Комментарии 3
в качестве теста рекомендую проверить распознавание на актере Брюсе Уилесе с его «широким» спектром эмоций
Какая-то слабая статья. В заголовке что-то про распознавание эмоций, но при этом на самом деле 2/3 статьи — это введение в ML и описания какого-то бойлерплейта вроде разбиения датасета на тренировочную и тестовую часть. При этом описанный приём — это вообще не то, что на самом деле надо делать для подобной задачи (1600 семплов, и вы учите сеть с нуля? Понятно, почему в конце получается такая плохая точность).
Ссылка на сорсы ведёт на страницу ошибки дропбокса (вы в Intel используете дропбокс в качестве source control, серьёзно?), а код в тексте вставлен картинками (это вообще за гранью добра и зла), что делает этот курс абсолютно невоспроизводимым и непрактичным.
Ссылка на сорсы ведёт на страницу ошибки дропбокса (вы в Intel используете дропбокс в качестве source control, серьёзно?), а код в тексте вставлен картинками (это вообще за гранью добра и зла), что делает этот курс абсолютно невоспроизводимым и непрактичным.
Также продолжаю традицию исправления факапов в переводах Intel, потому что авторы блога не удосужились дать перевод на вычитку специалисту в ML.
Классификация не двоичная, а бинарная.
В оригинале «Train/Validation Split» — разделение датасета на тренировочную и валидационную часть (это очевидно по дальнейшему тексту абзаца).
Имеется в виду 100% точность при валидации на тренировочных семплах.
Google Translate meets «overfitting/underfitting».
На самом деле: «Демонстрирует плохие предсказания даже на обучающем наборе данных».
Снова Google Translate для перевода «hold-out».
Пардон, но у вас он не справа.
Fixed seed — это не фиксированное число, а фиксированный инициализатор генератора случайных чисел.
Shearing — это не свёртка, а деформация сдвигом.
То чувство, когда приходится лезть в оригинал, чтобы понять, что речь про дропаут.
На самом деле: «Одним из возможных признаков оверфита являются чрезвычайно различные (отличающиеся на порядок) значения весовых коэффициентов.»
Снова Google Translate.
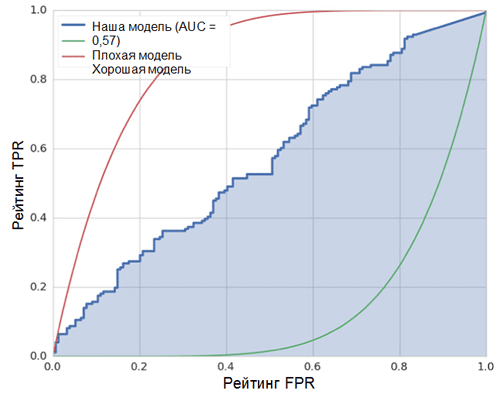
Rate — это уровень, а не рейтинг.
При переводе легенда сломалась, но всем пофиг.
задачу двоичной классификации
Классификация не двоичная, а бинарная.
Разделение процесса обучения/проверки
В оригинале «Train/Validation Split» — разделение датасета на тренировочную и валидационную часть (это очевидно по дальнейшему тексту абзаца).
100-процентную точность при обучении на примерах, которые использовались для этого много раз
Имеется в виду 100% точность при валидации на тренировочных семплах.
Данная проблема называется сверхподгонкой и является одной из важнейших в машинном обучении. Также существует и проблема недоподгонки
Google Translate meets «overfitting/underfitting».
демонстрирует плохие предсказания даже при использовании фиксированного обучающего набора данных
На самом деле: «Демонстрирует плохие предсказания даже на обучающем наборе данных».
техника удерживания части образцов
Снова Google Translate для перевода «hold-out».
см. рисунок справа
Пардон, но у вас он не справа.
с помощью фиксированного случайного числа
Fixed seed — это не фиксированное число, а фиксированный инициализатор генератора случайных чисел.
таких как поворот, сдвиг, свертка, масштабирование и горизонтальный поворот
Shearing — это не свёртка, а деформация сдвигом.
Полносвязный слой + метод исключения
То чувство, когда приходится лезть в оригинал, чтобы понять, что речь про дропаут.
Одним из возможных признаков сверхподгонки являются чрезвычайно различные значения весовых коэффициентов (порядки соответствующих величин).
На самом деле: «Одним из возможных признаков оверфита являются чрезвычайно различные (отличающиеся на порядок) значения весовых коэффициентов.»
перекрестная энтропия проверки и точность
Снова Google Translate.
Рейтинг FPR
Rate — это уровень, а не рейтинг.
hsto.org/webt/oo/vu/-t/oovu-t0vyxvlbgb4zgp4qyvodsw.png
{kind=link}
При переводе легенда сломалась, но всем пофиг.
По заголовку и первой картинке складывается впечатление что статья о распознавании именно эмоций людей на изображениях, а не картинок разделенных на два класса позитивных и негативных. Ну и то что в конце выясняется что результата нет, добивает. Разве это практическое пособие о том как нужно делать? Скорее вы показали как не нужно решать эту задачу.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
AI, практический курс. Базовая модель распознавания эмоций на изображениях