Что? Строки могут быть «грязными»?
Да, могут.
Вы думаете, в этом примере строка занимает 30 байт?
А вот и нет! Она занимает 30 мегабайт!
Дьявол кроется в деталях. В данном примере — это «какой-то код». Очевидно, какой-то код что-то делает, что строка занимает много памяти. И вроде бы это вас не касается, но лишь до тех пор, пока это не ваш собственный код. Возможно, в вашем коде уже сейчас много мест, где строки занимают в десятки раз больше, чем в них содержится.
Сразу хочу заметить, что этотбаг фича давно известна. Я не открыл ничего нового. Это особенность движка V8, которая позволяет ускорить работу со строками в ущерб, естественно, памяти. То есть это касается Google Chrome и прочих хромиум-браузеров, а также Node.js. Этого уже достаточно, чтобы отнестись серьёзно к этому явлению.
UPD4: Firefox это, видимо, тоже касается.
Сидите вы, значит, под пальмой за компьютером, пишете очередной AJAX на JavaScript, ни о чём не подозреваете, и у вас получается что-то вроде этого:
Написали, значит, проверили, опубликовали. Но вдруг оказывается, что сайт начинает жрать память. 200-300Мб — фигня, думаете вы, и уходите на пляж купаться, оставляя браузер открытым. Потом возвращаетесь, а ваш сайт уже 2 гигабайта! Вы удивляетесь, и сразу после этого Chrome крашится у вас на глазах.
Что-то здесь не так. Но код-то ведь простой! Вы начинаете искать утечку памяти в вашем коде и… не находите! А знаете почему? Да потому что её там нет! Вы не допустили ни одной ошибки. Однако проблема есть, заказчик будет недоволен, и решать всё равно придётся вам.
Без паники! Есть проблема — значит, решаем. Открываем профилировщик и видим, что там куча строк в памяти JS, которые там не должны быть. А именно — полностью загруженные страницы.
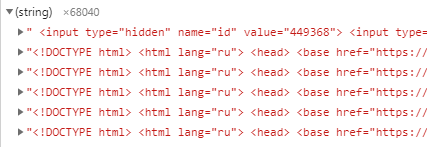
Смотрим дальше на Retainers.
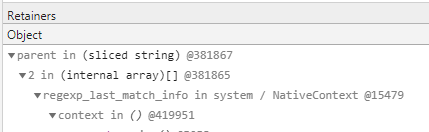
Что же такое sliced string?
В общем, оказывается, что строки содержат ссылки на родительские строки! Что??
Это вроде бы не сильно на что-то влияет, но только до тех пор, пока вы не захотите из огромной строки вырезать маленький кусочек и оставить себе, а большую строку удалить. Ведь она не удалится. Она останется в памяти, потому что на неё ссылается новая строка, которую вы где-то сохранили, поэтому сборщик мусора нехочет может освободить память.
Получается такая цепочка указателей:
какой-то массив или объект -> ваша новая маленькая строка -> старая большая строка
На самом деле всё ещё сложнее, у строки может быть несколько «родителей», но не будем усугублять.
Рабочий пример:
В этом примере мы каждую секунду увеличиваем память на 25 байт. Ой ли? Смотрим диспетчер задач и видим, как память быстро растёт. Ладно, просто GC (сборщик мусора) немного запаздывает, сейчас очухается и очистит. Но нет. Проходит несколько минут, память заполняется до предела, — и браузер крашится.
Ради чистоты эксперимента можно довести до 1.5 гига, остановить таймер и оставить вкладку сайта на ночь. GC типа сам решит, когда пора чистить память, ага. Главное, дождаться.
В качестве решения можно предложить лишь «очистку» строки от внешних зависимостей. Тогда эти внешние зависимости GC сможет спокойно удалить, как недостижимые.
Простейший кейс, когда мы точно знаем, что в строке число, либо нам нужно получить число:
Второй кейс — использование строки в качестве ключа объекта. Ключ, видимо, участвует в процессах хеширования, а для этого лучше полностью скопироваться и не иметь зависимостей:
На этом простые кейсы кончаются. В любом случае, очевидно, что строку нужно превратить в другой тип. Это не обязательно единственное решение, но это точно поможет. Пробуем:
Да, это работает, строка очищается.
Но можно немного улучшить решение. Если копнуть чуть глубже, то окажется, что V8 не оставляет ссылок у очень маленьких строк, меньше 13 символов. Видимо, такие маленькие строки проще скопировать целиком, чем ссылаться на область памяти в другой строке. Для Firefox это число 12. Воспользуемся этим:
Сложно сказать, изменится ли это число 13 в будущих версиях V8, и 12-24 в будущих версиях Firefox, но пока что так.
Конечно, нет. Это кэширование не просто так придумано. Оно реально ускоряет работу со строками. Просто иногда это выходит боком, как в примерах выше.
В качестве глобального фикса можно через прототипы заменить стандартные строковые фукнции, типа извлечения подстроки, но это замедлит их работу в десятки раз. Оно вам надо?
Лучшая стратегия такая. При анализе большой строки, вы обычно выделяете куски, потом из этих кусков выделяете более мелкие строки, потом их приводите в должный вид, всякие там replace(), trim() и т.п. И вот конечную маленькую строку, которая точно сохраняется в вечно-живой объект/массив, уже нужно чистить.
А чистка в самом начале просто не имеет смысла. Лишняя нагрузка на процессор.
UPD:
UPD2:
UPD3 Мой вывод:
Да, могут.
//.....Какой-то код console.log(typeof str); // string console.log(str.length); // 15 console.log(str); // "ччччччччччччччч"
Вы думаете, в этом примере строка занимает 30 байт?
А вот и нет! Она занимает 30 мегабайт!
Дьявол кроется в деталях. В данном примере — это «какой-то код». Очевидно, какой-то код что-то делает, что строка занимает много памяти. И вроде бы это вас не касается, но лишь до тех пор, пока это не ваш собственный код. Возможно, в вашем коде уже сейчас много мест, где строки занимают в десятки раз больше, чем в них содержится.
Предисловие
Сразу хочу заметить, что этот
UPD4: Firefox это, видимо, тоже касается.
Практичный пример
Сидите вы, значит, под пальмой за компьютером, пишете очередной AJAX на JavaScript, ни о чём не подозреваете, и у вас получается что-то вроде этого:
var news = []; function checkNews() { var xhr = new XMLHttpRequest(); xhr.open('GET', 'http://example.com/WarAndPeace', true); //Проверяем сайт xhr.onload = function() { if (this.status != 200) return; //Извлекаем новости var m = this.response.match(/<div class="news">(.*?)<.div>/); if (!m) return; var feed = m[1]; //Новость if (!news.find(e=>e==feed)) { //Свежая новость news.push(feed); document.getElementById('allnews').innerHTML += '<br>' + feed; } }; xhr.send(); } setInterval(checkNews, 55000);
Написали, значит, проверили, опубликовали. Но вдруг оказывается, что сайт начинает жрать память. 200-300Мб — фигня, думаете вы, и уходите на пляж купаться, оставляя браузер открытым. Потом возвращаетесь, а ваш сайт уже 2 гигабайта! Вы удивляетесь, и сразу после этого Chrome крашится у вас на глазах.
Что-то здесь не так. Но код-то ведь простой! Вы начинаете искать утечку памяти в вашем коде и… не находите! А знаете почему? Да потому что её там нет! Вы не допустили ни одной ошибки. Однако проблема есть, заказчик будет недоволен, и решать всё равно придётся вам.
Профилирование
Без паники! Есть проблема — значит, решаем. Открываем профилировщик и видим, что там куча строк в памяти JS, которые там не должны быть. А именно — полностью загруженные страницы.
Смотрим дальше на Retainers.
Что же такое sliced string?
Суть проблемы
В общем, оказывается, что строки содержат ссылки на родительские строки! Что??
Это вроде бы не сильно на что-то влияет, но только до тех пор, пока вы не захотите из огромной строки вырезать маленький кусочек и оставить себе, а большую строку удалить. Ведь она не удалится. Она останется в памяти, потому что на неё ссылается новая строка, которую вы где-то сохранили, поэтому сборщик мусора не
Получается такая цепочка указателей:
какой-то массив или объект -> ваша новая маленькая строка -> старая большая строка
На самом деле всё ещё сложнее, у строки может быть несколько «родителей», но не будем усугублять.
Рабочий пример:
function MemoryLeak() { let huge = "x".repeat(15).repeat(1024).repeat(1024); // 15МБ строка let small = huge.substr(0,25); //Маленький кусочек return small; } var arr = []; var t = setInterval(e=>{ //Каждую секунду добавляем 25 байт или 15 мегабайт? let str = MemoryLeak(); //str = clearString(str); console.log('Добавляем памяти:',str.length + ' байт'); arr.push(str); console.log('Текущая память страницы:',JSON.stringify(arr).length+' байт'); },1000); //clearInterval(t);
В этом примере мы каждую секунду увеличиваем память на 25 байт. Ой ли? Смотрим диспетчер задач и видим, как память быстро растёт. Ладно, просто GC (сборщик мусора) немного запаздывает, сейчас очухается и очистит. Но нет. Проходит несколько минут, память заполняется до предела, — и браузер крашится.
Ради чистоты эксперимента можно довести до 1.5 гига, остановить таймер и оставить вкладку сайта на ночь. GC типа сам решит, когда пора чистить память, ага. Главное, дождаться.
Решение
В качестве решения можно предложить лишь «очистку» строки от внешних зависимостей. Тогда эти внешние зависимости GC сможет спокойно удалить, как недостижимые.
Простейший кейс, когда мы точно знаем, что в строке число, либо нам нужно получить число:
str = str - 0;
Второй кейс — использование строки в качестве ключа объекта. Ключ, видимо, участвует в процессах хеширования, а для этого лучше полностью скопироваться и не иметь зависимостей:
obj[str] = 123; str = null; //или просто выйти за область видимости
На этом простые кейсы кончаются. В любом случае, очевидно, что строку нужно превратить в другой тип. Это не обязательно единственное решение, но это точно поможет. Пробуем:
function clearString(str) { return str.split('').join(''); }
Да, это работает, строка очищается.
//Уже понятно, как жить дальше. let m = big_data.match(/\sMY_OPTIONS_(\w+) = (\w+)\s/); if (m) obj[m[1]] = clearString(m[2]); //Как-то так.
Но можно немного улучшить решение. Если копнуть чуть глубже, то окажется, что V8 не оставляет ссылок у очень маленьких строк, меньше 13 символов. Видимо, такие маленькие строки проще скопировать целиком, чем ссылаться на область памяти в другой строке. Для Firefox это число 12. Воспользуемся этим:
function clearString(str) { return str.length < 12 ? str : str.split('').join(''); }
Сложно сказать, изменится ли это число 13 в будущих версиях V8, и 12-24 в будущих версиях Firefox, но пока что так.
Что же это выходит? Все строки надо чистить?!
Конечно, нет. Это кэширование не просто так придумано. Оно реально ускоряет работу со строками. Просто иногда это выходит боком, как в примерах выше.
В качестве глобального фикса можно через прототипы заменить стандартные строковые фукнции, типа извлечения подстроки, но это замедлит их работу в десятки раз. Оно вам надо?
Лучшая стратегия такая. При анализе большой строки, вы обычно выделяете куски, потом из этих кусков выделяете более мелкие строки, потом их приводите в должный вид, всякие там replace(), trim() и т.п. И вот конечную маленькую строку, которая точно сохраняется в вечно-живой объект/массив, уже нужно чистить.
nickname = clearString(nickname); //как-то так. long_live_obj.name = nickname; //уже чистая строка, всё ок.
А чистка в самом начале просто не имеет смысла. Лишняя нагрузка на процессор.
let cleared = clearString(xhr.response); //бред
Оптимальный способ очистки
Пробуем найти другие решения
function clearString(str) { return str.split('').join(''); } function clearString2(str) { return JSON.parse(JSON.stringify(str)); } function clearString3(str) { //Но остаётся ссылка на строку ' ' + str //То есть в итоге строка занимает чуть больше return (' ' + str).slice(1); } function Test(test_arr,fn) { let check1 = performance.now(); let a = []; //Мешаем оптимизатору. for(let i=0;i<1000000;i++){ a.push(fn(test_arr[i])); } let check2 = performance.now(); return check2-check1 || a.length; } var huge = "x".repeat(15).repeat(1024).repeat(1024); // 15Mb string var test_arr = []; for(let i=0;i<1000000;i++) { test_arr.push(huge.substr(i,25)); //Мешаем оптимизатору. } console.log(Test(test_arr,clearString)); console.log(Test(test_arr,clearString2)); console.log(Test(test_arr,clearString3));
Примерное время работы в Chrome 73
console.log(Test(test_arr,clearString)); //700мс console.log(Test(test_arr,clearString2)); //300мс console.log(Test(test_arr,clearString3)); //280мс
UPD:
Замеры в Opera и Firefox от @WanSpi
//Opera console.log(Test(test_arr,clearString)); // 868.5000000987202 console.log(Test(test_arr,stringCopy)); // 493.80000005476177 console.log(Test(test_arr,clearString2)); // 435.4999999050051 console.log(Test(test_arr,clearString3)); // 282.60000003501773
//Firefox (ради интереса, ведь ваш сайт предназначен для всех браузеров) console.log(Test(test_arr,clearString)); // 210 console.log(Test(test_arr,stringCopy)); // 2077 console.log(Test(test_arr,clearString2)); // 632 console.log(Test(test_arr,clearString3)); // 185
UPD2:
Замеры Node.js от @V1tol
function clearString4(str) { //Используем Buffer в Node.js //По-умолчанию используется 'utf-8' return Buffer.from(str).toString(); } Результат: //763.9701189994812 //clearString //567.9718199996278 //clearString2 //218.58974299952388 //clearString3 //704.1628979993984 // Buffer.from
UPD3 Мой вывод:
Абсолютный победитель
Существенно лучше никто не предложил. На строках 15 байт разница не большая, максимум в 2 раза. Но если увеличить строку до 150 байт, и тем более 1500 байт, разница гораздо больше. Это самый быстрый алгоритм.
Тесты: jsperf.com/sliced-string
function clearStringFast(str) { return str.length < 12 ? str : (' ' + str).slice(1); }
Существенно лучше никто не предложил. На строках 15 байт разница не большая, максимум в 2 раза. Но если увеличить строку до 150 байт, и тем более 1500 байт, разница гораздо больше. Это самый быстрый алгоритм.
Тесты: jsperf.com/sliced-string
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Чем вы пользуетесь для очистки строк?
89.99%Впервые слышу про такую утечку памяти. Интересно1420
2.85%Мне без разницы, сколько памяти жрёт мой сайт (или приложение)45
4.44%Мой сайт (приложение) слишком простой, чтобы думать о таких тонкостях70
0.51%Всегда юзал str.split('').join('')8
0.82%Всегда юзал JSON.parse(JSON.stringify(str))13
0.19%Всегда юзал (' '+str).slice(1)3
1.2%Всегда юзал другой вариант19
Проголосовали 1578 пользователей. Воздержались 257 пользователей.

