Доброго дня, коллеги!

Сегодня я расскажу вам о том, как не внося большого количества изменений в приложение улучшить его быстродействие. Речь пойдет о нашем небольшом «велосипеде» [1], призванном заменить memcache в некоторых случаях.
Статья написана по моему докладу «Кругом обман или использование стандартных протоколов для нестандартных вещей» [2] на DevConf'12.
Введение
Недавно мы уже рассказывали об архитектуре сети мобильной рекламы Plus1 WapStart. Если вы не читали, можете ознакомиться по ссылке.
Мы постоянно занимаемся мониторингом «узких» мест в нашем приложении. И в один прекрасный момент для нас таким узким местом стала логика подбора баннера. Дело осложнялось тем, что за годы существования приложения наш код оброс большим количеством слабо документированной бизнес-логики. И, как вы понимаете, переписывать с нуля не представлялось возможным по очевидным причинам.
Логику подбора баннера можно разбить на 3 этапа:
- Определение характеристик запроса.
- Подбор подходящих под запрос баннеров.
- Отсечки во время выполнения.
Проблемным для нас оказался этап под номером 1. Причем беда пришла откуда не ждали — из
Индии.
Индия здесь рассматривается по той причине, что для нас она является редким траффиком и был реальный бизнес-кейз, когда Индия к нам пришла
Обычно все данные, необходимые для определения характеристик запроса у нас есть в кеше и лишь небольшой процент запросов приходится на базу.

Но в случае, когда к нам приходит Индия, в кеше у нас практически ничего нет и 70-90% запросов уходит в базу. Это доставляет определенные проблемы и мы отдаем баннер чуть медленнее, чем хотелось бы.
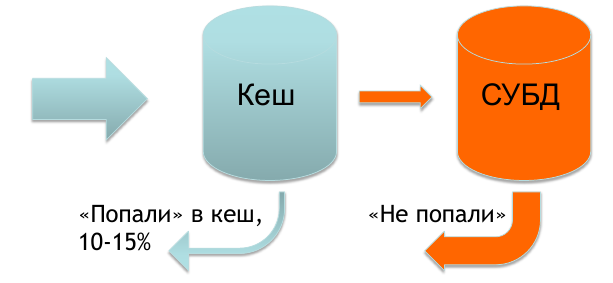
И тут нам пришла идея, как можно решить проблему скорости отдачи баннера.
Проект «Рыба»: идея

Идею можно выразить достаточно просто: мы всегда должны отвечать из памяти. Пришел запрос, опрашиваем хранилище на наличие данных, если данные есть — сразу отдаем ответ. В противном случае добавляем данные запроса в очередь на наполнение и отвечаем пустым ответом, не дожидаясь пока данные появятся.
В силу того, что для кеширования мы используем memcache, было решено использовать его протокол для реализации обозначенной идеи.
Проект «Рыба»: итерация первая
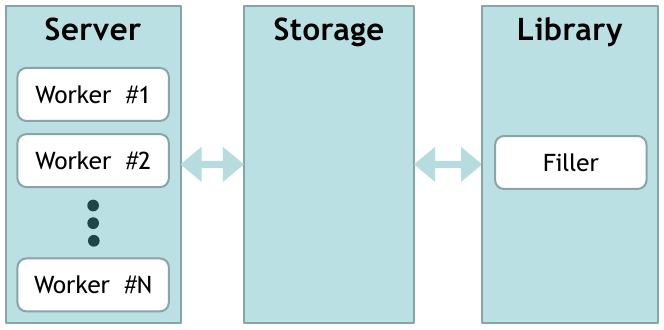
Реализация достаточно стандартна. Есть набор worker'ов, которые принимают соединения (их количество конфигурируется). Worker'ы обращаются к хранилищу за получением данных. Хранилище отдает ответ. В случае, когда данных нет, мы добавляем запрос в очередь. Кроме того, существует отдельный поток наполнения, который берет запросы из очереди и просит предоставить данные о них у библиотеки. Полученные данные добавляются в хранилище.
Библиотека может быть любая. В нашем случае она запрашивает данные из БД.
Логику приложения мы изменили таким образом, чтобы характеристики запроса брались из нашего кеша (из запроса формируется ключ и мы просим get key_with_request_characteristics). В данной конфигурации все работало отлично за исключением нескольких проблем.
Проблемы и их решение
Во-первых, мы столкнулись с проблемой удаления данных. При достижении лимита на выделенную память, хранилище начинало чиститься. Просматривались все существующие данные, проверялся TTL и, при необходимости, данные удалялись. В этот момент происходили задержки с ответом в силу того, что удаление — операция блокирующая. Решили мы ее достаточно просто: ввели лимиты на размер удаляемых данных. Варьируя данный параметр, мы смогли минимизировать потери в скорости на момент очистки.
Второй проблемой стало наличие в хранилище большого количества дублированных данных (слегка отличающимся запросам могут соответствовать одни и те же характеристики). Вот для ее решения мы и придумали следующее улучшение.
Проект «Рыба»: итерация вторая

В целом картина осталась прежней, за исключением двух функциональных единиц, которые мы добавили в библиотеку.
Первое — это Normalizer. Все запросы мы нормализуем (приводим к стандартному виду). И в хранилище ищем данные уже по нормализованному ключу.
Как я уже писал выше, из запроса формируется ключ. Ключ этот составной. Для себя мы решили сортировать части этого ключа в лексикографическом порядке.
Второе — это Hasher. Он служит для сравнения данных. Теперь мы не добавляем одни и те же данные в хранилище дважды.
Если раньше мы хранили пару ключ-значение, то сейчас мы храним ключи и данные отдельно. Между ключами и данными существует связь один-ко-многим (одни данные могут соответствовать множеству ключей).
И опять все вроде бы хорошо, но мы снова столкнулись с проблемой удаления данных.
Проблемы и их решение
Удаление производится по следующему алгоритму. Мы ищем среди ключей те, что уже устарели и удаляем их. Затем проверяем данные, если существуют такие, для которых не осталось ключей — мы их удаляем.
В силу специфики у нас получается большое количество маленьких ключей. Чтоб их все проверить (даже до установленного лимита на удаление) уходит много времени (для нас и нескольких десятых секунды много).
Решение тут как мне кажется, вполне очевидно. Мы добавили индекс на время добавления ключа. Если необходимо удалить данные, мы обходим ключи по данному индексу и удаляем до лимита, тем самым минимизирую расход времени.
Помимо проблемы удаления еще существует «проблема первого запроса» — мы отвечаем пустым запросом, когда данных нет. Она есть с первой версии, но для нас это допустимо и в ближайшее время решать ее мы не планируем.
Заключение
Для нас, ввод в бой «рыбки» позволил минимизировать затраты на переписывание кода. Логика приложения практически не изменилась, мы просто стали опрашивать другой кеш. И теперь в случае редких запросов, мы отвечаем быстро и уверенно.
Это конечно не последняя реализация (можно считать это альфой), мы работаем над повышением производительности и смежными задачами. Но уже сейчас код можно посмотреть на GitHub [3]. Проект получил название swordfishd [1]. Там же можно найти другие наши продукты отданные на растерзание в open-source.
