принимать решения внутри своей команды. Почему так? Потому, что за рамками контекста находится четко определенный интерфейс.
На детали реализации ушло не более трех дней. И то только потому, что нужно посмотреть, соответствуют ли базы данных нашим нефункциональным требованиям.
Сервисы должны быть построены вокруг бизнес-потребностей и развертываться независимо. Event Storming позволяет очень быстро определить бизнес-потребности и достаточно быстро, через практики DDD, перейти к техническому решению.
К чему мы идем?
При помощи связки Event Storming + Domain-Driven Design получилось быстро и эффективно получить независимые контексты, в рамках которых могут жить наши микросервисы. Вполне вероятно, что в будущем появятся новые актуальные практики. Но на текущий момент именно благодаря Event Storming есть возможность сделать это быстро и автономно.
Выводы
Event Storming помогает быстро получить стратегический дизайн, определив границы, в рамках которых технические решения можно принимать автономно;
Если преднамеренно не нарушать границы на уровне реализации, то зависимости не появятся;
А все мы помним, что в разработке нас тормозят две вещи: зависимости и технический долг. Даже если мы не понимаем, что разрабатывать, мы все равно можем написать это очень быстро:) Правда, не факт, что это будет именно то, что нужно клиенту. Когда же появляются зависимости, скорость разработки падает, ведь нам требуется координация.
За счет автономности значительно упрощается управление техническим долгом;
Появляется возможность эволюционного развития к целевому видению.
Event Storming — это не та сессия, которую можно провести, и забыть о ней. И бизнес, и архитектура развиваются. Поэтому приходится задействовать дополнительные сессии, дополнять события, проверять агрегаты.
Но повторные сессии занимают еще меньше времени. Ведь получается поддержать общее видение и общую ментальную модель. Наверное, это самое важное, что дает Event Storming.
Узнать еще больше подробностей о современных решениях для микросервисов, вы можете подписавшись на канал автора доклада, Сергея Баранова.
Хотите стать спикером TechLead Conf 2021? Если вам есть что сказать, вы хотите подискутировать или поделиться опытом — подавайте заявку на доклад.
Следите за нашими новостями в Telegram, Twitter, VK и Fb и присоединяйтесь к обсуждениям.
