
Спектральный анализ сигналов нелинейных звеньев АСУ на Python
3 мин
Цель работы
В моей статье [1] рассмотрен метод гармонической линеаризации для исследования систем управления, содержащих нелинейные элементы.
Этот метод может быть использован в том случае, когда линейная часть системы является низкочастотным фильтром, т.е. отфильтровывает все возникающие на выходе нелинейного элемента гармонические составляющие, кроме первой гармоники [2]. Поэтому логическим продолжением моей первой статьи будет гармонический анализ рассмотренных нелинейных элементов. Кроме этого нужно рассмотреть аппаратную альтернативу методу гармонической линеаризации.
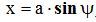 , где
, где  Преобразовав выходной сигнал в ряд Фурье только для первой гармоники. Получим:
Преобразовав выходной сигнал в ряд Фурье только для первой гармоники. Получим: 
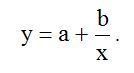 (1)
(1)