
Мониторинг стал весьма важным компонентом растущих облачных решений с ростом сложности распределенных систем. Он необходим для понимания их поведения. Нужны масштабируемые инструменты, которые смогут собрать данные со всех сервисов — и предоставить специалистам единый интерфейс с анализом производительности, демонстрацией ошибок, доступностью и журналами.
Эти же инструменты должны быть эффективными и производительными. В этой статье мы рассмотрим два популярных стека технологий: EFK (Elasticsearch) и PLG (Loki) и разберём их архитектуры и различия.
Стек EFK
Возможно, вы уже слышали о весьма популярном ELK или EFK. Стек состоит из нескольких отдельных частей: Elasticsearch (объектное хранилище), Logstash или FluentD (сбор и агрегация журналов) и Kibana для визуализации.
Типичная схема работы выглядит так:

Elasticsearch — распределенное объектное хранилище с поиском и аналитикой в реальном времени. Превосходное решение для частично структурированных данных, например журналов. Информация сохраняется в виде документов JSON, индексируется в режиме реального времени и распределяется по узлам кластера. Применяется инвертированный индекс, содержащий все уникальные слова и связанные с ними документы для полнотекствого поиска, который в свою очередь основан на поисковом движке Apache Lucene.
FluentD — это сборщик данных, выполняющий унификацию данных при их сборе и потреблении. Он старается упорядочить данные в JSON насколько это возможно. Его архитектура расширяема, существует более сотни различных расширений, поддерживаемых сообществом, на все случаи жизни.
Kibana — средство визуализации данных для Elasticsearch с различными дополнительными возможностями, например, анализом временных рядов, графов, машинным обучением и прочим.
Архитектура Elasticsearch
Данные кластера Elasticsearch хранятся размазанными по всем его узлам. Кластер состоит из нескольких узлов для улучшения доступности и устойчивости. Любой узел может выполнять все роли кластера, но в крупных масштабируемых развертываниях узлам обычно назначают отдельные задачи.
Типы узлов кластера:
- мaster node — управляет кластером, нужно минимум три, одна активна всегда;
- data node — хранит индексированные данные и осуществляет с ними разные задачи;
- ingest node — организует конвейеры для преобразования данных перед индексацией;
- coordinating node — маршрутизация запросов, сокращение фазы обработки поиска, координация массовой индексации;
- alerting node — запуск задач по оповещению;
- machine learning node — обработка задач машинного обучения.
На диаграмме ниже показано, как данные сохраняются и реплицируются по узлам для достижения более высокой доступности данных.
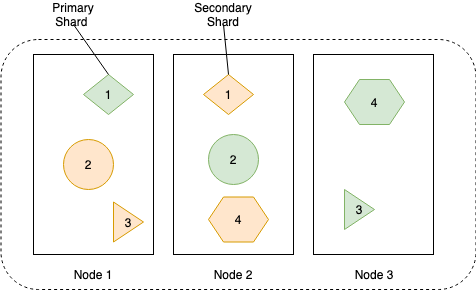
Данные каждой реплики хранятся в инвертированном индексе, схема ниже показывает, как это происходит:
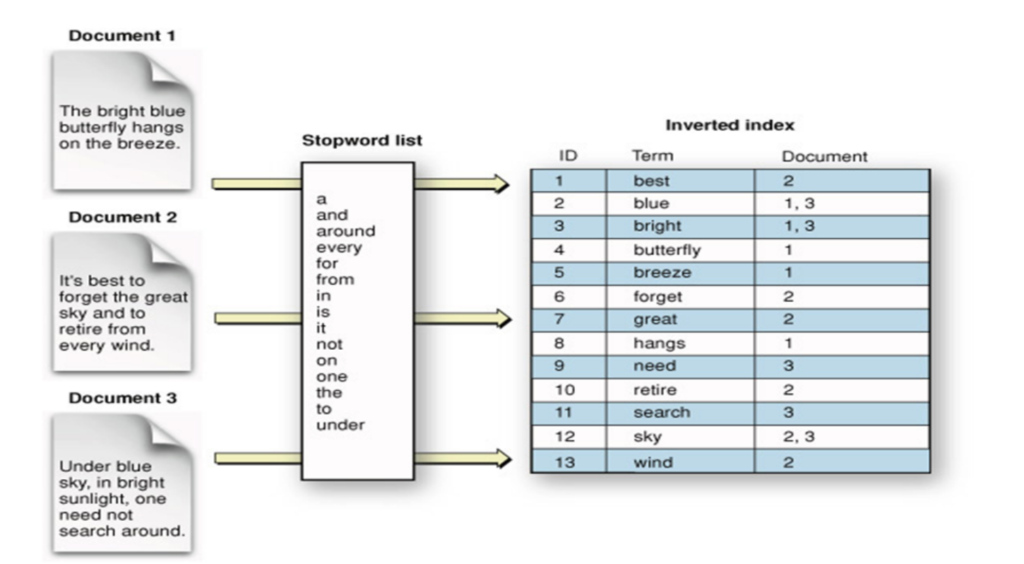
Установка
Детали можно посмотреть здесь, я буду использовать helm chart:
$ helm install efk-stack stable/elastic-stack --set logstash.enabled=false --set fluentd.enabled=true --set fluentd-elasticsearch.enabled=true Стек PLG
Не стоит удивляться, если не можете найти этот акроним, ведь его больше знают как Grafana Loki. В любом случае этот стек набирает популярность, поскольку применяет выверенные технические решения. Вы, возможно, уже слышали о Grafana, популярном инструменте для визуализации. Её создатели, вдохновляясь Prometheus, разработали Loki, горизонтально масштабируемую высокопроизводительную систему агрегации журналов. Loki индексирует только метаданные, но не сами журналы, это техническое решение позволило ему стать простым в эксплуатации и экономически выгодным.
Promtail — агент для отправки журналов из операционной системы в кластер Loki. Grafana — инструмент визуализации на основе данных из Loki.

Loki построен на тех же принципах, что и Prometheus, поэтому он хорошо подходит для хранения и анализа журналов Kubernetes.
Архитектура Loki
Loki может быть запущен как в режиме одного процесса, так и в виде нескольких процессов, что обеспечивает горизонтальное масштабирование.

Также он может работать, как в виде монолитного приложения, так и в виде микросервиса. Запуск в виде одного процесса может пригодиться для локальной разработки или же для мелкого мониторинга. Для промышленного внедрения и масштабируемой нагрузки рекомендуется применять микросервисный вариант. Пути записи и чтения данных разделены, так что его можно достаточно тонко настроить и масштабировать по необходимости.
Давайте посмотрим на архитектуру системы сбора журналов без детализации:
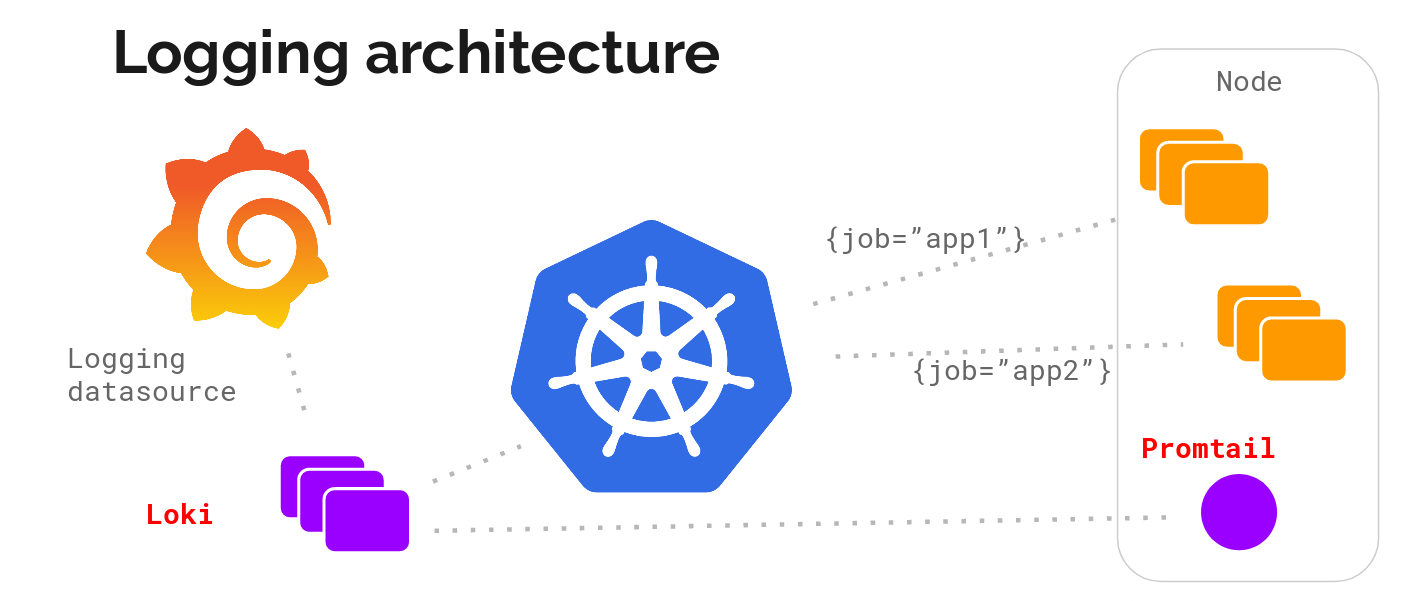
А здесь — описание (микросервисная архитектура):

Составные части:
Promtail — агент, устанавливаемый на узлы (в виде набора сервисов), он снимает журналы из задач и обращается к API Kubernetes для получения метаданных, которыми будут помечены журналы. Затем он отправляет журнал к основному сервису Loki. Для сопоставления метаданных поддерживаются те же правила для маркировки, что и в Prometheus.
Distributor — сервис-распределитель, работающий как буфер. Для обработки миллионов записей он производит упаковку входящих данных, сжимая их блоками по мере их поступления. Одновременно работает несколько приемников данных, но журналы, принадлежащие одному потоку входящих данных должны оказаться только в одном из них для всех его блоков. Это организовано в виде кольца приемников и последовательного хэширования. Для отказоустойчивости и избыточности оно делается n раз (3, если не настраивать).
Ingester — сервис-приемник. Блоки данных приходят сжатыми с добавленными журналами. Как только блок оказывается достаточного размера, производится сброс блока в базу данных. Метаданные идут в индекс, а данные от блока с журналом попадают в Chunks (обычно это объектное хранилище). После сброса приемник создает новый блок, куда будут добавляться новые записи.

Index — база данных, DynamoDB, Cassandra, Google BigTable и прочее.
Chunks — блоки журналов в сжатом виде, обычно хранятся в объектном хранилище, например, S3.
Querier — путь чтения, делающий всю черную работу. Он смотрит диапазон времени и метки, после чего смотрит индекс для поиска совпадений. Далее читает блоки данных и фильтрует их для получения результата.
А теперь давайте посмотрим все в работе.
Установка
Для установки в Kubernetes проще всего воспользоваться helm. Полагаем, что вы уже его поставили и настроили (и третьей версии! прим. переводчика)
Добавляем репозиторий и ставим стек.
$ helm repo add loki https://grafana.github.io/loki/charts
$ helm repo update
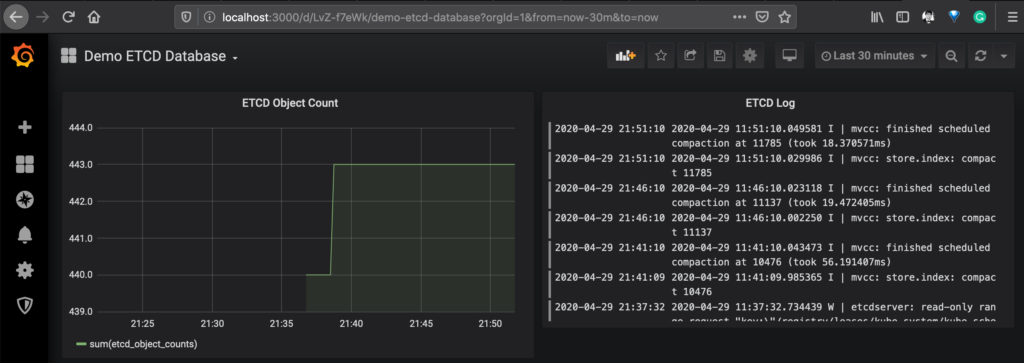
$ helm upgrade --install loki loki/loki-stack --set grafana.enabled=true,prometheus.enabled=true,prometheus.alertmanager.persistentVolume.enabled=false,prometheus.server.persistentVolume.enabled=falseНиже приведен пример панели инструментов, на которой показаны данные из Prometheus для метрик Etcd и Loki для журналов подов Etcd.
А теперь давайте обсудим архитектуру обеих систем, а также сравним их возможности между собой.
Сравнение
Язык запросов
В Elasticsearch используется Query DSL и Lucene query language, которые обеспечивают возможность полнотекстового поиска. Это устоявшийся мощный поисковой движок с широкой поддержкой операторов. С его помощью можно искать по контексту и сортировать по релевантности.
На другой стороне ринга — LogQL, применяемый в Loki, наследник PromQL (Prometheus query language). Он использует метки журналов для фильтрации и выборки данных журналов. Есть возможность использовать некоторые операторы и арифметику, как описано здесь, но по возможностям он отстает от Elastic language.
Поскольку запросы в Loki связаны с метками — их легко соотнести с метриками, в результате с ними проще организовать оперативный мониторинг.
Масштабируемость
Оба стека горизонтально масштабируемы, но с Loki это проще, поскольку у него разделены пути чтения и записи данных, а также у него микросервисная архитектура. Loki может быть настроен под ваши особенности и может быть использован под очень большие объемы данных журналов.
Мультиарендность
Мультиарендность кластера — общая тема для сокращения OPEX, оба стека обеспечивают мультиарендность. Для Elasticsearch есть несколько способов разделения клиентов: отдельный индекс каждому клиенту, маршрутизация на основе клиента, уникальные поля клиента, поисковые фильтры. В Loki есть поддержка в виде заголовка HTTP X-Scope-OrgID.
Стоимость
Loki весьма эффективен экономически из-за того, что он не делает индексацию данных, а только метаданных. Таким образом достигается экономия на хранилище и памяти (кэше), поскольку объектное хранилище дешевле блочного, которое используется в кластерах Elasticsearch.
Заключение
Стек EFK может использоваться для различных целей, обеспечивая максимальную гибкость и многофункциональный интерфейс Kibana для аналитики, визуализации и запросов. Он дополнительно может быть улучшен возможностями машинного обучения.
Стек Loki полезен в экосистеме Kubernetes из-за механизма обнаружения метаданных. Можно легко сопоставить данные для мониторинга на основе временных рядов в Grafana и журналах.
Когда речь идет о стоимости и длительном хранении журналов, Loki является отличным выбором для входа в облачные решения.
На рынке есть больше альтернатив — некоторые могут быть лучше для вас. Например, для GKE есть интеграция Stackdriver, которая обеспечивает отличное решение для мониторинга. Мы не включили их в наш анализ в этой статье.
Ссылки:
- https://github.com/grafana/loki/blob/master/docs/overview/comparisons.md
- https://www.elastic.co/blog/found-elasticsearch-from-the-bottom-up
- https://www.elastic.co/blog/found-elasticsearch-in-production/
Статья переведена и подготовлена для Хабра сотрудниками обучающего центра Слёрм — интенсивы, видеокурсы и корпоративное обучение от практикующих специалистов (Kubernetes, DevOps, Docker, Ansible, Ceph, SRE, Agile)

