
Привет! Меня зовут Олег, и я работаю в Skyeng. Мы с командой разрабатываем ядро образовательной платформы, на которой проходят все онлайн‑уроки, решаются домашки, экзамены и контрольные.
Раньше на IT‑собеседованиях мне задавали один и тот же вопрос:
— Расскажи о крупнейшем фейле в твоей карьере?
Не уверен, что ответ может много рассказать о кандидате, но цель моей статьи прозрачна: поделиться опытом, чтобы предотвратить подобные инциденты в будущем.
Почему фейл крупнейший?
Я отношу упавший сервер к highload. Посудите сами:
~500 RPS;
~0,5 млрд записей в одной таблице БД;
~3 ТБ на всю БД.
Skyeng проводит в среднем 3000+ уроков в час. На полтора часа основной сегмент нашего бизнеса отключился, и ученики не могли попасть на платформу. Это стоило компании дорого.
С чего все началось: аналитика и soft delete
Не секрет, что современный софт обвешан аналитикой — каждое действие пользователя обезличивается и логируется.
Типичные события в журнале аналитиков: пользователь открыл страницу, пользователь кликнул по кнопке и так далее. Это помогает понять, на какие кнопки кликают чаще других, а какие пора выкинуть за ненадобностью. Бизнес, в свою очередь, может делать выводы, какие фичи в приложении нравятся пользователям, а какие «не взлетели».
Аналитические отчеты строятся не только по журналу действий пользователя. Например, в качестве источника информации могут использоваться продуктовые базы данных — у нас это PostgreSQL.
С последней есть один нюанс: если данные из БД задействованы в аналитических отчетах, то банальное удаление (SQL DELETE) строки из таблицы может испортить этот самый отчет. Поэтому, с одной стороны, нужно уметь удалять данные из БД, а с другой стороны, удалять их нельзя, так как портится аналитика. Как быть?
Soft delete — это паттерн, при котором записи не удаляются, а остаются в БД навсегда с пометкой об удалении. То есть вместо SQL DELETE используется SQL UPDATE c deleted_at = now.
Как вы уже догадались, моей команде потребовалось внедрить soft delete для корректной работы отчетов аналитики.
Техническое ревью
Стек технологий на целевом сервисе: PHP 8.1, Symfony 5, PostgreSQL. Soft delete отсутствует, то есть при удалении записи из БД работает SQL DELETE. Находим готовое коробочное решение для Symfony и ее ORM Doctrine — расширение SoftDeleteable.
Это позволяет включить soft delete практически без изменения кода. Достаточно добавить в проект этот пакет через composer и включить мягкое удаление в конфигурации сущностей БД. Не забудем добавить в каждую нужную таблицу новую колонку deleted_at при помощи SQL ALTER TABLE.
На этом задача выполнена? Не совсем.
В БД миллиарды записей, и для ускорения SQL-запросов мы точечно применяем индексы. После внедрения soft delete имеющиеся уникальные индексы будут мешать текущей логике, и вот почему.
Пусть есть составной уникальный индекс на две колонки: user_id и resource_id.
Рассмотрим сценарий:
Добавляем запись с
user_id = 100иresource_id = 10.Удаляем эту запись, помня про soft delete: записываем текущее время в
deleted_at. Сервис больше не видит удаленную запись, но в БД она есть.
Логика нашего приложения допускает повторную вставку записи после ее удаления. Но после внедрения soft delete мы больше не сможем вставить в БД запись с такой же парой (user_id и resource_id) из-за нарушения уникальности — БД выдаст ошибку.
На помощь приходит фича PostgreSQL — partial index. Это такой индекс, который накладывается не на все записи БД, а только на ту часть, которая подходит по предикату. В нашем случае partial index накладывается на записи, у которых
deleted_at IS NULL(это и есть предикат). Таким образом, partial index игнорирует все записи, помеченные удаленными.
Это выглядит как идеальное решение в текущей ситуации. Как только запись помечается удаленной через deleted_at, она тут же автоматически исключается из частичного уникального индекса. То есть запись, помеченная как удаленная, теперь не видна сервису и partial уникальному индексу. Поэтому повторная вставка записи с теми же значениями будет работать без проблем.
Следующий вопрос: что делать с уже имеющимися в БД старыми, не partial индексами?
Очевидно, старые уникальные индексы нужно аккуратно удалить и создать новые аналогичные partial уникальные индексы.
Удаление индекса даже на большой БД выполняется за секунды. Но создание индекса может занимать целый час на штуку, а у нас таких индексов целых 5! Если сначала удалим старые уникальные индексы, а потом начнем создавать новые — получим окно в несколько часов, когда сервис будет работать под обычной нагрузкой, но без индексов. Это автоматически приведет к падению сервиса и, как следствие, всей школы Skyeng. Мы это предвидим и так делать не будем.
Следовательно, сначала в фоне создаем новые индексы, и только после этого удаляем старые. Сразу замечаем, что SQL-запросы на удаление старых и создание новых индексов будем делать руками в продуктовой БД, так как в CI/CD подобные часовые операции не пройдут из-за лимита времени на деплой.
Наш итоговый план релиза (не делайте так!):
Добавить колонку в таблицу
deleted_atсdefault NULL(деплой миграции).Создать новый уникальный partial index (руками, закладываем 5 часов).
Удалить старый уникальный индекс (руками).
Включить soft delete в код (установить Doctrine-расширения, включить soft delete в конфигах, зафиксировать новую структуру БД через миграции).
Релиз: день 1
Первые два пункта выглядят достаточно безопасно. Они занимают больше всего времени из-за многочасового создания новых partial индексов, поэтому мы решили разделить релиз на два дня.
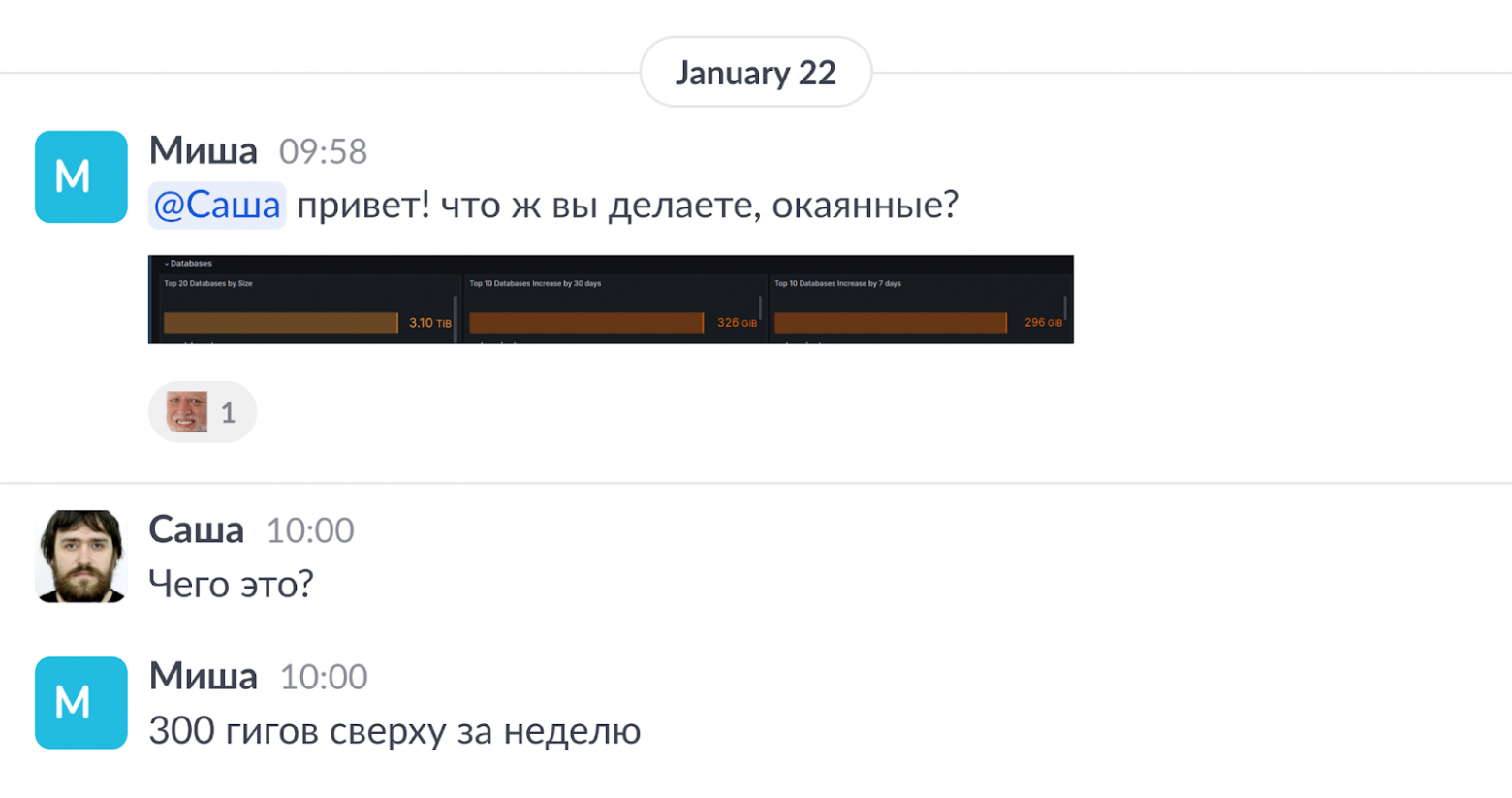
Как и ожидалось, первый этап прошел гладко, если не считать алерта от Миши из команды инфраструктуры — расходы файлового хранилища резко выросли:

Релиз: день 2. Как развивался инцидент
Итак, настает день икс. В очередное деплойное окно релиз продолжается.
В 12:10 я запускаю SQL-команды на удаление старых уникальных индексов в продовой БД согласно плану. Ничто не предвещает проблем с удалением старых индексов, ведь новые partial индексы уже есть, и они готовы к работе!
В 12:17 все старые индексы удалены. Судя по графику размера БД, полегчало:

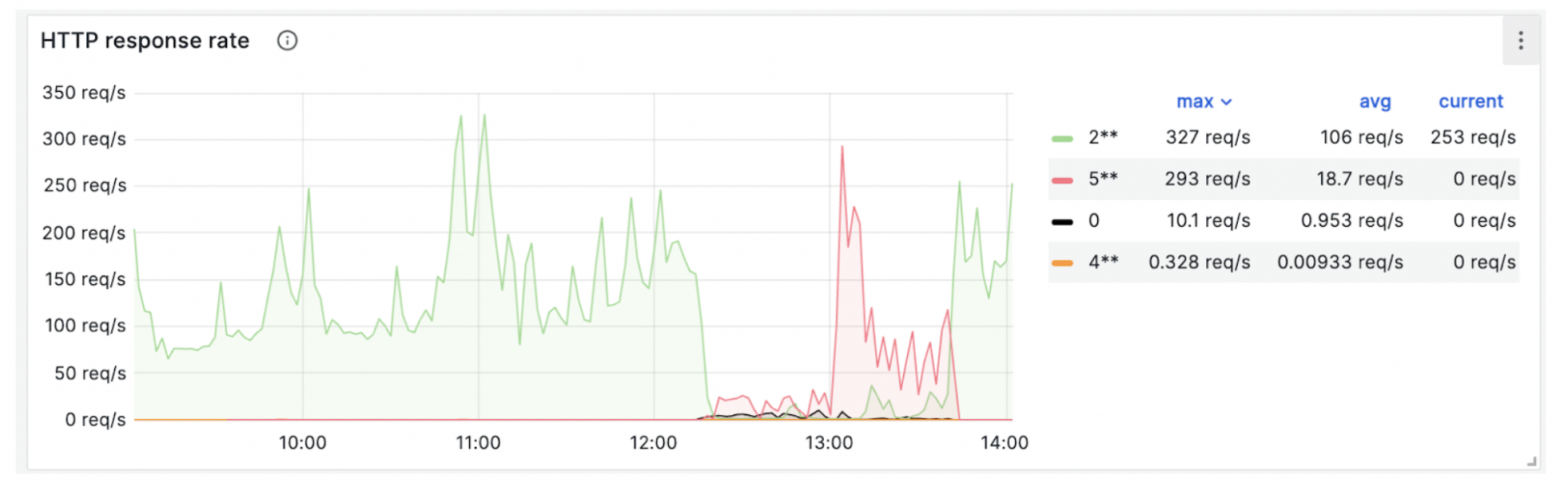
Однако уже в 12:20 начали массово поступать жалобы от клиентов. Я посмотрел в мониторинг сервиса и понял, что прод упал.
Мониторинг HTTP-ответов от сервиса показывает резкий скачок — 500 ошибок. Забились коннекты к БД, судя по загрузке CPU и RAM, что-то идет не так.
Обычная практика в подобных случаях — hotfix или откат деплоя (rollback). Второе проще, но в данной ситуации быстро вернуть все как было не получится — откатывать нечего. Мы удалили старые индексы вручную, и чтобы их вернуть, нужно вручную запустить SQL-команду и ждать 5 часов — это явно не выход.
Откатить нельзя, фиксить (запятая поставлена правильно)
К счастью, в инцидент оперативно вмешался Саша — мой тимлид. Он быстро и трезво оценил, что новые индексы есть, но они не работают. Как такое может быть?
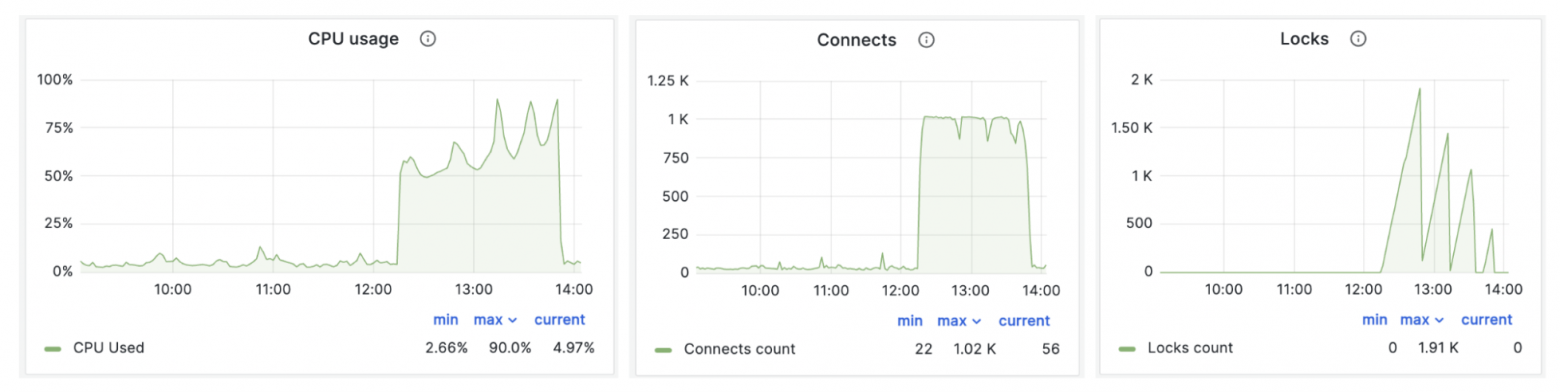

Старых индексов уже нет. Новые partial индексы есть, но код на сервере старый → старый код не использует новые индексы при поисковых запросах → SQL-запросы выполняются очень долго. Коннекты БД и очередь запросов забились → сервис упал под нагрузкой.
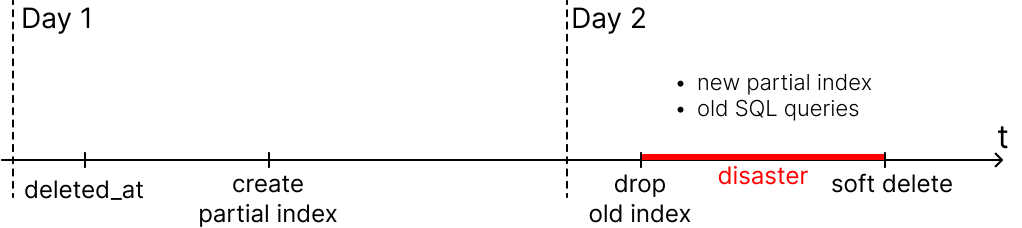
Изначально я не учел ключевую деталь: partial index работает, только когда SQL-запрос в коде содержит предикат, аналогичный предикату partial индекса (предикат тут — это то, что идет после WHERE).
Проще говоря:
Такой запрос не использует partial index:
SELECT * FROM exercise WHERE user_id = <user_id> AND resource_id = <resource_id>
Правильный запрос, чтобы использовался partial index:
SELECT * FROM exercise WHERE user_id = <user_id> AND resource_id = <resource_id> AND deleted_at IS NULL
Ясно, что в конечной точке деплоя все стало в порядке. Но в окне между 3-м и 4-м пунктами мы получили дизастер.
К сожалению, завершить деплой получилось лишь в 13:30. В GitLab-воркерах скопилась очередь билдов, и мой деплой ждал, пока не освободится воркер. Плюс дал свою задержку канареечный деплой.
В данном случае можно было катить с выключенной канарейкой. Когда деплой завершился, потребовалось еще рестартнуть memcached — после этого ситуация стала приходить в норму.
Инцидент завершился в 13:52.
План, исключающий падение прода
Добавить колонку в таблицу
deleted_atсdefault NULL(деплой миграции).Создать новый уникальный partial index руками. Закладываем 5 часов.
Включить soft delete в коде: установить Doctrine расширения, включить soft delete в конфигах, зафиксировать новую структуру БД через миграции.
Удалить старый уникальный индекс.

Такой вариант релиза предотвратит падение прода, но есть один интересный момент.
Дело в том, что до завершения релиза (пункт 4) в БД живет старый уникальный индекс. Поэтому в окне между 3-м и 4-м пунктами нас потенциально ждут ошибки 5xx, если кто-то сделает удаление при помощи soft delete, а потом попробует добавить новую запись с теми же данными. Старый уникальный индекс не даст этого сделать, пока не будет удален. При RPS близком к 1000 даже за минуту вы поймаете несколько ошибок.
Но есть более правильный вариант, к которому мы пришли вместе с разработчиком из соседней команды — она тоже недавно прокололась на таком кейсе.
План бесшовного релиза
Когда новый код с soft delete на проде, старый уникальный индекс нужно удалить. Иначе он не даст добавить новые записи, аналогичные удаленным с помощью soft delete. C другой стороны, нельзя удалять старый уникальный индекс, пока работает старый код.
Нам пришла идея: вместе с новым partial индексом создать временный поисковый индекс — аналогичный старому, но без ограничения уникальности.

Добавить колонку в таблицу
deleted_atсdefault NULL— деплой миграции.Создать новый уникальный partial index руками, закладываем на это 5 часов.
Создать временный индекс, идентичный старому, но без ограничения уникальности. Тоже выполняем руками, закладываем 5 часов.
Удалить старый уникальный индекс.
Включить soft delete в коде: установить Doctrine-расширение, включить soft delete в конфигах, зафиксировать новую структуру БД через миграции.
Удалить временный неуникальный индекс.
В этом случае в любой момент релиза поисковые запросы будут работать быстро, и мы не получим проблем со вставкой новых записей.
Минусы такого варианта:
Удваивается время релиза из-за создания дополнительного временного неуникального индекса.
Временно удваивается размер хранилища БД.
Итоги
Плохо, что такой кейс случился. Хорошо, что мы установили причины, все исправили и смогли поделиться результатами. Это поможет предотвратить подобные инциденты не только в Skyeng, но и, надеюсь, у всех, кто дочитал статью до конца!
Кстати, коллеги с пониманием отнеслись к произошедшему. Ведь практически у каждого разработчика есть в запасе подобная история. Поспрашивайте друг у друга в перерыве!
Ну и, конечно, не корите себя за ошибки. Как говорят мудрецы:

Спасибо за внимание. Жду ваших вопросов в комментариях, хорошего дня!
