
Всем привет! Меня зовут Илья Алонов. Я фронтенд-инженер и уже второй год занимаюсь производительностью фронта в Авито в платформенной команде Perfomance.
Хочу рассказать про профилирование фронтденда в продакшене с использованием JS Self-Profiling API. Этот инструмент я откопал, когда пытался ускорить исполнение клиентского JS в Авито. Если интересуетесь перформансом веб-приложений — эта статья для вас.
С этим материалом я выступал на митапе MoscowJS. Запись моего выступления с докладом «Профилирование фронтенда в проде» можно посмотреть на YouTube-канале AvitoTech.

Что такое профилирование
Профилирование — это измерение и анализ производительности и эффективности кода. Оно помогает разработчикам искать узкие места, ненужные запросы и другие проблемы, которые могут замедлить работу программы или ухудшить пользовательский опыт.
Профилирование бывает двух видов: инструментальное и сэмплирующее.
Инструментальный профайлер программно дополняет таймингами каждый вызов на стеке. Эти тайминги вычисляют время исполнения того или иного кода.
Сэмплирующий профайлер раз в N времени берёт снэпшот (сэмпл) стека вызовов и вычисляет из них время исполнения кода.
Под профилированием фронтенда в основном подразумевают использование инструментов браузера, таких как профайлеры в Chrome или Firefox.
Зачем нужно профилирование
Есть метрика Total Blocking Time (TBT). Она отражает, как долго исполнение JS блокирует главный поток браузера — то есть время, в течение которого браузер не отвечает на взаимодействия пользователя с сайтом. У нас оно выглядело вот так:
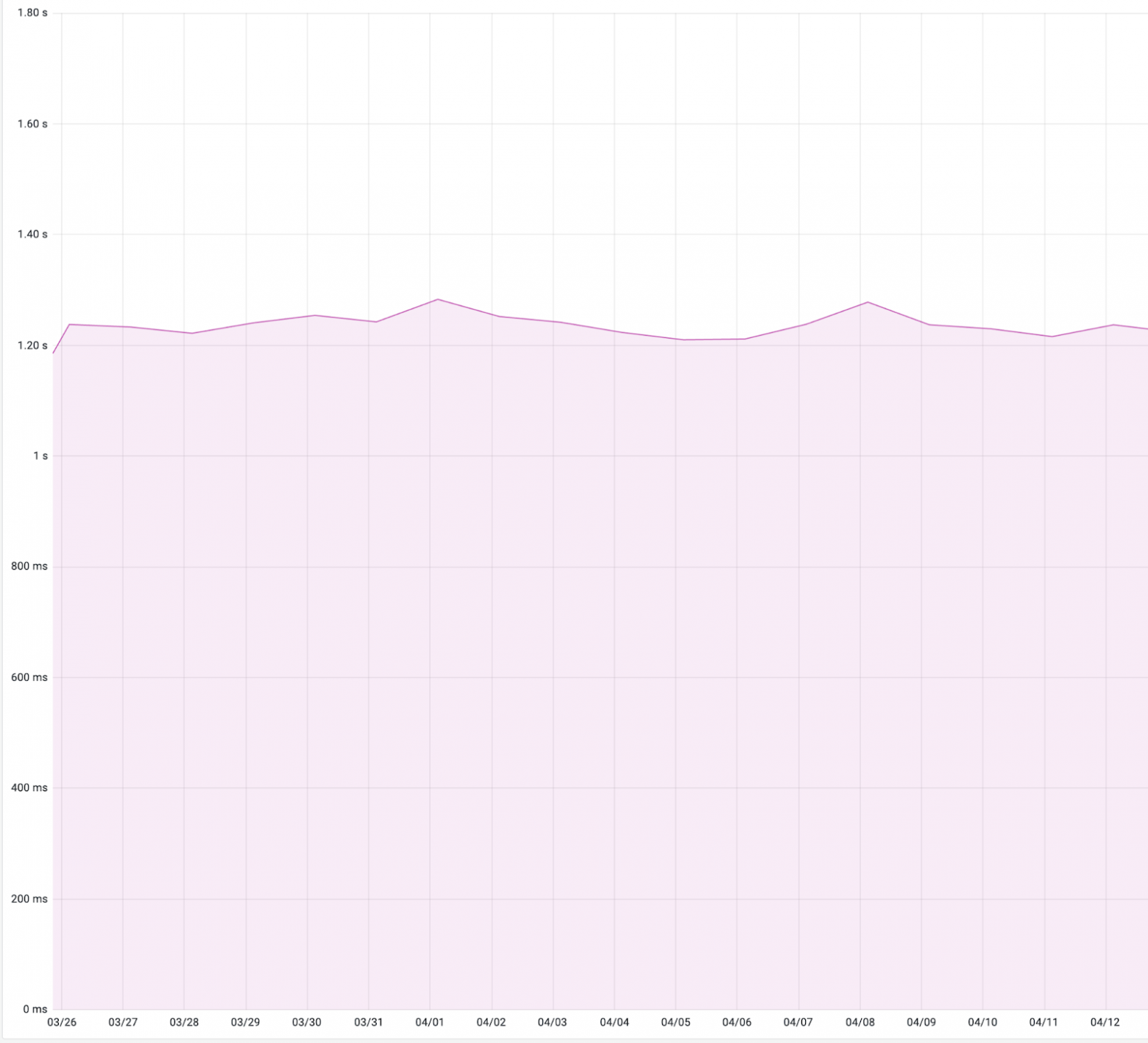
TBT измеряется для всей страницы. Соответственно, любая блокировка учитывается в этой метрике, и из-за этого её сложно оптимизировать. Эта сложность растёт вместе с количеством загружаемого и исполняемого кода, запросов в сеть, загруженных ресурсов.
Подробнее о Total Blocking Time →
Спустя множество ручных оптимизаций и предшествовавших им рисерчей я решил, что с этим надо что-то делать. Моих рук и головы (да и в целом всей нашей команды) просто не хватит, чтобы постоянно следить за метрикой на всех страницах, реагировать на просадки и пилить оптимизации. Хочется иметь инструмент, который поможет командам самим следить за перформансом своего кода в рантайме.
С такими мыслями я начал искать способ декомпозировать TBT и набрёл на JS Self-Profiling API.
Что такое JS Self-Profiling API
JS Self-Profiling API — это браузерный API, который позволяет запускать сэмплирующий профайлер. Не стоит путать с профайлерами, доступными в devtools — это разные вещи.
Профайлеры сэмплирующего класса собирают сэмплы стека вызовов, из которых строят трейс — то, что профайлер выплёвывает как результат:

JS Self-Profiling API позволяет запускать и останавливать профилирование в любой момент жизненного цикла страницы.
Как использовать JS Self-Profiling API
Давайте рассмотрим, как это работает на практике. Идея такая: инициализируем профайлер, в нужный момент останавливаем его и получаем трейс.
Важно: на момент выхода статьи JS Self-Profiling API доступен в Chrome 94 и выше. Проверьте, совместим ли инструмент с вашим браузером.
1. Инициализируем профайлер:
if (windows.Profiler) {
const profilier = new Profiler({
sampleRate: 10,
maxBufferSize: Number.MAX_SAFE_INTEGER
});
// … когда придет время …
const trace = await profiler.stop();
doStuff(trace);
}Для инициализации нужно 2 параметра:
sampleRate— частота сэмплирования в миллисекундах. Любой number. На деле для *nix-систем минимальное значение — 10 мс, для Windows — 16 мс. Если поставить значения меньше минимальных, браузер под капотом всё равно выставит нужные.maxBufferSize— предельное количество сэмплов, которое мы хотим снять.
2. После профилирования получаем объект Trace с 4 полями:
resources— список url-ов исполненных JS-файлов;frames— список фреймов с информацией об исполняемом коде: имена функций и их позиции в загруженном файле;stacks— список стеков вызовов. Элементы списка состоят из двух полей: frameId — ссылка на фрейм из списка frames, parentId — ссылка на вызывающий стек. Фактически в этом списке хранятся деревья вызовов;samples— список всех собранных сэмплов: состоит из timestamp и ссылки на стек.
Вот как это выглядит:
{
"resources": [
"https://domain.com/static/abc.js",
"https://domain.com/static/123.js"
],
"frames": [
{
"name": "a", "resourceId": 6,
"line": 23, "column": 169
},
{
"name": "b", "resourceId": 1,
"line": 313, "column": 1325
},
],
"stacks": [
{ "frameId": 0 },
{ "frameId": 1, "parentId": 0 },
{ "frameId": 2, "parentId": 1 }
],
"samples": [
{ "timestamp": 1551.73499998637, "stackId": 2 },
{ "timestamp": 1576.83999999426, "stackId": 1 },
]
}Трейс загрузки главной странцы Авито весит ~90Kb. Эта информация понадобится нам чуть позже.
Что там с оверхедом
Главное стоп-слово для разработчиков, желающих включить профилирование (необязательно в браузере) — оверхед. Давайте смотреть, что с ним у нашей технологии.
Во-первых, есть исследование от ребят из Facebook* об оверхеде от JS Self-Profiling API. Они пишут, что в их случае оверхед составляет 1% в скорости загрузки.
Во-вторых, я сам провёл A/B-тест в Авито и тоже обнаружил низкий оверхед. На мобильной версии сайта он в среднем составил 1–2% от скорости загрузки и Total Blocking Time при частоте сэмплирования 10 мс.
Итого оверхед у JS Self-Profiling API незначительный, следовательно, можно развлекаться дальше.

Дизайн инструмента
С оверхедом разобрались, можно приступать к дизайну. Что можно сделать с полученным трейсом? Первое, что приходит в голову — слить его на сервер и там как-то обрабатывать. План выглядит надёжно, давайте посчитаем математику:
предположим, что у нас 10K RPM,
трейс загрузки в проде весит 90 Кб.
Несложными вычислениями получаем 1 Тб в день. И это при условии, что все данные нормализованные:
90Kb / 1024^2 * 10000 * 60 * 24 = 1 Tb/day
Это, конечно, можно процессить на сервере и даже хранить, но для этого нужна инфраструктура. А зачем делать инфраструктуру, если можно её не делать?
Упрощаем себе задачу
Я решил уменьшить масштаб задачи и обрабатывать данные только о лонгтасках, из которых складывается Total Blocking Time.
Чтобы это получилось, нужно вытащить лонгтаски с помощью PerformanceObserver и смержить их с трейсом профилирования:
const trace = await profiler.stop();
const longtasks = getLongtasks(); // via PerformanceObserver
function merge(trace, longtasks) { … }
const richLongtasks = merge(trace, longtasks);Этот алгоритм хорошо описал Nic Jansma в своей статье.
В результате получаются обогащённые лонгтаски — со временем начала, конца и списком причин. Вот как это выглядит:
{
start: 1,
end: 11,
reasons: [
{
duration: 6,
frames: [
{
url: 'https://domain.com/static/abc.js',
line: 23, column: 169
},
{
url: 'https://domain.com/static/123.js',
line: 313, column: 1325
},
]
},
…
]
}
Превращаем обфусцированный код в исходники
Мы получили обогащённые таски со списком причин. Проблема в том, что файлы, на которые ссылаются фреймы, — это обфусцированный исходный код.
Замапить трейс собранного кода в исходнки можно с помощью сорсмап, но грузить их на клиент дорого и не очень безопасно. Но нам и не нужны сорсмапы на весь код.
Давайте подумаем о том, как обычно выглядит фронтендерский проект. Он состоит из:
NPM-пакетов: проприетарных или open source;
модулей: компонентов, утилит;
стороннего кода: рекламы, трекеров, счётчиков и прочего подобного.
Зафиксируем эту мысль в виде конфига:
// profiling.config.json
{
"internal": [
"@avito/packageA",
"@avito/packageB"
"src/components/x",
…
],
"external": [
"yastatic",
"me.yandex.ru",
"googletagmanager",
…
]
}Так мы заранее знаем, профилирование каких модулей нам интересно. Чтобы всё это заработало, на этапе сборки мы вытащим из Source Map информацию о том, куда были собраны нужные нам модули. Тогда для каждого чанка получится сгенерировать некий json-файл, который мы назовём profiling map. Каждая такая мапа будет содержать информацию об интересующих нас модулях, попавших в соответствующий чанк.

Profiling map — это JSON с двумя полями:
modules — список профилируемых модулей;
intervals — отсортированный список интервалов. Каждый интервал состоит из 3 значений: начало, конец, индекс модуля из списка modules.
Вот как это выглядит:
// some-chunk.hash.profiling-map.json
{
"modules": [
"@avito/packageA",
"@avito/packageB"
"src/components/x"
]
"intervals": [
[154, 201, 1], // [start, end, moduleIdx]
[45886, 46813, 0],
[55574, 57004, 0]
[55574, 57004, 2],
],
}
Весит Profiling Map немного, в том числе за счёт нормализации данных. Для главной мобильной страницы Авито — всего 500 байт.
Собираем воедино
В прошлых двух разделах мы научились получать обогащённые лонгтаски и переходить от собранного кода к исходникам. Осталось всё это соединить, чтобы технология работала. Делать это будем в два этапа.
В начале загрузки страницы:
Запустить PerfomanceObserver.
Запустить Profiler.

В конце загрузки страницы:
Остановить PerfomanceObserver и получить лонгтаски.
Остановить Profiler и получить трейс.
Слить лонгтаски и трейс, получить обогащённые лонгтаски.
Параллельно с мержем лонгтасок и трейса запросить profiling map оттуда, где они лежат. Я положил рядом со статикой.
Достать из обогащённых лонгтасок то, что указано в profiling map’ах.


Ограничения JS Self-Profiling API и как их обойти
Так как профайлер сэмплирующий, разовое профилирование может не зацепить исполнение какого-то кода, и некоторые таски мы не увидим. Решить это можно банально: профилировать чаще. Чем чаще профилируем, тем больше данных имеем, тем лучше наши метрики.

CORS. Для всех ресурсов с доменов, отличных от текущего, должны быть настроены cross-origin политики. В противном случае JS Self-Profiling втихую удалит информацию о них из профилирования.
Инструмент воспринимает только исполнение JavaScript. Информацию о сборке мусора, парсинге HTML, вычислениях стилей и лейаута он не даст. Сейчас этого нет, но на GitHub есть предложение о добавлении такой информации в JS Self-Profiling API в виде маркеров на стеке.
Вот как это будет выглядеть:
"stacks" : [
{"marker" : "idle"}, // id: 0
{"marker" : "script"}, // id: 1
{"marker" : "parse"}, // id: 2
{"marker" : "gc"}, // id: 3
{"marker" : "paint"}, // id: 4
{"marker" : "other"}, // id: 5
{"frameId" : 1, "marker": "script"}, // id: 6
{"frameId" : 2, "parentId" : 6, "marker": "script"}, // id: 7
{"frameId" : 2, "parentId" : 6, "marker": "gc"}, // id: 8
{"frameId" : 3, "parentId" : 8, "marker": "script"} // id: 9
]Что в итоге
Мы создали инструмент, который:
умеет собирать метрики интересующих нас модулей,
почти не влияет на производительность,
прост в использовании.
Вот как выглядит график метрик пакета avito/core:
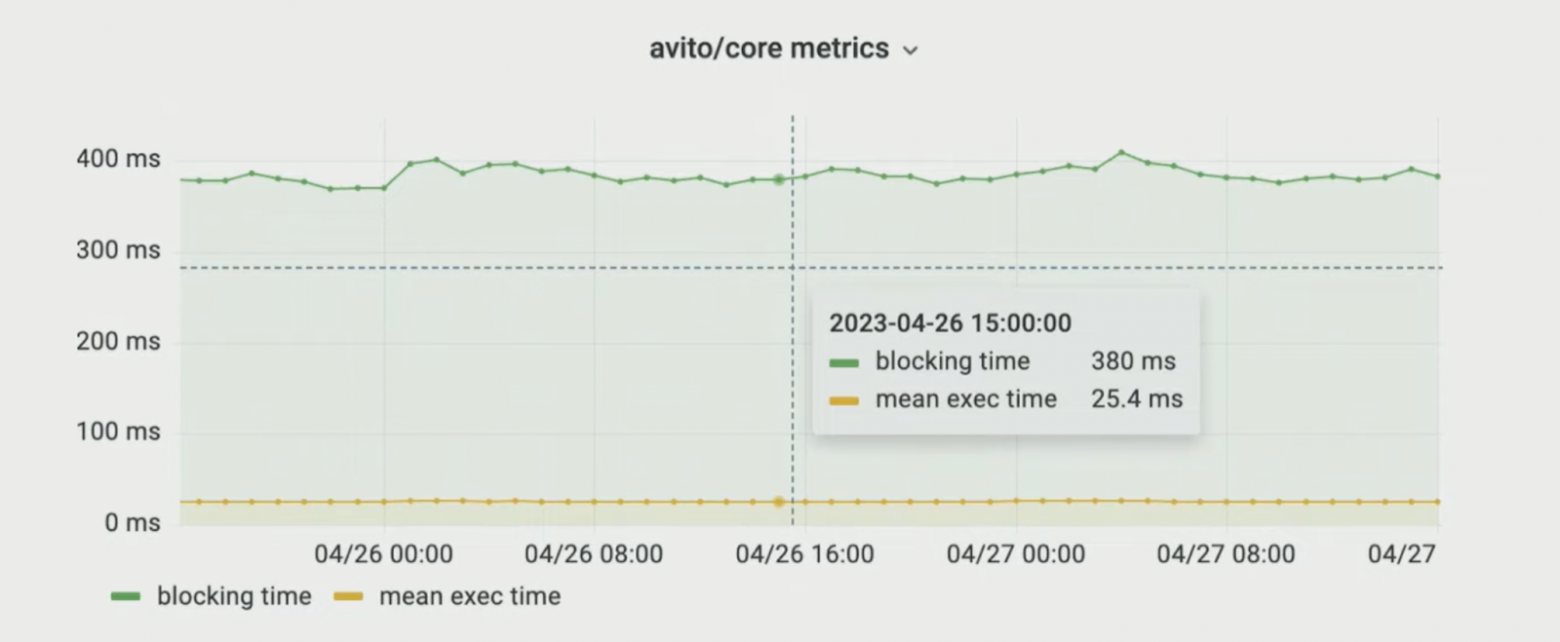
Данные для графика собраны моим инструментом, который я создал с помощью JS Self-Profiling API
Сейчас я развиваю инструмент дальше. Уже появилась поддержка микрофронтов и сильно улучшился DX — теперь включать профилирование пакетов можно из внутреннего дашборда, не запариваясь изменениями конфига.
Также у нас есть планы:
автоматизировать мониторинг метрик,
использовать технологию в NFR.
Полезные материалы
Запись моего выступления «Профилирование фронтенда в проде» на YouTube
Статья JS Self-Profiling API In Pratice, на которую я опирался
* Компания Meta, которой принадлежит Facebook, признана экстремистской и запрещена в России
Предыдущая статья: «Всё происходит само собой, когда тебе не всё равно»: как из игрока в покер стать руководителем тимлидов
