 Как вы знаете, ABBYY занимается разработкой технологии анализа естественных языков Compreno. Сейчас система работает на английском и русском языках, и активно используется во многих проектах. Однако изначально сама технология была задумана как многоязычная, поэтому мы много внимания уделяем и «обучению» другим иностранным языкам. И тут можно провести некоторую аналогию с человеком: после изучения одного иностранного языка другие даются легче. В частности, сейчас мы добавляем в технологию немецкий язык и параллельно исследуем возможности рынка – есть ли интерес к этому направлению. Сразу оговоримся – пока речь о продуктах, поддерживающих немецкий, не идёт, мы в самом начале пути.
Как вы знаете, ABBYY занимается разработкой технологии анализа естественных языков Compreno. Сейчас система работает на английском и русском языках, и активно используется во многих проектах. Однако изначально сама технология была задумана как многоязычная, поэтому мы много внимания уделяем и «обучению» другим иностранным языкам. И тут можно провести некоторую аналогию с человеком: после изучения одного иностранного языка другие даются легче. В частности, сейчас мы добавляем в технологию немецкий язык и параллельно исследуем возможности рынка – есть ли интерес к этому направлению. Сразу оговоримся – пока речь о продуктах, поддерживающих немецкий, не идёт, мы в самом начале пути.Что такое Compreno?
Прежде чем говорить о добавлении «новых» языков, поговорим о «старых», точнее об исходной базе данных, которая была построена на основе русского и английского языков.
Несмотря на то, что про Compreno есть уже немало научных публикаций,
(ссылки на них - под спойлером)
да и в прессе давалось описание базовых принципов, все же остается много вопросов к тому, что это все-таки такое и что оно умеет делать. Поэтому мы еще раз «заглянем под капот» технологии, чтобы посмотреть, каковы её основные принципы и как они реализуются в многоязычности. ● Anisimovich K. V., Druzhkin K. Ju., Minlos F. R., Petrova M. A., Selegey V. P. Zuev K. A. Syntactic and semantic parser based on ABBYY Compreno linguistic technologies. In: Computational linguistics and intellectual technologies. 2012, Vol. 11.
● Selegey V. 2012. On automated semantic and syntactic annotation of texts for lexicographic purposes. // Proceedings of the International Conference “Euralex 2012”
● E. Manicheva, M. Petrova, E. Kozlova & T. Popova — The COMPRENO semantic model as integral framework for multilingual lexical database
= Proceedings of the 3rd Workshop on Cognitive Aspects of the Lexicon, COLING conference, Mumbai, 2012
● Богданов А. В. Описание гэппинга в системе автоматического перевода // Диалог 2012
● А.В. Богданов, А.П. Леонтьев. Описание русской конструкции с внешним посессором в системе автоматической обработки естественного языка. Александр Евгеньевич Кибрик. In Memoriam. Материалы научно-мемориальных чтений памяти А.Е. Кибрика. 9 декабря 2012 г. М.: Изд-во Моск. ун-та, 2012
● Zuyev K. A., Indenbom E. M., Yudina M. V. Statistical machine translation with linguistic language model. In: Computational linguistics and intellectual technologies. 2013, Vol. 12
● M.Goncharova, E. Kozlova, T. Popova. Lexique multilingue dans le cadre du modèle linguistique Compreno développé par ABBYY. In: 20 conférence du Traitement Automatique du Langage Naturel 2013 (TALN 2013)
● Bogdanov A. V., Leontyev A. P. Description of the Russian external possessor construction in a natural language processing system, Dialogue 2013
● M.A. Petrova, THE COMPRENO SEMANTIC MODEL: THE UNIVERSALITY PROBLEM
The Compreno Semantic Model: The Universality Problem // International Journal of Lexicography (2014) 27 (2): 105-129. doi: 10.1093/ijl/ect038
● Nekhay I. V. The prospects of application of semantic markup to the named entity recognition problem, Dialogue 2013
● Marina KULICHIKHINA, Natalia RUBAN. Semantisches Wörterbuch der deutschen Sprache für maschinelle Sprachverarbeitungssysteme. In: Aussiger Beiträge — Germanistische Schriftenreihe aus Forschung und Lehre 7 (2013). Lexikologie und Lexikografie. Aktuelle Entwicklungen und Herausforderungen (hrsg. von Hana Bergerová, Marek Schmidt und Georg Schuppener), 310 S., h-net.msu.edu/cgi-bin/logbrowse.pl?trx=vx&list=H-Germanistik&month=1401&week=c&msg=MDHb3ZWmZ6YjUOXokqHvjA
ff.ujep.cz/files/kger/ab/ab203_abstracts_en.pdf
● Elena KOZLOVA, Maria GONCHAROVA. Le modèle linguistique Compreno développé par ABBYY. In: 82e du Congrès de l'Acfas — Colloque 635 — Langues naturelles, informatique et sciences cognitives, May 2014, Montréal, Canada
● Elena KOZLOVA, Maria GONCHAROVA. ABBYY Compreno technology and its applications for information extraction and semantic search. In: 27th Canadian Conference on Artificial Intelligence, Canadian AI 2014, Montréal, QC, Canada, May 6-9, 2014
● Irina Burukina. Translating implicit elements in RBMT
● Использование технологии ABBYY Compreno для обработки текстов на естественном языке. Доклад на конференции AINL 2013, Санкт-Петербург
● Технология разработки предметно-ориентированных систем извлечения информации. Доклад на конференции AINL 2014, Москва
● Bogdanov A. V., Dzhumaev S. S., Skorinkin D. A., Starostin A. S. ANAPHORA ANALYSIS BASED ON ABBYY COMPRENO LINGUISTIC TECHNOLOGIES // Dialogue 2014
● Leontiev A. P., Petrova M. A. The description of locative dependencies in a natural language processing model //Dialogue 2014
● Starostin A., Smurov I., Stepanova M., A Production System for Information Extraction Based on Complete Syntactic Semantic Analysis. Computational Linguistics and Intellectual Technologies: Papers from the Annual International Conference “Dialogue” (2014), Bekasovo, June 2014, pp. 659-667
● Bogdanov A. V., Gorbunova I. M. The Case of Russian Subject Pro in Machine Translation System //Диалог 2015
● Гончарова M. Б., Козлова E. А., Пасюков А. В., Гаращук Р. В., Селегей В. П. Смысловое выравнивание, основанное на лингвистической модели, как средство интеграции нового языка в многоязычную лексико-семантическую базу данных c интерлингвой //Диалог 2015
● Skorinkin D. A. Wardrobe and Peas: Understanding Leo Tolstoy with ABBYY Compreno //Диалог 2015
● Selegey V. 2012. On automated semantic and syntactic annotation of texts for lexicographic purposes. // Proceedings of the International Conference “Euralex 2012”
● E. Manicheva, M. Petrova, E. Kozlova & T. Popova — The COMPRENO semantic model as integral framework for multilingual lexical database
= Proceedings of the 3rd Workshop on Cognitive Aspects of the Lexicon, COLING conference, Mumbai, 2012
● Богданов А. В. Описание гэппинга в системе автоматического перевода // Диалог 2012
● А.В. Богданов, А.П. Леонтьев. Описание русской конструкции с внешним посессором в системе автоматической обработки естественного языка. Александр Евгеньевич Кибрик. In Memoriam. Материалы научно-мемориальных чтений памяти А.Е. Кибрика. 9 декабря 2012 г. М.: Изд-во Моск. ун-та, 2012
● Zuyev K. A., Indenbom E. M., Yudina M. V. Statistical machine translation with linguistic language model. In: Computational linguistics and intellectual technologies. 2013, Vol. 12
● M.Goncharova, E. Kozlova, T. Popova. Lexique multilingue dans le cadre du modèle linguistique Compreno développé par ABBYY. In: 20 conférence du Traitement Automatique du Langage Naturel 2013 (TALN 2013)
● Bogdanov A. V., Leontyev A. P. Description of the Russian external possessor construction in a natural language processing system, Dialogue 2013
● M.A. Petrova, THE COMPRENO SEMANTIC MODEL: THE UNIVERSALITY PROBLEM
The Compreno Semantic Model: The Universality Problem // International Journal of Lexicography (2014) 27 (2): 105-129. doi: 10.1093/ijl/ect038
● Nekhay I. V. The prospects of application of semantic markup to the named entity recognition problem, Dialogue 2013
● Marina KULICHIKHINA, Natalia RUBAN. Semantisches Wörterbuch der deutschen Sprache für maschinelle Sprachverarbeitungssysteme. In: Aussiger Beiträge — Germanistische Schriftenreihe aus Forschung und Lehre 7 (2013). Lexikologie und Lexikografie. Aktuelle Entwicklungen und Herausforderungen (hrsg. von Hana Bergerová, Marek Schmidt und Georg Schuppener), 310 S., h-net.msu.edu/cgi-bin/logbrowse.pl?trx=vx&list=H-Germanistik&month=1401&week=c&msg=MDHb3ZWmZ6YjUOXokqHvjA
ff.ujep.cz/files/kger/ab/ab203_abstracts_en.pdf
● Elena KOZLOVA, Maria GONCHAROVA. Le modèle linguistique Compreno développé par ABBYY. In: 82e du Congrès de l'Acfas — Colloque 635 — Langues naturelles, informatique et sciences cognitives, May 2014, Montréal, Canada
● Elena KOZLOVA, Maria GONCHAROVA. ABBYY Compreno technology and its applications for information extraction and semantic search. In: 27th Canadian Conference on Artificial Intelligence, Canadian AI 2014, Montréal, QC, Canada, May 6-9, 2014
● Irina Burukina. Translating implicit elements in RBMT
● Использование технологии ABBYY Compreno для обработки текстов на естественном языке. Доклад на конференции AINL 2013, Санкт-Петербург
● Технология разработки предметно-ориентированных систем извлечения информации. Доклад на конференции AINL 2014, Москва
● Bogdanov A. V., Dzhumaev S. S., Skorinkin D. A., Starostin A. S. ANAPHORA ANALYSIS BASED ON ABBYY COMPRENO LINGUISTIC TECHNOLOGIES // Dialogue 2014
● Leontiev A. P., Petrova M. A. The description of locative dependencies in a natural language processing model //Dialogue 2014
● Starostin A., Smurov I., Stepanova M., A Production System for Information Extraction Based on Complete Syntactic Semantic Analysis. Computational Linguistics and Intellectual Technologies: Papers from the Annual International Conference “Dialogue” (2014), Bekasovo, June 2014, pp. 659-667
● Bogdanov A. V., Gorbunova I. M. The Case of Russian Subject Pro in Machine Translation System //Диалог 2015
● Гончарова M. Б., Козлова E. А., Пасюков А. В., Гаращук Р. В., Селегей В. П. Смысловое выравнивание, основанное на лингвистической модели, как средство интеграции нового языка в многоязычную лексико-семантическую базу данных c интерлингвой //Диалог 2015
● Skorinkin D. A. Wardrobe and Peas: Understanding Leo Tolstoy with ABBYY Compreno //Диалог 2015
Итак, Compreno – это
• технология семантико-синтаксического анализа текста,
• основанного на языковой модели
• и на статистических данных.
Конечно, такое определение пока не прояснило ситуацию, поэтому разберем его по частям.
«Compreno — это технология семантико-синтаксического анализа текста». Семантический анализ реализуется за счет того, что в базе данных Compreno описаны и сложены в семантическую иерархию значения слов разных языков. Сама по себе семантическая иерархия задумана как интерлингва (межъязыковой уровень), состоящая из понятий, которые есть в каждом языке. На данный момент в системе 145 000 таких понятий. Каждое такое понятие содержит одно или несколько значений конкретного языка. Например, понятие CONTRACT реализуется русскими значениями договор, контракт, соглашение и др. и английскими contract, agreement, treaty и др. Смысловые узлы могут заполняться как отдельными словами, так и группами слов (здравоохранение – public health). Иерархия представляет собой не семантическую сеть, а семантическое дерево, что позволяет передавать признаки по наследству от родителя к потомкам. Синтаксический анализ возможен потому, что для каждого языка есть свое синтаксическое описание, т.е. «грамматика», которая учитывает и морфологические признаки, и признаки частеречные, и грамматические особенности, объясняющиеся значением слова. Например, находиться в значении POSITION_IN_SPACE употребляется только возвратно, в отличие от находиться в значении TO_FIND (Дом находится в саду. — Слова нелегко находятся в тексте).
«Compreno — это технология семантико-синтаксического анализа текста, основанного на языковой модели». В базе данных описаны не только значения слов и их грамматические признаки, но и системно описаны возможные связи между значениями – как смысловые, так и грамматические, которые мы и называем Моделью. Смысловые связи мы именуем глубинными позициями (#[[Possessor: Компания] [Time: ежегодно] Predicate: закупает [[у] Source: поставщика] [Object: оборудование]]). В нашей системе около 300 таких семантических «ролей». Грамматические связи описываются с помощью поверхностных позиций (#[[$Subject: Компания] [$AdjunctTime: ежегодно] $Verb: закупает [[$Preposition: у] $Object_Indirect_У: поставщика] [$Object_Direct: оборудование]]).
«Compreno — это технология семантико-синтаксического анализа текста, основанного на языковой модели и на статистических данных». При анализе текста Compreno опирается на подробную языковую модель, а также на оценки вероятностей. Языковая модель определяет то, какие варианты анализа в принципе возможны. Статистика подсказывает, какие из возможных вариантов наиболее вероятны. Статистический компонент нашей системы обучается на параллельных (русско-английско-немецких) и моноязычных текстовых корпусах.
Таким образом, Compreno – это технология, которая в некоторой степени моделирует языковое (именно языковое) мышление человека, то, как человек определяет значения слов и связи между ними в предложении.
Посмотрим, как происходит семантико-синтаксический анализ на примере неоднозначной фразы зеленые ели. Compreno анализирует текст по принципу Микеланджело: берет все возможное, а затем постепенно отсекает лишнее.

Крупнее
Так, на начальных этапах проверяется морфология, какими формами от каких слов, в каком роде, числе, падеже могут в принципе быть слова «зеленые» и «ели». Идем в семантическую иерархию и смотрим, в каких значениях есть такие слова (GREEN, ENVIRONMENTALIST, FIR, TO_EAT). Далее рассматриваются все возможные грамматические и семантические связи между ними, несовместимые формы отсекаются, после чего строятся семантико-синтаксические структуры. С помощью целого ряда статистических оценок на базе частоты встречаемости того или иного явления, слова в том или ином значении и т.п. в размеченных корпусах выбирается структура-«победитель». На финальном этапе все признаки исходного языках удаляются, и остается только смысловая структура с семантическими связями и универсальными понятиями иерархии в качестве узлов.
Зачем нужна технология Compreno?
За счет модели Compreno выявляет смысловые связи в тексте (Что? Кто? Когда? Куда? Почему? Зачем? Кому? Сколько? и т.д.), которые могут быть по-разному выражены синтаксически. Соответственно, технология лучше всего применима там, где от машины требуется разобраться в контекстах, в сложных смысловых высказываниях, зачастую сложно синтаксически оформленных (анализ текста договоров, переписки и т.п.). Для анализа специальных текстов соответствующие ветки расширяются терминологической лексикой.
На основе лингвистической технологии Compreno решаются разные прикладные задачи, связанные с обработкой текстовой информации:
— извлечение информации,
— семантическая классификация,
— семантический поиск
— и т.п.
Как реализуется многоязычность?
В отличие от многих семантических систем, в основе Compreno с самого начала был заложен принцип многоязычности. Об этом говорит сам факт того, что система создавалась не на одном, а сразу на двух языках — русском и английском — имеющих разные способы языкового отображения реальности. Например, в русском языке широко используются производные от слов (убежать-забежать-оббежать), а в английском наблюдается тенденция выражать то же самое дополнительными словами (run away-run into-run around). В нашей системе дополнительные смыслы, будь они выражены приставкой или отдельным словом, кодируются одним смысловым признаком, или семантемой, не зависящей от конкретного языка («Depart»-«To»-«InVariousDirections»). Структура иерархии учитывает также тот факт, что широкое понятие в одном языке (go) может соответствовать нескольким более узким понятиям в других (ехать, идти; gehen, fahren). Таким образом, иерархия значений не привязана к логике одного языка, а задумана как межъязыковой уровень, или интерлингва. Добавленное значение сразу получает соответствие во всех описанных языках.
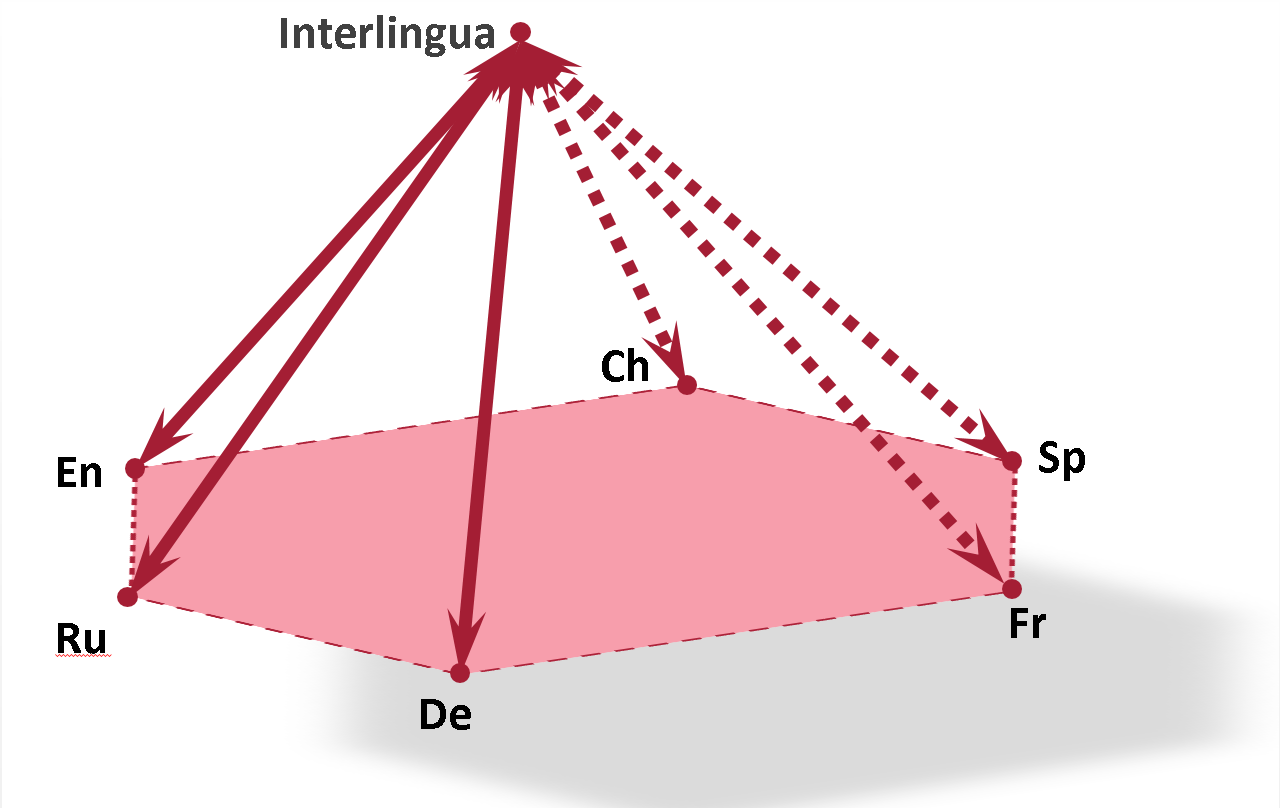
Поскольку при анализе текста получается структура, включающая смыслы и смысловые связи, одна глубинная структура может быть результатом разных конкретных реализаций одного смысла в разных языках:

Крупнее
За счет чего можно ускорить описание новых языков в семантических системах?
Рано или поздно идея ускорить описание значений новых интегрируемых языков приходит в голову всем, кто занимается семантическим анализом текста. Почему? Потому что описание всех значений даже одного-двух языков «вручную» требует огромных ресурсов и не меньшей силы духа, чтобы довести дело до результата. А имея один-два хорошо описанных языка, т.е. имея структуру и методику описания, «ручное» описание уже не нужно, потому что можно очень эффективно использовать параллельные или многоязычные ресурсы, в которых есть связи между языками. В современной лингвистике это называется смысловым выравниванием ресурсов (Word Sense Alignment), т.е. сопоставлением значений в разных источниках. Сам термин Word Sense Alignment изначально использовался для обозначения такого выравнивания, которое имело целью собрать разную информацию про одно значение. Например, в одном источнике есть хорошее определение, в другом — примеры, в третьем — синонимы и т.д., ведь изначально не было такого ресурса, который ставил бы перед собой амбициозную цель описать «все», каждый был ориентирован на что-то «свое». Но по сути тот же принцип сопоставления значений применяется при автоматической интеграции новых языков в семантические системы.
Для добавления новых языков в разных подходах смыслового выравнивания ресурсов используются:
— дву- или многоязычные словари;
— энциклопедические или онтологические ресурсы (например, Wikipedia), где есть гиперссылки между языками;
— параллельные корпуса;
— машинный перевод.
Также используется выравнивание готовых семантических сетей между собой.
Как Compreno учит новые языки?
В результате «изучения» русского и английского языков, универсальное семантическое дерево Compreno выросло и разрослось. Отдельные его части могут меняться, расширяться и дополняться, но принципы и основная структура после многолетнего непрерывного тестирования могут считаться рабочими. За счет готового универсального описания нужно меньше усилий для описания нового языка. Мы покажем это на примере немецкого.
Алгоритм добавления нового языка состоит в том, что программа анализирует часть параллельных пословно выровненных источников на «выученном» языке и через глубинную структуру предполагает, в какую часть иерархии добавить значение нового языка. Работа лингвиста сводится к проверке того, что предположила программа, и описанию сложных явлений. Однако нужно понимать, что полуавтоматическому этапу всегда предшествует «ручная» работа по подробному описанию синтаксиса, ядерной лексики (около 5000 значений) и модели основных веток.
Как мы используем смысловое выравнивание для добавления нового языка?
Итак, наша задача – найти место в иерархии не просто для немецкого слова, а именно для значений этого слова, которые мы берем из двуязычного немецко-английского словаря. Делаем это с помощью парсера, т.е. программы, анализирующей текст. Уникальность Compreno-парсера в том, что он строит не только синтаксическую, но и смысловую структуру предложений. Мы анализируем известное нам, т.е. английскую часть словарной статьи, и через глубинную структуру получаем гипотезы о том, как нам позиционировать немецкое значение в иерархии. По сути дела, мы выравниваем значения словаря с универсальными значениями нашей иерархии.
Однако в словарной статье довольно мало контекстов, необходимых для правильного разбора через Compreno-парсер. Поэтому для улучшения результата мы используем анализ параллельных англо-немецких текстовых корпусов, также автоматически разобранных нашим парсером. В реальных предложениях контексты гораздо более ясные, и для каждой гипотезы известна ее частотность, т.е. сколько раз такое соответствие встретилось в корпусе. Точно так же человеку для изучения языка недостаточно выучить все словарные значения, ему нужны реальные тексты.
Результаты анализа параллельных корпусов и словарной статьи сравниваются, универсальные значения, которые встретились и там, и там, считаются первичной гипотезой для позиционирования, то есть для размещения значения в нашей универсальной иерархии. Далее эти гипотезы проходят несколько дополнительных фильтров. И только самые-самые лучшие попадают в «финал».
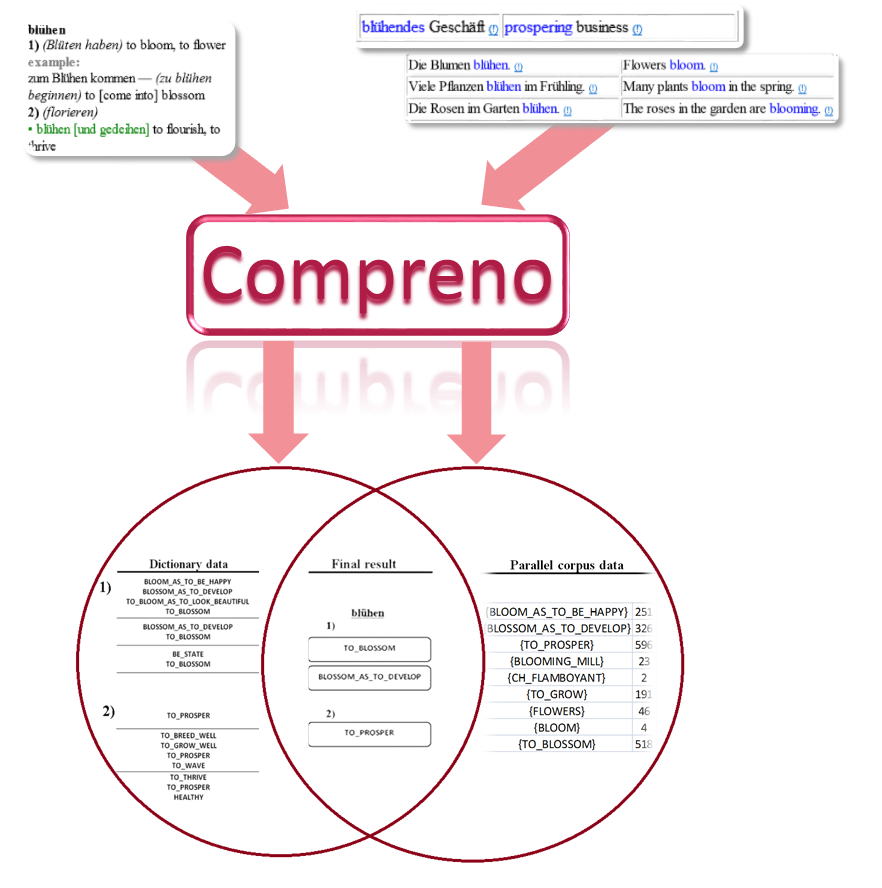
Посмотрим, как это происходит, на примере значений немецкого глагола blühen. Берем словарную статью, в которой выделяется два значения (цвести, процветать), для каждого из которых нам нужно найти место в иерархии. Анализируем английскую часть статьи и получаем список гипотез для каждого значения. Берем выровненный пословно параллельный англо-немецкий корпус, в котором известно не только то, что blühendes Geschäft – это prospering business, но и то, что blühendes — это prospering, а Geschäft – это business. Анализируем английскую часть, при этом каждая гипотеза из получившегося списка имеет показатель частотности. Программа алгоритма пересекает два множества, в результате для первого значения blühen остаются две гипотезы добавления в иерархию (TO_BLOSSOM, BLOSSOM_AS_TO_DEVELOP), а для второго — одна (TO_PROSPER).
Иногда список гипотез, получившийся после пересечения, все еще довольный длинный, что неудобно для быстрого просмотра лингвистом. Поэтому гипотезы, которые получились по результатам анализа перевода, синонимов и примеров из словарной статьи, проходят несколько фильтров.
В качестве примера рассмотрим первое значение из словарной статьи Beweis (свидетельство, доказательство). Анализ словарной статьи складывается из анализа переводов, примеров и синонимов. После пересечения результатов анализа словарной статьи и корпусов мы получили достаточно большой список гипотез из семи понятий. Чтобы сократить его и упростить задачу проверки лингвисту, применяем дополнительные фильтры, перечисленные на картинке:
Beweis
1) ·JUR (Nachweis) proof, evidence
example:
● im Hintergrund wurden Beweise gegen ihn gesammelt — evidence was secretly [being] gathered against him
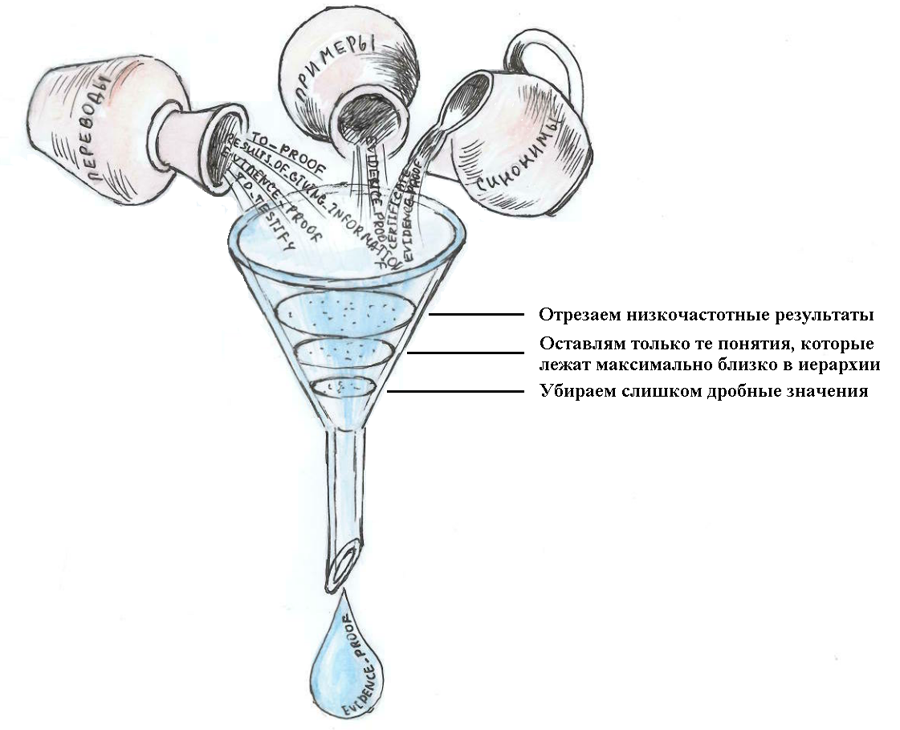
После применения фильтров список сократился до одного понятия – EVIDENCE_PROOF.
Что получили?
В итоге для 121852 значений из 92985 словарных статей немецко-английского словаря мы получили гипотезы позиционирования в иерархии. Это позволило ускорить работу лингвистов в 10 раз по простой лексике и в 5 раз – по сложной.
Что планируем получить?
Итак, в результате эксперимента с немецким языком мы опробовали собственное универсальное средство выравнивания ресурсов на основе семантико-синтаксического парсера Compreno. По сути, оно может быть применено не только для добавления значений новых языков из общелексического словаря в семантическую иерархию, но и для заполнения, например, терминологических лакун в иерархии с использованием дополнительных ресурсов, Wikipedia или специальных словарей. Например, статьи для USt-IdNr.( ИНН ) нет в общелексических немецких словарях, однако есть статья в Wikipedia и юридическом словаре.
Статья написана по материалам доклада, представленного на международной конференции по компьютерной лингвистике «Диалог». О конференциях прошлых лет мы писали в нашем блоге здесь, здесь и здесь. Если вы хотите сделать доклад на «Диалоге» в-2016 году, вы можете подать заявку в программный комитет начиная с конца декабря 2015 года (следите за объявлениями на сайте www.dialog-21.ru). Регистрация для слушателей конференции начинается в конце апреля 2016 года.
Мария Гончарова,
Елена Козлова,
департамент разработки технологий

{kind=link}
{kind=link}