Особенности работы внутренних механизмов PostgreSQL позволяют ему быть очень быстрым в одних ситуация и «не очень» в других. Сегодня остановимся на классическом примере конфликта между тем, как работает СУБД и тем, что делает с ней разработчик — UPDATE vs принципы MVCC.
Кратко сюжет из отличной статьи:

Но это произойдет далеко не сразу, а вот проблемы с «мертвецами» можно нажить очень быстро — при многократном или массовом обновлении записей в большой таблице, а чуть позже столкнуться с ситуацией, что и VACUUM не сможет помочь.
Допустим, ваш метод на бизнес-логике работает себе, и вдруг понимает, что надо бы обновить поле X в какой-то записи:
Потом, по ходу выполнения, выясняет, что поле Y надо бы обновить тоже:
… а потом еще и Z — чего уж мелочиться-то?
Сколько версий этой записи теперь имеем в базе? Ага, 4 штуки! Из них одна актуальная, а 3 должен будет прибрать за вами [auto]VACUUM.
Не надо так! Используйте обновление всех полей за один запрос — почти всегда логику работы метода можно так изменить:
Итак, вам все-таки захотелось обновить много-много записей в таблице (в ходе применения скрипта или конвертера, например). И в скрипт летит что-то такое:
Примерно в таком виде запрос встречается достаточно часто и почти всегда не для заполнения пустого нового поля, а для коррекции каких-то ошибок в данных. При этом сама корректность уже существующих данных вообще не учитывается — а зря! То есть запись переписывается, даже если там лежало ровно то, что и хотелось — а зачем? Поправим:
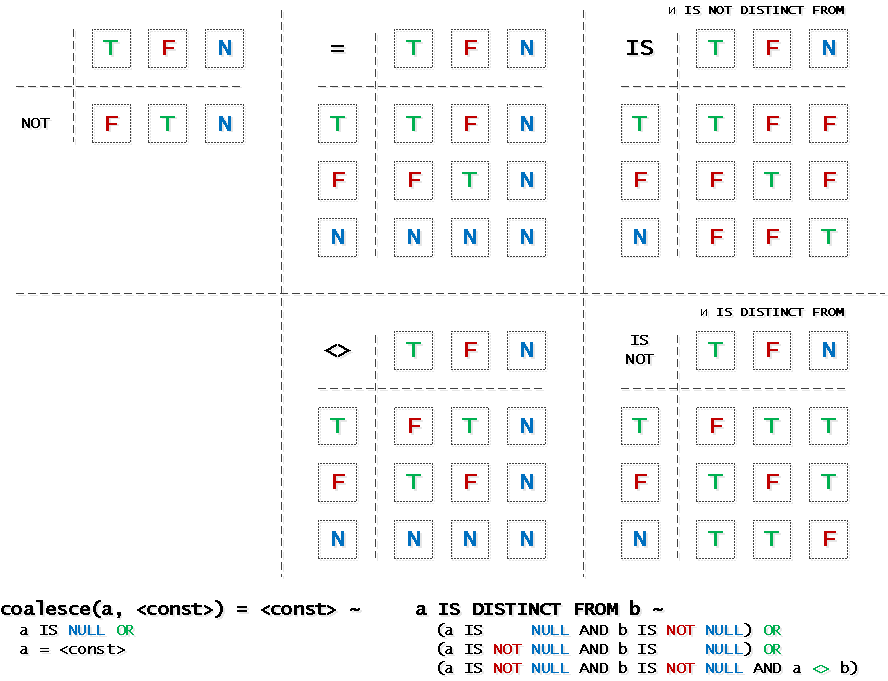
Многие не в курсе про существование такого замечательного оператора, поэтому вот шпаргалка по
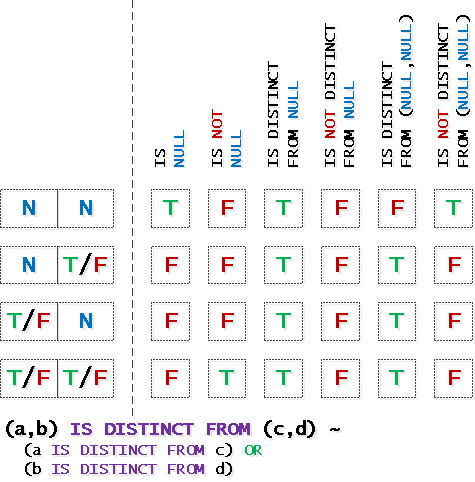
… и немного про операции над сложными
Запускаются два одинаковых параллельных процесса, каждый из которых пытается пометить на записи, что она находится «в работе»:
Даже если эти процессы предметно делают независимые друг от друга вещи, но в рамках одного ID, на этом запросе второй клиент «залочится», пока не закончится первая транзакция.
Решение №1: задача сведена к предыдущей
Просто снова добавим
В таком виде второй запрос просто ничего не будет менять в базе, там и так уже «все как надо» — поэтому и блокировка не возникнет. Дальше факт «ненахождения» записи уже обрабатываем в прикладном алгоритме.
Решение №2: advisory locks
Большая тема для отдельной статьи, в которой можно почитать про способы применений и «грабли» рекомендательных блокировок.
Решение №3: без[д]умные вызовы
А вот точно-точно у вас должна происходить одновременная работа с одной и той же записью? Или вы все-таки накосячили с алгоритмами вызовов бизнес-логики со стороны клиента, например? А если подумать?..
Кратко сюжет из отличной статьи:
Когда строка изменяется командой UPDATE, фактически выполняются две операции: DELETE и INSERT. В текущей версии строки устанавливается xmax, равный номеру транзакции, выполнившей UPDATE. Затем создается новая версия той же строки; значение xmin у нее совпадает с значением xmax предыдущей версии.Через какое-то время после завершения этой транзакции старая или новая версии, в зависимости от
COMMIT/ROOLBACK, будут признаны «мертвыми» (dead tuples) при проходе VACUUM по таблице и зачищены.Но это произойдет далеко не сразу, а вот проблемы с «мертвецами» можно нажить очень быстро — при многократном или массовом обновлении записей в большой таблице, а чуть позже столкнуться с ситуацией, что и VACUUM не сможет помочь.
#1: I Like To Move It
Допустим, ваш метод на бизнес-логике работает себе, и вдруг понимает, что надо бы обновить поле X в какой-то записи:
UPDATE tbl SET X = <newX> WHERE pk = $1;Потом, по ходу выполнения, выясняет, что поле Y надо бы обновить тоже:
UPDATE tbl SET Y = <newY> WHERE pk = $1;… а потом еще и Z — чего уж мелочиться-то?
UPDATE tbl SET Z = <newZ> WHERE pk = $1;Сколько версий этой записи теперь имеем в базе? Ага, 4 штуки! Из них одна актуальная, а 3 должен будет прибрать за вами [auto]VACUUM.
Не надо так! Используйте обновление всех полей за один запрос — почти всегда логику работы метода можно так изменить:
UPDATE tbl SET X = <newX>, Y = <newY>, Z = <newZ> WHERE pk = $1;#2: Use IS DISTINCT FROM, Luke!
Итак, вам все-таки захотелось обновить много-много записей в таблице (в ходе применения скрипта или конвертера, например). И в скрипт летит что-то такое:
UPDATE tbl SET X = <newX> WHERE pk BETWEEN $1 AND $2;Примерно в таком виде запрос встречается достаточно часто и почти всегда не для заполнения пустого нового поля, а для коррекции каких-то ошибок в данных. При этом сама корректность уже существующих данных вообще не учитывается — а зря! То есть запись переписывается, даже если там лежало ровно то, что и хотелось — а зачем? Поправим:
UPDATE tbl SET X = <newX> WHERE pk BETWEEN $1 AND $2 AND X IS DISTINCT FROM <newX>;Многие не в курсе про существование такого замечательного оператора, поэтому вот шпаргалка по
IS DISTINCT FROM и другим логическим операторам в помощь:… и немного про операции над сложными
ROW()-выражениями:#3: А я милого узнаю по… блокировке
Запускаются два одинаковых параллельных процесса, каждый из которых пытается пометить на записи, что она находится «в работе»:
UPDATE tbl SET processing = TRUE WHERE pk = $1;Даже если эти процессы предметно делают независимые друг от друга вещи, но в рамках одного ID, на этом запросе второй клиент «залочится», пока не закончится первая транзакция.
Решение №1: задача сведена к предыдущей
Просто снова добавим
IS DISTINCT FROM:UPDATE tbl SET processing = TRUE WHERE pk = $1 AND processing IS DISTINCT FROM TRUE;В таком виде второй запрос просто ничего не будет менять в базе, там и так уже «все как надо» — поэтому и блокировка не возникнет. Дальше факт «ненахождения» записи уже обрабатываем в прикладном алгоритме.
Решение №2: advisory locks
Большая тема для отдельной статьи, в которой можно почитать про способы применений и «грабли» рекомендательных блокировок.
Решение №3: без[д]умные вызовы
А вот точно-точно у вас должна происходить одновременная работа с одной и той же записью? Или вы все-таки накосячили с алгоритмами вызовов бизнес-логики со стороны клиента, например? А если подумать?..

