В июне Яндекс опубликовал нейросеть YaLM 100B. Нейросеть умеет генерировать тексты. А это очень мощная вещь, можно попробовать массу всего полезного (и не очень) создать с ее помощью, от сюжетов для книг, игр и приложений, заканчивая рерайтом статей или того хуже, дорвеями.
Эта штука имеет лицензию Apache 2.0. Но чтобы запустить нужно ~ 200GB GPU видеопамяти!
И еще есть нюанс, проверить нейронку в работе, не так-то просто. Яндекс не предоставили ни демок, ни инструкций, как запустить бюджетно YaLM 100B. Пока все ждут урезанную или онлайн версию, я познакомился с ней поближе. Об этом и лонгрид.
Спойлер, дальше рассказ пойдёт о том, через что я прошёл и результаты. Исходников не будет.
Почему я в это ввязался?
Я оставил корпоративную карьеру в этом самом Я, чтобы поиграться в алготрейдинг, торговых роботов и ML. Писал детальнее здесь: https://habr.com/ru/post/672274/
В торгах финансовые прогнозы это все. Пришла мысль, что скажет нейросеть, если ей в контекст задать новость или другие финансовые вводные.
YaLM 100B это реально крутая работа ��ирового масштаба, и я просто не могу ждать, пока появится более доступная версия.
А у меня сейчас куча свободного времени и энергии, чтобы разобраться, как бюджетно запустить YaLM 100B простому смертному, не обладающему 200 GB видеопамяти.
Я реально заинтересован ее использовать. Попробовав в облаке, результатом остался доволен. Не идеально, конечно, но сильно зависит от контекста. Примеры выложил на opexflow.com)
Первые шаги
Первым делом я перечитал интернеты, в которых потенциальные пользователи огорчены тем, что нельзя попробовать.
Но были и такие шальные как я, кто верил, что всё возможно. Статья от арбитражников вдохновила меня, что запустить возможно (на самом деле нет, либо они смогли распилить слои на части, либо история что-то умалчивает).
Подкрепилась моя уверенность и вот этими комментариями


Просто нужно сделать так, чтобы оно последовательно обрабатывалось на GPU, а хранилось где-либо ещё. Осталось дело за малым. Подключить.
Как и положено, я посмотрел доки, посмотрел код на питоне, подумал что я фронтендер, у меня лапки и мне с этим не справиться. Потом вспомнил, что я фундаментально обученный магистр системный программист и принялся за дело.
Две недели боли, слёз и страданий
Первыми делом, докупил NVMe на 1Tb, чтобы было место и развернуть, и выкачать, и сгрузить туда всё во время выполнения. Так говорилось в статье от арбитражников.
Нахрапом взять и приткнуть код не получилось. Но через время код в YaLM-100B мне стал как родной. От незнания предметной области пришлось обложиться документацией и дебажить по строкам не только его, но и часть библиотек. И сравнивать результат в основном репо, и с моими изменениями.
Это всё было приправлено тем, что всё выполнялось достаточно долго, пока я не нашёл что можно на первом этапе безболезненно выбросить чекпоинты и уменьшить до одного слоя. Благодаря чему всё стало запустаться за минуту, а не за час.

Но, изо дня в день у меня что-то получалось. Пару раз хотел бросить, но мне было надо и я не сдавался. Кроме того, по репозиторию были разбросаны напутствия, что всё получится.
Например, в репозитории лежит файл с конфигом zero offload. Который нужен, чтобы запуск модели не падал по памяти, а выгружался в NVMe. Оставалось только понять, куда это приткнуть.
Настал момент, когда я
перечитал всю документацию;
раздебажил каждую строку;
знал не только что в какой переменной лежит, но и то что моя сборка буква в букву совпадает с оригинальным результатом.
Появилась 100%-я уверенность, что я смогу запустить полную сборку, это лишь вопрос времени. Себе я все доказал и пришло время подключить здравый смысл, а стоит ли продолжать?
Юзкейс я видел следующий.
Я хочу дополнять прогнозы торгового робота с помощью нейронки. Пишу тезисы, выгружаю файл в контекст и через какое-то адекватное время получаю результат. Ставку делаю на качество текста, а не скорость.
Отложив разработку в сторону менеджер вошёл в чат.
Сколько нужно вложить в железо, чтобы выполнялось за адекватное время?
Это должен быть сервер или облако? А на домашнем железе?
Нанять человека с нужными скиллами на эти деньги не дешевле ли?
Понятно было только одно, что на домашнем компе не собрать. Нужно 256 ГБ RAM. На nvme оно будет выполняться вечность. Вкладывать в железо с непонятным результатом мне не подходило. Особенно с учётом того, что есть опция обратиться к человеческому ресурсу.
Прикинув всё это, решил выжать максимум из текущего конфига и продолжить исследования. Докупил 64 Гб RAM, чтобы ускорить запуск и на этом вложения решил прекратить.
Заработало!
Дальше стало проще. И даже ночные зависания ПК починил. Всего-то надо было прикрутить вентилятор над nvme памятью, которая спряталась под видеокартой.
Как и предполагал, всё получилось. Даже нашёл два решения, одно супер простое из нескольких строк. Но требующее х2 времени и памяти при старте. Второе сложнее, зато без вот этих неоптимальностей.
Теперь я тоже могу говорить, что добавить zero offload очень просто.
Это "просто" мне стоило:
Время: две недели (на раздебажить с самых низов имея поверхностные знания в python и ��олное отстутствие знаний про используемые библиотеки).
Деньги: ~ 35к рублей (nvme, ram, cloud).
За это я получил опыт в python, Megatron-LM, deepspeed, zero offload. Ну и само собой радость от выполненной задачи + знания и опыт для новых экспериментов с ML.
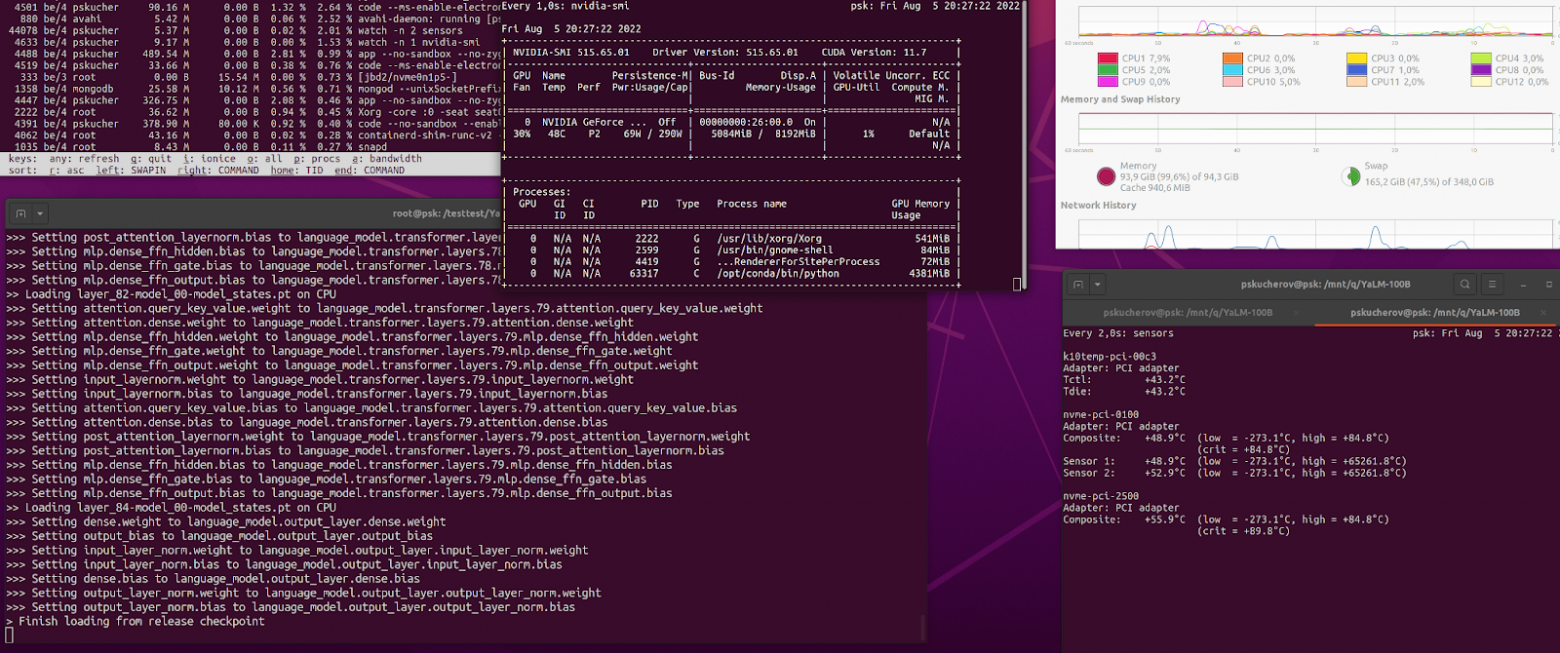
Итак, мы находимся в точке, когда можем запустить YaLM 100B на любом ПК, даже домашнем. Но смысла в этом нет, т.к. расчёт идёт по слоям.
Как я понял, если их порезать и считать только то что в ОЗУ, то будет быстрее. Но когда часть лежит в nvme, пусть даже пару Гб, то расчёт становится вечным. Т.к. nvme не умеет быстро работать с непоследовательными чтениями-записями, скорость падает в лучшем случае до сотен МБ, а в критические моменты вообще до десятков.
Для понимания, простой эксперимент. Берём 1 слой (1 / 80 от всей модели, ~1.2 млрд. параметров), отправляем в GPU без zero offload. Оно считается моментально, за единицу времени. Берём этот же слой, включаем zero offload cpu и всё то же самое считается в 10 раз медленнее, т.к. задействована ОЗУ. А теперь включаем zero offload nvme и всё считается в 100 раз медленнее, т.к. проходит через nvme. Точных значений у меня нет, но порядки примерно такие. Напомню, это идеальные условия, когда всё помещается в память GPU. А теперь представим, что мы пытаемся на nvme запускать полную модель из 100 млрд параметров, когда в память всё не помещается. Это будет оооочень долго. Для сравнения, один текст на одной видеокарте + CPU offload генерируется порядка 20-40 минут. Боюсь представить сколько будет на NVMe, неделя?
Тут, кстати, возникает вопрос к статье от арбитражников. Как им удалось? =)
Пока остаётся надеяться на вот это.

Вместо выводов:
Все возможно.
Подробная инструкция по запуску YaLM 100b в облаке на GPU. На CPU ещё нужно доразбираться.
Качество текста можно оценить здесь (как и обещали, чем лучше контекст, тем лучше результат).
Открыт к обратной связи и взаимодействию по проектам.
Если кто-то учится фронту, хочет пообщаться, парнопопрограммировать, покодревьювить и получить адекватный фидбек — велкам.
Поддержать меня можно: донатом на развитие алготрейдинга, начинающих фронтендеров и опенсорса http://sobe.ru/na/S2d2i0i6X1u0
Лайки и репосты статьи также приветствуются, а ссылка на автора обязательна.
