Комментарии 80
Опять же, не злорадства ради, до сих пор нельзя sequence'ы по delete удалять, таблицы можно, причем каскадно, а ключи приходится через консоль и drop sequence: https://youtrack.jetbrains.com/issue/DBE-2750
Обратил внимание на упоминание об этом в статье: "Добавили Drop в контекстное меню многих объектов". Полез проверить еще раз и действительно — уже можно, значит этот тикет можно закрыть.
вот ещё тоже закройте :)
@JetBrains посмотрите пожалуйста на HeidiSQL и сделайте такую же удобную Database Manager…
1) нельзя создать базу, можно только открыть уже созданную
2) нельзя сделать дамп базы с данными
3) когда добавляешь новую запись, то для того чтобы она применилась нужно создать новую строку, потому удалить ее. Видимо нужна какая-то кнопка «apply»
4) Не исполняются много запросов за один раз.
И добавьте, пожалуйста, поддержку MongoDB. Очень не хватает.
Спасибо.
2) На PostgreSQL и MySQL можно.
3) По Ctrl+Enter происходит отправка данных в базу. Вы точно пробовали 2016.3?
4) Приведите пример, пожалуйста. Потому что, вообще, исполняются.
5) Монги пока нет в ближайших планах.
2) Как это сделать? Не нашел такой строчки.
3) Спасибо, помогло.
Записал видео проблемы 4 и 2 пунктов.
https://cloud.mail.ru/public/AEEa/C5t5yrAsT
4) насколько я понял, имеется в виду этот баг
Пользуюсь ems много лет. у datagrip много крутых фишек, но каких-то самых используемых визардов не найти (
Спасибо за фидбек )
Нравятся ваши продукты, особенно DG, как всегда есть нюанс — синхронизация огромных схем.
Работаю с базой, в одной схеме которой есть 50к+объектов: 6к таблиц, 12к представлений, 25к пакетов и остального понемножку. Полная синхронизация почти всегда заканчивается с одним результатом — DG зависнет на Applying Changes.
Но это полбеды, если начать синхронизироваться с другой схемой внутри одного подключения (к примеру SYS), то после завершения Intoinspector примется за полную синхронизацию той огромной
Мне трудно судить по скорости работы, потому как сейчас работаю только с двумя базами, у одной простая структура, там изначально проблем не было, а вторая — эта вот эта:
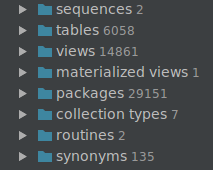
С ней трудно вести подсчеты по времени, полная синхронизация этой схемы прошла только один раз: на Win 10, 2016.3 (x64), Oracle JDK 8u111.
Вчера ночью запустил на Ubuntu 16.04, 2016.03, утром все еще выполнялся Applying Changes, после завершении работы "интраинспектора" интерфейс DG повис
Или это мультитенантная система?
Напиши пожалуйста, помогло ли.
Поигравшись с настройками:
Load Sources --> None
Auto Sync --> Снял чекбокс (почему сразу я не отключил — непонятно)
Запустил обновляться схему и… опять все повисло на этапе Applying Changes, полез в логи и обратил внимание, что раз в 5 секунд создаются файлы threadDump (пример)
В принципе рабочий workround уже для меня был:
- запустить синхронизацию
- остановить ее после индексов
Так как данная база — это коробочный продукт (АБС банка), в котором структура не так часто меняется, то меня вполне устроят подсказки по полям таблиц/представлений.
Однако интерес заставил поэкспериментировать, а именно поиграться с JDK. Поменял на версию от Oracle и о чудо — синхронизация завершилась. Решил продолжить:
- Снес подключение (для чистоты эксперимента)
- Создал новое подключение
- Настроил Load Sources / Auto Sync
- Добавил две схемы
- Нажал синхронизировать и ушел по делам
по возвращении в Event Log нашел следующую запись:
27.11.16 14:13 @TEST: Synchronization successful (25m 47s)Oracle JDK:
DataGrip 2016.3
Build #DB-163.7744.4, built on November 18, 2016
JRE: 1.8.0_112-b15 amd64
JVM: Java HotSpot(TM) 64-Bit Server VM by Oracle Corporation
Bundled openJDK
DataGrip 2016.3
Build #DB-163.7744.4, built on November 18, 2016
JRE: 1.8.0_112-release-408-b2 amd64
JVM: OpenJDK 64-Bit Server VM by JetBrains s.r.o
ref https://www.mssqltips.com/sqlservertip/1816/getting-started-with-sql-server-database-diagrams/
А возможно как-то сгенерировать скрипт для создания всей базы для MSSQL? ( только схему хотябы, не данные, но включая таблицы, вьюхи, триггеры и т д)
Я не буду отвечать вам по пунктам — все ваши претензии обснованы. Единственное, что непонятно: про редактирвоание процедур «GUI должен облегчать исполнение запроса.». В любом GUI есть элемент «тело функции», в которой и находится сам запрос, как GUI должен помогать его исправлять?
Что касается возможностей по администрированию, мы знаем, что у нас сейчас их почти нет — надеемся заняться этим в будущем. Про GUI писал выше — отчасти здесь проблему решают Live Templates. Но мы обсуждаем возможность его создания для создания базовых объектов. Кстати, когда создаёте объекты, пробуйте в консоли Ctrl+N (Cmd+O на Маке) → IDE поможет вам сгенерировать простой код для начала.
Вы спрашиваете, зачем вообще такой продукт? У нас уже есть много возможностей, которых нет у многих других инструментов. Редактор данных умеет много, IDE позвоялет генерировать предложения INSERT, UPDATE, а самое главное — делает синтаксический анализ вашего кода и поэтому предлагает исправления и быстрое автодополнение. В этом посте, опять же, написано про то, что DataGrip (и все остальные наши IDE) научился искать вхождения внутри объектов. То есть он в первую очередь для того, кому эти фичи помогают в ежедневной работе. Сейчас это скорее SQL-программист, чем администратор БД. Но мы постараемся сделать так, чтобы продукт стал незаменинмым для всех.
SELECT
ISNULL(-gdol.Mass, ISNULL(gdl.Mass, ISNULL(g1.Mass, ISNULL(sc.Mass, ISNULL(CASE WHEN pol.Operation = 0
THEN -gpol.Mass
ELSE 0 END, 0))))) AS Mass,
ISNULL(-gdol.MetallMass,
ISNULL(gdl.MetallMass,
ISNULL(g1.MetallMass,
ISNULL(sc.MetallMass,
ISNULL(CASE WHEN pol.Operation = 0
THEN -gpol.MetallMass ELSE 0 END,
0)
)
)
)
) AS MetallMass,
FROM ...
ставьте вручную переносы строк — форматирование будет относительно них сделано
А не хотите попробовать "засахарить" с помощью COALESCE
SELECT
COALESCE(-gdol.Mass, gdl.Mass, g1.Mass, sc.Mass, CASE WHEN pol.Operation = 0 THEN -gpol.Mass END, 0)
, COALESCE(-gdol.MetallMass, gdl.MetallMass, g1.MetallMass, sc.MetallMass, CASE WHEN pol.Operation = 0 THEN -gpol.MetallMass END, 0)
FROM ...
Решил опробовать данный инструмент, и сразу воткнулся в проблему соединения с базой по ssh.
В поддержке нашел вот такой топик.
Скажите, есть ли какой-то туториал по этому поводу?
Спасибо!

у вас шлюз (proxy host) по ssh доступен по порту 2345 вместо 22?
ЗЫ: доступ на сервер через root-пользователя это сильно.
если коротко:
на закладке "General" вы даёте настройки так, будто вы находитесь на сервере bastion. А на закладке "SSH/SSL" указываете настройки для входа по SSH на сервер bastion.
туннельный локальный порт DataGrip сам сгенерит случайный
По такому принципу у меня Toad работает.
В данном случае, сообщение об ошибке у меня исчезло и DataGrip начал работать по ssh, после перезапуска компьютера.
Возможно, где-то у меня в системе было что-то не так.
Как usercase:
1) Установил DataGrip
2) Настроил ssh-тонель, получил ошибку
3) Перезапустил систему
4) Соединение по ssh-тоннелю заработало
Не нашел, но было бы круто — распределение объектов по подпапкам, сейчас у нас решается костылями на уровне именования.
Доброго времени суток, очень приятно IDE часто улучшается но в этот раз в списке таблиц и sequence secuance расположена высшее чем остальные по сути список sequence не часто надо хотел предложить расположит группы () по частоте или сделать возможность настроить порядок.
Еще раз спасибо за хороший продукт.
DROP PROCEDURE…
CREATE PROCEDURE…
Теперь, после какого-то обновления, только CREATE PROCEDURE… и запуск (Ctrl+A,Ctrl+Enter) ожидаемо приводит к [42000][1304] PROCEDURE… already exists
Это баг или фича? Какая сейчас рекомендуемая практика для изменения хранимок?
Мы полностью переделали то, как хранятся и отображаются исходники.
И то что, сейчас только CREATE — неудобно. Мы хотим сделать так, чтобы IDE сама понимала что происходит и накатывала миграцию.
в режиме drop-create было удобнее — можно было просто скопировать и вставить куда-нить в консоль уже готовое.
т.е. то, что IDE будет сама понимать надо ли drop или нет конечно класс, но хотелось бы и старый функционал сохранить… хотя бы в виде включаемой опции в настройках
И когда планируется? Ну и да, возможность как-то получить поведение (код) подобный старому лучше сделать опционально — не все доверяют умным программам, особенно если не видят код.
Хорошая программа DataGrip, правда ещё не совсем привык к логике работы с проектами, в смысле обычно в других программах просто подключаешься к базе данных и работаешь, сохраняешь отдельные sql файлы, но не связанные между собой в проекты. Основное преимущество программы в том, что можно работать с разными типами баз данных: MySQL, MSSQL, PostgreSQL и прочее.
Для быстрого изучения структуры чужой базы данных очень удобно использовать ER модели. В DataGrip есть возможность отобразить визуализацию таблиц: Diagrams -> Show Visualisation… При этом отображаются таблицы со всеми своими полями (даже со связями, если связи прописаны на уровне базы данных), практически то, что нужно, однако у отображения есть один большой недостаток, что квадраты (именно квадраты!!! а не прямоугольники) отображающие таблицы излишне большие по ширине, съедают слишком много места, в то время как внутри этих квадратов пустота. В итоге эти квадраты не помещаются на страницу, приходится печатать их очень мелкими и ничего не видно. Т.е. от такой визуализации на выходе ноль! к сожалению.
1. Нельзя ли визуализацию сделать более компактной?
Пытаюсь обойти эту проблему тем, что хочу экспортировать структуру базы данных и скормить полученный *.sql файл другой программе для ER моделирования. Такой возможности в DataGrip не нахожу. Есть экстрактор для экспорта данных, но для экспорта структуры всей базы данных (или отдельной схемы) нет.
2. Нельзя ли сделать экстрактор для извлечения пустой структуры базы данных? Кое-что нагуглил на эту тему (http://www.varuste.net/show_create_table.html), но не знаю куда этот скрипт нужно «засунуть» :)
экспорт структуры, это ПКМ на DataSource (тогда все видимые схемы) или на конкретной схеме и там "Copy DDL".
прямоугольниками они становятся если отключить отображение колонок.
А более удобный вид — ПКМ на диаграмме и там выбрать себе удобный Layout. Я например предпочитаю Organic.
Причём если несколько раз выбрать один и тот же Layout, то внешний вид будет меняться
У меня почему-то при переключении Layout ничего не меняется в отображении, странно.
на следующих версиях планируется ли поддержка mongodb?
Таск создали 10 июня 2014 04:35, он и так имеет наибольшее количество голосов, но до сих пор не взят в работу.
Могу добавить, что мы бы с огромной радостью взяли в команду человека, которому прямо сейчас интересно писать поддержку NoSQL баз и находимся в постоянном поиске.
Релиз DataGrip 2016.3