 Недавно я побывал на замечательной конференции Percona Live 2016 в Санта-Кларе. Хочется написать множество хвалебных слов организаторам и за отлично работающий Wi-Fi, и питание, и точное следование расписанию, и подготовку залов. Но все же статью я пишу не для туристического сайта, а для технического, потому просто расскажу о самых интересных докладах из тех, которые я посетил.
Недавно я побывал на замечательной конференции Percona Live 2016 в Санта-Кларе. Хочется написать множество хвалебных слов организаторам и за отлично работающий Wi-Fi, и питание, и точное следование расписанию, и подготовку залов. Но все же статью я пишу не для туристического сайта, а для технического, потому просто расскажу о самых интересных докладах из тех, которые я посетил.На удивление для столь узкоориентированной конференции, спектр докладов не ограничился одним только MySQL, как это могло бы показаться, но охватывал в целом инструменты работы с данными. Место нашлось и Hadoop с экосистемой и колоночными базам данных, и облакам (куда сейчас без них).
Внедрение GTID-репликации в Dropbox
Начиная с версии MySQL 5.6, в MySQL появилась такая замечательная вещь, как GTID репликация. В руководстве написано «много букв» о том, как эта репликация работает, но практически отсутствует информация, зачем она нужна.
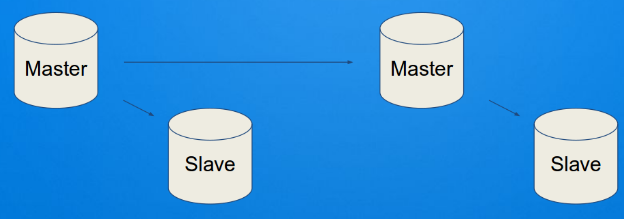
Давайте представим себе, что кому-то потребовалось сделать каскадную репликацию данных. Это может потребоваться в случае, если часть каскада реплик находится в другом дата-центре. Чтобы сэкономить трафик между дата-центрами, только одна реплика тянет копию данных на себя, и уже с ее логов обновляются локальные слейвы. В общем-то, не самая плохая и вполне рабочая схема. Но она содержит в себе одну маленькую проблему.
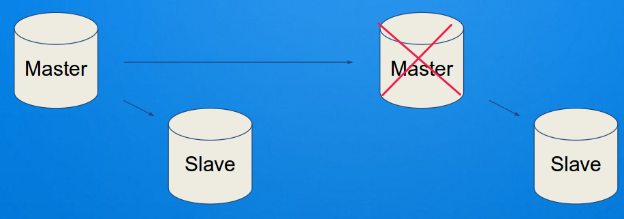
Нельзя просто так взять и поменять мастер у слейва. Например, если отказывает один из узлов, то придется все узлы ветки инициализировать заново, т.е. разворачивать копию нового мастера и запускать с него репликацию. А это уже и дорого, и долго.
Чтобы этого не происходило, был предложен новый формат лога репликации, который и даёт возможность слейву продолжать репликацию с других слейвов. Т.е. лог репликации, записанный на слейве, будет полностью дублировать лог с мастера.
Более детально о работе этого механизма, а также о том, как включить его для крупного проекта (напоминаю, рассказывают Dropbox), можно узнать непосредственно из доклада.
Rolling out Global Transaction IDs at Dropbox
Пирамида Маслоу для БД
В весьма сатирической и практической форме Charity Majors рассказала о том, что на самом деле определяет пирамиду потребностей и выживания при выборе базы данных для проекта. Каждый из пунктов подкреплен отличной иллюстрацией, типа такой:

Maslow's Hierarchy of Needs for Databases
Партицирование в MySQL
Вот уже много много лет в MySQL есть возможность организации партицированных таблиц. Для чего это нужно, надеюсь, объяснять не надо. Однако, в силу некоторых особенностей реализации разработчики часто обходят этот механизм стороной. В общем-то, топора бояться — лес не рубить. Rick James предлагает разобраться, как же этот инструмент можно использовать по назначению и при каких ограничениях партицирование будет работать хорошо.
Вот примеры задач, где от партицирования можно выиграть:
- Sliding time;
- 2d index;
- Import export.
PARTITIONing — How-To vs. Don't-Bother
Репликация пользовательских шардов в Facebook
Daren Seagrave из Facebook раскрыл некоторые особенности организации их системы пользовательских шардов и рассказал о том, как они переезжают между серверами и дата-центрами, какой путь они прошли, чтобы получить равномерное и эффективное использование пула серверов. Самым необычным решением, на мой взгляд, оказалось то, что они сначала определяют, куда переносить данные, и только потом — что именно нужно перенести. Несмотря на то, что технически сами шарды представляют собой MySQL-сервера, практически целиком доклад применим к любым БД.
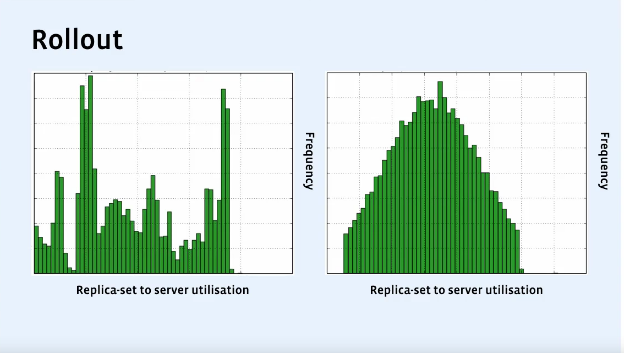
Everyday We’re Shuffling — Online Shard Migration at Facebook
Бекап баз данных в Facebook
Shlomo Priymak и Dan Reif из Facebook рассказали о том, как они организовали систему хранения бэкапов пользовательских шардов. В связи с тем, что все шарды маленького размера, процесс бэкапа отдельно взятого шарда происходит быстро. Как известно, бэкап не может считаться бэкапом, пока мы не убедились, что с него можно развернуться. Именно поэтому в Facebook организовали систему, постоянно проверяющую, что снятые бэкапы можно использовать для разворачивания БД.
Второй технической особенностью системы оказалась интересная идея по организации инкрементных бэкапов. Честно говоря, я даже никогда не слышал, чтобы кто-то снимал инкрементный бэкап базы данных. Идея для его реализации оказалась фантастически простой.

Также в докладе упомянули о том, как они это внедрили и организовали хранение в Hadoop. А также как они отказались от вычисления этого «дифа» в Hadoop. Вообще я считаю этот доклад самым полезным и интересным 8).
Massively Distributed Backup at Facebook Scale
Производительность Linux
Brendan Gregg из Netflix представил превосходный блиц о том, из каких подсистем состоит Linux. Какими утилитами можно получить информацию о каждой из подсистем, чтобы понять, не там ли «затуп».

Также он представил свой список команд для того, чтобы собрать необходимую информацию о состоянии сервера за 60 секунд. Я верю, что из этого доклада каждый «девопс» почерпнёт для себя что-нибудь новое и полезное.
Linux Systems Performance
Ретроспектива развития BI в Badoo
И конечно же, я не могу умолчать про доклад Badoo на Percona Live 2016. В докладе мы рассказали, как развивалась наша система бизнес-аналитики. С какими трудностями сталкивались, как их решали, какие технологии и при каких объемах данных работали, а также о том, как мы выбрали базу данных для аналитики.

В конце доклада мы рассказали о том, что самой актуальной задачей для нас является проблема сложности данных (сотни таблиц) и о том, как мы собираемся эту проблему решать.
BI at Badoo — historical retrospective
Fixing MySQL Bug#2: now MySQL makes toast!
Случилось невероятное! Через 14 лет мы наконец-то пофиксили баг номер 2. Прямо у нас на глазах MySQL сделал тост!

Итоги
По большому счету, весь пост — это большое спасибо организаторам за программу проведенной конференции. Дополнительно хочу отметить разные мелочи, которые помогли не отрываться от самой конференции: питание почти без очередей, отлично работающий Wi-Fi, наличие воды в кулерах, свободные места и возможность зарядки гаджетов в аудиториях для докладов, забавный квест по сбору печатей в зоне выставки и, конечно, проведение Percona Game Night.
Алексей Еремихин (@alexxz ), руководитель группы разработки BI
