Введение
Сегодня мы поговорим о Pingora, новом HTTP-прокси, который мы создали у себя внутри с помощью Rust. Прокси обслуживает более 1 триллиона запросов в день, форсирует производительность и предоставляет множество новых функций для клиентов Cloudflare, при этом требуя всего лишь треть ресурсов CPU и памяти нашей предыдущей прокси-инфраструктуры.
По мере масштабирования Cloudflare мы выросли из NGINX. Он был отличным инструментом в течение многих лет, но со временем его ограничения в нашем масштабе добавляли все более смысла сделать что-то новое. Мы больше не могли получить необходимую нам производительность, а NGINX не обладал функциями, необходимыми для нашей очень сложной среды.
Многие клиенты и пользователи Cloudflare используют нашу глобальную сеть в качестве прокси-сервера между HTTP-клиентами (такими как веб-браузеры, приложения, устройства IoT и т. д.) и серверами. В прошлом мы много говорили о том, как браузеры и другие пользовательские агенты подключаются к нашей сети, мы разработали множество технологий и внедрили новые протоколы (см. QUIC и оптимизация для http2), чтобы сделать эту часть соединения более эффективной.
Сегодня мы сосредоточимся на другой части уравнения: службе, которая проксирует трафик между нашей сетью и серверами в Интернете. Этот прокси-сервис поддерживает наши CDN, Workers fetch, Tunnel, Stream, R2 и многие, многие другие функции и продукты.
Зачем создавать еще один прокси
С годами наше использование NGINX столкнулось с ограничениями. Часть мы оптимизировали или обошли, но остальное было крайне тяжело преодолеть.
Ограничения архитектуры бьют по производительности
Архитектура worker процессов NGINX не самая подходящая для наших сценариев использования, из-за чего страдает производительность и эффективность.
Во-первых, в NGINX каждый запрос может быть обработан только одним worker. Это выливается в несбалансированную нагрузку по всем ядрам CPU, что ведет к внезапным всплескам сетевых задержек.
Благодаря этому "привязыванию" к процессу, запросы, которые нагружают CPU или блокируют IO, тормозят остальные запросы. Как видно из приведенных ссылок на блог, мы потратили очень много времени, чтобы как-то с этим разобраться.
Но самая критичная проблема для нашего использования это неоптимальное переиспользование TCP соединений. Наше оборудование подключается к серверам-источникам (origin) для проксирования HTTP запросов. Переиспользование уже установленных соединений из пула ускоряет TTFB (time-to-first-byte, время до первого байта), благодаря пропуску TCP и TLS рукопожатий, требуемые для нового подключения.
Однако в NGINX пул соединений у каждого worker процесса отдельно. Когда запрос приземляется на один из процессов, он может переиспользовать соединения только из пула соединений этого процесса. Когда мы увеличиваем количество NGINX worker для масштабирования, количество повторно использованных соединений наоборот уменьшается из-за того, что соединения разбросаны по процессам.
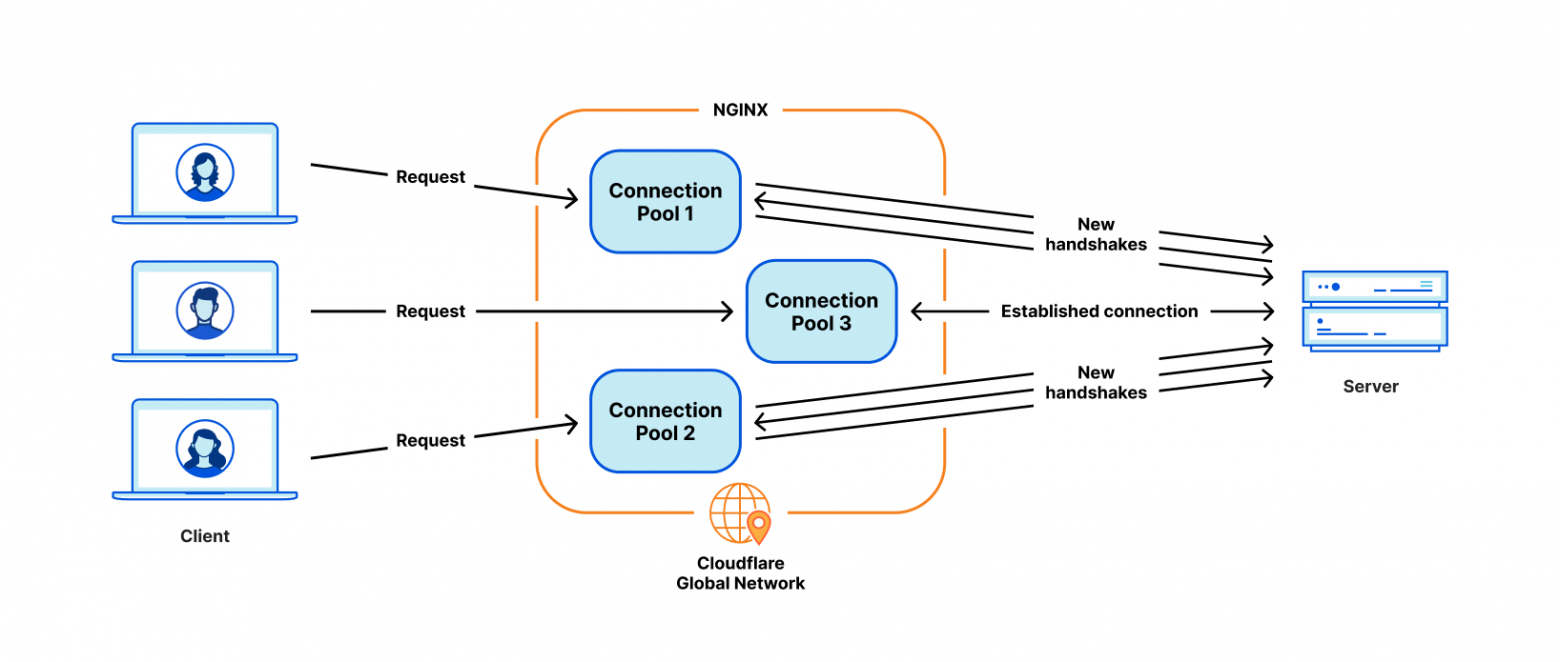
Как уже было отмечено ранее, у нас есть обходные пути для решения этих проблем. Но если разобраться с первопричиной — архитектурой модель worker/процесс — все эти проблемы уйдут естественным образом.
Типы функциональности, которые сложно добавить
NGINX очень хорош как web-сервер, load-balancer или как простой шлюз. Но Cloudflare делает гораздо больше, чем это. Мы привыкли строить весь нужный функционал вокруг NGINX, что на самом деле не так просто, если стараться не уходить слишком далеко от основной кодовой базы сервера.
Например, при повторной отправке отвалившегося запроса, мы иногда хотим перенаправить его на другой origin сервер с другим набором заголовков, чего NGINX нам не позволяет. В этом, и других подобных случаях, мы тратим время и силы на поиск и обход этих ограничений.
При этом, языки программирования, на которых нам приходится работать, не помогают нам с этими трудностями. NGINX полностью написан на C, который небезопасен при работе с памятью по определению, и работа с такой 3rd-party кодовой базой — источник множества проблем. Даже опытные инженеры совершают ошибки в работе с памятью, и мы хотим избежать этого настолько, насколько можно.
Другим языком, дополняющим C является Lua. Он менее рискованный, но в том же время менее производительный. Кроме того, нам часто не хватало статической типизации при работе со сложным кодом Lua и бизнес-логикой.
И сообщество NGINX не очень активно, и разработка склонна вестись за "закрытыми дверями".
Решаем построить свое
В течении нескольких лет, наращивая нашу клиентскую базу и набор фичей, мы постоянно оценивали три варианта:
Продолжаем инвестировать в NGINX и, возможно, форкнуть его, чтобы он на 100% соответствовал нашим нуждам. У нас был необходимый опыт, но, учитывая упомянутые выше ограничения архитектуры, потребовались бы значительные усилия, чтобы перестроить ее так, чтобы она полностью соответствовала нашим потребностям.
Мигрировать на другой 3rd-party прокси. Безусловно, есть хорошие проекты, такие как envoy и другие. Но этот путь означал бы, что тот же цикл может повториться через несколько лет.
Начать с чистого листа, создав внутреннюю платформу и фреймворк. Этот выбор требует самых больших первоначальных инвестиций (с точки зрения инженерных усилий).
Каждый из этих вариантов мы оценивали ежеквартально в течение последних нескольких лет. Нет никакой очевидной формулы, которая бы сказала, какой выбор лучше. Мы долго шли по пути наименьшего сопротивления, продолжая развивать NGINX. Однако в какой-то момент стало казаться, что создание собственного решения того стоит. Мы решили создать прокси-сервер с нуля и начали разрабатывать платформу своей мечты.
Проект Pingora
Архитектурные решения
Чтобы создать прокси, который обрабатывает миллионы запросов в секунду быстро, эффективно и безопасно, мы должны были принять несколько важных архитектурных решений.
Мы выбрали Rust как язык для платформы, потому что он может делать то же, что может C, но через безопасную работу с памятью, не жертвуя производите��ьностью.
Несмотря на наличие отличных готовых HTTP библиотек, таких как hyper, мы решили разрабатывать собственную, для максимальной гибкости в обработке HTTP трафика и чтобы быть уверенным, что мы можем привносить инновации в собственном ритме.
Мы в Cloudflare обрабатываем трафик со всего интернета. У нас множество случаев необычного и несовместимого с RFC HTTP трафика, который нам приходится поддерживать. Вообще говоря, это распространенная дилемма внутри HTTP сообщества и веба: строго поддерживать HTTP спецификации или приспосабливаться к нюансам широкой экосистемы потенциальных legacy клиентов или серверов. Выбор стороны тут — жесткое решение.
Статус-коды ответов HTTP определены в RFC 9110 как трехзначное число, и в целом ожидается, что оно будет в промежутке от 100 до 599. Однако много серверов поддерживают использование кодов между 599 и 999. На гитхабе библиотеки Hyper был создан тикет для поддержки этой фичи, в котором разгорелись дебаты сторонников разных подходов. В конечном итоге команда hyper приняла изменения, но у них были бы вполне обоснованные причины отказать в таком запросе. И это только один из многих случаев несовместимого поведения, которые мы должны поддерживать.
Чтобы удовлетворить требования Cloudflare в экосистеме HTTP, нам нужна была надежная, разрешительная (permissive), настраиваемая HTTP-библиотека, которая могла бы выжить в диких дебрях Интернета и поддерживать множество несовместимых сценариев использования. Лучший способ гарантировать это — реализовать свою собственную.
Следующим архитектурным решением был выбор подхода для распределения нагрузки. Мы выбрали multithreading вместо multiprocessing чтобы легко шарить ресурсы, особенно пулы соединений. Мы также решили, что нам необходим work stealing, чтобы избежать некоторые классы проблем, упомянутых выше. Асинхронный рантайм Tokio нам отлично подошел.
Наконец, мы хотели, чтобы наш проект был интуитивно понятным и удобным для разработчиков. То, что мы создаем, не является конечным продуктом, оно должно быть расширяемым как платформа, поскольку на его основе создается все больше функций. Мы решили реализовать программируемый интерфейс на основе «жизнь запроса» (life of a request), аналогичной NGINX/OpenResty. Например, фаза «фильтр запроса» (request filter) позволяет разработчикам запускать код для изменения или отклонения запроса при получении его заголовка. Благодаря этому подходы мы можем четко разделить нашу бизнес- и общую прокси логику. Разработчики, ранее работавшие с NGINX, могут легко переключиться на Pingora и начать продуктивно работать.
Pingora быстрее в продакшене
Переместимся в настоящее. Pingora уже обрабатывает почти каждый HTTP-запрос, который должен взаимодействовать с исходным сервером (например, для промаха кеша), и в процессе мы собрали много данных о производительности.
Для начала посмотрим, как Pingora ускоряет трафик наших клиентов. Общий трафик на Pingora показывает снижение медианного значения TTFB на 5 мс и снижение на 80 мс на 95-м перцентиле. Но это не потому, что мы выполняем код быстрее. Даже наш старый сервис мог обрабатывать запросы в диапазоне менее миллисекунды.
Экономия достигается за счет нашей новой архитектуры, которая может совместно использовать соединения для всех потоков. Это означает лучший коэффициент повторного использования соединения, который тратит меньше времени на рукопожатия TCP и TLS.

Pingora делает только треть новых подключений в секунду для всех клиентов по сравнению со старым сервисом. Для одного крупного клиента он увеличил коэффициент повторного использования соединений с 87,1% до 99,92%, что сократило количество новых подключений к их источникам в 160 раз. Чтобы представить результат более интуитивно, переходя на Pingora, мы экономим нашим клиентам и пользователям 434 года времени рукопожатий каждый день.
Больше возможностей
Наличие интерфейса, который удобен и с которым знакомы инженеры, при устранении предыдущих ограничений, позволяет нам быстрее внедрять новые фичи. Основные, такие как новые протоколы, служат строительными блоками для большего количества продуктов, которые мы можем предложить клиентам.
Например, мы смогли добавить в Pingora поддержку upstream потока HTTP/2 без особых препятствий. Вскоре после этого, мы смогли предложить gRPC нашим клиентам. Добавление такой же функциональности в NGINX потребовало бы значительно больших инженерных усилий и, возможно, не было бы реализовано.
Совсем недавно мы анонсировали Cache Reserve, в котором Pingora использует хранилище R2 в качестве уровня кэширования. То есть по мере расширения функциональности Pingora мы можем предлагать новые продукты, которые раньше были просто невозможны.
Более эффективно
В продакшене Pingora потребляет примерно на 70% меньше CPU и на 67% меньше памяти по сравнению с нашим старым сервисом с той же нагрузкой по трафику. Экономия достигается за счет нескольких факторов.
Наш код на Rust работает более эффективно по сравнению с нашим старым кодом на Lua. Кроме того, различия в производительности достигаются за счет разницы архитектуры. Например, в NGINX/OpenResty, когда код Lua хочет получить доступ к заголовку HTTP, он должен прочитать его из C-структуры NGINX, выделить строку Lua и затем скопировать ее в строку Lua. После этого Lua также должен выполнить сборку мусора для этой новой строки. В Pingora это будет просто прямой доступ к строке.
Многопоточная модель делает обмен данными между запросами более эффективным. NGINX также имеет разделяемую память (shared memory), но из-за ограничений реализации каждый доступ к разделяемой памяти должен использовать мьютекс-блокировку, и в разделяемую память можно помещать только строки и числа. В Pingora же к большинству общих элементов можно получить доступ напрямую через общие ссылки за ARC (атомарными счетчиками ссылок).
Другая значительная порция экономия CPU достигается, как было упомянуто ранее, за счет меньшего количество соединений. Рукопожатия TLS обходятся дорого по сравнению с простой отправкой/получением данных.
Более безопасно
Быстрое и безопасное внедрение новых фичей — это сложный процесс, особенно на нашем масштабе. Сложно спрогнозировать каждый острый угол, на который можно натолкнуться в распределенной среде, обрабатывающей миллионы запросов в секунду. Фаззинг и статический анализ могут только смягчить такие встречи. Безопасная для памяти семантика Rust защищает нас от неопределенного поведения и дает нам уверенность в том, что наш сервис будет работать правильно.
Эти гарантии позволяют нам больше сосредотачиваться на том, как изменение нашего сервиса взаимодействует с другими сервисами или серверами клиента. Мы можем внедрять новые функции гораздо чаще и не быть обремененными безопасностью памяти и трудно диагностируемыми сбоями.
Когда сбои все же происходят, инженеру нужно потратить время, чтобы разобраться, как это произошло и что было причиной. С момента создания Pingora мы обслужили несколько сотен триллионов запросов, и до сих пор не произошло сбоев из-за кода нашего сервиса.
Факт, но сбои Pingora настолько редки, что мы обычно обнаруживаем совсем несвязанные с сервисом причины, когда разбираемся с ними. Недавно мы обнаружили ошибку ядра вскоре после того, как наш сервис начал крашиться. Мы также обнаружили проблемы с оборудованием на нескольких машинах, что в прошлом, в случае редких проблем с памятью, было почти исключено, так как серьезная отладка была почти невозможна.
Выводы
Подводя итог, мы создали собственный прокси-сервер, который быстрее, эффективнее и универсальнее в качестве платформы для наших текущих и будущих продуктов.
Мы вернемся с более подробной технической информацией о проблемах, с которыми мы столкнулись, примененных оптимизациях и уроках, которые мы извлекли из создания Pingora и развертывания ее для обеспечения значительной части Интернета. Мы также вернемся с нашим планом по открытию исходного кода.
Pingora — наша последняя попытка переписать нашу систему, но не последняя. Кроме того, это лишь один из строительных блоков при реархитектуре наших систем.

