
Привет, Хабр! Как-то раз на нашем внутреннем семинаре мой руководитель – глава отдела тестирования – начал свою речь со слов «тестирование не нужно». В зале все притихли, некоторые даже пытались упасть со стульев. Он продолжил свою мысль: без тестирования вполне возможно создать сложный и дорогостоящий проект. И, скорее всего, он будет работать. Но представьте, насколько увереннее вы будете себя ощущать, зная, что продукт работает как надо.
В Badoo релизы происходят довольно часто. Например, серверная часть наравне с desktop web релизится дважды в день. Так что мы не понаслышке знаем, что сложное и медленное тестирование – камень преткновения разработки. Быстрое же тестирование – это счастье. Итак, сегодня я расскажу о том, как в компании Badoo устроено smoke-тестирование.
Что такое smoke-тестирование
Первое своё применение этот термин получил у печников, которые, собрав печь, закрывали все заглушки, затапливали её и смотрели, чтобы дым шёл только из положенных мест. Википедия
В оригинальном своём применении smoke-тестирование предназначено для проверки самых простых и очевидных кейсов, без которой любой другой вид тестирования будет неоправданно излишним.
Давайте рассмотрим простой пример. Предпродакшн нашего приложения находится по адресу bryak.com (любые совпадения с реальными сайтами случайны). Мы подготовили и залили туда новый релиз для тестирования. Что стоит проверить в первую очередь? Я бы начал с проверки того, что приложение всё ещё открывается. Если web-сервер нам отвечает «200», значит, всё хорошо и можно приступать к проверке функционала.
Как автоматизировать такую проверку? В принципе, можно написать функциональный тест, который будет поднимать браузер, открывать нужную страницу и убеждаться, что она отобразилась как надо. Однако, у этого решения есть ряд минусов. Во-первых, это долго: процесс запуска браузера займёт больше времени, чем сама проверка. Во-вторых, это требует поддержания дополнительной инфраструктуры: ради такого простого теста нам потребуется где-то держать сервер с браузерами. Вывод: надо решить задачу иначе.
Наш первый smoke-тест
В Badoo серверная часть написана по большей части на PHP. Unit-тесты по понятным причинам пишутся на нём же. Итого у нас уже есть PHPUnit. Чтобы не плодить технологии без необходимости, мы решили писать smoke-тесты тоже на PHP. Помимо PHPUnit, нам потребуется клиентская библиотека работы с URL (libcurl) и PHP extension для работы с ней – cURL.
По сути, тесты просто делают нужные нам запросы на сервер и проверяют ответы. Всё завязано на методе getCurlResponse() и нескольких типах ассертов.
Сам метод выглядит примерно так:
public function getCurlResponse(
$url,
array $params = [
‘cookies’ => [],
‘post_data’ => [],
‘headers’ => [],
‘user_agent’ => [],
‘proxy’ => [],
],
$follow_location = true,
$expected_response = ‘200 OK’
)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
if (isset($params[‘cookies’]) && $params[‘cookies’]) {
$cookie_line = $this->prepareCookiesDataByArray($params[‘cookies’]);
curl_setopt($ch, CURLOPT_COOKIE, $cookie_line);
}
if (isset($params[‘headers’]) && $params[‘headers’]) {
curl_setopt($ch, CURLOPT_HTTPHEADER, $params[‘headers’]);
}
if (isset($params[‘post_data’]) && $params[‘post_data’]) {
$post_line = $this->preparePostDataByArray($params[‘post_data’]);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post_line);
}
if ($follow_location) {
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
}
if (isset($params[‘proxy’]) && $params[‘proxy’]) {
curl_setopt($ch, CURLOPT_PROXY, $params[‘proxy’]);
}
if (isset($params[‘user_agent’]) && $params[‘user_agent’]) {
$user_agent = $params[‘user_agent’];
} else {
$user_agent = USER_AGENT_DEFAULT;
}
curl_setopt($ch, CURLOPT_USERAGENT, $user_agent);
curl_setopt($ch, CURLOPT_AUTOREFERER, 1);
$response = curl_exec($ch);
$this->logActionToDB($url, $user_agent, $params);
if ($follow_location) {
$this->assertTrue(
(bool)$response,
'Empty response was received. Curl error: ' . curl_error($ch) . ', errno: ' . curl_errno($ch)
);
$this->assertServerResponseCode($response, $expected_response);
}
curl_close($ch);
return $response;
}Сам метод умеет по заданному URL возвращать ответ сервера. На вход принимает параметры, такие как cookies, headers, user agent и прочие данные, необходимые для формирования запроса. Когда ответ от сервера получен, метод проверяет, что код ответа совпадает с ожидаемым. Если это не так, тест падает с ошибкой, сообщающей об этом. Это сделано для того, чтобы было проще определить причину падения. Если тест упадёт на каком-нибудь ассерте, сообщив нам, что на странице нет какого-то элемента, ошибка будет менее информативной, чем сообщение о том, что код ответа, например, «404» вместо ожидаемого «200».
Когда запрос отправлен и ответ получен, мы логируем запрос, чтобы в дальнейшем при необходимости легко воспроизвести цепочку событий, если тест упадёт или сломается. Я об этом расскажу ниже.
Самый простой тест выглядит примерно так:
public function testStartPage()
{
$url = ‘bryak.com’;
$response = $this->getCurlResponse($url);
$this->assertHTMLPresent('<body>', $response, 'Error: test cannot find body element on the page.');
}Такой тест проходит менее чем за секунду. За это время мы проверили, что стартовая страница отвечает «200», и на ней есть элемент body. С тем же успехом мы можем проверить любое количество элементов на странице, продолжительность теста существенно не изменится.
Плюсы таких тестов:
- скорость – тест можно запускать так часто, как это необходимо. Например, на каждое изменение кода;
- не требуют специального софта и железа для работы;
- их несложно писать и поддерживать;
- они стабильные.
По поводу последнего пункта. Я имею в виду – не менее стабильные, чем сам проект.

Авторизация
Представим, что с момента, как мы написали наш первый smoke-тест, прошло три дня. Само собой, за это время мы покрыли все неавторизованные страницы, какие только нашли, тестами. Немного посидели, порадовались, но потом осознали, что всё самое важное в нашем проекте находится за авторизацией. Как бы получить возможность это тоже тестировать?

Чем отличается авторизованная страница от неавторизованной? С точки зрения сервера всё просто: если в запросе есть информация, по которой пользователя можно идентифицировать, нам вернётся авторизованная страница.
Самый просто вариант – авторизационная cookie. Если добавить её к запросу, то сервер нас «узнает». Такую cookie можно захардкодить в тесте, если её время жизни довольно большое, а можно получать автоматически, отправляя запросы на страницу авторизации. Давайте подробнее рассмотрим второй вариант.
На нашем сайте страница авторизации выглядит так:
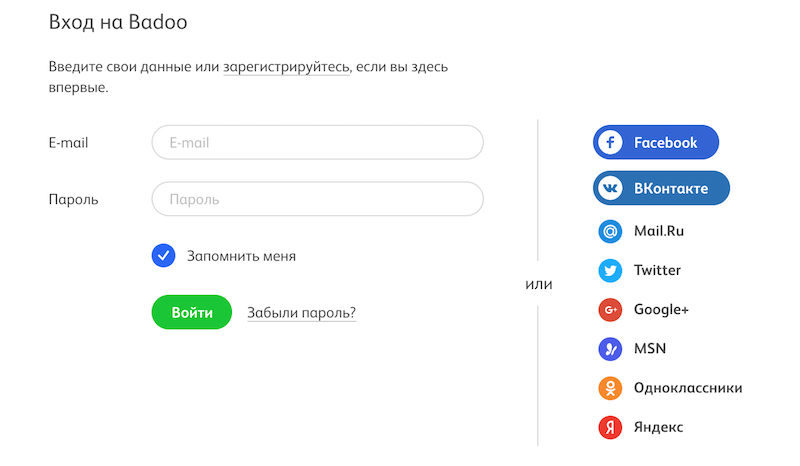
Нас интересует форма, куда надо ввести логин и пароль пользователя.
Открываем эту страницу в любом браузере и открываем инспектор. Вводим данные пользователя и сабмитим форму.
В инспекторе появился запрос, который нам надо имитировать в тесте. Можно посмотреть, какие данные, помимо очевидных (логин и пароль), отсылаются на сервер. Для каждого проекта по-разному: это может быть remote token, данные каких-либо cookies, полученных ранее, user agent и так далее. Каждый из этих параметров придётся предварительно получить в тесте, прежде чем сформировать запрос на авторизацию.
В инструментах разработчика любого браузера можно скопировать запрос, выбрав пункт copy as cURL. В таком виде команду можно вставить в консоль и рассматривать там. Там же её можно опробовать, поменяв или добавив параметры.

В ответ на такой запрос сервер вернёт нам cookies, которые мы будем добавлять в дальнейшие запросы, чтобы тестировать авторизованные страницы.
Поскольку авторизация – довольно долгий процесс, авторизационную cookie я предлагаю получать только один раз для каждого пользователя и сохранять где-то. У нас, например, такие cookies хранятся в массиве. Ключом является логин пользователя, а значением – информация о них. Если для следующего пользователя ключа ещё нет, авторизуемся. Если есть – делаем интересующий нас запрос сразу.
Пример кода теста, проверяющего авторизованную страницу, выглядит примерно так:
public function testAuthPage()
{
$url = ‘bryak.com’;
$cookies = $this->getAuthCookies(‘employee@bryak.com’, ‘12345’);
$response = $this->getCurlResponse($url, [‘cookies’ => $cookies]);
$this->assertHTMLPresent('<body>', $response, 'Error: test cannot find body element on the page.');
}Как мы видим, добавился метод, который получает авторизационную cookie и просто добавляет её в дальнейший запрос. Сам метод реализуется довольно просто:
public function getAuthCookies($email, $password)
{
// check if cookie already has been got
If (array_key_exist($email, self::$known_cookies)) {
return self::$known_cookies[$email];
}
$url = self::DOMAIN_STAGING . ‘/auth_page_adds’;
$post_data = [‘email’ => $email, ‘password’ => $password];
$response = $this->getCurlResponse($url, [‘post_data’ => $post_data]);
$cookies = $this->parseCookiesFromResponse($response);
// save cookie for further use
self::$known_cookies[$email] = $cookies;
return $cookies;
}Метод сначала проверяет, есть ли для данного e-mail (в вашем случаем это может быть логин или что-то ещё) уже полученная ранее авторизационная cookie. Если есть, он её возвращает. Если нет, он делает запрос на авторизационную страницу (например, bryak.com/auth_page_adds) с необходимыми параметрами: e-mail и пароль пользователя. В ответ на этот запрос сервер присылает заголовки, среди которых есть интересующие нас cookies. Выглядит это примерно так:
HTTP/1.1 200 OK
Server: nginx
Content-Type: text/html; charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
Set-Cookie: name=value; expires=Wed, 30-Nov-2016 10:06:24 GMT; Max-Age=-86400; path=/; domain=bryak.comИз этих заголовков нам при помощи несложного регулярного выражения надо получить название cookie и её значение (в нашем примере это name=value). У нас метод, который парсит ответ, выглядит так:
$this->assertTrue(
(bool)preg_match_all('/Set-Cookie: (([^=]+)=([^;]+);.*)\n/', $response, $mch1),
'Cannot get "cookies" from server response. Response: ' . $response
);После того, как cookies получены, мы можем смело добавлять их в любой запрос, чтобы сделать его авторизованным.
Разбор падающих тестов
Из вышесказанного следует, что такой тест – это набор запросов к серверу. Делаем запрос, совершаем манипуляцию с ответом, делаем следующий запрос и так далее. В голову закрадывается мысль: если такой тест упадёт на десятом запросе, может оказаться непросто разобраться в причине его падения. Как упростить себе жизнь?
Прежде всего я бы хотел посоветовать максимально атомизировать тесты. Не стоит в одном тесте проверять 50 различных кейсов. Чем тест проще, тем с ним проще будет в дальнейшем.
Ещё полезно собирать артефакты. Когда наш тест падает, он сохраняет последний ответ сервера в HTML-файлик и закидывает в хранилище артефактов, где этот файлик можно открыть из браузера, указав название теста.
Например, тест у нас упал на том, что не может найти на странице кусочек HTML:
<span class=”link”>Link<span>Мы заходим на наш коллектор и открываем соответствующую страницу:
С этой страницей можно работать так же, как с любой другой HTML-страничкой в браузере. Можно при помощи CSS-локатора попытаться разыскать пропавший элемент и, если его действительно нет, решить, что либо он изменился, либо потерялся. Возможно, мы нашли баг! Если элемент на месте, возможно, мы где-то ошиблись в тесте – надо внимательно посмотреть в эту сторону.
Ещё упростить жизнь помогает логирование. Мы стараемся логировать все запросы, которые делал упавший тест, так, чтобы их легко можно было повторить. Во-первых, это позволяет быстро руками совершить набор аналогичных действий для воспроизведения ошибки, во-вторых – выявить часто падающие тесты, если такие у нас имеются.
Помимо помощи в разборе ошибок, логи, описанные выше, помогают нам формировать список авторизованных и неавторизованных страниц, которые мы протестировали. Глядя на него, легко искать и устранять пробелы.
Последнее, но не по важности, что могу посоветовать – тесты должны быть настолько удобными, насколько это возможно. Чем проще их запустить, тем чаще их будут использовать. Чем понятнее и лаконичнее отчет о падении, тем внимательнее его изучат. Чем проще архитектура, тем больше тестов будет написано и тем меньше времени будет занимать написание нового.
Если вам кажется, что тестами пользоваться неудобно – скорее всего вам не кажется. С этим необходимо бороться как можно скорее. В противном случае вы рискуете в какой-то момент начать обращать меньше внимания на эти тесты, а это уже может привести к пропуску ошибки на продакшн.

На словах мысль кажется очевидной, согласен. Но на деле всем нам есть куда стремиться. Так что упрощайте и оптимизируйте свои творения и живите без багов. :)
Итоги
На данный момент у нас *открываю Тимсити* ого, уже 605 тестов. Все тесты, если их запускать не параллельно, проходят чуть меньше, чем за четыре минуты.
За это время мы убеждаемся, что:
- наш проект открывается на всех языках (которых у нас более 40 на продакшене);
- для основных стран отображаются корректные формы оплаты с соответствующим набором способов оплаты;
- корректно работают основные запросы к API;
- корректно работает лендинг для редиректов (в том числе и на мобильный сайт при соответствующем юзер-агенте);
- все внутренние проекты отображаются правильно.
Тестам на Selenium WebDriver для всего этого потребовалось бы в разы больше времени и ресурсов.
Конечно, это не замена Selenium. Нам всё равно придётся проверять корректное поведение клиента и кросс-браузерные кейсы. Мы можем заменить лишь те тесты, которые проверяют поведение сервера. Но, помимо этого, мы можем осуществлять предварительное тестирование, быстрое и простое. Если на этапе smoke-тестирования нашлись ошибки и «дым идёт не оттуда», возможно, запускать долгий набор тяжеловесных Selenium-тестов до фиксов смысла нет? Это уже на ваше усмотрение! :)
Спасибо за внимание.
Виталий Котов, QA-инженер по автоматизации.
