
Для таргетинга мы в Ozon используем сегменты, в которые группируем пользователей по интересам, а они могут быть определены через систему трекинга событий. Последние в свою очередь формируются в процессе взаимодействия пользователя с маркетплейсом Ozon. На основе сегментов мы отправляем нотификации, рассылаем письма, показываем рекомендации, баннеры, страницы с товарами и цены на товары, участвующие в маркетинговых акциях. В принципе, на сегменты можно завязать любую механику. Мы даже А/В тесты иногда проводим с ними.
Первоначально сегменты создавались вручную: поступал запрос от заказчика, после чего проводилась аналитическая работа по сбору требований. Но количество заявок на создание сегментов со временем только увеличивалось. Чтобы автоматизировать процесс создания сегментов мы создали конструктор сегментов для DMP — Data Management Platform. Это относительно молодой проект, ему чуть больше двух лет, но уже он полностью себя оправдал. Сегодня расскажу вам о нашем опыте. Меня зовут Евгений Чмель, и я руковожу командой DMP & CDP.

DMP позволяет сегментировать аудиторию используя разные фильтры на больших объемах данных. Его ключевые понятия:
Сегмент — набор пользователей (выбираем по их user_id и session_id), который формируется по различным правилам (фильтрам).
Фильтры — можно использовать город, бренд, категорию, поисковый запрос или тип платформы, с которой взаимодействует пользователь.
Атрибуты — применяются для определения характеристик сегмента.
В характеристики сегмента, в свою очередь, включены:
номер сегмента;
его название;
количество времени, которое пользователь в нём находится;
тип сегмента;интервал его существования (от даты создания до момента, когда его можно удалить);
количество пользователей в сегменте.
Когда мы пришли к тому, что нужно создавать конструктор сегментов, то первый вопрос, который у нас возник: на каких данных автоматизировать сборку сегментов? Ответ уже был — наш трекер собирает все пользовательские события в два хранилища: СlickHouse и HDFS (Hadoop Distributed File System). Чтобы решить, из чего можно получать данные, мы провели небольшие тесты. Они показали, что время выполнения запросов через Spark поверх HDFS в 30 раз выше, а бывало, что и в 100 раз. Поэтому мы остановились на ClickHouse.
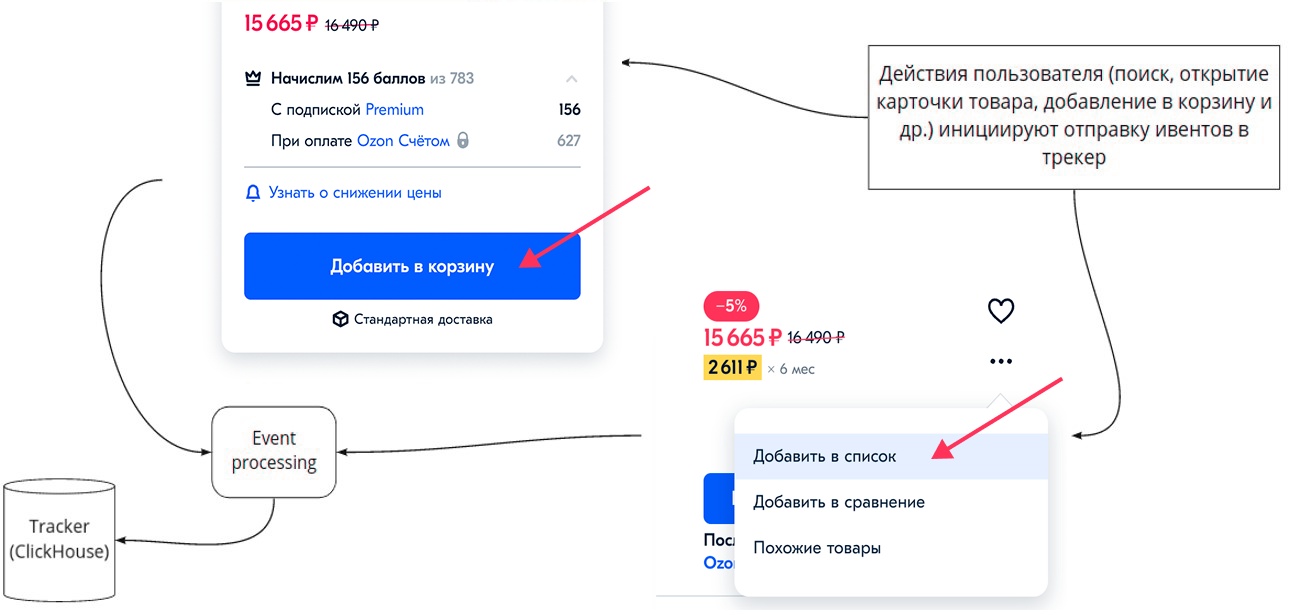
Позже к нему добавили Vertica для построения сегментов по заказам. Раз в сутки в него выгружаются данные из сервисной БД OMS (Order Management System). По ним можно строить сегменты, например, по среднему чеку или что пользователь купил за последние 2 недели, месяц, год — то есть узнать, чем он интересуется. Пример взаимодействия пользователя с Ozon, в результате чего появляется событие — клик на товаре, просмотр, добавление в корзину и другие действия:

После действий пользователя событие попадает в трекер и в ClickHouse. Или, если пользователь оформляет заказ — передается в OMS, а потом, раз в сутки, складывается в Vertica. Для пользователя это выглядит так:
Для менеджера создание сегмента начинается с задания фильтра. Он указывает нужное ему действие пользователя в категории товаров, задает тип сегмента и интервал выборки. Интервал мы ограничили до 90 дней, чтобы не перегружать ClickHouse. Здесь же выбираются сегменты, из которых пользователя нужно исключить:

Для отладки мы добавили фичу, которая просматривает те запросы, которые могут быть сформированы для ClickHouse и Vertica.

Архитектура DMP
DMP в сухом остатке состоит из двух таблиц, а id_map содержит связки, на которые ссылается таблица с сегментами. У каждой связки есть корневой элемент — target_id, который объединяет id и сессии пользователя:

Пример сегмента:

В этой таблице всего две колонки, а dmp_id — тот самый target, который ссылается на связки, хранящиеся в id_map. dmp_id — ключ, по которому шардирована таблица segments. На текущий момент — 24 шарда с конфигурацией master + 2 слейва. В качестве ключей JSON используются id сегментов, в данном случае 66 и 365. Source — это источник, который инициировал создание сегмента, а recency и expires — timestamps, то есть время добавления пользователя в сегмент и время выхода пользователя из него.
После того, как менеджер создал сегмент, dmp-segments-importer формирует расписание с условиями сборки и на его основе периодически создает задачи на пересборку сегментов. Весь процесс сборки сегмента по запросу менеджера выглядит так:

То есть, dmp-segments-importer — это конструктор сегментов + API по добавлению пользователей в сегменты. Любой сервис может дёрнуть ручку и добавить туда батч пользователей.
Пример работы фильтров, где мы объединяем фильтры A и B, формируем запрос в ClickHouse и получаем id. После чего импортёр сохраняет все полученные результаты в набор под каким-либо сегментом:
Условие сборки сегмента
{
"formula": "A|B",
"requests": {
"A" {
"body": {
"filter": {
"$and": [
{"$event_alias": "view_pdp_product"},
{"$date_alias": "LAST_60_DAYS"},
{"$field": "properties_brand_id","$value": 87314531,"$operator": "$eq"}
]
}
},
"source": "tracker"
},
"B":{
"body": {
"filter": {
"$and": [
{"$event_alias": "favorite_product"},
{"$date_alias": "LAST_60_DAYS"}
{"$field": "properties_brand_id","$value": 87314531,"$operator": "$eq"}
]
}
},
"source": "tracker"
}
},
"selection_entity": "USER_TYPE_ID"
}Пример простого запроса в ClickHouse для одного фильтра:
Запрос для одного фильтра
SELECT DISTINCT user_client_id
FROM events
WHERE attributes_namespace = 'bx'
AND action_type = 'view'
AND object_type = 'product'
AND action_widget = 'pdp-widget'
AND date BETWEEN '2021-03-04' AND '2021-05-03'
AND has([87314531], dictGetUInt64('sku', 'brand_id', toUInt64(object_sku)));Запросы могут быть очень большими и выполняться будут намного медленнее, чем параллельное выполнение каждого подзапроса. Поэтому мы делаем разбивку, отправляя несколько мелких запросов параллельно, а затем применяем алгоритм сортировочной станции, чтобы отсекать ненужных пользователей по формуле для полученных id. Такой подход позволяет нам использовать разные источники данных для построения сегментов.
Сборка real-time-сегментов
Для сборки сегментов в реальном времени мы создали сервис dmp-events-consumer. Пользователь добавляется в сегмент настолько быстро, насколько это возможно при получении события из Kafka:

Консьюмер слушает топики сервисов — трекера, OMS и других, и при получении события определяет его тип и в зависимости от условий добавляет пользователя в сегмент или нет. Условия могут быть связаны с походами в другие сервисы или быть ограничены проверками атрибутов полученного ивента. Логика по формированию real-time сегмента пишется каждый раз разработчиком, пока конструктора для сборки таких сегментов нет.
Объединение сегментов
Сегменты нужно объединять, если пользователь совершал какие-то действия, но не был залогинен в систему. У него была только сессия, мы не знали его id, но для него уже создались сегменты в системе. И когда он залогинился, то оказалось, что для его id есть и другие сегменты. Тогда они объединяются, эту операцию выполняет dmp-events-consumer:

Выдача сегментов
Еще у нас есть задача возвращать все сегменты, которые есть для пользователя, тем сервисам, что отправляют в DMP запрос user_id или session_id. Это делает dmp-api:

Экспорт и пересечение сегментов
Также бывает нужно вернуть всех пользователей из сегмента или выполнить пересечение различных сегментов. Так как мы храним сегменты в PostgreSQL, то выбрать всех пользователей из базы — сложно и долго. Поэтому dmp-segments-exporter экспортирует все сегменты раз в сутки в ClickHouse. После чего с помощью сервиса dmp-statistics-api мы выполняем пересечение по этим сегментам:

Пример запроса в dmp-statistics-api на получение количества пользователей в сегменте по формуле на определенную дату:
curl \
-X POST "http://dmp-statistics-api.bx/segments/expression/quantity" \
-d "{ \"formula\": \"372 & 536 & 576\", \"targetDate\": \"2020-06-15T08:03:08.485Z\"}"Ответ:
{
"quantity": 531789,
"targetDate": "2020-06-15T00:00:00Z"
}Здесь мы оперируем сегментами как множествами. Передаем формулу, состоящую из трёх сегментов, и в результате получаем пересечение на определенную дату. Как правило, используется текущая дата.
Второй пример:

Пример запроса в API на получение списка пользователей в сегменте с номером 376:
curl \
-X POST "http://dmp-statistics-api/segments/users" \
-d "{ \"limit\": 100,\"segmentId\": \"376\"}"Пример запроса в сервис для получения пересечения трех сегментов:
curl \
-X POST "http://dmp-statistics-api/segments/expression/quantity" \
-d "{ \"formula\": \"1 & 2 & 3\"}"При этом в ClickHouse формируется запрос такого вида:
SELECT count()
FROM dmp_segments_history
WHERE segment_id = 1
and date = 'date'
AND dmp_id IN (SELECT dmp_id FROM dmp_segments_history
WHERE segment_id = 2 and date = 'date')
AND dmp_id IN (SELECT dmp_id FROM dmp_segments_history
WHERE segment_id = 3 and date = 'date')На вход принимается формула, делается запрос (внутри есть билдер запросов), и результат возвращается пользователю. Всё это выполняется довольно быстро. Но по мере роста базы сегментов резонно использовать вероятностные структуры данных, например, фильтр Блума. Так же может быть полезным использование битовых карт, если вы всегда оперируете числовыми значениями.
Тем не менее внедрение платформы DMP не обошлось без некоторых трудностей.
Проблемы
Большие JSON’ы
Первая проблема, с которой мы столкнулись, была связана с постепенным увеличением размера поля с сегментами, которое имеет тип JSONB. Поначалу деградация скорости чтения/записи (CPU, disk IO) не ощущалась, но со временем стало очевидно, что слишком много времени тратится на распаковку и сжатие JSON.
Чтобы уменьшить потребляемое место на диске и ускорить операции чтения-записи над JSON с сегментами, мы решили удалять сегменты с истекшим TTL — которые больше не нужны бизнесу и не участвуют ни в каких акциях и рассылках. Для этого мы реализовали сервис dmp-segments-gc и переписываем JSON, когда нам нужно обновить хотя бы один сегмент пользователя:

Мы провели ряд нагрузочных тестов на запись и чтение для разных моделей данных. Сравнили построчное хранение сегментов (когда номер сегмента и его атрибуты хранятся в разных колонках) с хранением в JSONB. Из-за фрагментированности данных, построчная модель показала себя несколько хуже. Дело в том, что PostgreSQL при выборке всех сегментов по конкретному пользователю выполнял больше чтений буфферных страниц, чем при чтении этих же сегментов, но уже из JSONB. Фрагментированность возникала из-за частых обновлений сегментов, а обновление сегментов происходит постоянно.
Основная часть сегментов обновляется по расписанию. При этом время старта обновления выставляется рандомно при создании каждого сегмента, с целью получения равномерной нагрузки на кластер ClickHouse и Vertica, а так же более оптимального потребления памяти сервисом.
Первоначально запросы на обновление сегментов выстраивались в очередь. Это значит, что если надо обновить 10 сегментов, каждый из которых содержит 5 миллионов пользователей, то формировались батчи со списками пользователей на обновление и при этом каждый батч содержал обновление только по одному сегменту. Если допустить, что один батч мог содержать 7000 пользователей, то в пределе имеем 5000000*10/7000 = 7143 батча.
На текущий момент сегментов около 3000. И при текущей конфигурации кластеров обновление всех сегментов будет выполняться очень долго, даже если слать батчи по разным сегментам одновременно. Для ускорения обновления мы решили сливать в один батч обновление по нескольким сегментам сразу.
В реальности это работает следующим образом: в течение 15-ти минут копится буфер пользователей по каждому сегменту, которые должны быть записаны или удалены из сегмента, после чего данные из буфера нарезаются на батчи (батч — это мапа, у которой ключ — id пользователя, а значение — список сегментов). Конечно в этом случае размер батча в байтах увеличился, но количество операций ввода-вывода у PostgreSQL значительно сократилось:

Изначально обновление таблицы с сегментами выполнялось в двух сервисах, что вело к определенным издержкам на сопровождении (понятно, что это антипаттерн). Мы решили вынести операцию обновления в один сервис — dmp-segments-worker, который получает команды на обновление из Kafka:

Проблемы операции слияния пользовательских сегментов
У пользователей есть идентификаторы сессий, которые могут время от времени меняться. При наступлении события аутентификации, DMP пытается выполнить слияние сегментов, которые закреплены за текущей сессией, с сегментами, которые закреплены за user_id пользователя. Иногда такая операция может выполняться довольно часто, особенно с учетками для автотестов.
Из-за частой смены сессий у таких аккаунтов операция слияния сегментов стала сильно притормаживать. Причина была в увеличении количества перелинковок. Ведь мы связывали предыдущие сессии с user_id через target_id при наступлении каждого события аутентификации. Чтобы решить эту проблему, мы ограничили количество сохраняемых сессий для одного target_id и изменили алгоритм объединения. Сессиям можно задавать время жизни в DMP и удалять таковые при экспирации.
Ограничения инфраструктуры
Сначала у нас был один шард (мастер + 2 слейва) для хранения сегментов и мы довольно быстро уперлись в лимит, выставленный DBA. Например, одно из ограничений — 17К IOps на одну ноду, которое является стандартным для любой инсталляции PostgreSQL в Ozon. Ограничения выставляются с целью снизить влияние «шумных соседей», контролировать потребление ресурсов и быстро находить наиболее подходящий сервер для переноса или поднятия новой реплики.
Наша таблица сегментов быстро росла и увеличивалась из-за фрагментированности данных. С целью оптимизации потребляемого места на диске мы стали выполнять (каждый месяц) pg_repack. Это процедура занимала 4–6 часов и не всегда проходила удачно с первого раза. Для pg_repack желательно снижать интенсивность записи, но так как запись была очень активной, то нам приходилось её вообще практически останавливать.
Такими были наши показатели по Load Average:

Чтобы снизить интенсивность записи, мы разбили таблицу segments на 12 шардов, segments и id_map стали храниться в разных местах. И это помогло. Сейчас IOps у id_map не достигает даже 3K. На серверах потребление на мастере стало примерно 5K IOps, на репликах — около 3K. Количество апдейтов при этом — от 2,5 до 3 K в секунду (на момент публикации статьи 24 шарда):

Лишние перезаписывания сегментов
Обновление сегмента чаще всего выполняется раз в сутки. Таблица с событиями в ClickHouse партиционирована по дням, и при достаточно большой выборке — например, при фильтрации за последние 90 дней — выполняется процессинг большого объема данных. При этом ClickHouse возвращает много пользовательских айдишников (будем называть их активным сетом), которые надо сохранить в сегмент:

Чтобы уменьшить этот сет, мы стали пересекать его с набором тех пользователей, что имели активность с момента последнего обновления (как правило 2 календарных дня), и это дало положительный эффект.
На момент публикации статьи мы успели добавить сохранение активного сета в виде битмапы в Ceph, перед сохранением в PostgreSQL. Для таких сегментов не существует TTL и при каждом обновлении выполняется операция сравнения активного сета предыдущей сборки с текущей. На выходе получаем два массива: 1-ый — пользователи, которых надо добавить в сегмент; 2-ой — пользователи, которых надо удалить из сегмента. Таким образом мы еще больше снизили нагрузку на запись в PostgreSQL.

Общая схема сервисов DMP:

Выводы
Чем больше JSONB, тем сильнее ощущается деградация скорости чтения/записи (CPU, disk IO). Большие JSON подвергаются механизму TOAST: PostgreSQL создает отдельную таблицу, в которой JSON сохраняется в виде нарезанных чанков по 2 Кбайт. У нас встречаются экземпляры по >19 Кбайт, в этом случае содержимое одной записи разбивается на несколько страниц, то есть фактически даже одно поле JSONB может быть разбито на несколько чанков. С увеличением размера поля ситуация только ухудшается. Это не очень хорошо, но в принципе терпимо.
Очевидно, что сегменты следует обновлять батчами, например, по 3–4K пользователей. При использовании построчной (нормализованной) модели можно столкнуться с сильной деградацией чтения из-за фрагментированности данных. Чтение одной записи c JSONB будет требовать меньше обращений к диску, по сравнению с нормализованной моделью. При большом количестве сегментов JSONB оказывается выгодней.
Шардинг позволяет масштабироваться горизонтально. У PostgreSQL нет шардинга из коробки, поэтому приходится делать распределенное обращение к БД на стороне клиентского приложения. Ноды желательно делать как можно меньше по объему данных. Для шардинга мы использовали подход с виртуальными бакетами. Он описан в этой статье.
Видео моего выступления на конференции HighLoad++ 2021:
Конференция Highload++ Foundation пройдет 17 и 18 марта в Москве, в Крокус-Экспо. Описание докладов и раписание уже готовы. Билеты можно купить на сайте.
А сейчас идет открытое голосование по Open Source трибуне, где определятся 5 лучших решений. Отдайте свой голос за то, что вам нравится и помогите определить лучших!
