
Про то, как в Avito работает performance review, я очень много раз рассказывал внутри компании, а этой весной ещё и на двух конференциях — TeamLeadConf и CodeFest. Мы активно вкладываемся в доработку процесса, проводим много экспериментов и собираем кучу полезных данных, поэтому каждое новое выступление стабильно включает в себя какой-то новый контент. Цель этой статьи — не выдать вам готовое коробочное решение, а поделиться всеми практиками и инсайтами, которые мы обнаружили на своем пути.

TL;DR
Статья получилась достаточно объёмной. Чтобы привлечь внимание, вот список того, о чем я рассказываю.
- Из каких этапов состоит процесс performance review в Avito, как писать хороший self review и зачем разбивать респондентов на разные роли.
- Как быть с вопросами анонимности и постепенно приводить команду к культуре открытой обратной связи.
- Какие данные и аналитику мы вытащили из собранных 10.000 оценок.
- Как автоматически определять тех, кто спустя рукава относится к performance review, систематически занижает или завышает оценки.
- Что такое нормализация и корректировка оценок и как это работает.
- Какие бывают стандартные антипаттерны в фидбэке, и как их можно выявить.
- Какой набор шаблонов использовать для быстрого старта в вашей компании и как подходить к вопросу автоматизации процесса.
Введение
Вопрос того, как оценить вклад сотрудника в результаты компании волнует, наверное, практически всех руководителей. Иметь ясную картину в этом вопросе действительно очень круто — мы получаем честный инструмент определения вознаграждения для сотрудников, сравнения команд друг с другом и всё такое. И в первом приближении задача кажется не слишком сложной.
Мы в Avito для целеполагания используем методологию OKR. Это что-то вроде MBO на стероидах. Мы выстраиваем дерево целей всей организации со стратегического уровня и до конкретной команды. Цели определяют ценность для бизнеса или клиента, а ключевые результаты устанавливают измеримые и однозначные признаки достижения целей. Там в комплекте идут ещё разные принципы: амбициозность целей, отвязка от материальной мотивации, публичность, измеримость — но не суть, мой рассказ не об этом, хотя почитать про OKR подробнее сильно рекомендую.
В теории все звучит круто: дерево целей разбивается до конкретного специалиста, мы видим его результаты за квартал и используем их для оценки его вклада. Но на деле, конечно, это так не работает. Когда к достижению цели прикладывает руку вся команда, бывает очень сложно отделить личный вклад каждого конкретного специалиста и оценить его в чем-то конкретном, как того требует методология. Ну ведь и правда — если фича выстрелила и принесла пользу, нельзя сказать, что заслуга Пети в этом в два раза больше, чем Васи. Не в коммитах же мы будем это считать.
И это только одна сторона проблемы. Нельзя забывать еще и о том, что чаще всего деятельность сотрудника заключена не только в его команде. Он может выступать с докладами, помогать другим коллегам с их задачами, продвигать какие-то общие инженерные подходы. И это тоже может как приносить пользу, так и вредить. И еще один момент. Достигать своих целей можно очень по-разному. Кто-то умеет договариваться, уведомлять всех заинтересованных, учитывать интересы других людей. Ну а кто-то другой может идти по головам, мешать другим командам и гнаться только за своими показателями.

Получаем стандартную ситуацию. В теории оценка человека по результатам — это красиво, а на практике при подходе в лоб не работает. С этим я и столкнулся, когда пришел в Avito. У нас было много команд, все работали по OKR, но мы не умели оценивать качество и эффективность работы конкретных людей. Изучив опыт других компаний, мы пришли к необходимости внедрения процесса performance review, который в первом приближении очень сильно напоминал модели, используемые в Google и Badoo. Про Google можно почитать в замечательной книге Ласло Бока «Работа рулит», а про Badoo — почитать статью или послушать доклад Алексея Рыбака. Но, что очень важно, мы не стояли на месте. Взяв за основу готовую модель, мы постепенно, проводя ряд экспериментов и собирая данные, стали её улучшать.
Как работает performance review
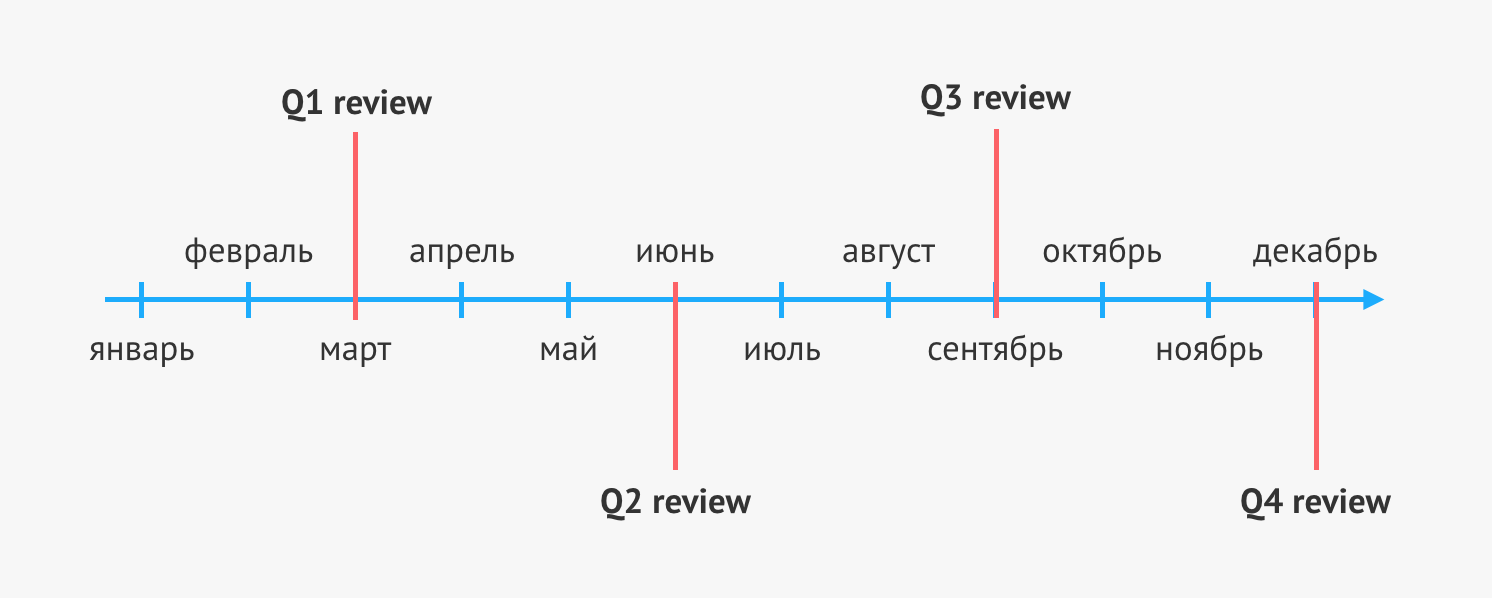
Сейчас performance review мы проводим раз в квартал, и в среднем от начала до конца на это у нас уходит около двух-трех недель.
Процесс состоит из пяти основных шагов:
- подготовка self review,
- определение респондентов,
- запуск процесса,
- проведение оценки,
- подведение итогов.
Self review
В первую очередь оцениваемый сотрудник готовит self review. Это важный момент рефлексии, когда ты садишься и вспоминаешь, чем занимался последние несколько месяцев. Сразу могу сказать, что процесс долгий и болезненный — на это уходит не менее часа-двух. Удобно взять плед, налить какао, отключить уведомления в мессенджере и готовиться к появлению легкого налета депрессии — по себе знаю, что результаты могут довольно сильно расстроить.
Для того, чтобы респондентам проще было работать с вашим потоком мыслей, я рекомендую разбивать self review на четыре секции.
Первая секция. Роли и ожидания. Включает в себя описание ожиданий от ваших позиций и ролей. В нашем случае это документы в Confluence с подробным описанием задач и качеств, ожидаемых от сотрудника. Здесь может быть информация о функциональных ожиданиях от инженеров, описание роли наставника, спикера, участника образовательной программы, юнит лидера или тех. юнит лидера — короче говоря, любой позиции и роли, в которой вы выступаете. Эти данные призваны помогать респондентам писать корректные отзывы и понимать, что от вас ожидает компания.
Вторая секция. Что делали. Краткие результаты последнего периода оценки. Это ключевая секция, в которой вы перечисляете все проекты и деятельность, которой занимались. Это могут быть цели вашей команды, на которые вы фактически повлияли, проекты, над которыми вы работали, детали выполнения ваших базовых функциональных обязанностей. Здесь же стоит упомянуть про свои планы по росту и развитию и подчеркнуть, что вы делали, чтобы достичь желаемого. Всякие дополнительные активности вроде выступления на митапах или участия в хакатонах тоже добавляются сюда. Старайтесь не лить воды, а говорить только о фактах. Если кому-то из респондентов не будет хватать информации для оценки, он спокойно сможет у вас её получить. Пусть люди оценивают факты, а не красивые слова.
Третья секция. Что было хорошо. Здесь вы перечисляете те факты, которые считаете своими основными достижениями и успехами. В основном делайте упор на рабочие достижения — успешно запущенные проекты, налаженные с кем-то взаимоотношения, успешно выпущенные обученные новички. Опять же, не будьте многословными и старайтесь удерживать фокус на главном.
Четвёртая секция. Что было плохо. Максимально открыто перечислите свои основные провалы, то, чем вы сами недовольны и что хотели бы исправить и улучшить в будущем. Сюда можно включать как провалы конкретных поставленных перед вами или командой целей, так и свои личные ошибки. Очень сильно в самокритику ударяться тоже не стоит, фокус никто не отменял.
Посмотрим на несколько хороших и плохих выдержек из self review. Часть была выдумана, часть — взята из реальных примеров.
«Я драйвил разработку мобильной дизайн-платформы, которая уже практически завершена и готова к внедрению в приложение».
Это — хороший пример. Оцениваемый в явном виде указывает, каким проектом занимался и до какого состояния его довел.
«Слишком мало времени уделял наставничеству, из-за чего ввод Иванова в компанию проходит гораздо хуже, чем запланировано».
Это — тоже пример хорошего заполнения. Чётко обозначенная ошибка — мало времени уделялось наставничеству, подчёркнут результат — ввод в компанию нового сотрудника прошел плохо.
«Даже не знаю… Просто работал, задачи делал».
Теперь плохой пример — здесь, в принципе, все понятно и без пояснений — никакой конкретики, нет желания проанализировать свою деятельность и понять, была от нее польза или нет.
«Косячил пару раз, но вроде все норм».
И ещё один пример — оцениваемый намекает, что своим ожиданиям он вполне соответствует, но, чтобы не казаться полностью идеальным, фразой «косячил пару раз» завоевывает доверие респондентов. Здесь — то же самое, что и в прошлом примере — нежелание описать конкретные факты сильно усложняет жизнь тем, кто будет этого человека оценивать.
Определение респондентов
На этом этапе оцениваемый выбирает своих респондентов. Мы их разделяем на четыре группы. Рассмотрим их на примере абстрактного разработчика мобильных приложений Кости.
1. Менеджер
Самым важным респондентом является непосредственный руководитель сотрудника. В случае Кости — это Иван, руководитель группы разработки мобильных приложений. Костя и Иван работают в разных командах, но это не мешает Ване участвовать в оценке.
2. Стейкхолдеры
Следующая группа респондентов — это стейкхолдеры. В случае Кости это два человека — его продакт-менеджер, Павел, и руководитель функции, Егор. Паша постоянно взаимодействует с Костей в рамках работ над целями команды, а Егор периодически подключает Костю к подготовке митапов и работе над open-source проектами. В эту же группу могут входить продакты, лидеры других юнитов — короче говоря, заказчики ваших услуг.
3. Пиры
Обычно самая многочисленная группа — это пиры. Сюда Костя включил всех своих коллег по команде, с которыми он работает над своими задачами — это несколько iOS-разработчиков, android- и backend-разработчик, дизайнер и тестировщик. Пару раз за последние несколько месяцев Костя пересекался по общей задачи с ребятами из платформенной команды, но решил их сюда не включать, потому что поработать вместе они успели сравнительно мало. Также Костя не стал включать тех ребят, с кем он просто ходит на обед и по барам — он понимает, что их оценка его продуктивности не имеет ничего общего с его рабочими успехами. Костя молодец, будьте как Костя.
4. Подчиненные
И последняя группа респондентов — это подчиненные. Косте повезло, подчиненных у него нет. Сюда стоит добавлять даже неформальных подчиненных. К примеру, вы ведущий разработчик, и часть времени менторите джуниора.
Запуск процесса
Третий этап целиком лежит на плечах руководителя — он вычитывает все данные, полученные от сотрудника, готовит ревью и рассылает его участникам.

В первую очередь руководитель смотрит на результаты self review. Смотрит тщательно, подмечает все недостатки, говорит, какую информацию стоит добавить, а какую — убрать, дает дополнительные советы по форме. Все замечания руководителя обязательно нужно учесть и исправить.
Похожая процедура проходит и со списком респондентов. Руководитель просматривает его, оценивает релевантность участников, может кого-то убрать или добавить. В общем виде вы должны быть способны объяснить руководителю, зачем добавили того или иного человека, и как с ним работали в последние несколько месяцев.
Затем руководитель стартует ревью в нашем инструменте для performance review. Всем участникам приходят уведомления в slack и начинается период оценки.
Проведение оценки
Теперь пора переключить майндсет и перейти в роль респондентов. Посмотрим на то, как Костю оценивает его коллега. Он читает self review, смотрит на список приложенных ожиданий и отмечает релевантные для себя — те стороны его деятельности, с которыми он имел дело и может адекватно оценить.
У нас действует такая градация оценок.
- (1) Значительно ниже ожиданий
- (2) Ниже ожиданий
- (3) Соответствует ожиданиям
- (4) Выше ожиданий
- (5) Значительно выше ожиданий
- (0) Затрудняюсь дать оценку

В текущем случае это деятельность Кости как представителя функции мобильной разработки и вся его деятельность, помимо работы в своей команде. Респондент работает в другой команде и не может оценить эту работу Кости.
Оценка: «Ниже ожиданий»
Комментарии к оценке:
«Вместо того, чтобы обратиться за помощью, неделями закапывается в проблему сам. Кроме того, пока не начал ориентироваться в компании».
Что начать делать:
- больше изучать платформенную разработку,
- наладить коммуникацию со своими коллегами,
- преодолеть страх спрашивать совета.
Что перестать делать:
- играть в PS по ночам,
- молчать на общих синк-апах, бояться высказывать свою точку зрения,
- пытаться решить все проблемы самостоятельно.
В итоге он ставит Косте оценку «Ниже ожиданий». Судя по комментарию, коллега считает, что основная проблема Кости как разработчика — это нежелание обращаться к товарищам за помощью в решении проблем. Вторая проблема заключается в неумении ориентироваться в компании, что тоже является несоответствием ожиданиям.
В комплекте идут несколько советов по развитию — активнее изучать платформенную разработку, а не закапываться в Танненбаума, наладить коммуникацию с коллегами и преодолеть страх спрашивать совета. Последние два пункта напрямую коррелируют с его комментарием. И в секции «что перестать делать» респондент затрагивает еще один интересный момент — молчание на общих встречах, нежелание активно высказывать и продвигать свою точку зрения. Обратная связь выглядит конструктивной и полезной — менеджер Кости спокойно сможет начать с ней работать и помогать ему исправить ситуацию.
На очереди второй респондент, Павел. Павел, как я уже упоминал, продакт-менеджер команды, в которой работает Костя. Оценка Кости у Павла строится фактически на абсолютно других ожиданиях и фактах его деятельности. Это абсолютно правильно, потому что тип их взаимодействия был совсем иным.
Оценка: «Выше ожиданий»
Комментарии к оценке:
«Костя — лучший. Он помог выстроить процессы планирования в юните и предложил кучу отличных идей по достижению наших OKR-ов. Если бы не Костя, наш юнит в этом квартале не справился бы».
Что начать делать:
- погружаться в проблемы пользователей, участвовать в их выявлении и анализе,
- вовлекать в кросс-функциональную деятельность остальных коллег.
Что перестать делать:
- работать по выходным — такими темпами можно выгореть через полгода,
- пить энергетики,
- парить вейп в переговорках.
Оценка Павла тоже сильно отличается — «выше ожиданий», отличный результат. Комментарий написан абсолютно в другой тональности, Павел очень доволен Костей и приводит кучу примеров его пользы для команды. Заметьте — здесь ни слова не говорится о тех недостатках, с которыми имел дело предыдущий респондент. Это просто другая сторона человека.
Советы по развитию у Павла тоже другие, касаются роста в сторону продуктового анализа и кроссфункционального взаимодействия. И секция «что перестать делать» довольно стандартная — из всех ревью, что я видел, в каждом втором человека просят взять отпуск, перестать работать по ночам или выходным. Мораль такова — нужно стараться подключать к оценке очень разных людей — это поможет вам собрать критику о разных сторонах вашей деятельности.
Подведение итогов
Последний этап снова целиком ложится на плечи менеджера. В первую очередь он агрегирует весь полученный фидбэк, параллельно исследуя его на наличие аномалий. Если менеджер встречает несправедливо выставленную оценку, он либо калибрует ее самостоятельно, либо связывается с респондентом для получения дополнительных уточнений. Затем по хитрой формуле подсчитывается итоговый результат.

Как я уже рассказывал, все респонденты разбиты на четыре группы: менеджер, стейкхолдеры, пиры и подчиненные. Для каждой группы подсчитывается средняя оценка, затем — средняя по всем группам с учетом равновесного распределения. И получившееся число преобразуется в одну из уже знакомых категорий — ниже ожиданий, соответствует ожиданиям… Получившаяся оценка и доносится до сотрудника.
После подведения итогов performance review менеджер проводит встречу со своим сотрудником, где доносит до него итоговую оценку и структурированный фидбэк. Эта обратная связь обсуждается с сотрудником. По результатам этой встречи обычно составляется экшн-план и менеджер продолжает в течение квартала работать с сотрудником, решая обнаруженные проблемы. Кроме того, оценка по ревью для менеджера и сотрудника становится прозрачным инструментом для роста в компании.
Разобравшись с тем, как у нас сейчас работает процесс performance review, давайте перейдем к деталям, в которых самая суть.
Практики performance review
Анонимность
Еще до момента полноценного запуска performance review на всех сотрудниках, мы проводили ряд экспериментов на ограниченных группах, чтобы получить первые наборы данных, которые можно использовать для дальнейшей разработки процесса. Один из этих экспериментов был про анонимность.
Вообще анонимность в performance review — это довольно сложная тема. Навскидку, доступны несколько разных способов реализации.
Первый, самый простой: все видят всё. Каждому сотруднику доступен полный фидбэк от всех его пиров. Он знает, кто и что ему написал, какую оценку поставил. Из плюсов — исчезает эффект сломанного телефона. Оцениваемый всегда может понять, к чему относился отзыв, исходя из личности того, кто его оставил. А если не понял, то всегда может подойти и узнать детали лично. Из минусов — при недостаточном уровне зрелости коллектива это может спровоцировать серьезные конфликты и обиды. Кроме того, люди могут начать умалчивать о проблемах, предпочитая обойтись «троечкой» (соответствует ожиданиям) и пустым комментарием.
Второй вариант — обезличенный фидбэк, в котором нет явных указаний на автора. Перед тем, как открыть результаты сотруднику, все ответы просматриваются менеджером, перемешиваются, могут быть дополнительно очищены. С таким подходом мы решаем поставленную ранее проблему. Если автор отзыва неизвестен, то и обижаться не на кого. Но вылезает другая серьезная проблема — очень трудно дать обезличенный, но все еще конструктивный и полезный фидбэк.
Ну и совсем хардкорный вариант. Менеджер самостоятельно обрабатывает все-все отзывы и сводит это в набор рекомендаций формата «что было хорошо», «что надо улучшить». Плюсов особых нет — на самом деле при любом из этих подходов менеджер должен проделать такое упражнение хотя бы даже просто для себя. А минус основной в том, что теряется контекст. Менеджер может пропустить что-то важное, личное, что может понять только оцениваемый, либо неверно интерпретировать какие-то факты.

Мы проводили эксперименты со всеми форматами, и выявили те плюсы и минусы, которые я перечислил. В итоге мы решили пойти следующим путем — поставили себе цель выйти к полностью открытому фидбэку, но идти к этому решили постепенно. На первом раунде менеджеры всегда давали обезличенный фидбэк. Некоторые отзывы было сложно деанонимизировать, но в общем виде получалось сохранять видимость анонимности. Параллельно с теми респондентами, кто писал в комментариях откровенный треш, велась воспитательная работа — мы разбирали сложные кейсы, определяли допустимые нормы поведения.
В следующем раунде ревью по решению менеджера показывали не обезличенный фидбэк некоторым сотрудникам, но большей части — все еще анонимный. Результаты отлично себя показали, ни одного конфликта замечено не было, зато люди стали обсуждать фидбэк с респондентами, задавать вопросы и появилось гораздо больше понимания причин наличия некоторых отзывов.
С каждым последующим раундом мы постепенно открывали больше ревью, приучая сотрудников к культуре открытой обратной связи. В итоге сейчас мы пришли к тому состоянию, что все видят всё за редким исключением. Например, только сформировавшаяся команда, либо еще какие-то частные случаи. Но в общем виде решение по анонимности результатов всегда остается на менеджере.
Работа с данными

Адекватные данные мы начали собирать с момента первой крупной раскатки ревью — это второй квартал 2017 года. За это время мы собрали больше десяти тысяч оценок от 1000 респондентов.

Жесткого ограничения на количество респондентов в ревью мы изначально не ставили, обозначив примерный порог в 10 человек. В итоге всё само пришло к этому числу. Причины понятны — это, по-сути, two-pizza-size team, плюс несколько респондентов снаружи команды. «Хвосты» здесь — это либо менеджеры, на которых висит много проектов и коммуникаций, либо инженеры из совсем небольших команд.

А вот это — гистограмма количества оценок, которые люди ставят в один период ревью. Видно, что для большинства оно колеблется от 1 до 11 оценок. С учетом средней продолжительности ревью порядка 25 минут, получается, что на проставление оценок своим коллегам нужно убить не больше 6 часов за квартал, причем с учетом фокус-фактора в 0,5. Это достаточно немного, поэтому людям дается вполне легко.
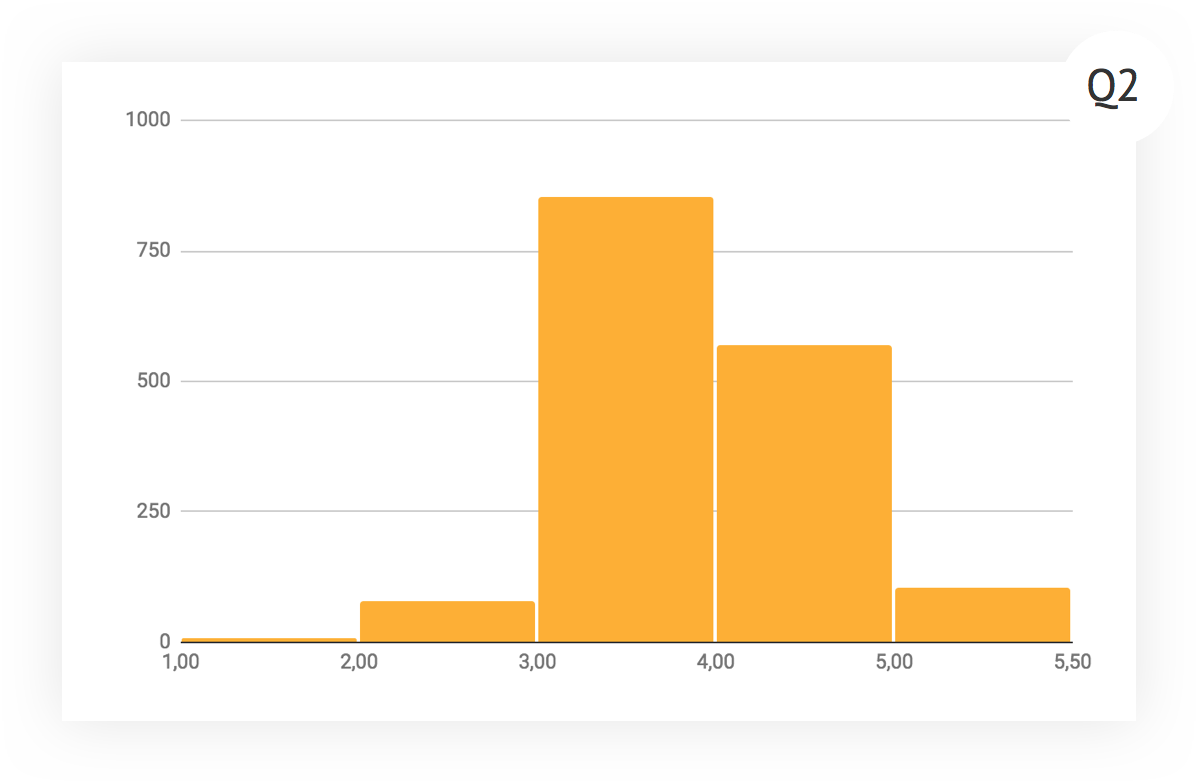
Теперь давайте изучать, как менялось распределение оценок во времени. Это — гистограмма за первый квартал проведения ревью. Налицо сильный перекос в сторону добра, количество четверок («выше ожиданий») приближается к тройкам («соответствует ожиданиям»). Было две гипотезы — либо у нас много недооцененных суперпрофессионалов, либо мы не умеем критически мыслить и правильно подходить к оценке.

К следующему кварталу поработали по обоим направлениям. Отличившихся прокачали и перевели на новые должности, а с теми, кто выделился большим количеством положительных и слабо обоснованных оценок, провели дополнительную работу. Кроме того, в этот раз менеджеры уделяли больше внимания отправлению ревью на доработку.

Что интересно, в последнем квартале график почти не изменился. Средний балл уменьшился буквально совсем чуть-чуть, форма гистограммы тоже неизменна. В принципе, мы пришли в определенный период стабильности, и, проводя дальнейшие эксперименты, можем оценивать их влияние за счет изучения отклонения от текущей формы графика.

Был ещё ряд интересных экспериментов. К примеру, про изучение наличия межгрупповых конфликтов или неприязни. Я сравнил средние оценки, которые все респонденты ставят членам своей команды с оценками, которые они ставят членам других команд. В итоге: серьёзных расхождений практически нет, в среднем оценки обеим группам примерно равны, на концах интервалов есть расхождения максимум в 0,5 балла. Гипотеза того, что люди склонны завышать оценки своей команде и занижать другим, не подтвердилась.
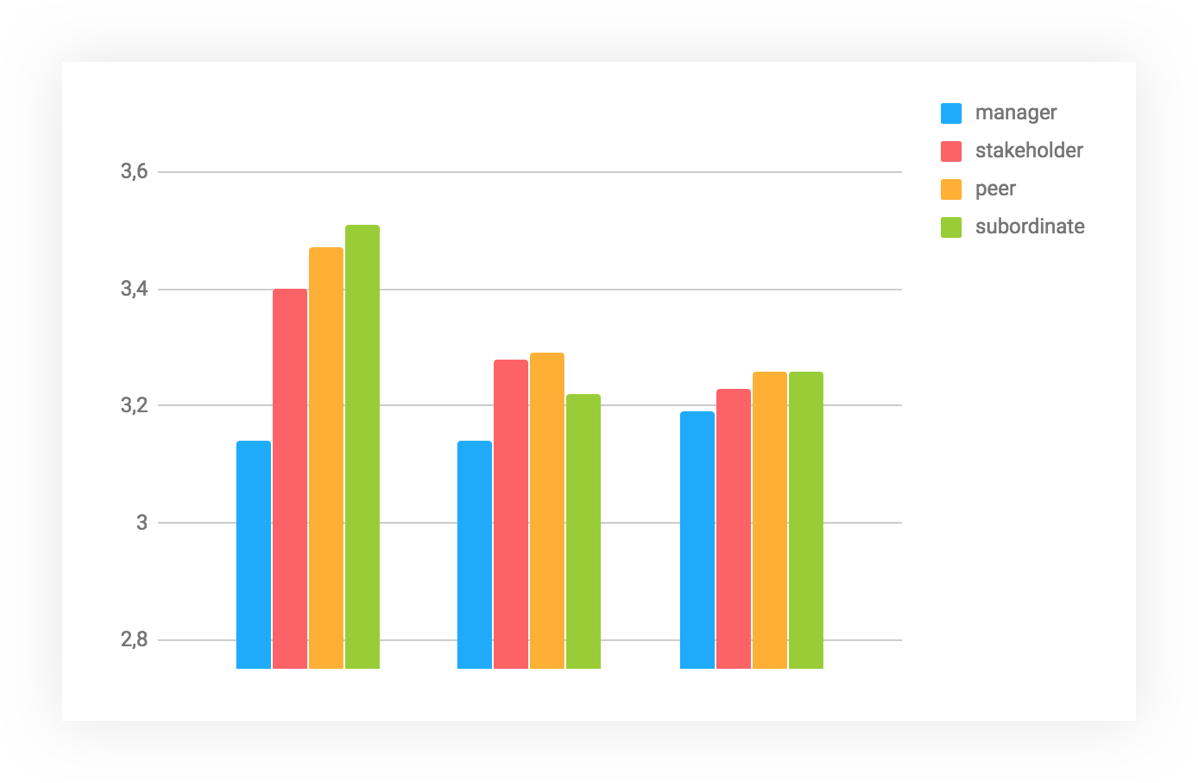
Еще одна гипотеза, которую я проверил — это влияние роли, к которой относится респондент, на его оценки. И вот тут всё подтвердилось. Сильнее всего различие видно на старте процесса, когда оценки менеджеров и подчиненных различались на пол-балла. К текущему моменту различия сгладились, но менеджеры продолжают быть самыми жесткими ревьюерами — в принципе, им по статусу и положено критическое мышление.
Эти результаты сильно коррелируют с распределением оценок в первом квартале. Видно, что у менеджеров изначально было гораздо более четкое понимание того, как нужно подходить к оценке. Из-за того, что до остальных сотрудников мы слабо довели всю методологию, и получился перекос в сторону оценок «выше ожиданий».
Оценочные профили
По результатам каждого квартала мы выделяем три яркие группы респондентов, соответствующих одному из трех оценочных профилей — доброта, справедливость или трудолюбие.
Пройдемся по каждому профилю и начнем с доброты. В эту группу люди попадают при соблюдении следующих условий: дал более 4 оценок, средний балл выше 4,1, среди оценок отсутствуют единицы и двойки. У попадания в этот профиль обычно бывает несколько причин. Например, человек реально очень добрый и ему тяжело писать критику. Или у респондента заниженные ожидания, поэтому даже работа на среднем уровне ему кажется их перевыполнением. И, конечно, действительно может быть так, что весь круг оцениваемых относится к крутым перформерам — но это, скорее, исключение из правил.
Справедливость — та же история, но наоборот. Ищем людей, поставивших меньше 2,7, не ставивших оценки выше средней и сделавших более четырех ревью. Сразу скажу, что таких существенно меньше, по крайней мере в нашем случае. Ну и, кстати, попадание в эту группу может быть маркером того, что человеку неуютно работать в его текущей команде.
Последний профиль — трудолюбие — это самый тяжелый случай. Сюда мы относим людей, которые провели сравнительно много ревью, средняя оценка — три, и дисперсия нулевая. Ну и как дополнительный фильтр — смотрим на размер оставленных комментариев и фокусируемся на тех, кто пишет сильно меньше среднего объема. Этот набор характеристик явно указывает на людей, которые не заморачиваются обдумыванием чужого ревью, а проставляют средние оценки, вставляют простую отписку и движутся дальше.
Помимо оценочных профилей, мы смотрим и на ряд других аномалий, среди которых есть как довольно очевидные вещи — кто пишет много и мало комментариев, например, так и более необычные.

Один из примеров — исследуем результаты на появление стратегий вырожденной группы. По нашей формуле расчёта оценки все группы оценщиков имеют равный вес. В рамках группы мы считаем среднюю оценку. Таким образом, чем меньше в группе человек, тем больше удельный вес оценки её участника. Вот пример — есть три группы. Человека оценивает пять коллег, три подчиненных и один стейкхолдер. В результате оценка стейкхолдера может поменять итоговую практически на полтора балла и перевести её из категории очень плохой в очень хорошую. Сейчас мы смотрим на это ретроспективно, но в планах выравнивать ситуацию еще до старта самого ревью.
Нормализация оценок
Наш процесс перфоманс ревью сильно завязан на менеджере, который его проводит. Он должен держать в уме все известные аномалии, исследовать обратную связь на предмет адекватности и наличия отклонений. Запутаться в этом было довольно просто, поэтому после очередного раунда ревью мы ввели такое понятие, как нормализованная оценка.

Нормализованная оценка, по сути своей, показывает отклонение текущей оценки от средней оценки, которую обычно ставит респондент. Важно отметить, что за аксиому принят тот факт, что если все сотрудники находятся на своих местах, то оценка большинства будет стремиться к 3 («соответствует ожиданиям»).
Разберем, как такая формула работает на добряках. Есть парень, который любит всех вокруг, и его средний балл за ревью в этом периоде — 4,3. Из-за этого мы считаем, что его оценки девальвированы. Если он поставит очередную четверку, то после нормализации она превратится в 2.7.
Это работает и в обратную сторону. Двойка от такого парня ценится сильнее, ведь если даже добряка довели, то причина скорее всего есть, и она очень серьезная. После нормализации оценка превращается в единицу.

Теперь пошли к клану справедливых. В этом примере средняя оценка респондента — 2,4. Поставленная им двойка с таким подходом начинает весить чуть больше, таким образом мы автоматически принимаем во внимание его склонность пессимизировать реальность. Ну и как в случае с добрым парнем — если справедливый ставит 4, то эта оценка и весит намного больше.
В итоге в каждом ревью мы получаем две оценки — performance score и нормализованный итог. Обратите внимание — сотруднику доносится именно основной результат, без нормализации. Второе значение мы используем только как индикатор для менеджера.
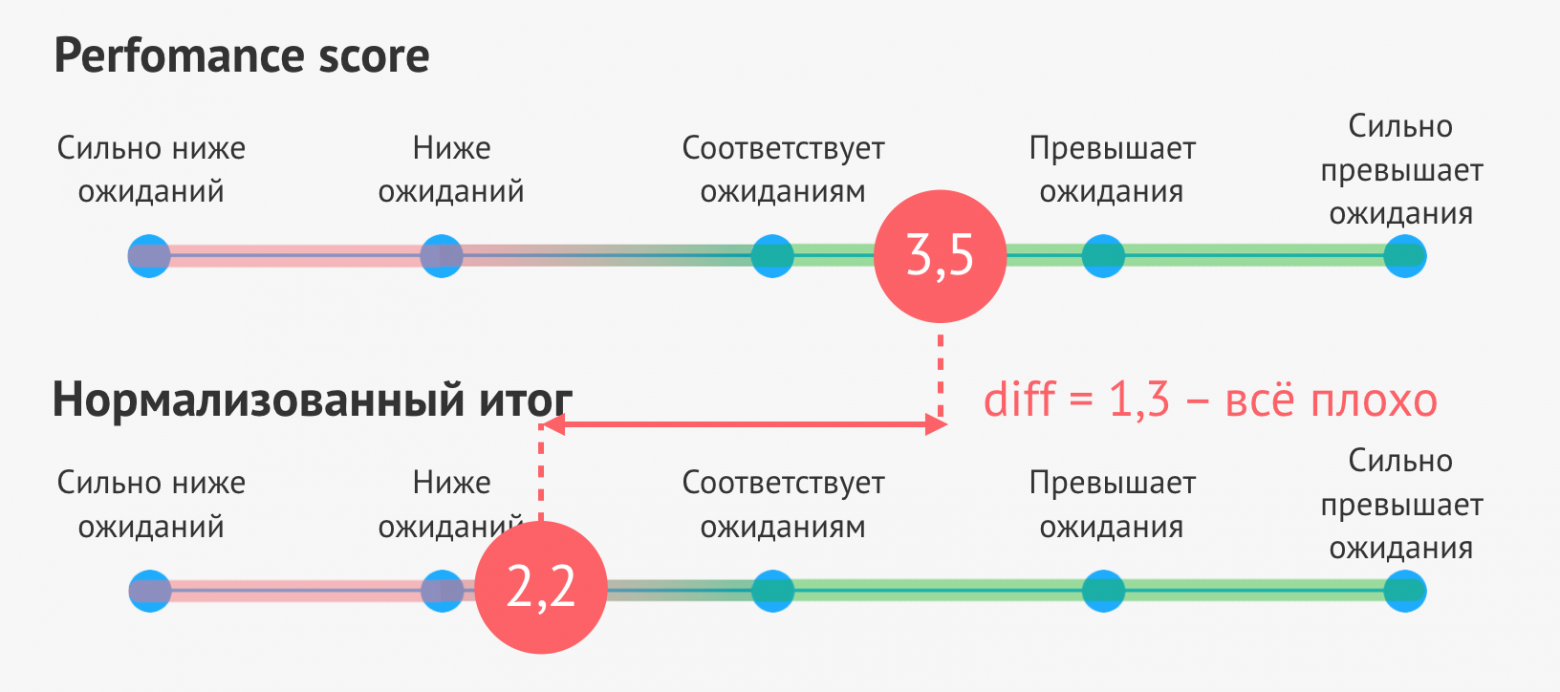
Работать с нормализованной оценкой можно по следующим сценариям.
- Нормализованная оценка и performance score отличаются незначительно, следовательно можно не сильно углубляться в анализ обратной связи и не напрягать респондентов.
- Нормализованная оценка и performance score отличаются сильно (более, чем на 0.5), следовательно, есть вероятность, что часть респондентов имеют предрасположенность к завышению или занижению оценок. Если их попросят пересмотреть оценки, то performance score оцениваемого станет принципиально другим.
Корректировка оценок
Вообще в теории все звучит красиво. Респонденты молодцы, пишут объективные ревью, всегда ориентируются на ожидания от роли и никогда не сачкуют. Тем не менее, я уже рассказал про кучу встречаемых нами девиаций, и ими весь список не ограничивается. Когда оценка в ревью выставлена явно неадекватно, либо хотя бы вызывает вопросы, в процесс включается менеджер и начинает процедуру детализации фидбэка. В ряде случаев все проходит быстро. Респондент одумывается, пишет конструктивный отзыв, исправляет оценку. Но иногда случаются проблемы — человек уходит в отпуск, отказывается идти на контакт, жёстко стоит на своем. Так мы и пришли к необходимости введения возможности ручной корректировки оценки менеджером.
У менеджера есть возможность поменять выставленный респондентом балл на любой другой, в том числе и на состояние «затрудняюсь оценить». При введении такой фишки доверие сотрудников к системе может начать подрываться. Да и в любом случае, не исключена ситуация, когда менеджер не по злому умыслу, а от банальной лени начнет самостоятельно корректировать множество оценок без попытки выяснить причины их проставления. Чтобы этого избежать, мы отслеживаем факт корректировки. В базе хранятся все версии оценок, выставленные в рамках одного ревью. Ретроспективно мы смотрим, какие менеджеры злоупотребляют инструментом, и при необходимости вмешиваемся. Чтобы вы понимали масштаб проблемы — в предыдущем раунде ревью, где мы проработали 3.977 оценок, скорректированы менеджером были всего 62, 80% из которых не более, чем на один балл.
Антипаттерны
Помимо выделения общих профилей на основе аналитики, есть ряд стандартных антипаттернов, которые выявляются качественной оценкой — просмотром фидбэка от человека.

Впечатлительный.
Оценивает, основываясь на одном ярком впечатлении.
Оценка:
«Сильно превысила ожидания».
Комментарии к оценке:
«Помог мне почистить айфон от вирусов. Он — один из лучших в компании».
Первый из них — делать выводы о продуктивности сотрудника только на основе последнего взаимодействия с ним. Понятно, что если какое-то яркое событие произошло совсем недавно, оно в любом случае может сильно исказит впечатление — но это не отменяет необходимости абстрагироваться от этого и оценить весь опыт работы с человеком.
Яркий маркер антипаттерна — это отсутствие нормального обоснования поставленной оценке, либо оно дано очень однобоко. Лечить можно как со стороны процесса, требуя детального комментария к оценкам, так и со стороны самих людей. Были случаи, когда ребята заранее вели для себя короткие заметки по коллегам, где отмечали, на что стоит обратить внимание в ревью.

Злопамятный.
Оценивает все время работы с сотрудником, а не последний квартал.
Оценка:
«Ниже ожиданий».
Комментарии к оценке:
«В 2014 году, когда мы сидели в одной комнате, он много курил. А еще весь прошлый год уделял больше внимания коду, а не потребностям бизнеса».
Следующий антипаттерн прямо противоположен. Оценка ведется исходя из всего периода знакомства с оцениваемым. Performance review — это анализ деятельности человека за короткий отрезок времени, поэтому нужно стараться не давать воспоминаниям давить на вас.
Такие отзывы характерны двумя особенностями. Во-первых, там много оценочных суждений вроде «он отличный парень» или «она невыносима». Во-вторых, нет никаких конкретных деталей. Лечение аналогично предыдущему случаю — закручивание гаек при приемке менеджером оценок.

Конформист.
Не может оценить, но оценивает.
Оценка:
«Соответствует ожиданиям».
Комментарии к оценке:
«—».
Достаточно часто бывает, что вас добавляют в ревью к человеку, оценить которого достаточно сложно — просто не хватает опыта взаимодействия с ним. В таком случае многие ставят «соответствует ожиданиям» и отписываются ничего не значащим комментарием.
Мы лечим это возможностью отказаться от участия в ревью на уровне инструмента. Кроме того, такие ребята имеют повышенный шанс засветиться в аналитике в группе «Трудолюбие».

Жалостливый.
Не дает конструктивной обратной связи, жалеет сотрудника.
Оценка:
«Соответствует ожиданиям».
Комментарии к оценке:
«Справляется со своими обязанностями, не хуже и не лучше других».
Этот вариант, к сожалению, очень распространен. Респондент не хочет обижать оцениваемого, уменьшая его оценку или присылая негативный отзыв о его работе, поэтому ставит «соответствует ожиданиям» и отмазывается общими словами.
Бороться с ним, на самом деле, очень сложно. Ретроспективно помогает в основном все та же массовая аналитика по оценкам, назначение человека в один из оценочных профилей и работа менеджера с ним. Здесь же помогает та самая нормализация, о которой я уже писал. Ну и, как самый простой инструмент, требовать подробностей в фидбэке и бенчмаркать их относительно ожиданий к позиции сотрудника.

Субъективный.
Оценивает по субъективным ожиданиям.
Оценка:
«Соответствует ожиданиям».
Комментарии к оценке:
«Он перформил как бешеный, но это соответствовало моим изначально сильно завышенным ожиданиям».
Респондент оценивает сотрудника, исходя из своих собственных ожиданий и представлений о том, что он должен делать, поэтому его оценка теряет всякую объективность. Стандартный пример, с которым я сталкивался — в команде есть один бесконечно крутой инженер, который овер-перформит, но из-за того, что все к этому привыкли, это воспринимается как должное.
Следите за появлением в тексте маркеров вроде «по моим ожиданиям» — это чёткое указание на то, что вы столкнулись с этим антипаттерном. Лучший метод лечения здесь — построить простую и понятную систему ожиданий от позиций и ролей.
Инструменты
Google Forms
Как настоящие продуктовоориентированные ребята, мы начинали с MVP. Состоит он из трех частей. Первая и основная — это гуглоформа, в которую менеджер вбивает все данные своего сотрудника, включая self review, и вручную рассылает ее по списку респондентов. Потом он следит за степенью заполнения формы, руками вычисляет тех, кто забыл провести ревью, и пинает их в мессенджерах. Дёшево и сердито, но вполне работоспособно.
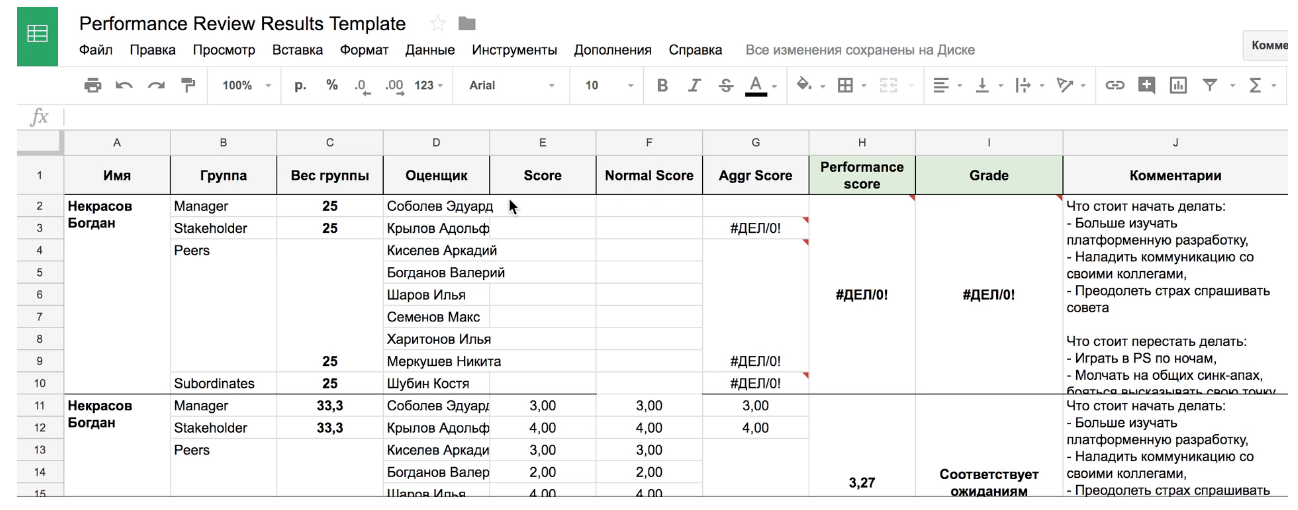
Вторая часть системы — это таблица с результатами команды или отдела. Все формулы подсчета уже забиты, так что расчёт итоговой оценки самому делать не нужно. Одна из проблем — необходимость вручную синхронизировать данные из гуглоформы с таблицей, в связи с чем возможно искажение информации. Ну и, конечно, основная проблема в децентрализации. Очень сложно собрать результаты всех команд в компании, посчитать аналитику, или просто хранить их для истории. А сразу пилить в общем документе тоже не просто, встают вопросы приватности и разделения прав доступа.
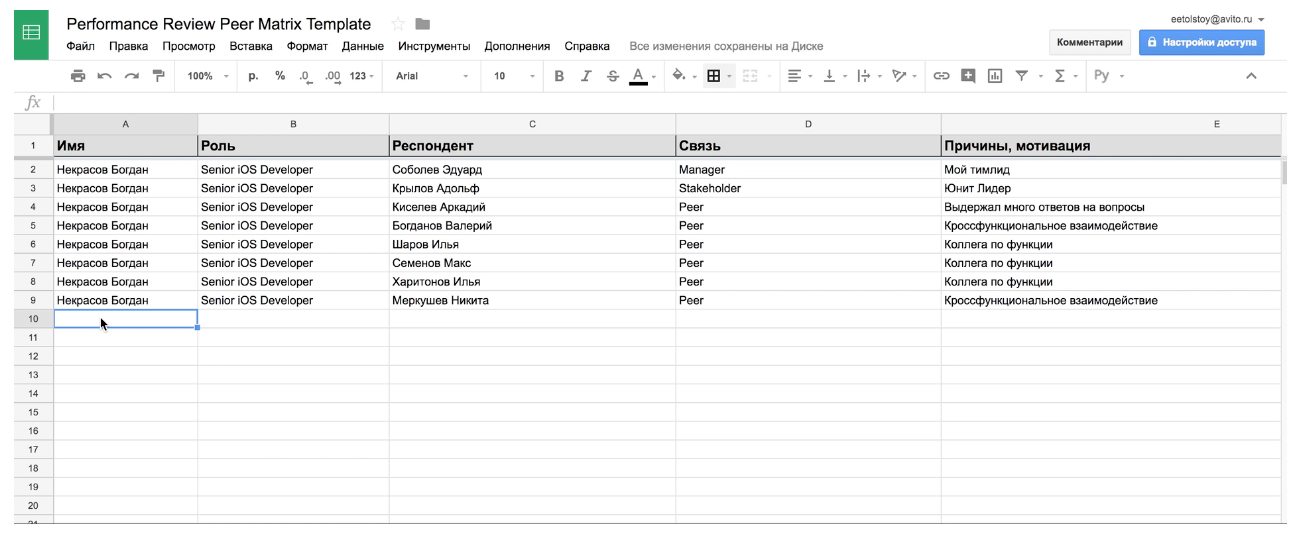
И третья часть — сводный список всех участников performance review в компании. Применяется для двух целей — во-первых, контроль полного списка участников, во-вторых — балансировка нагрузки на респондентов. Когда вы добавляете кого-то в ревью, то сначала проверяете, сколько уже человек он оценивает.
С такой системой мы проработали, по сути, два квартала — первый тестовый, когда обкатывали систему на нескольких командах, и один полноценный. В целом работа с гуглоформами полностью оправдана в двух случаях. На старте внедрения процесса, когда вы еще не знаете, к какой итоговой форме хотите прийти, и в случае небольших команд, где не всплывают проблемы масштаба.
Автоматизация
На ретроспективе после первого раунда ревью мы провели подсчет того, сколько времени у команды ушло на работу с инструментом. Посчитав, во сколько денег нам обходятся потери в виде выполнения механических действий, мы поняли, что пора двигаться к запиливанию своего инструмента. В полухакатонном режиме силами одного человека была реализована альфа-версия того, что мы в итоге назвали громким словом Перфоратор. Я не буду вдаваться в детали развития инструмента — он находился в режиме постоянного изменения, и то, что мы получили в результате, сильно отличается от первого прототипа.

В итоге с его помощью мы свели все требуемые действия для performance review к минимуму, оставив только полезную нагрузку. А хранение абсолютно всех данных и сбор дополнительной статистики сильно облегчили нам задачу анализа получаемых оценок.
Известные недостатки
Текущее состояние нашего performance review очень отличается от того, с чего мы начинали. Но это еще не конец, и мы продолжаем итеративно дорабатывать процесс, проверять разные гипотезы.
У нас описаны ожидания практически для всех ролей и позиций. К сожалению, в основном это огромные полотна текста, которые тяжело читать и анализировать. Это сильно отталкивает часть людей, и их можно понять — удерживать в голове ожидания от позиций всех в кросс-функциональной команде нереально. Мы думаем об упрощении ожиданий и представлении их в ограниченном наборе тезисов.
Сейчас в ревью мы просим респондентов заполнять три поля — собственно, комментарий, а также поля «что начать делать» и «что перестать делать». Судя по аналитике, большинство людей ограничиваются заполнением первого поля, а в два других вставляют плейсхолдеры. Мы планируем провести несколько A/B тестов и посмотреть, что изменится, если упростить эту форму.
Еще одна проблема — когда несколько сотен человек начинают заполнять ревью друг на друга, работа встаёт. Особенно это проблемно для менеджеров, которым приходится учитывать эти пики при планировании своего времени на квартал вперед. Мы планируем попробовать сгладить нагрузку постепенной раскаткой очередного раунда ревью по группам людей.
Часто возникает ситуация, что оцениваемый случайно или намеренно не добавил в список респондентов тех, чей фидбэк было бы очень полезно услышать. Мы планируем это победить тем, что дадим людям возможность предлагать себя в качестве ревьюера.
Заключение
В этой статье я сосредоточился именно на разборе самого процесса, упомянув нашу мотивацию к его внедрению только в самом начале. Пройдусь тезисно по основным преимуществам, которые мы получили.
- Мы научились оценивать результаты и эффективность работы сотрудников с учетом мнений всех, с кем он взаимодействует.
- В компании появился прозрачный как для менеджмента, так и для самих сотрудников инструмент роста.
- Сбор обратной связи и донесение её до сотрудника стал обязательным и регулярным, что сильно помогло в развитии многих.
- Мы начали развивать культуру открытой обратной связи, что иногда выходит и за пределы performance review. Люди начинают открыто обсуждать свои конфликты, своевременно хвалить друг друга.
- Self review оказался крутым инструментом для саморефлексии, которой ранее многие пренебрегали.

Главная мысль, которую я хочу донести в этой статье — вам не нужно строить космолёт с самого начала. Если вашей команде нужен performance review, начните с самого простого варианта. Затем соберите обратную связь, проанализируйте полученные данные, проведите несколько экспериментов по улучшению процесса. И так, двигаясь итеративно, вы сможете раз за разом получать более качественный процесс, адаптированный именно под вашу команду и культуру. Ну а если вам помогут те практики и инсайды, которыми я сегодня делился — будет очень круто!
