
Привет, я Антон Маслов, ведущий разработчик в MTS AI.
Некоторое время назад мне довелось глубоко погрузиться в очень необычные чипы на базе технологии Edge AI. Микроконтроллеры со встроенными нейроускорителями. И позапускать на них самые разные кейсы. Оказалось, что это очень классная штука. И стоит недорого, и работает быстро. А, главное, мелкая. Так что можно встроить в любой девайс.
Я расскажу об опыте погружения в технологию Edge AI, про то, как устроен чип с нейроускорителем, а также про то, с какими трудностями пришлось столкнуться, чтоб заставить все это работать.
Но, обо всем по порядку. Что такое нейроускоритель будет дальше, сначала разберемся, что такое Edge AI. Если совсем по-простому, это про то, как запустить нейросеть на каком-то выделенном кристалле, без связи с внешним миром. Ну то есть, упаковать весь стек сбора данных, вычислений, обработки, а также последующего применения сети так, чтоб наружу ничего не светило. Закрыто и секурно. И еще независимо от проводов, всяких радиоканалов, внешних баз на дальних серверах, и прочих нестабильных и лагающих передатчиков. Короче, делаем кусок искусственного мозга.
Подробно про теорию и философию Edge AI можно почитать, например, тут.
Но нам интересно сделать девайс, так что будем искать практический выхлоп.
Итак, будем играться с чипом KL520 от компании Kneron. На сайте компании есть некоторые доки на сами чипы, а также софт, частично в исходных кодах, для разработки прошивки и сборки нейросети в специальном формате. В лучших традициях изобретений из поднебесной, ждать нормального даташита не приходится. Примеры написаны на коленке. Много воды и хайпа. Ну, никуда не деться, будем разбираться.
Нейросеть
Чтоб было интереснее, запустим и разберем реальный пример от производителя. Задача типовая, распознавание объектов с видеокамеры в реальном времени. На сайте есть вся необходимая документация.
Центральным узлом системы является нейросеть Tiny YOLOv3. Эта сетка является частью проекта YOLO, с которым можно подробно ознакомиться тут.

Не вдаваясь пока в детали архитектуры самой нейросети, представим её как некий черный ящик. На вход этого черного ящика подаётся картинка размером 416×416 пикселей в формате RGB, то есть каждому пикселю соответствует тройка целочисленных значений от 0 до 255. Таким образом на входе имеем трехмерный массив 3×416×416. На выходе же получаем два массива 255×13×13 и 255×26×26. Каждый массив — это разбиение исходного изображения по клеткам на 13×13 или 26×26 частей, то есть по 32×32 или 16×16 пикселей. Для каждого элемента клетки изображения, выдается структура, состоящая из трех частей:
- Координат обрамляющей рамки;
- Так называемого индекса объектности, который показывает вероятность нахождения какого либо объекта в этой рамке;
- Набора индексов, показывающих вероятность принадлежности объекта к одному из классов, на которые обучена нейросеть.
Каждая такая структура упакована в вектор длиной 255. То есть на выходе черного ящика имеем по факту два трехмерных массива чисел с плавающей точкой.
Нейроускоритель это некий вычислитель, который очень ловко умеет перемножать кучу матриц в правильном порядке. Он умеет работать с разными слоями, в том числе сверточными. Понятное дело, у него есть ограничения по размеру входа и выхода. Однако помимо этого, в чипе KL520 он работает только с целочисленными значениями в формате int8, то есть от -128 до 127. Это аппаратное ограничение, с одной стороны, несколько ограничивает вычислительные возможности, но, с другой стороны, позволяет существенно повысить скорость самих вычислений. То есть у нас своего рода кастомный целочисленный DSP, заточенный под матричные операции, которые хорошо поддаются распараллеливанию.
Ну хорошо, вычислитель у нас есть. Но все популярные опенсорсные сети работают во float или double. Так что возникает задача преобразования нейросети в целочисленный формат, так называемой квантизации. Но просто так, обычным умножением на некую константу и отбрасыванием дробной части, преобразовать все значения весов нейросети из float в int8 нельзя. Ввиду большого количества слоев и, соответственно, многократного перемножения коэффициентов, можно в таком случае потерять работоспособность всей конструкции. В добавок к этому, система становится чувствительной к входным изображениям. Чем меньше освещенность, тем темнее пиксели, а значит значения RGB ближе к нулю. В этом случае, результаты работы всей сетки зависят от некоторых околонулевых значений, а грубое округление результатов умножения может привести к их обнулению.
Для решения этой проблемы производитель предоставляет набор собственных утилит на python. Утилиты позволяют преобразовать значения всех коэффициентов нейросети в целочисленный формат с сохранением, насколько это возможно, точности предсказаний. Сам алгоритм закрыт, но в целом, что он делает, можно догадаться. Многократно прогоняя данные и перемножая матрицы он ищет такой набор масштабных коэффициентов на всех этапах, чтоб значения не вылезли за предел int8. Работа утилит требует наличия большого количества библиотек определенных версий, а также вспомогательных скриптов. Поэтому для работы с ними любезно предоставляется виртуальная машина в виде docker контейнера.
Однако, не с каждой нейросетью предлагаемый набор утилит может справиться. Сами данные для распознавания или выход сетки могут не укладываться в допустимый диапазон int8. А в некоторых случаях вообще может быть эффективнее изначально проектировать и обучать нейросеть в целочисленном формате.
При квантизации возникает задача нормализации данных и подготовки нейросети для работы с этими данными. В процессе нормализации могут быть использованы преобразования, которые переводят входные данные в целочисленный формат с минимизацией потерь полезной информации. Но для оценки уровня потерь и выбора оптимального преобразования необходимы опорные значения. Для этого в процессе квантизации используется часть датасета, содержащего реальные входные данные. Но утилиты работают не всегда оптимально, так что это процесс творческий и требует от инженера понимания сути происходящего.
Нейроускоритель в KL520 поддерживает только определенный набор слоев нейросетей. Некоторые слои можно запускать на ускорителе, а некоторые на процессорном ядре. С полным списком можно ознакомиться тут.
Работу со скриптами можно условно разделить на несколько этапов:
- Прогон изначальной нейросети на некоем тестовом наборе картинок и получение опорных результатов распознавания. Это будут те значения вероятностей, к которым мы будем стремиться. Выше той точности, которую дает изначальная нейросеть, нам добиться вряд ли получится. Будет потом с чем сравнить;
- Подготовка набора картинок для квантизации. Значения RGB на этих картинках должны быть приближены к реальным, которые мы потом планируем получать. То есть, в первую очередь, освещенность и контрастность изображений должна быть такая же, как на будущих картинках с камеры;
- Запуск алгоритма квантизации, получение нейросети в проприетарном целочисленном формате bie и проверка точности работы на тестовом наборе картинок. Для упрощения, и тестовые картинки, и картинки для квантизации могут быть одними и теми же. На результат проверки точности это все равно не повлияет;
- Упаковка квантизованной нейросети в особый формат nef, представляющий собой контейнер. В этом контейнере, кстати, может храниться несколько нейросетей. И каждая из них будет представлять собой бинарный код для работы нейроускорителя;
- Сравнение результатов работы контейнера с результатами изначальной нейросети и оценка потери точности. Если погрешность нас устраивает, у нас есть готовая нейросеть для работы на чипе.
Архитектура системы
Не трудно догадаться, что размер изображения 416×416 не соответствует ни одному из стандартных разрешений, которое можно получить со встроенной камеры. Плюс к этому, нас мало интересует огромный набор вероятностей в клетках, да и еще и в разных масштабах. Мы же хотим получить четкое указание объектов на картинке. Значит, необходимо внедрить некие алгоритмы предобработки сырых данных с камеры, а также постобработки результатов YOLO в прошивку. Кстати, сам алгоритм постобработки уже применяется в наборе инструментов при квантизации, его можно найти в составе docker контейнера (/data1/keras_yolo3/yolo3/model.py).
Нормализация данных в процессе прогона нейросети проходит на этапе предобработки. Пример работы на базе YOLO в этом случае, кстати, имеет скрытое преимущество на этапе квантизации. Дело в том, что пиксели картинки уже изначально кодируются в целочисленном формате (RGB565). Если бы пришлось работать со звуком или другим сложным сигналом в виде чисел с плавающей точкой, задача квантизации могла бы сильно усложниться.
Поскольку мы хотим получить систему, работающую в режиме реального времени, хорошо бы все процессы запускать параллельно. В KL520 для этого как раз предусмотрено два отдельных ядра Cortex-M4. Помимо этого, и сам нейроускоритель работает независимо, фактически как еще одно ядро. Все три компонента используют единое пространство быстродействующей памяти, интегрированной в чип.
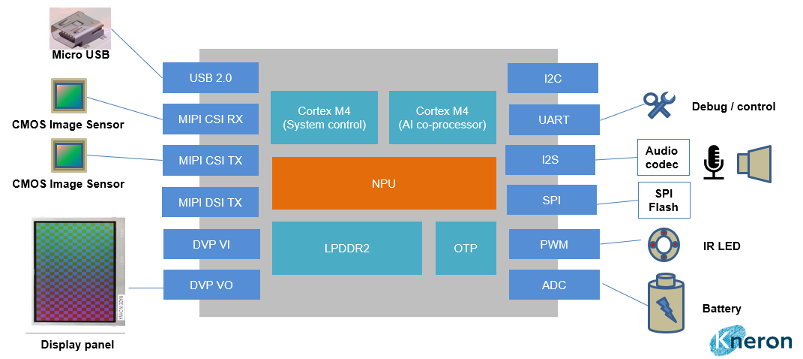
Казалось бы, ничего сложнее каноничных ядер Cortex-M4. Но их вполне хватает.
Основное ядро (SCPU) занято получением и преобразованием изображений с камеры, выводом картинки на дисплей и отрисовкой обрамляющих прямоугольников. Вспомогательное ядро (NCPU) выполняет чисто вычислительные задачи постобработки результатов YOLO. Нейроускоритель (NPU) занят прогоном нейросети.
Помимо основных задач, на чипе, как на любом серийном микроконтроллере, можно поднять работу с периферийными устройствами по самым разным интерфейсам. Можно связаться с внешним миром по USB при необходимости. Всем этим занимается основное ядро. В системе также предусмотрен встроенный загрузчик для чтения прошивки из внешней флэш памяти в память программ основного ядра, так как в составе чипа KL520 нет встроенной флэш памяти. Хотя все ядра и нейроускоритель живут в одном пространстве со встроенной DDR памятью, карта памяти у всех разная, и нужно выискивать задефайненые адреса общих блоков из исходников. Механизм межпроцессорного взаимодействия реализован без заморочек, просто с использованием флагов и общих двунаправленных буферов.
Прошивка
Интересующий нас проект является частью SDK от Kneron для KL520.
Подготовка системы для работы состоит из этапов:
- Получение контейнера nef;
- Сборка микропрограмм для SCPU и NCPU средствами Keil MDK из исходного кода и библиотек в бинарном виде.
Используется среда разработки Keil MDK для Arm. Оба ядра работают под управлением операционной системы Keil RTX; - Подготовка контейнера для записи во внешнюю флэш;
Поскольку все прошивки и нейросети хранятся на одной внешней флэш, производитель предоставляет утилиту для упаковки всех компонент в единый контейнер для последующей прошивки (KL520_SDK/utils/bin_gen/kdp2_bin_gen.py); - Прошивка внешней флэш.
Запись возможна следующими способами:
- Через интерфейс UART по протоколу xmodem (KL520_SDK/utils/flash_programmer/flash_programmer.py);
- С использованием внешнего программатора JTAG, например, Segger J-Link, и механизма Open flashloader (KL520_SDK/utils/Jlink_programmer/kdp2_flash_prog.bat).
Дальнейшее обновление прошивки возможно через интерфейс USB по внутреннему протоколу с использованием функций из библиотеки Kneron PLUS.
Существует два основных режима работы прошивки, которые предлагает производитель:
- Режим host (KL520_SDK/example_projects/tiny_yolo_v3_host/workspace.uvmpw);
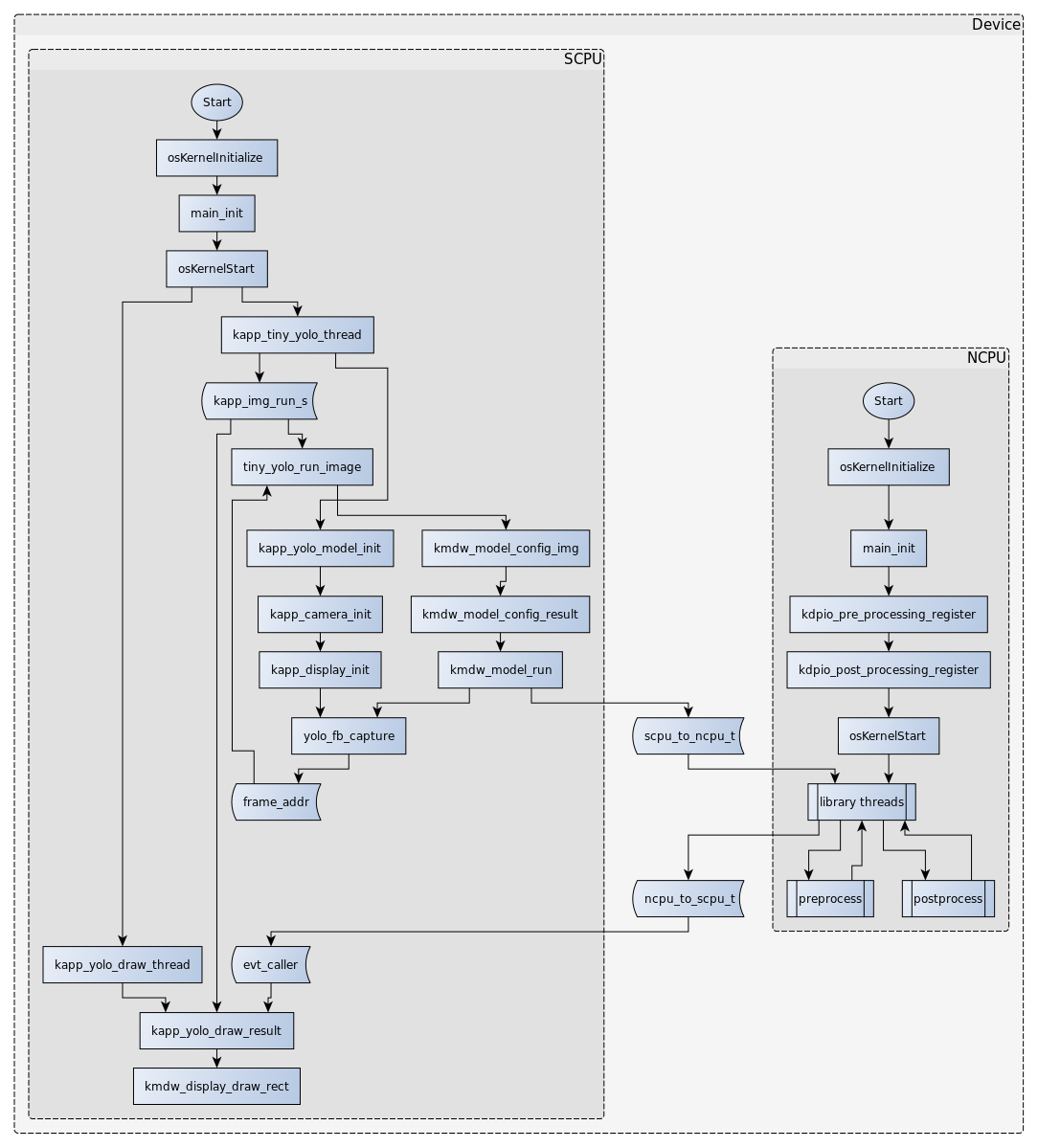
В этом режиме исходные данные для распознавания поступают со встроенной камеры. Механизмы предобработки изображения и постобработки результатов нейросети запускаются на вспомогательном ядре. Связь с внешним миром может и вовсе отсутствовать. Хотя, для целей отладки и чтения результатов может использоваться интерфейс UART. - Режим companion (KL520_SDK/example_projects/kdp2_companion_user_ex/workspace.uvmpw).
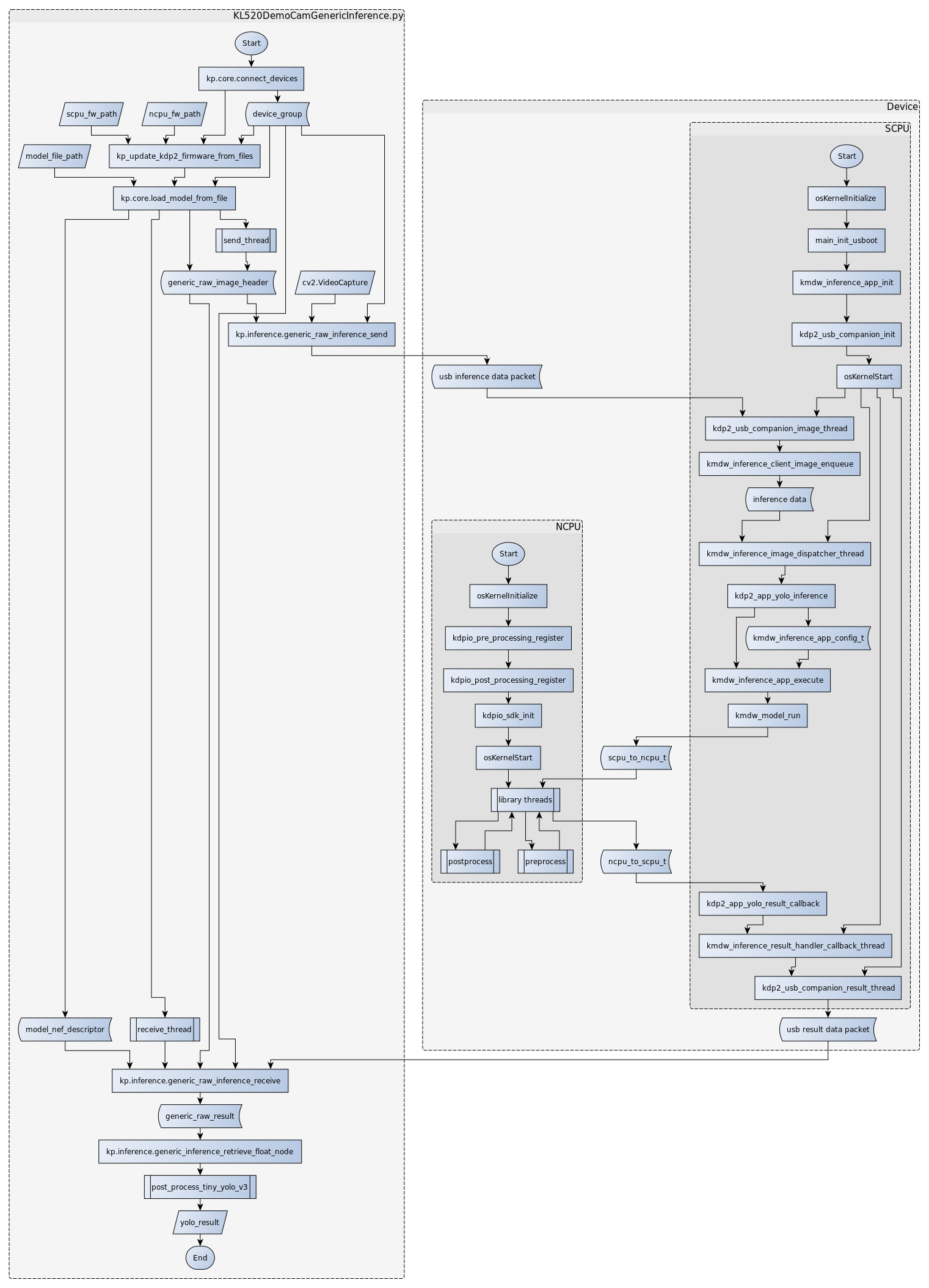
В этом режиме исходные данные подаются с внешнего компьютера через интерфейс USB с помощью функций библиотеки Kneron PLUS. Есть вариант как на C, так и на Python, кому как удобнее. Источником может служить как веб-камера, так и набор файлов с изображениями. Интерфейс UART в этом режиме также остается доступным для своих целей.
Благодаря быстрой скорости интерфейса USB работа прошивки в обоих режимах практически не отличается по быстродействию. Так что, для изучения работы системы можно использовать любой из режимов.
Загрузка
После подачи питания первым делом на основном ядре запускается встроенный загрузчик. Он на медленной скорости считывает из внешней флэш код вторичного загрузчика в память программ SCPU. Далее, вторичный загрузчик на быстрой скорости считывает из внешней флэш код основной программы SCPU. Основная программа выполняет инициализацию всей периферии, встроенной памяти, и подает питание на вспомогательное ядро NCPU. Происходит выделение памяти под нужды механизмов межпроцессорного взаимодействия и алгоритмов конвейерной обработки данных для распознавания. Далее, из внешней флэш загружается код программы для NCPU в его память программ. Содержимое контейнера с нейросетью считывается во встроенную быстродействующую память. Запускается выполнение программы NCPU, которая в свою очередь выполняет инициализацию своей периферии и выделяет память для алгоритмов предобработки и постобработки. Затем асинхронно запускаются процессы ОС реального времени на обоих ядрах.
Процесс работы
Работа системы в режимах host и companion немного отличается структурой процессов OC. Однако сам механизм запуска нейросети единообразен для обоих режимов. Будь то работа с потоковым видео со встроенной камеры или чтение картинок по USB, каждый кадр является обособленным набором данных. Все кадры складываются в FIFO буфер. Для каждого из них формируется специальный дескриптор. В этом дескрипторе содержатся параметры картинки, такие как размер и формат; адреса для чтения исходных данных и записи результата; адреса буферов и параметры для препроцессинга и постобработки; идентификатор нейросети; флаг режима параллельной работы. Распознавание каждого кадра изображения является независимым процессом, а режим параллельной работы позволяет запускать обработку нового кадра, не дожидаясь окончания работы NPU для предыдущего кадра. Поэтому для сопоставления исходных данных и результатов используется специальный идентификатор. Все результаты складываются в свой FIFO буфер, откуда происходит их считывание в другом процессе ОС.
В режиме host дополнительно запускаются процессы чтения данных со встроенной камеры с последующей обработкой. Инициатором запуска нейросети выступает процесс работы с камерой.
В режиме companion в свою очередь дополнительно запускаются процессы для осуществления связи по USB. В этом случае выделяются дополнительные буферы для асинхронной передачи данных между SCPU и внешним компьютером. Инициатором запуска нейросети выступает процесс чтения данных через USB.
Результаты
Осталось дело за малым. Собрать и залить прошивку. Протестировать полученное решение в режиме host можно с помощью набора для разработки на базе KL520. В состав входит отладочная плата, две камеры и дисплей.


Быстродействие данного решения составило приблизительно 14 кадров в секунду. При этом потребляемая мощность всего отладочного комплекта не превысила 2 Вт. Результаты распознавания можно наблюдать на экране и в текстовом формате через UART.
В режиме companion тест производился с использованием миниатюрного USB донгла на базе KL520.

На этот раз быстродействие оказалось порядка 30 кадров в секунду. Потребляемая мощность донгла составила менее 700 мВт. Результаты можно считывать с помощью функций из библиотеки Kneron PLUS через USB.
Вот как это работает в режиме реального времени.
Выводы
Если принять все аппаратные ограничения KL520, как данность, то в целом можно точно сказать, что штука это классная! Стек, конечно, сложный и замороченный, но вполне живой. Ту же Tiny YOLOv3 можно переобучить на свой набор объектов и запустить для других кейсов.
Конечно, есть и преимущества, и недостатки:
- ⊕ Достаточное быстродействие для решения большого пула задач;
- ⊕ Высокая энергоэффективность в пересчете на каждый кадр;
- ⊕ Относительная дешевизна;
- ⊝ Производитель не публикует документацию на периферийные модули;
- ⊝ Неполное и местами противоречивое описание возможностей SDK;
- ⊝ Вспомогательное ядро недоступно для отладки через JTAG.
Однако, принципиальные возможности, заложенные в чип, позволяют спроектировать полезное устройство с искусственным интеллектом на борту без какой-либо связи с внешним миром. А именно этот аспект нас больше всего и интересовал. Можно утверждать, что за свои деньги KL520 справляется с задачами в полном объеме.
На момент написания данной статьи от производителя уже доступен более совершенный комплект на базе системы KL720. Заявленное быстродействие на базе нового чипа при работе с Tiny YOLOv3 составляет уже 148 кадров в секунду! А это в свою очередь открывает совершенно иные возможности применения.
Несмотря на все ограничения и труднодоступность документации, особенно на русском языке, можно с уверенностью утверждать, что сама по себе технология Edge AI является своего рода прорывом в сфере применений искусственного интеллекта. Кто знает, может уже скоро мы увидим гораздо более совершенные системы, сможем создать на их основе ряд инновационных продуктов для самых разных отраслей по всему миру.
Может быть, будущее уже наступило?
