У социальной сети Одноклассники, как и у других интернет-ресурсов, где пользователи могут загружать любой контент, существует задача фильтровать изображения, нарушающие законы Российской Федерации и лицензионное соглашение самой площадки. Таким контентом в соцсети считается порнография в открытом доступе, а также сцены насилия, жестокости и прочие ужасные картинки.
Ежедневно в социальную сеть загружается более 20 миллионов картинок. Для того чтобы их проверить, наши инструменты на основе нейронных сетей автоматически фильтруют картинки определенных категорий. Однако часть контента мы пропускаем через ручную разметку, так как не всегда нейронная модель однозначно может определить, есть запрещенный контент на картинке или нет. Наш любимый пример пограничного контента — диван из разряда «показалось».

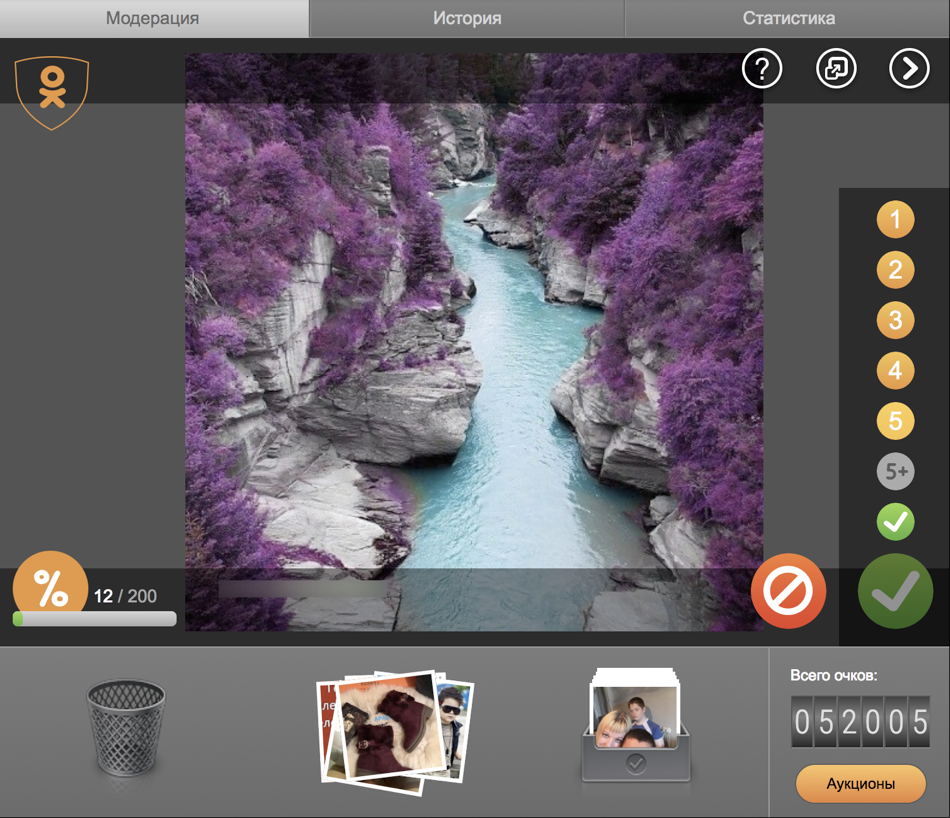
Кроме внутренней модерации, у нас создано игровое приложение «Модератор Одноклассников», где любой пользователь соцсети может обрабатывать поток изображений, разделяя фотографии на запрещенный контент и «хороший» – тот, что соответствует правилам соцсети. За каждое правильное решение модератор получает очки, которые потом может потратить на покупку внутренних платных услуг Одноклассников. Конечно, пользователям в приложении показываются только публичные и общедоступные изображения. Ниже пример скриншота приложения.
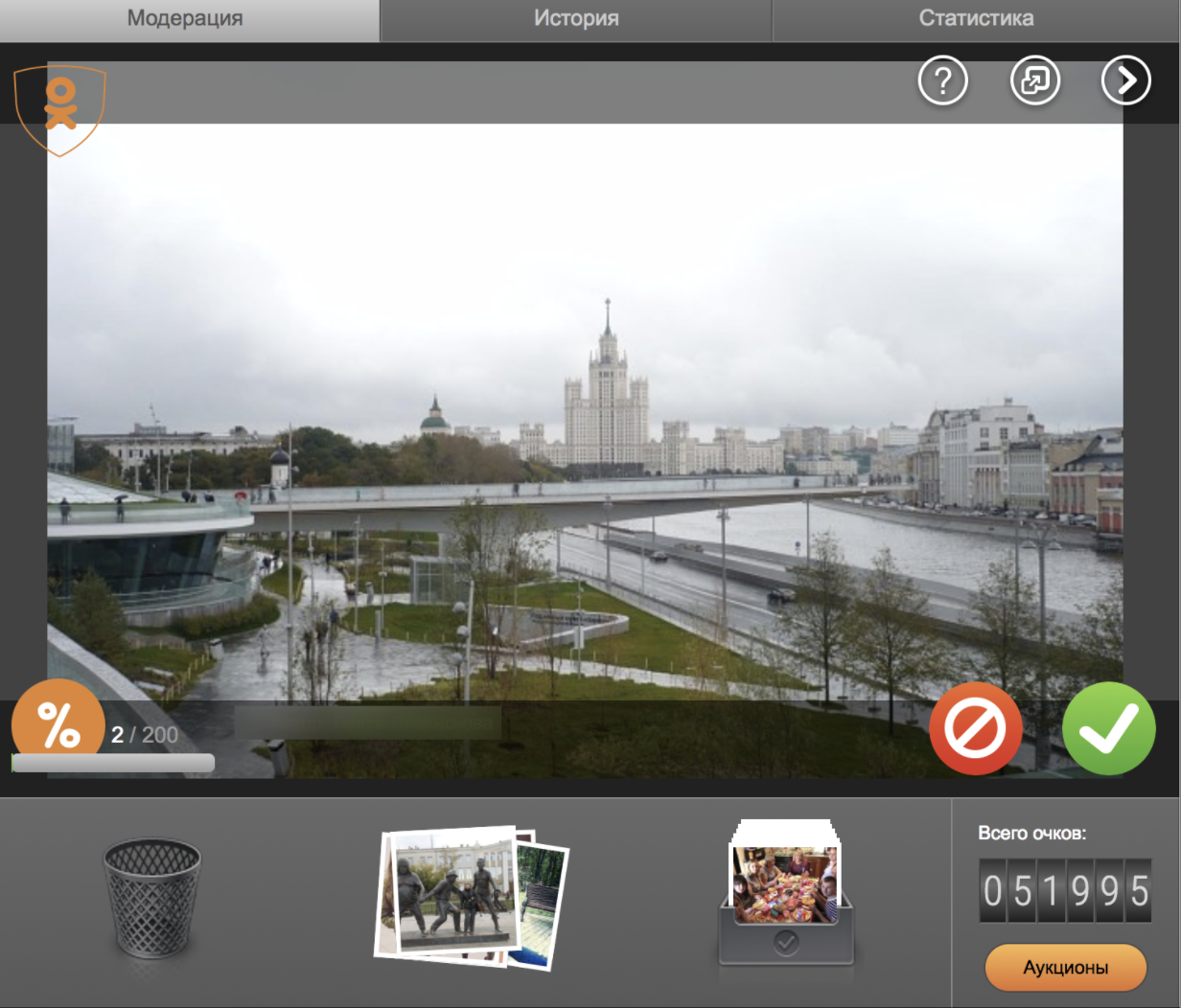
Разметка из приложения в дальнейшем используется для обучения нейронных моделей. А если кому-то будет интересно почитать о том, как мы геймифицировали разметку изображений, мы напишем об этом отдельную статью. :)
Задача
DAU (daily active users — количество уникальных пользователей за сутки) приложения «Модератор Одноклассников» скромное: около 40 тысяч. Это позволяет размечать 3—4 миллиона картинок в сутки. Задача, о решении которой мы расскажем ниже, заключалась в увеличении DAU. Ведь чем больше пользователей станет играть, тем больше картинок будет размечено.
Кроме того, мы договорились, что если в итоге новых пользователей мы привлечем не так много, но при этом заметно прибавится количество размечаемых изображений в сутки, то такой результат будет также положительным. Чтобы справиться с задачей, мы решили воспользоваться методами машинного обучения. Все описанные ниже классификаторы строились на Python c помощью scikit-learn.
Первый этап создания модели
Итак, перед нами стоит задача бинарной классификации пользователей. Разделить их на тех, кому приложение может понравиться, и тех, кого оно, скорее всего, не заинтересует. Начнем с подготовки обучающей выборки. Так как у нас есть статистика по пользователям приложения (приложение работает с 2014 года), выбираем их в качестве объектов обучения. Теперь определимся с двумя вещами:
- Как разделить пользователей на два класса: заинтересованные и незаинтересованные.
- Какие признаки пользователя брать для обучения.
Логично предположить, что если пользователю понравилось приложение, то играть он будет неоднократно. И наоборот, если приложение не приглянулось, вряд ли пользователь вернется после первой игры. Мы решили разделить пользователей по этому признаку следующим образом:
- Те, которые продолжают играть в приложение спустя семь дней после первой игры, считаются заинтересованными.
- Те, которые сыграли один раз и больше не возвращались, считаются незаинтересованными.
В результате у нас получился следующий размер обучающей выборки: около 133 000 заинтересованных и около 262 700 незаинтересованных пользователей.
Полдела сделано, пора выбирать признаки.
Для начала мы взяли такие обычные признаки, как пол и возраст. Затем мы начали рассуждать: что может мотивировать пользователя помогать нам модерировать запрещенный контент? Скорее всего, это категория людей, которые выступают против него в публичном доступе. Такие пользователи чаще, чем другие, нажимают кнопку «Пожаловаться». Поэтому следующим признаком мы взяли количество жалоб на контент.
Помимо «светлых» целей у человека может быть и небольшой корыстный интерес: получить бесплатно платную услугу за разметку картинок. Поэтому мы добавили признаки, связанные с покупкой услуг Одноклассников. И конечно, мы не могли не задаться вопросом, какие еще приложения пользователь запускал в Одноклассниках. Используя критерий хи-квадрат (метода фильтрации признаков chi-square test), мы отобрали наиболее значимые для классификации приложения, которые и стали нашими последними признаками.
В итоге у нас получился датасет из около 396 000 пользователей с 49 признаками. Датасет разделили на обучающую и тестовую выборку. Первую выборку использовали для обучения, а вторую — для сравнения следующих классификаторов: kNN, SVM, AdaBoost, RandomForest, DecisionTree, LogisticRegression, GradientBoostingClassifier.
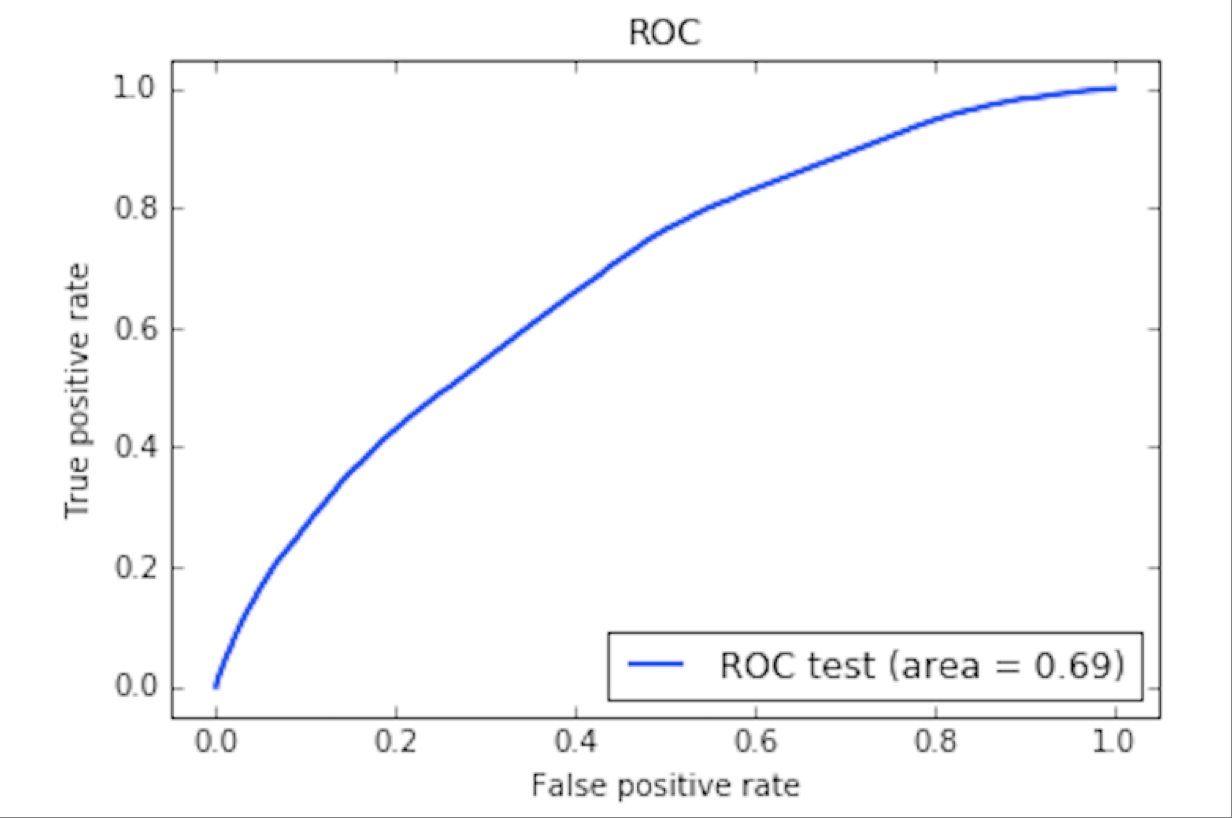
У классификаторов есть собственные начальные параметры (например, количество соседей у kNN), от которых зависит их качество. Такие параметры подбирались для каждого классификатора на обучающей выборке с помощью кросс-валидации. Для этого использовались GridSearch и Stratified KFold из scikit-learn. Для обученных классификаторов с подобранными параметрами строились ROC-кривые (receiver operating characteristig) на тестовой выборке. После этого классификаторы сравнивались по AUC score (area under ROC-curve, площадь под ROC-кривой) соответствующих ROC-кривых. Чем выше данный показатель, тем более качественным считается классификатор. В итоге лучшим по AUC оказался классификатор GradientBoostingClassifier. Ниже показана его ROC-кривая по результатам обучения.
Полевые испытания первой модели
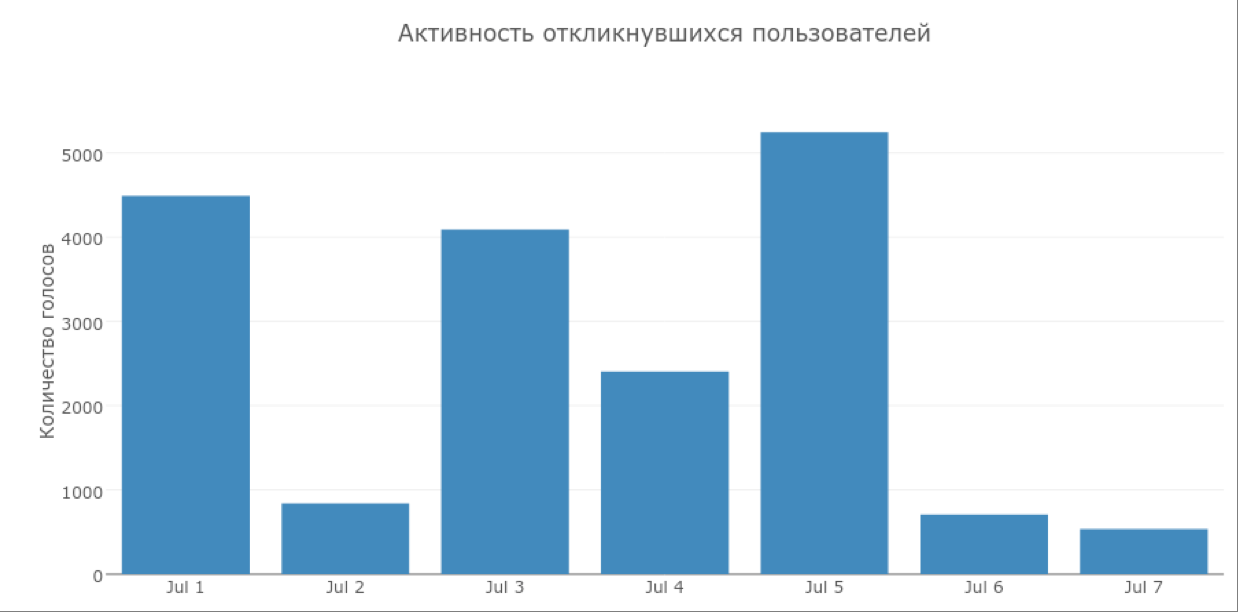
Получившийся классификатор мы протестировали на 500 000 случайных пользователей. После чего отфильтровали их по активности в социальной сети, возрасту (наше приложение имеет рейтинг 18+) и получили 3949 кандидатов. Кандидатам внутри Одноклассников разослали пуши с приглашениями попробовать наше приложение.
За неделю с момента рассылки пушей в приложение зашли всего 59 человек (1,5 % общего количества кандидатов). Результаты оказались, мягко говоря, далеки от желаемых.
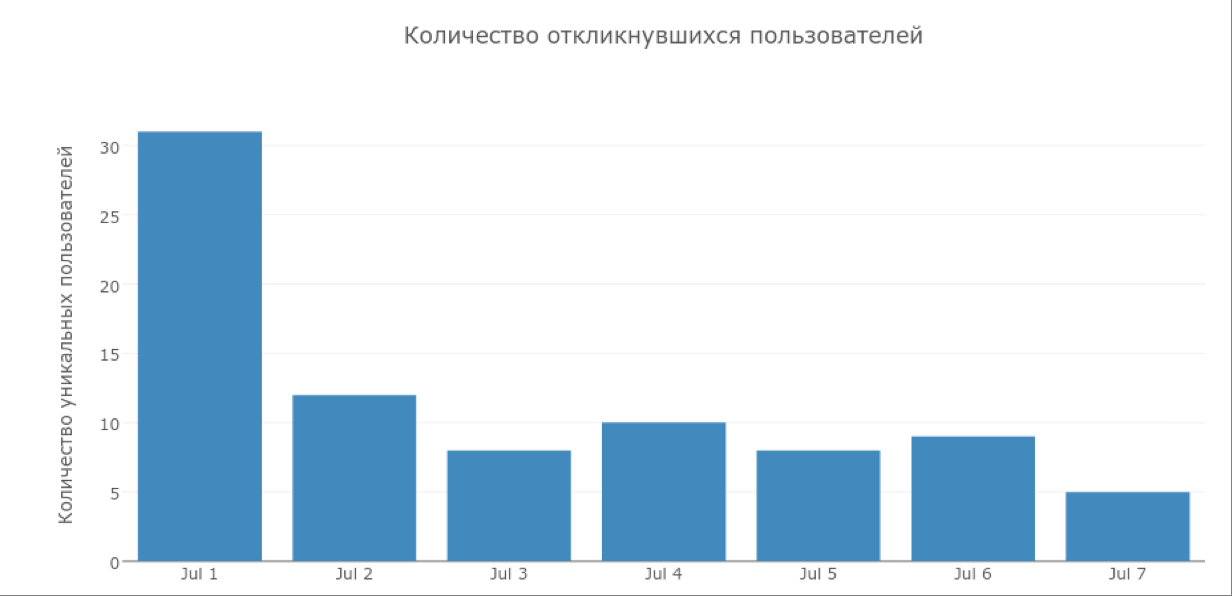
Тем не менее 59 новых пользователей за неделю обработали около 19 000 изображений, так что мы не отчаялись и решили предпринять вторую попытку.
Второй этап создания модели
При второй попытке мы решили изменить подход к разделению пользователей на два класса. Основной упор сделали на увеличение количества обработанных изображений. На базе такого критерия мы выделили заинтересованных пользователей, которые играют постоянно и размечают более 6000 изображений за неделю.
Мы выгрузили данные за неделю и получили новый размер обучающей выборки: около 4400 заинтересованных пользователей, около 7740 незаинтересованных (менее 5 размеченных изображений) и около 106 630 пользователей, проверивших от 5 до 6000 изображений.
В датасет добавили новые признаки: факт заполнения профиля (семейное положение, школа, вуз, место работы), карма пользователя: добавляли ли его в черный список, жаловались ли на его контент, а также активность в социальной сети: создание постов, «классы», комментарии к контенту других пользователей.
Также мы добавили сведения о том, какие приложения пользователь открывал за последний месяц (ведь со временем вкусы человека могут меняться, а нам интересно текущее положение вещей).
Собрав новый датасет, мы решили посмотреть на наиболее значимые признаки. Часть из них оказалась подозрительно хороша. Например, распределение признака «оценки фотографии» между категориями пользователей выглядело следующим образом.
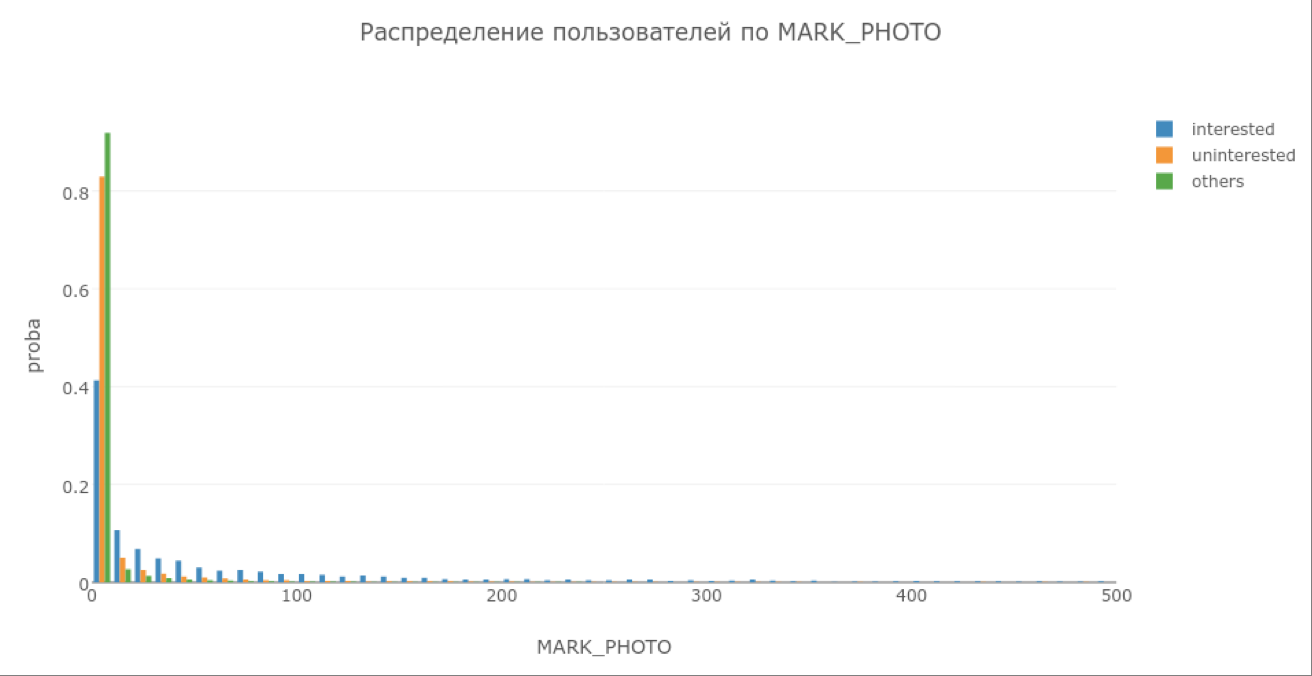
На графике по оси Х — количество оценок фото за неделю, а по оси Y — доля пользователей из соответствующей категории, которые поставили Х оценок. Дело в том, что интерфейс нашего приложения (на скриншоте столбик оценок справа) позволяет игроку в том числе ставить оценки проверяемым фото во время разбора картинок, чем и объясняется полученный график.
В связи с этим мы решили убрать данный и схожие подозрительные признаки из выборки. А вот по возрасту, например, получилась более интересная картина (см. график ниже), поэтому возрастные критерии были оставлены.
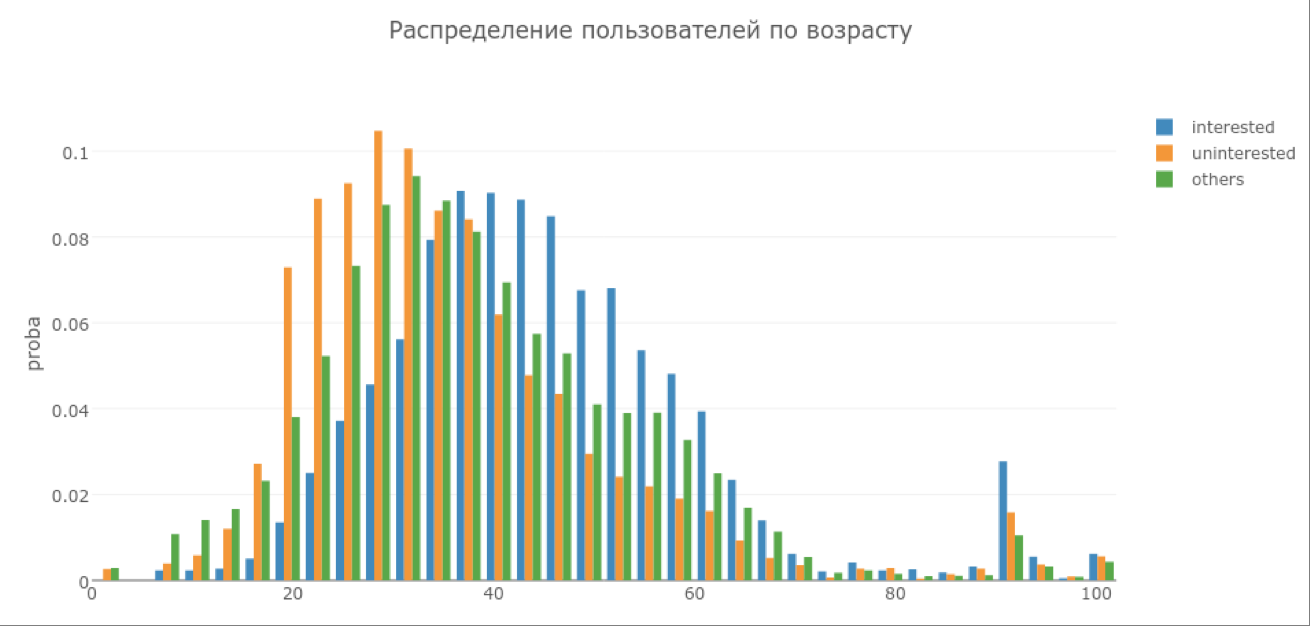
На графике по оси Х — возраст пользователей, а по оси Y — доля поля пользователей с возрастом Х в соответствующей категории. Повторив обучение на новом наборе данных, мы получили следующую ROC-кривую для лучшего классификатора.
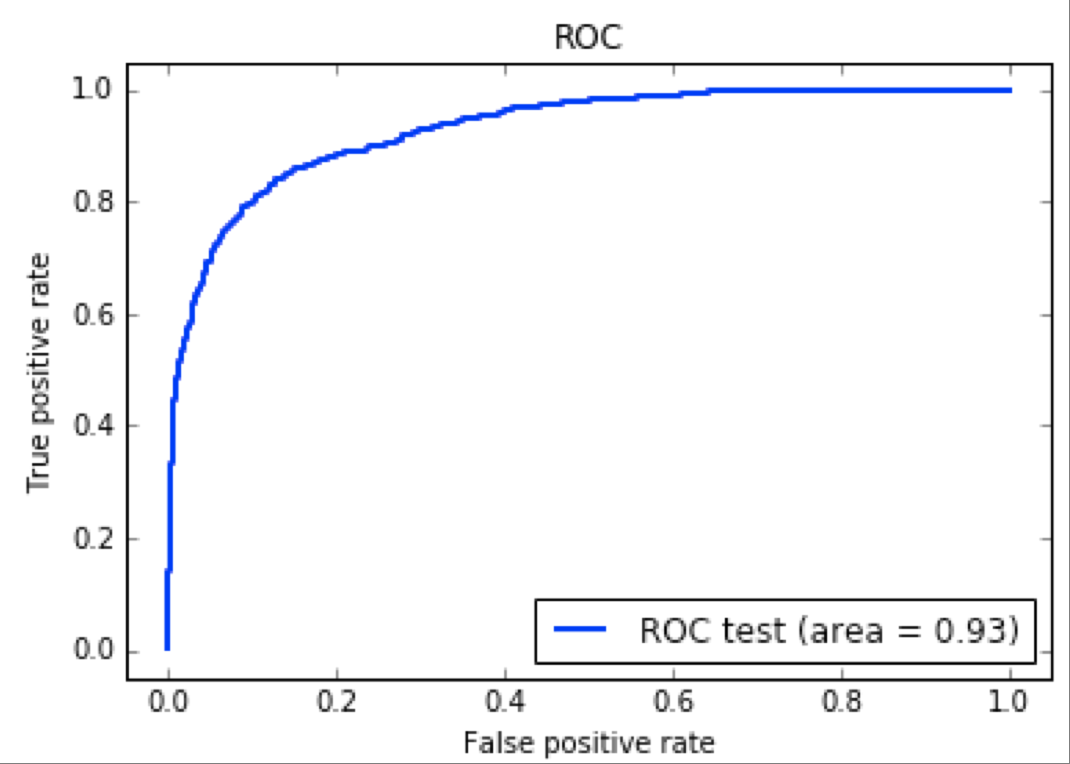
По сравнению с первым заходом AUC уже выглядело более привлекательным, и мы перешли к полевым испытаниям.
Полевые испытания второй модели
В этот раз из случайного подмножества пользователей, отфильтрованных по активности и возрасту, наша модель отобрала 60 000 потенциальных кандидатов. Также для получения сравнительных статистических данных дополнительно случайным образом выбрали еще 60 000 пользователей.
В результате нотификация с предложением опробовать наше приложение была отправлена 60 000 кандидатам от модели и 60 000 случайным пользователям. Спустя неделю статистика показала, что в приложение зашли 5056 человек, то есть около 4 % из 120 000 получателей пушей. Посмотрим, кого из них выбрал классификатор, а кто попал благодаря всемогущему рандому:
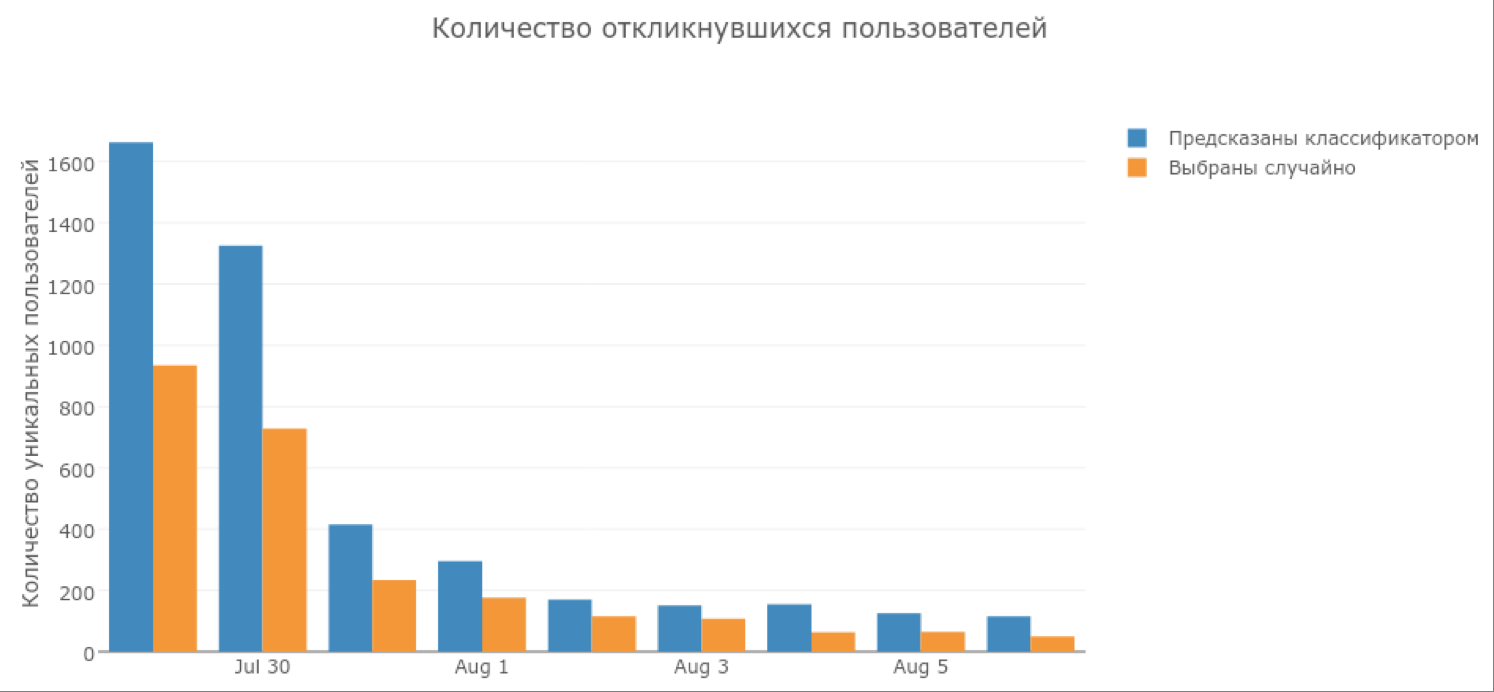
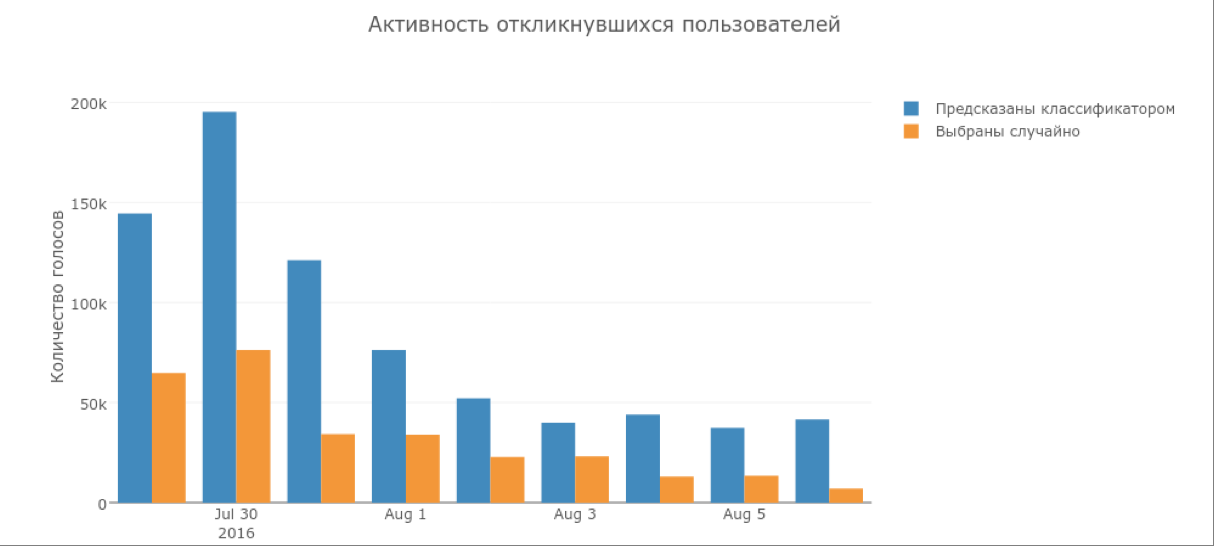
Вторая модель привлекла в два раза больше пользователей, чем рандомная рассылка. Точно так же дело обстоит и с количеством обработанных изображений: пользователи, привлеченные моделью, размечали в 2—2,5 раза больше картинок.
Также стоит отметить, что часть пользователей, выбранных моделью, начали играть каждый день, в то время как пользователи из рандомной выборки к концу недели почти перестали заходить в игру.
Итоги
Что мы вынесли для себя по итогам создания и испытания модели:
- Первый результат обучения классификатора далеко не всегда будет положительным. Но он должен не приводить к остановке обучения, а, наоборот, давать пищу для последующих экспериментов.
- При выборе признаков для датасета стоит понимать, как каждый признак может повлиять на результат. Оптимально подкреплять выбор каждого признака статистикой.
- Хорошо обученная модель — лишь часть успеха. На конечный результат влияют и другие факторы:
- Каким образом пользователь получает рекламу. Например, можно было добавить признак того, как часто пользователи кликают на пуши в мобильной и в веб-версии портала.
- Очень важен и текст самого пуша. Пользователи чаще реагируют на вирусный текст, чем на обычный. Например, на пуш с текстом «Бесплатные ОКи, играй и выигрывай!» будет кликов больше, чем на пуш «Попробуйте наше приложение». Если вирусный текст подкрепить вирусной картинкой — эффект возрастет.
- В какое время стоит рассылать пуши. Например, если пользователи из датасета в большинстве своем живут в Москве, по прогнозу Гидрометцентра смотрим ближайший дождливый день и его определяем как день для рассылки. Расчет на то, что в дождь люди не пойдут гулять и будут сидеть в соцсети. А значит, шанс того, что они увидят наш пуш сразу после отправки, возрастет.
- То же самое касается и времени рассылки: если пользователи преимущественно живут во Владивостоке, то рассылку в 18:00 по московскому времени они прочтут только утром, спустя 7—8 часов. За это время наш пуш может затеряться среди других пушей пользователя.
