
Аннотация
Потоки являются прямой адаптацией доминирующей сейчас последовательной модели вычислений к параллельным системам. Языки программирования не требуют (или требуют совсем немного) изменений в синтаксисе, чтобы поддерживать потоки, а операционные системы и архитектуры непрерывно развиваются, чтобы повысить эффективность их использования. Многие технологи (инженеры) стремятся интенсивно использовать многопоточность в программном обеспечении и ожидают получить значительное (предсказанное) увеличение производительности. В этой работе я доказываю, что это не очень хорошая идея. Хотя использование потоков кажется небольшим шагом от последовательных вычислений, фактически, это огромный шаг. Использование потоков разрушает такие неотъемлемые свойства последовательных вычислений как: понятность, предсказуемость и определенность (детерминированность). Потоки, как модель вычислений, являются очень недетерминированными, а работа программ также становится неопределенной. Хотя многие исследованные техники улучшают модель вычислений за счет более эффективного сокращения неопределенности, я доказываю, что они не решают проблему полностью. Вместо того, чтобы сокращать неопределенность, мы должны строить модель вычислений исходя из полного детерминизма во взаимодействии программных компонентов. Неопределенность должна явно и аккуратно вводиться туда, где есть в этом необходимость, вместо того, чтобы удаляться там, где нет необходимости. Я доказываю преимущество разработки параллельных языков координации компонентов. Я верю, что такие языки будут гораздо более надежны, а программы будут более распараллеленные.
1 Введение
Всем известно, что программировать параллельные системы сложно. Кроме того, следование императиву параллельного программирования становится все более и более трудным. Многие инженеры предсказывают, что конец действия закона Мура будет отменен увеличением параллелизма архитектур вычислительных систем (многоядерность, многопроцессорность) [15]. Если мы рассчитываем продолжить увеличивать производительность вычислений, программы должны быть в состоянии использовать этот параллелизм. Одно из возможных технических решений – автоматизация использования параллелизма в последовательных программах на аппаратном уровне, например, динамическая диспетчеризация или на программном уровне — с помощью автоматического распараллеливания последовательных программ [6]. Тем не менее, многие исследователи соглашаются, что эти техники малоэффективны и могут использовать только немного параллелизма программ. Более естественное решение – программы должны сами по себе стать «более параллельными».
Если мы понимаем, почему параллельное программирование настолько сложное, мы имеем больший шанс решить проблему. Саттер и Ларус [47] отмечали: «люди быстро разочаровываются в параллелизме из-за более сложного кода, чем в последовательных программах. Даже аккуратные люди пропускают возможное чередование даже среди простого набора частично упорядоченных операций».
Физический мир в большой степени является параллельным, а наше выживание зависит от наших возможностей рассуждать о параллельной физической динамике. Проблема в том, что мы выбрали абстракции параллельного программирования, которые отдаленно напоминают параллельность физического мира. Мы стали использовать эти вычислительные абстракции так, что теперь уже даже сами забыли, что они не являются неизменными. В этой работе, я заключаю, что трудности параллельного программирования — это следствие неправильного выбора абстракций, и если бы мы решили отказаться от этих абстракций, проблемы стали бы решаемыми.
Оптимистическая точка зрения дается Барроссо [7], который заключает, что технологические силы приведут вычисления в серверах и в настольных компьютерах к параллельному мультипроцессингу (concurrent multiprocessing, CMP), а когда технологии станут мэйнстримом, проблемы программирования будут решены. Но мы не должны недооценивать трудности. Одно из требований Штайна (Stein) гласит: «замените традиционную метафору последовательность шагов понятием объединение взаимодействующих сущностей» [46]. Эта статья рассматривает именно этот случай.
2 Потоки
В практике разработки программного обеспечения общего назначения мы достигли точки, в которой единственный подход к параллельному программированию доминирует над всеми остальными, а именно, — потоковая модель вычислений (или просто потоки). Потоки — это последовательные процессы, которые имеют общую память. Они представляют собой ключевую модель параллелизма, поддерживаемую современными компьютерами, языками программирования и операционными системами. Множество используемых параллельных архитектур общего назначения на сегодняшний день (например, архитектура SMP – symmetric multiprocessors или shared memory processing) представляют собой прямую аппаратную реализацию абстракции «поток».
Некоторые приложения могут очень эффективно использовать потоки. Так называемые «embarrassingly parallel» приложения (например, приложения, которые неотъемлемо порождают множество независимых процессов, такие как утилиты сборки – Parallel Virtual Machine (PVM), gmake или веб-сервера). Благодаря независимости этих приложений программировать их относительно легко, а используемая при этом абстракция – более «процессы» (которые не обладают общей памятью), нежели «потоки». Когда такие приложения разделяют данные, они это делают, используя абстракции баз данных, которые управляют параллелизмом с помощью механизма транзакций. Тем не менее, клиентская сторона приложений достаточно сложная. Снова цитируя Сатера и Ларуса [47]:
«Мир клиентских приложений не является хорошо структурированным. Параллельные процессы вычислений могут взаимодействовать и разделять данные множеством способом. Неоднородный код; гранулированность, сложность взаимодействий; структуры данных-указатели — все это делают такой тип программ сложными для параллельного программирования».
Конечно, потоки – не единственная возможность для параллельного программирования. В научных вычислениях, в которых производительность давно требует и использует параллельное программирование. Расширения языков для параллелизма по данным и библиотеки обмена сообщениями (PVM [23], MPI [39], OpenMP) — эти технологии доминируют над потоками с точки зрения возможностей параллельного программирования. Фактически, архитектуры компьютеров, направленные на научные вычисления, часто значительно отличаются от архитектур общего назначения. Например, они обычно поддерживают вектора и потоки на аппаратном уровне. Тем не менее, в этой области, параллельные программы остаются трудоемкими для написания. Языки С и Fortran преобладают, несмотря на длинную историю гораздо лучших языков параллельного программирования. В распределенных вычислениях, потоки часто не является практически применимой абстракцией, т.к. создание иллюзии наличия общей памяти может слишком дорого стоить. Даже не смотря на этот факт, мы прошли значительный путь к созданию механизма распределенных вычислений, который эмулирует многопоточное программирование. CORBA и .NET, например, главенствуют среди распределенных объектно-ориентированных техник. В них программные компоненты взаимодействуют друг с другом через посредника, который ведет себя так, как будто бы мы имели локальные объекты в общей памяти. Абстракция объектно-ориентированных данных ограничивает использования иллюзии совместно используемой памяти, поэтому эти техники в меру эффективны. Они заставляют распределенное программирование быть похожим на многопоточное программирование.
Программирование встроенных систем также использует модель параллелизма, отличную от потоков. Программируемые системы обработки цифровых сигналов часто имеют архитектуру VLIW-машин. Обработку видеосигнала совмещают с SIMD, с VLIW и с потоковой (streaming) обработкой. Сетевые обработчики предоставляют собой явную аппаратную поддержку потоковых (streaming) данных. Тем не менее, не смотря на значительное количество инновационных исследований, в практике, модели программирования для перечисленных архитектур остаются примитивными. Разработчики пишут низкоуровневый ассемблерный код, который использует специфические свойства аппаратуры, и совмещают этот код с кодом на языке С только там, где производительность не критична.
Интересное свойство многих приложений встроенных систем состоит в том, что надежность и предсказуемость гораздо важнее, чем выразительность (выразительные возможности) или производительность. Это спорно для универсальных компьютеров, но этот вопрос лежит в стороне от тематики данной работы. Я докажу, что достижение надежности и предсказуемости, как правило, невозможно с использованием потоков для многих приложений.
3 Потоки, как вычислительная модель
В этом разделе, я буду анализировать фундаментальные основы потоков, без ссылки на конкретные библиотеки или языки, и покажу, что модель вычислений на их основе существенно некорректна. В следующем разделе я рассмотрю некоторые предлагаемые поправки к модели.
Пусть множество N = {0,1,2,…} – множество натуральных чисел. Пусть также, B = {0, 1} – множество двоичных цифр (битов), а B* — множество всех последовательностей битов конечной длины. Тогда
 — множество всех последовательностей битов бесконечной длины (каждая из которых есть функция, которая отображает N в B). Также, пусть
— множество всех последовательностей битов бесконечной длины (каждая из которых есть функция, которая отображает N в B). Также, пусть  [17]. Мы будем использовать B** для представления состояния вычислительной машины: ее входов (которых, потенциально, — бесконечной количество) и ее выходов (которых также может быть бесконечно много). Пусть
[17]. Мы будем использовать B** для представления состояния вычислительной машины: ее входов (которых, потенциально, — бесконечной количество) и ее выходов (которых также может быть бесконечно много). Пусть  обозначает множество всех частичных функций с областью определения и изменения — B** (частичные функции — это функции, которые могут или не могут быть определены на каждом элементе их области определения).
обозначает множество всех частичных функций с областью определения и изменения — B** (частичные функции — это функции, которые могут или не могут быть определены на каждом элементе их области определения). Императивная машина (A, c) есть конечное множество
 атомарных действий и функция управления с:
атомарных действий и функция управления с:  . Множество А представляет собой атомарные действия (инструкции) машины, а функция c отражает последовательность выполнения этих действий. Мы предположим, что А содержит в качестве одной из инструкций инструкцию останова
. Множество А представляет собой атомарные действия (инструкции) машины, а функция c отражает последовательность выполнения этих действий. Мы предположим, что А содержит в качестве одной из инструкций инструкцию останова  . То есть, инструкция останова не изменяет состояния машины.
. То есть, инструкция останова не изменяет состояния машины.Последовательную программу длины m
 N назовем функцией
N назовем функцией  , где
, где  . То есть, последовательная программа включает конечное число обычных инструкций и бесконечное число инструкций останова. Отметим, что множество всех последовательных программ, которые мы обозначим P, является счетным бесконечным множеством.
. То есть, последовательная программа включает конечное число обычных инструкций и бесконечное число инструкций останова. Отметим, что множество всех последовательных программ, которые мы обозначим P, является счетным бесконечным множеством.Выполнение этой программы представляет собой поток. Он начинается с начального
 которое отражает начальное состояние машины и ее входы. Для всех
которое отражает начальное состояние машины и ее входы. Для всех 
 (1)
(1)Здесь,
 представляет собой индекс в программе p следующей инструкции
представляет собой индекс в программе p следующей инструкции  . Эта инструкция применяется к состоянию
. Эта инструкция применяется к состоянию  , чтобы получить следующее состояние
, чтобы получить следующее состояние  . Если для любого
. Если для любого 
 , тогда = h и программа останавливается в состоянии (т.е. состояние больше не изменяется). Если для всех начальных состояний программа p останавливается, тогда p описывает конечную функцию в Q. Если же программа p останавливается только для некоторых
, тогда = h и программа останавливается в состоянии (т.е. состояние больше не изменяется). Если для всех начальных состояний программа p останавливается, тогда p описывает конечную функцию в Q. Если же программа p останавливается только для некоторых  , тогда она описывает частичную функцию в Q (легко показать, что Q — несчетное множество (даже подмножество постоянных функций множества Q не является счетным, т.к. B** само по себе несчетное. И это легко может быть продемонстрировано, используя диагональный аргумент Кантора). Так как множество всех конечных программ P – счетное, мы можем заключить, что не все функции в Q могут быть заданы конечными программами. Поэтому, любая последовательная машина имеет ограниченную выразительность. Тьюринг и Чёрч [48] показали, что множество выборов последовательных машин (А, с) отражается в программах P, что может дать точно такое же подмножество множества Q. Такое подмножество называется подмножеством эффективно вычислимых функций)).
, тогда она описывает частичную функцию в Q (легко показать, что Q — несчетное множество (даже подмножество постоянных функций множества Q не является счетным, т.к. B** само по себе несчетное. И это легко может быть продемонстрировано, используя диагональный аргумент Кантора). Так как множество всех конечных программ P – счетное, мы можем заключить, что не все функции в Q могут быть заданы конечными программами. Поэтому, любая последовательная машина имеет ограниченную выразительность. Тьюринг и Чёрч [48] показали, что множество выборов последовательных машин (А, с) отражается в программах P, что может дать точно такое же подмножество множества Q. Такое подмножество называется подмножеством эффективно вычислимых функций)). Теперь обратимся к ядру последовательной программы. Пусть дана программа и начальное состояние, а также определена последовательность (1). Если последовательность останавливается, тогда функция, вычисляемая программой, определена. Любые две программы p и p' могут быть сравнены друг с другом. Они эквивалентны, если они вычисляют одну и ту же частичную функцию. То есть, они эквиваленты, если останавливаются для одних и тех же начальных состояний и для этих состояний имеют одинаковое конечное состояние (в классической теории, когда программы не останавливаются — они считаются эквивалентными, что создает серьезные проблемы для применения теории вычислений к ПО встроенных систем, в которых программы не останавливаются никогда [34]). Такая теория эквивалентности важна для любого конструктивного формализма. Эти существенные свойства программ теряются, когда используется множество потоков. Рассмотрим две программы
 и
и  , которые запускаются параллельно. Что мы имеем в виду, когда заменяем выражение (1) формулой:
, которые запускаются параллельно. Что мы имеем в виду, когда заменяем выражение (1) формулой: (2)
(2)На каждом шаге n, каждая из программ может выполнять следующее атомарное действие. Проверим сейчас, получается ли конструктивная теория эквивалентности. То есть, когда две заданные многопоточные пары программ
 и
и  будут эквивалентны? Расширение базовой теории определяет их эквивалентными тогда, когда все чередования останавливаются для одного и того же начального состояния в одном и то же конечном состоянии. Огромное число возможных вариантов чередований делает чрезвычайно сложным доказательство эквивалентности. Исключение составляют тривиальные случаи, например, состояния B** разделены, поэтому выполнение каждой из программ не влияет на разделы других программ.
будут эквивалентны? Расширение базовой теории определяет их эквивалентными тогда, когда все чередования останавливаются для одного и того же начального состояния в одном и то же конечном состоянии. Огромное число возможных вариантов чередований делает чрезвычайно сложным доказательство эквивалентности. Исключение составляют тривиальные случаи, например, состояния B** разделены, поэтому выполнение каждой из программ не влияет на разделы других программ.Таким образом, если две программы p и p' запускаются в многопотоковой среде, мы больше не можем судить об их эквивалентности. Фактически, мы должны знать обо всех остальных потоках, которые могут быть запущены, и мы должны проанализировать все возможные чередования. Мы можем таким образом сделать заключение, что теория эквивалентности не может быть применена к потокам.
Даже более того, реализовать многопотоковую модель вычислений чрезвычайно трудно. В качестве свидетельства можно упомянуть о тонкостях модели памяти языка Java [41, 24], в котором даже очень тривиальная программа может вести себя неоднозначно.
Ядро абстракций вычислений, представленных в формуле (1), на которую опираются все широко используемые языки программирования, подчеркивает детерминированную композицию детерминированных компонентов. Эти действия являются детерминированными, и их последовательная композиция также является детерминированной. Последовательный запуск, по смыслу, является функциональной композицией — простой моделью, в которой детерминированные компоненты производят детерминированные результаты.
Потоки, с другой стороны, крайне недетерминированы. Работа программиста – сократить эту неопределенность. У нас имеются, конечно, разработанные вспомогательные инструменты для сокращения неопределенности. Семафоры, мониторы и более современные механизмы работы с потоками (которые будут обсуждаться в следующем разделе). Эти техники позволяют программисту сильно сокращать неопределенность. Но это сокращение редко бывает удовлетворительным.
Приведем другую аналогию, предположим, что мы попросили инженера-механика разработать двигатель внутреннего сгорания из железной банки, углеводорода и молекул кислорода, перемещающимся случайным образом в силу действия температуры. Термодинамика и химия говорят нам, что это возможно в теории, но возможно ли это на практике?
Давайте рассмотрим третью аналогию. Бытовое определение безумия – это делать одно и то же снова и снова, ожидая при этом, что результаты будут разные. По этому определению, мы, фактически, требуем, чтобы программисты многопотоковых систем были безумны. Если бы они были нормальными, они бы не смогли понять своих программ.
Я докажу, что мы должны и можем строить параллельную модель вычислений таким образом, чтобы она была как можно более определенной. Неопределенность мы должны вносить аккуратно и только там, где это необходимо, также как в последовательном программировании. Потоки используют противоположный подход. Они делают программы до абсурда неопределенными и полагаются на стиль программирования, который ограничивает эту неопределенность, чтобы достичь определенных целей.
4 Насколько это плохо на практике?
Мы доказали, что потоки представляют собой крайне бесполезную математическую модель вычислений. Что касается практики: многие программисты на сегодняшний день пишут программы, которые работают.
Имеется ли здесь противоречие? На практике, программисту предоставлены инструментарии для сокращения большей части неопределенности. Например, объектно-ориентированное программирование ограничивает видимость определенных частей программы, определяющих ее состояние. Это эффективно разбивает пространство состояний B** на непересекающиеся множества. Там, где программы оперируют открытыми частями этого пространства состояний, семафоры, взаимно-исключающие блокировки и мониторы (объекты с взаимно-исключающими методами) предоставляют механизмы, которые программы могут использовать для сокращения еще большего количества неопределенности. Но на практике эти техники делают программы понимаемыми только для очень простых взаимодействий.
Рассмотрим общеизвестный и широко используемый паттерн «Observer» [22]. Java-реализация этого паттерна показана в листинге 1. На нем показано два метода класса, в котором при вызове метода setValue() срабатывает уведомление об изменении значения (посредством вызова метода valueChanged()) для всех объектов, которые были зарегистрированы вызовом метода addListener().
public class ValueHolder {
private List listeners = new LinkedList();
private int value;
public interface Listener {
public void valueChanged(int newValue);
}
public void addListener(Listener listener) {
listeners.add(listener);
}
public void setValue(int newValue) {
value = newValue;
Iterator i = listeners.iterator();
while(i.hasNext()) {
((Listener)i.next()).valueChanged(newValue);
}
}
}
Листинг 1. Java-реализация паттерна Observer, предназначенная для выполнения в одном потоке
Код из листинга 1 не является потокобезопасным, т.к. если несколько потоков вызовут метод setValue() или addListener(), то может случиться так, что список listeners будет модифицирован в то время, когда итератор совершает проход по списку. Это вызовет ошибку и, вероятно, непредвиденное завершение программы.
Наиболее простое решение – это добавить ключевое слово synchronized языка Java в определения методов setValue() и addListener(). Ключевое слово synchronized реализует взаимное исключение методов, включая экземпляры класса ValueHolder в мониторы, предотвращающие одновременный вызов этих методов в любых двух потоках. Когда синхронизованный метод вызывается, вызывающий его поток пытается заблокировать объект, получить его в монопольное распоряжение. Если любой другой поток заблокирует объект, тогда вызывающий поток остановится до тех пор, пока блокировка не будет снята.
Тем не менее, это решение не является разумным, т.к. может вести к взаимным блокировкам. Предположим, что у нас есть экземпляр a класса ValueHolder и экземпляр b другого класса, который реализует интерфейс Listener. Последний класс может делать, что угодно в его методе valueChanged(), включая получения блокировки на другой монитор. Если он не может получить блокировку, то будет продолжать блокировать объект класса ValueHolder. Тем временем, другой поток может вызвать метод addListener() для объекта a. Оба потока тогда будут заблокированы без надежды на разблокировку. Этот тип потенциальных deadlock'ов скрывается во многих программах, которые используют мониторы.
Рассмотрим улучшенную реализацию, приведенную в листинге 2. В то время, когда объект заблокирован, метод setValue() делает копию списка listeners. Так как метод addListeners() синхронный, это помогает избежать возникновения ошибки при модификации списка. В дальнейшем, метод valueChanged() вызывается вне синхронизированного блока, чтобы избежать взаимной блокировки.
public class ValueHolder {
private List listeners = new LinkedList();
private int value;
public interface Listener {
public void valueChanged(int newValue);
}
public synchronized void addListener(Listener listener) {
listeners.add(listener);
}
public void setValue(int newValue) {
List copyOfListeners;
synchronized(this) {
value = newValue;
copyOfListeners = new LinkedList(listeners);
}
Iterator i = copyOfListeners.iterator();
while(i.hasNext()) {
((Listener)i.next()).valueChanged(newValue);
}
}
}
Листинг 2. Java-реализация паттерна Observer и попытки сделать код потокобезопасным
Соблазнительно думать, что мы решили проблему, но фактически, код по-прежнему некорректен. Предположим, что два потока вызывают метод setValue(). Один из них установит значение последним, оставляя это значение в поле объекта. Но listeners могут быть уведомлены, что значение изменилось в обратном порядке. «Листенеры» могут сделать вывод, что конечное значение, содержащееся в объекте класса ValueHolder, является неверным.
Конечно, этот паттерн может быть реализован в Java так, чтобы он работал устойчиво (я оставляю это в качестве упражнения для читателя). Факт состоит в том, что даже этот простой и обще используемый паттерн проектирования требует некоторого довольно сложного анализа возможных чередований вызовов. Я думаю, что большинство многопоточных программ имеют такие ошибки. Более того, я полагаю, что эти ошибки на сегодняшний день не являются основными препятствиями только потому, что сегодняшние архитектуры и операционные система предоставляют скромные возможности для параллельного программирования. Стоимость (время) переключения контекстов процессов слишком высока, поэтому только крошечный процент возможных чередований инструкций потоков происходит на практике. Моя догадка состоит в том, что большинство многопоточных приложений общего назначения, по факту, содержат множество ошибок в реализации параллелизма, т.к. многоядерная архитектура становится самой распространенной, то эти ошибки будут проявляться в виде крахов систем. Такой сценарий весьма суров для продавцов компьютеров: их следующее поколение машин прославиться тем, что на этих машинах программы часто падают.
Эти же самые продавцы защищают многопотоковое программирование, потому что в них имеется поддержка параллелизма и они готовы продавать ее нам. Например, Intel проводит активную кампанию, в результате которой во многих ведущих академических программах по информационным технологиям будет сделан акцент на многопоточное программирование. Если они преуспеют в их деле, то следующее поколение программистов будет использовать многопоточное программирование более интенсивно, и тогда следующее поколение компьютеров станет практически бесполезным.
5 Корректировка модели потоков с помощью более агрессивного сокращения неопределенности
В этом разделе я буду обсуждать подходы для решения описанной в заголовке раздела задачи. Эти подходы сохранят модель вычислений на основе потоков для программистов, но предоставят им более эффективные механизмы для устранения неопределенности поведения программ.
Первая техника – это улучшение процесса инженерии программного обеспечения. Это важно для получения надежных многопотоковых программ. Этого, тем не менее, не достаточно. Вот предостерегающий случай из проекта Ptolemy, выполняемого институтом Беркли. В начале 2000-го года моя группа начала разработку ядра Ptolemy II [20] — среды программирования, поддерживающей параллельную модель вычислений. Одной из ранних целей было позволить модификацию параллельных программ с помощью GUI в режиме их выполнения. Сложность в том, чтобы гарантировать согласованность потоков в противоречивой структуре программы. Предполагалось использовать стратегию с Java-потоками и мониторами.
Одной из целей экспериментального проекта было проверить, будут ли полезными практики эффективной программной инженерии для научного исследования. Мы разработали процесс, который включал: рейтинговую систему «зрелости» программы, состоящей из четырех уровней: красного, желтого, зеленого и синего; анализ проекта, анализа кода, ночные сборки, регрессионное тестирование, автоматизированную разметку кода [43]. Часть ядра, которая гарантировала согласованность представления структуры программы, была написана в начале 2000 года. Анализ проекта был по введенной шкале желтым, анализ кода — зеленым. Анализ проводили эксперты в области параллельного программирования. Мы написали регрессионные тесты для 100% кода. Ночные сборки и регрессионные тесты запускались на двухпроцессорной SMP-машине, что проявлялось в отличном поведении программ от поведения на однопроцессорных машинах разработчиков. Система Ptolemy II стала широко использоваться. Проблем не наблюдалось до тех пор, пока в 26 апреля 2004 (спустя 4 года после начала разработки) не проявился deadlock.
Очевидно, что наша относительно строгая практика проектирования параллельных программ помогла выявить и исправить множество багов, касающихся параллельного выполнения. Но фактически, такой серьезный баг, как deadlock, не был выявлен, и это настораживает. Как много подобных проблем осталось? Как долго необходимо тестировать, чтобы мы могли быть уверены в отсутствии багов? С сожалением, я должен заключить, что тестирование не может выявить все проблемы в нетривиальном многопоточном коде.
Конечно, имеются, казалось бы, простые правила для исключения появления взаимных блокировок [32]. Например, осуществлять блокировку всегда в одном и том же порядке. Но такое правило очень сложно применить на практике, т.к. широко распространенных языках нет специализированных техник, которые показали бы, каким вызовом был заблокирован метод. Поэтому необходимо проводить исследование исходного кода всех методов, которые были вызваны, а также всех методов, которые были вызваны в этих методах и т.д. Даже если мы исправим эту проблема языка, сделав блокировки частью сигнатуры методов, это правило сделает очень сложным реализовать симметричный доступ (когда взаимодействия могут инициироваться с любого конца). Неизвестно такое решение проблемы, в котором реализация взаимно исключающих блокировок не была бы чрезвычайно трудной. Если программисты не могут понимать их код, код не будет надежным.
Кто-то может заключить, что проблема в том, как Java реализует потоковую модель. Возможно, ключевое слово synchronized не лучший инструмент для сокращения неопределенности. Действительно, в версию Java 5.0, введенную в 2005 году, введены дополнительные механизмы для синхронизации потоков. Они обогатили инструментарий программиста для сокращения неопределенности. Но эти механизмы (например, семафоры) по-прежнему сложны для использования, и очень похоже, что результатом их использования будут непостижимые для понимания программы с хитрыми скрытыми ошибками.
Только лишь построением грамотного процесса проектирования ПО не решить проблему. Другой подход, который может помочь, — это использование паттернов проектирования, которые были специально исследованы для параллельных вычислений [32, 44]. Действительно, это огромная помощь в случае, когда задача программирования соответствует одному из паттернов. Тем не менее, существует две сложности. Одна — это реализация шаблона, которая может быть очень сложной, даже с подробной инструкцией. Программисты будут делать ошибки, а техники для автоматической проверки корректности реализация шаблона не существует. Что более существенно, паттерны бывает сложно совместить. Их свойства обычно несовместимы, поэтому нетривиальные программы, которые требуют использования более одного паттерна, вряд ли будут понимаемыми.
Более общий случай использования шаблонов в параллельных вычислениях – это поиск в базе данных, особенно с использованием механизма транзакций. Транзакции поддерживают асинхронные вычисления на копии данных, за которыми следует commit или abort (принятие транзакции или ее отмена). Принятие транзакции выполняется в случае, если не случилось ни одного конфликта в течение ее проведения. Транзакции бывают распределенные (как правило, для баз данных) или выполняемые в программной общей памяти машины [45], или, что наиболее интересно, выполняемые в аппаратной общей памяти машины [38]. В последнем случае, техника совмещается хорошо с протоколами согласования кэша, которые итак необходимы для этих машин. Транзакции устраняют незапланированные блокировки, но даже несмотря на их недавнее усовершенствование (см. [26]), по-прежнему остаются очень неопределенным механизмом взаимодействия. Они хорошо подходят для ситуаций, которые сами по себе являются неопределенными, в которых, например, несколько участников соревнуются за ресурсы. Но они не подходят для построения детерминированных параллельных взаимодействий.
Особенно интересное использование шаблонов было в MapReduce [19]. Этот шаблон был использован для крупномасштабной распределенной обработки большого объема данных компанией Google. Пока большинство шаблонов представляет собой гранулированные общие структуры данных и синхронизацию доступа к ним — MapReduce является фреймворком для конструирования больших распределенных программ. Этот шаблон был разработан на основе высокоуровневых функций языка Lisp и других функциональных языков. Параметры шаблона представляют собой части функциональности системы в виде кода, нежели «кусков» данных.
Шаблоны могут быть инкапсулированы экспертами в библиотеки так, как это было сделано с MapReduce, параллельными структурами данных в Java 5.0 и STAPL в С++ [1]. Это серьезное улучшение надежности реализации, но оно требует от программиста дисциплины для соблюдения правил совершения параллельных взаимодействия с использованием этих библиотек. Сворачивание возможности этих библиотек в языки, в которых синтаксис и семантика реализуют эти ограничения, может привести, в конечном счете, к гораздо более легкому процессу разработки параллельных программ.
Высокоуровневые шаблоны (такие как MapReduce) предоставляют интересные задачи и возможности для разработчиков языков программирования. Эти шаблоны выполняют более роль координационных языков, нежели традиционных языков программирования. Новые координационные языки, совместимые с существующими языками (Java, C++), скорее всего, заменят традиционные языки.
Компромиссом может быть расширение существующих языков программирования ключевыми словами для поддержки параллелизма. Это позволит использовать большую часть унаследованного функционала там, где не требуется параллельное программирование, но потребует изменений функционала для поддержки параллелизма. Этой стратегии придерживаются в Split-C [16] и Cilk [13] (С-подобные языки с поддержкой многопоточности). В Cilk программист может использовать ключевые слова cilk, spawn, sync в своей С-программе. Цель Cilk — поддержка динамической многопоточности в контексте общей памяти, в котором издержки возникают только тогда, когда параллелизм действительно используется (т.е. при использовании одного процессора – издержек практически нет).
Схожий подход – это совмещение расширений языка и ограничений выразительности существующих языков, чтобы добиться более согласованного и предсказуемого поведения. Например, язык Guava [5] есть ограничение языка Java, в котором несинхронизованные объекты недоступны из разных потоков. Также, имеется явное различие между блокировками, которые гарантируют целость данных (блокировки на чтение) и блокировками, которые позволяют безопасную модификацию данных (блокировки на запись). Эти изменения в языке сокращают значительную часть неопределенности, не вызывая при этом деградацию эффективности, но тем не менее остается риск возникновения deadlock’ов.
Другой подход, в котором акцент сделан на избежание взаимных блокировок называется promises (обещания), т.к. реализованы Марком Миллером в языке программирования E (см. www.erights.org). В нем, вместо блокировки доступа к общим данным, программы взаимодействует с посредником данных (таким способом, как если бы они напрямую обращались к данным).
Еще один подход оставляет языки программирования и механизмы параллелизма без изменений, а вместо этого вводит формальный анализ программ для идентификации мест потенциального возникновения ошибок в многопоточных программах. Это сделано в Blast [28] и Intel thread checker. Такой подход может оказать значительную помощь в анализе поведения программ, которые сложны для понимания. Менее формальные техники отладки, например, Valgrind, также могут помочь в этом. Не смотря на это, формальные и не формальные техники по-прежнему требуют значительного опыта в применении и страдают от ограничений на масштабируемость.
Все приведенные техники сокращают часть неопределенности поточной модели программирования. Тем не менее, даже в результате их применения получаются весьма недетерминированные программы. Для приложений, которым свойственна неопределенность (серверы, параллельный доступ к БД, конкуренция за ресурсы), они подходят. Но достижение определенных целей через неопределенность по-прежнему сложно. Выполнение детерминированных параллельных вычислений требует рассмотрение проблемы с различных сторон. Вместо работы с таким крайне недетерминированным механизмом как потоки и возлагая на программиста работу по сокращению неопределенности, мы должны начинать работу с детерминированных механизмов и вводить неопределенность только там, где необходимо. Мы рассмотрим этот подход в следующих разделах.
6 Альтернативы потоковой модели вычислений
Рассмотрим снова паттерн Observer, [22] показанный в листингах 1 и 2. Это тривиальный паттерн проектирования. Реализация должна быть простой. Но, как было показано выше, не просто реализовать этот паттерн, используя потоки.
Рассмотрим рисунок 1, на котором реализован этот шаблон на основе рандеву (концепции параллельного программирования) в Ptolemy II [20]. Подписанный меткой «Rendezvous Director» прямоугольник в левом верхнем углу есть обозначение диаграммы, представляющая собой CSP (Communicating Sequential Processes (CSP) — формальный язык описания шаблонов взаимодействия параллельных систем) -подобную [29] параллельную программу, в которой каждый компонент – это процесс, а взаимодействие осуществляется посредством рандеву. Процессы сами по себе реализованы на обыкновенной Java, таким образом, такую среду можно рассматривать как координационный язык (который, по случайности, является языком визуального программирования). Реализация области рандеву на Ptolemy II была сделана на основе работы [2] и включает блок «Merge», который реализует условное рандеву. На диаграмме, блок Merge определяет, что любой из двух Value Producers (поставщик/производитель значений) может участвовать в рандеву с Value Consumer и Observer. То есть, два возможных трехсторонних рандеву могут произойти. Эти взаимодействия могут происходить постоянно в произвольном порядке.
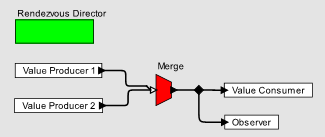
Рисунок 1. Реализация паттерна Observer в основанном на рандеву координационном языке визуального программирования.
Для начала, необходимо отметить что, когда вы начинаете понимать значения иконок, диаграмма ясно выражает паттерн Observer. Кроме того, все в программе является детерминированным, кроме явно недетерминированных взаимодействий, заданных блоком Merge. Если бы этот блок отсутствовал, мы бы имели программу, в которой осуществлялись детерминированные взаимодействия между детерминированными процессами. Deadlock произойти не может (если, конечно, нехватка циклов в диаграмме гарантирует, что dealock не произойдет). Также, способ осуществления рандеву с тремя участниками гарантирует, что Value Consumer и Observer получат значения в правильном порядке. Паттерн Observer становится простым (как это и должно быть).
Тривиальная проблема программирования стала простой, и мы можем начать рассматривать интересные разработки. На рисунке 2 показан паттерн Observer, реализованный с помощью PN Director, который реализует модель параллелизма, именуемую сетью обработки (processing net, PN) Кана [31]. В этой модели каждая иконка есть процесс, но место взаимодействий в виде рандеву, процессы взаимодействуют посредством передачи сообщений с бесконечной очередью и блокировками на чтение. В первоначальной модели PN [31], блокировки на чтение гарантировали, что каждая сеть будет осуществлять детерминированные вычисления. В нашем случае, модель дополнена некоторым примитивом, который можно назвать недетерминированный Merge, который явно объединяет потоки. Отметим, что дополненная модель с явной неопределенностью обычно используется для ПО встроенных систем [18].
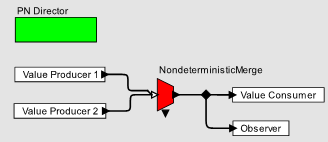
Рисунок 2. Реализация паттерна Observer с использованием сетевой модели параллелизма.
Модель на рисунке 2 имеет все характерные для модели на рисунке 1 преимущества, а также имеет дополнительное свойство – Value Consumer может не поддерживать явно шаблон Observer. Уведомления могут помещаться в очередь для последующей обработки. В потоковой реализации нужно очень постараться для реализации подобной формы взаимодействия.
Третий способ реализации можно ввести на основе природы неопределенности, выраженной недетерминированным объединением (merge). Принципы синхронных языков [8] могли бы гарантировать корректность. В Ptolemy II подобная модель могла быть реализована с помощью SR Director (синхронный/реактивный), который представляет собой синхронную модель схожую с Esterel [12], SIGNAL [10] и Lustre [25]. Последняя из них успешно используется для программирования и проектирования параллельного, с высокими требованиями к безопасности, программного обеспечения для приложений управления самолетом [11]. Использовать потоковую модель программирования для этих целей было бы глупым.
Четвертая реализация специализируется на синхронизации недетерминированных событий. В Ptolemy II похожая модель называется DE director (discrete events, дискретные события). Она предоставляет спецификацию для синхронизации со строгой семантикой [33], связанной подобием таких языков описания аппаратной части как VHDL, Verilog и такими средами моделирования сетей как Opnet Modeler.
Во всех четырех случаях (рандеву, PN, SR, DE) мы начинали с полного детерминизма во взаимодействиях. Недетерминизм был аккуратно введен точно там, где необходимо. Этот стиль проектирования очень отличается от стиля с потоками, который начинает с крайне недетерминированного механизма взаимодействий и пытается сократить нежеланный недетерминизм.
Реализации, показанные на рисунках 1 и 2, используют Java-потоки. Тем не менее, программная модель включает не только модель потоков. Сравнивая со всеми техниками, описанными в предыдущей секции, она ближе всего к MapReduce, которая есть разновидность стриминга данных для выполнения вычислений. Но, в отличие от MapReduce, она поддерживает строгий координационный язык, достаточно выразительный, чтобы описать широкий диапазон взаимодействий. Фактически, два различных координационных языка приведено здесь: с семантикой рандеву и с PN семантикой.
Эта разновидность параллелизма, конечно, не новая. Компонентные архитектуры, в которых потоки данных между компонентами могут быть названы «actor-oriented» [35]. Они принимают множество форм. Каналы (pipes) в Unix напоминают PN, хотя они более ограниченные, т.к. не поддерживают циклические графы. Пакеты передачи сообщений (MPI, OpenMP) включают возможности для реализации рандеву и PN, но в менее структурированном контексте, который делает больше ставку на выразительность, нежели на детерминированность взаимодействий. Наивный пользователь таких пакетов может быть обескуражен неожиданным результатом проявления неопределенности.
Такие языки как Erlang [4] в своей модели параллелизма делают передачу сообщений неотъемлемой частью языка программирования общего назначения. Такие языки как Ada, делают своей неотъемлемой частью рандеву. Функциональные языки [30] и языки с единственным присваиванием также делают акцент на детерминированные вычисления, но они «менее параллельны», поэтому контроль и использование параллелизма может быть более сложным. Языки параллелизма по данным также делают акцент на детерминированных взаимодействиях, но они требуют низкоуровнего переписывания ПО.
Все эти подходы являются частью решения проблемы. Но не похоже, что какой-то из них может стать мэйнстримом. В следующем разделе, я приведу доводы.
7 Проблемы и возможности
Факт в том, что альтернативы потоковой модели существуют уже долгое время, но потоки все же доминируют среди всех остальных подходов. Существует множество причин этого. Вероятно, одна из основных состоит в том, что ядро абстракций вычислений погрязло в последовательной парадигме. Большинство широко используемых языков программирования придерживается этой парадигмы.
Синтаксически, потоки всего лишь небольшое расширение этих языков (как в Java) или просто внешняя библиотека. Семантически же, они полностью разрушают существенную часть детерминизма языка. Прискорбно, что программисты часто руководствуются именно синтаксисом, нежели семантикой. Общепризнанные альтернативы потокам, такие как MPI и OpenMP, имеют ту же самую ключевую особенность. Они не изменяют синтаксис языка. Альтернативы, которые полностью заменяют эти языки со своим собственным синтаксисом (например, Erlang, Ada), не имеют всеобщего признания сейчас и, вероятно, не получат его вообще. Даже языки с минимальными модификациями синтаксиса, такие как Split-C или Cilk, остаются эзотерическими.
Напрашивается вывод, что мы не должны заменять общепризнанные языки. Мы должны вместо этого надстраивать их. Тем не менее, надстраивание только лишь в виде библиотек не достаточно. Библиотеки не позволяют многообразие структур, принудительной реализации шаблонов и сложных составных свойств.
Я верю, что правильный ответ лежит в разработке координационных языков. Они вводят новый синтаксис, этот синтаксис сохраняет цели, но эти цели ортогональны к тем, которые преследуют традиционные языки. Тогда как параллельные языки общего назначения (Erlang, Ada) должны включать синтаксис для обычных операций (например, арифметических выражений), координационный язык может не включать ничего, кроме того, что необходимо для координации. Синтаксис может сильно отличаться. «Программы», приведенные на рисунках 1 и 2 используют визуальный синтаксис для реализации actor-oriented координации (в них — скорее потоки данных проходят между компонентами, нежели управление) Хотя здесь визуальный синтаксис используется лишь для педагогических целей, возможно, что в конечном счете такой визуальный синтаксис будет масштабируемым и эффективным, как определенная часть UML для объектно-ориентированного программирования. Но даже если и нет, то легко предположить текстовый синтаксис с аналогичной структурой.
Хотя координационные языки были изобретены уже давно [40], но они слишком много раз терпели неудачу, что стать широко используемыми. Одна из причин – потеря однородности (гомогенности) архитектуры. Преобладающее веяние в исследованиях языков программирования: любой стоящий язык программирования должен быть общего назначения. Он должен быть, как минимум, достаточно выразительным, чтобы выражать его собственный компилятор. А тогда, сторонники языка будут рассмотрены как предатели, если они уступят новому языку. Войны языков — религиозные войны. Некоторые из таких войн – многотеистичны.
Тем не менее, UML, например, часто используют совместно с C++ и Java. Программисты начинают использовать более чем один язык, в которых дополнительные особенности предоставляются различными языками. Программы на рисунках 1 и 2 следуют этому веянию.
Модели параллелизма с более сильным детерминизмом, чем потоки (такие как сеть обработки Кана, CSP), также уже долгое время существуют. Некоторые из них привели к созданию таких языков программирования как Occam [21] (на основе CSP), а некоторые привели к созданию специализированных сред разработки, например, YAPI [18]. Остальные же не имели сильного влияния на мэйнстрим программирования. Я верю, что это может поменяться, если модели параллелизма будут использованы для создания языков координации, нежели для замены существующих языков.
На этом пути имеется множество трудностей. Разработать хороший язык для координации не легче, чем разработать хороший язык общего назначения. Например, легко попасть в ловушку ложной элегантности использования набора примитивов. Хорошо известно, что для создания языка общего назначения семи примитивов достаточно [48], но нет ни одного серьезного языка, построенного только на этих примитивах.
На рисунке 3 показаны две реализации простых параллельных вычислений. В верхней программе показана адаптация примера [3]: Последовательные выходы из источника данных 1 и 2 чередуются с определенной последовательностью, отражаемой сменой порядка в блоке Display. Тем не менее, эта довольно простая функциональность достигается сложным путем. Фактически, понимание работы этой модели сравнимо со сборкой паззла. Программа внизу гораздо легче для понимания. Блок Commutator выполняет рандеву с каждым из выходов в порядке сверху вниз и таким образом достигается аналогичное чередование. Разумный выбор примитивов языка позволяет простое, прямое и детерминированное выражение детерминированных целей. Верхняя модель использует недетерминированный механизм, хотя является более выразительной для достижения детерминированных целей. Таким образом, ее использование — нерационально.
Конечно, в координационных языках необходимы механизмы реализации масштабируемости и модульности аналогичных тем, которые реализуются в традиционных языках. Это может быть сделано. Например, Ptolemy II представляет собой современный тип систем на уровне координационных языков [49]. Более того, он определяет предварительные формы наследования и полиморфизма, которые адаптированы из объектно-ориентированных техник [35]. Огромные возможности таятся в адаптации высокоуровневых функций в координационные языки. Это позволит создавать аналогичные MapReduce системы на координационном уровне. Несколько много обещающих шагов в этом направлении сделано в [42].
Что более важно, в долгосрочной перспективе необходимо развивать теорию вычислений для получения лучших обоснований параллельных вычислений. Хотя значительный прогресс уже сделан в этом направлении, я верю, что можно сделать намного больше. В разделе 3, последовательные вычисления моделировались, как функциональное отображение одних последовательностей бит – в другие. Соответствующая параллельная модель была введена в [36], в которой вместо функции
 параллельные вычисления задаются функцией
параллельные вычисления задаются функцией 
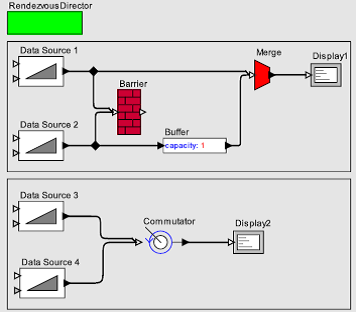
Рисунок 3. Два способа реализация детерминированных чередований с помощью рандеву.
В последней формуле T – частично или полностью упорядоченное множество тэгов, где порядок может представлять собой время, причинную связь или более абстрактные отношения зависимости. Вычисления, проводимые по этой модели, представляют собой отображения «продвинутой» битовой комбинации в «продвинутую» битовую комбинацию. Эта базовая формулировка может быть адаптирована ко многим моделям параллельных вычислений [9, 14, 37].
8 Заключение
Параллелизм в программных приложениях — это сложно. Тем не менее, большинство трудностей является последствием выбранных и используемых абстракций. Доминирующая абстракция – потоки. Но большинство нетривиальных многопоточных программ трудны для понимания. Эти программные модели могут быть улучшены посредством использования паттернов проектирования, лучшей атомарности операций (транзакций), улучшениями языков, формальными методами. Тем не менее, эти техники просто урезают огромный излишек недетерминизма модели потоков. Эта модель, по-прежнему, остается сложной для использования.
Если мы ожидаем, что параллельное программирование станет мэйнстримом и если мы требуем от программ надежности и предсказуемости, тогда мы должны отказаться от потоков как от модели программирования. Должны быть разработаны более понимаемые и предсказуемые модели параллелизма. В их основу должен лечь принцип: детерминированные цели должны достигаться детерминированными средствами. Недетерминизм должен быть аккуратно и явным образом введен там, где это необходимо в программе. Этот принцип, кажущийся очевидным, не используется в потоковой модели. Потоки должны быть перенесены в «машинное отделение» (engine room), чтобы использоваться и распространяться только опытными поставщиками данной технологии.
Литература
[1] P. An, A. Jula, S. Rus, S. Saunders, T. Smith, G. Tanase, N. Thomas, N. Amato, and L. Rauchwerger.
STAPL: An adaptive, generic parallel C++ library. In Wkshp. on Lang. and Comp. for Par. Comp.
(LCPC), pages 193–208, Cumberland Falls, Kentucky, 2001.
[2] F. Arbab. Reo: A channel-based coordination model for component composition. Mathematical Structures
in Computer Science, 14(3):329–366, 2004.
[3] F. Arbab. A behavioral model for composition of software components. L’Object, to appear, 2006.
[4] J. Armstrong, R. Virding, C.Wikstrom, and M.Williams. Concurrent programming in Erlang. Prentice
Hall, second edition, 1996.
[5] D. F. Bacon, R. E. Strom, and A. Tarafdar. Guava: a dialect of Java without data races. In ACM SIGPLAN
conference on Object-oriented programming, systems, languages, and applications, volume 35
of ACM SIGPLAN Notices, pages 382–400, 2000.
[6] U. Banerjee, R. Eigenmann, A. Nicolau, and D. Padua. Automatic program parallelization. Proceedings
of the IEEE, 81(2):211–243, 1993.
[7] L. A. Barroso. The price of performance. ACM Queue, 3(7), 2005.
[8] A. Benveniste and G. Berry. The synchronous approach to reactive and real-time systems. Proceedings
of the IEEE, 79(9):1270–1282, 1991.
[9] A. Benveniste, L. Carloni, P. Caspi, and A. Sangiovanni-Vincentelli. Heterogeneous reactive systems
modeling and correct-by-construction deployment. In EMSOFT. Springer, 2003.
[10] A. Benveniste and P. L. Guernic. Hybrid dynamical systems theory and the signal language. IEEE Tr.
on Automatic Control, 35(5):525–546, 1990.
[11] G. Berry. The effectiveness of synchronous languages for the development of safety-critical systems.
White paper, Esterel Technologies, 2003.
[12] G. Berry and G. Gonthier. The esterel synchronous programming language: Design, semantics, implementation.
Science of Computer Programming, 19(2):87–152, 1992.
[13] R. D. Blumofe, C. F. Joerg, B. C. Kuszmaul, C. E. Leiserson, K. H. Randall, and Y. Zhou. Cilk: an
efficient multithreaded runtime system. In ACM SIGPLAN symposium on Principles and Practice of
Parallel Programming (PPoPP), ACM SIGPLAN Notices, 1995.
[14] J. R. Burch, R. Passerone, and A. L. Sangiovanni-Vincentelli. Notes on agent algebras. Technical
Report UCB/ERL M03/38, University of California, November 2003.
[15] M. Creeger. Multicore CPUs for the masses. ACM Queue, 3(7), 2005.
[16] D. E. Culler, A. Dusseau, S. C. Goldstein, A. Krishnamurthy, S. Lumetta, T. v. Eicken, and K. Yelick.
Parallel programming in Split-C. In Supercomputing, Portland, OR, 1993.
[17] B. A. Davey and H. A. Priestly. Introduction to Lattices and Order. Cambridge University Press, 1990.
[18] E. A. de Kock, G. Essink, W. J. M. Smits, P. van der Wolf, J.-Y. Brunel, W. Kruijtzer, P. Lieverse, and
K. A. Vissers. Yapi: Application modeling for signal processing systems. In 37th Design Automation
Conference (DAC’00), pages 402–405, Los Angeles, CA, 2000.
[19] J. Dean and S. Ghemawat. MapReduce: Simplified data processing on large clusters. In Sixth Symposium
on Operating System Design and Implementation (OSDI), San Francisco, CA, 2004.
[20] J. Eker, J. W. Janneck, E. A. Lee, J. Liu, X. Liu, J. Ludvig, S. Neuendorffer, S. Sachs, and Y. Xiong.
Taming heterogeneity—the Ptolemy approach. Proceedings of the IEEE, 91(2), 2003.
[21] J. Galletly. Occam-2. University College London Press, 2nd edition, 1996.
[22] E. Gamma, R. Helm, R. Johnson, and J. Vlissides. Design Patterns: Elements of Reusable Object-
Oriented Software. Addison Wesley, 1994.
[23] A. Geist, A. Beguelin, J. Dongarra, W. Jiang, B. Manchek, and V. Sunderam. PVM: Parallel Virtual
Machine — A Users Guide and Tutorial for Network Parallel Computing. MIT Press, Cambridge, MA,
1994.
[24] A. Gontmakher and A. Schuster. Java consistency: nonoperational characterizations for Java memory
behavior. ACM Trans. Comput. Syst., 18(4):333–386, 2000.
[25] N. Halbwachs, P. Caspi, P. Raymond, and D. Pilaud. The synchronous data flow programming language
lustre. Proceedings of the IEEE, 79(9):1305–1319, 1991.
[26] T. Harris, S. Marlow, S. P. Jones, and M. Herlihy. Composable memory transactions. In ACM Conference
on Principles and Practice of Parallel Programming (PPoPP), Chicago, IL, 2005.
[27] J. Henry G. Baker and C. Hewitt. The incremental garbage collection of processes. In Proceedings
of the Symposium on AI and Programming Languages, volume 12 of ACM SIGPLAN Notices, pages
55–59, 1977.
[28] T. A. Henzinger, R. Jhala, R. Majumdar, and S. Qadeer. Thread-modular abstraction refinement. In
15th International Conference on Computer-Aided Verification (CAV), volume 2725 of Lecture Notes
in Computer Science, pages 262–274. Springer-Verlag, 2003.
[29] C. A. R. Hoare. Communicating sequential processes. Communications of the ACM, 21(8), 1978.
[30] P. Hudak. Conception, evolution, and application of functional programming languages. ACM Computing
Surveys, 21(3), 1989.
[31] G. Kahn and D. B. MacQueen. Coroutines and networks of parallel processes. In B. Gilchrist, editor,
Information Processing. North-Holland Publishing Co., 1977.
[32] D. Lea. Concurrent Programming in Java: Design Principles and Patterns. Addison-Wesley, Reading
MA, 1997.
[33] E. A. Lee. Modeling concurrent real-time processes using discrete events. Annals of Software Engineering,
7:25–45, 1999.
[34] E. A. Lee. What’s ahead for embedded software? IEEE Computer Magazine, pages 18–26, 2000.
[35] E. A. Lee and S. Neuendorffer. Classes and subclasses in actor-oriented design. In Conference on
Formal Methods and Models for Codesign (MEMOCODE), San Diego, CA, USA, 2004.
[36] E. A. Lee and A. Sangiovanni-Vincentelli. A framework for comparing models of computation. IEEE
Transactions on CAD, 17(12), 1998.
[37] X. Liu. Semantic foundation of the tagged signal model. Phd thesis, EECS Department, University of
California, December 20 2005.
[38] H. Maurice and J. E. B. Moss. Transactional memory: architectural support for lock-free data structures.
In Proceedings of the 20th annual international symposium on Computer architecture, pages 289–300,
San Diego, California, United States, 1993. ACM Press.
[39] Message Passing Interface Forum. MPI2: A message passing interface standard. International Journal
of High Performance Computing Applications, 12(1-2):1–299, 1998.
[40] G. Papadopoulos and F. Arbab. Coordination models and languages. In M. Zelkowitz, editor, Advances
in Computers — The Engineering of Large Systems, volume 46, pages 329–400. Academic Press, 1998.
[41] W. Pugh. Fixing the Java memory model. In Proceedings of the ACM 1999 conference on Java Grande,
pages 89–98, San Francisco, California, United States, 1999. ACM Press.
[42] H. J. Reekie. Toward effective programming for parallel digital signal processing. Ph.D. Thesis Research
Report 92.1, University of Technology, Sydney, 1992.
[43] H. J. Reekie, S. Neuendorffer, C. Hylands, and E. A. Lee. Software practice in the Ptolemy project.
Technical Report Series GSRC-TR-1999-01, Gigascale Semiconductor Research Center, University of
California, Berkeley, April 1999.
[44] D. C. Schmidt, M. Stal, H. Rohnert, and F. Buschmann. Pattern-Oriented Software Architecture — Patterns for Concurrent and Networked Objects. Wiley, 2000.
[45] N. Shavit and D. Touitou. Software transactional memory. In ACM symposium on Principles of Distributed
Computing, pages 204–213, Ottowa, Ontario, Canada, 1995. ACM Press.
[46] L. A. Stein. Challenging the computational metaphor: Implications for how we think. Cybernetics and
Systems, 30(6), 1999.
[47] H. Sutter and J. Larus. Software and the concurrency revolution. ACM Queue, 3(7), 2005.
[48] A. M. Turing. Computability and _-definability. Journal of Symbolic Logic, 2:153–163, 1937.
[49] Y. Xiong. An extensible type system for component-based design. Ph.D. Thesis Technical Memorandum
UCB/ERL M02/13, University of California, Berkeley, CA 94720, May 1 2002.
