Как-то раз возникла необходимость написать транслитерацию на Python — из кириллицы в латиницу. Из слова «ситх» получается «sith», а из «шелест» выходит «shelest».
Казалось бы, чего тут вообще писать — задача едва сложнее print "Hello world". И это отчасти так — но не совсем.
Дело в том, что некоторые буквы в русском языке при транслитерации преобразуются не в одну, а сразу несколько латинских букв: это Ж, Ц, Ч, Ш, Щ, Ю и Я. По сути, если бы правилами транслитерации предполагалось преобразовывать их в одну латинскую букву, то транслитерация русского в английский действительно была бы не намного сложнее той самой простейшей программы.
Но, поскольку правила транслитерации мы менять точно не собираемся, то посмотрим, что получится при использовании обычной транслитерации.
К примеру, фраза «ШАПКА и Юля» преобразуется в «SHAPKA и YUlya», либо в «ShAPKA и Yulya» — в зависимости от того, что задано в таблице транслитерации для «Ш» и «Ю» (иногда задаётся «SH» и «YU», а иногда «Sh» и «Yu»).
То есть регистр следующей буквы в стандартных функциях транслитерации не учитывается, и все буквы в верхнем регистре заменяются по общим правилам. Поэтому в ходе транслитерации для слов «ЧАША» и «Щи» легко получается что-то вроде «ChAShA» или «SCHi», когда реально мы скорее хотели получить «CHASHA» и «Schi».
Тем не менее, все найденные реализации транслитерации из кириллицы в латиницу на Python, как выяснилось, эту особенность не учитывали. Это и многочисленные решения, приведённые на форумах, и библиотека pytils, реализующая транслитерацию в одном из своих модулей.
Значит, напишем свою функцию транслитерации, с блэкджеком и^W^W^W^H^H. :)
Итак, первый вариант — пройтись по строке посимвольно. В этом случае всегда известно, какой символ следующий (если это не последний символ в строке).
Принцип такой:
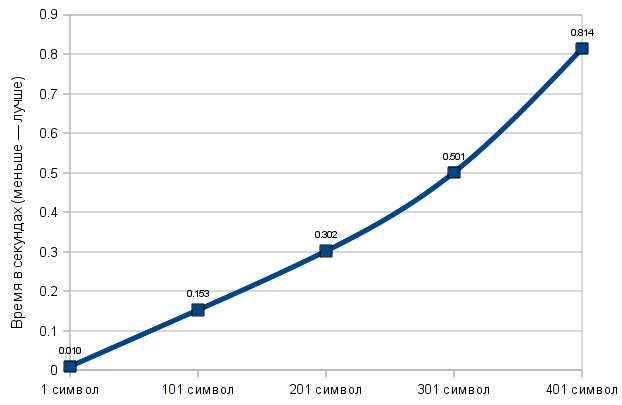
Преимущества этого варианта в том, что он немного короче следующих четырёх (на самом деле всего на несколько строчек), и, что более интересно, он очень быстро работает с очень маленькими строками. А вот с большими строками он наоборот работает очень медленно — то есть время, необходимое на транслитерацию строки, сильно зависит от количества символов в строке — на графике можно увидеть, как именно меняется время транслитерации при разном количестве символов.
Для большей точности время выполнения (и на этом, и на другом графике) указано не для одной операции транслитерации, а для 500. Процессор, установленный на компьютере — Intel Core 2 Quad CPU Q9400 @ 2.66GHz.
Что ж, стало очевидно, что для более быстрой обработки длинных строк нужно как-то использовать замену каждого отдельного символа сразу по всей строке (replace). А по сути, заменяться же может и не один символ, а сразу группа символов. Так и появился второй вариант.
Вообще, надо сказать, что замена групп символов — не единственное решение, которое приходило в голову. Сначала, например, возникла идея делить строку на слова, затем для каждого слова проверять регистр (если слово, в котором все символы переводятся в верхний регистр, равно первоначальному слову, значит, такое слово целиком в верхнем регистре), и, если слово написано в верхнем регистре, то применять отдельную таблицу транслитерации, специально для слов в верхнем регистре. Соответственно, в этом случае буква «Ш» в слове «Шахматы» будет транслитерирована как «Sh», а вот в слове «ШАХМАТЫ» уже как «SH».
Правда, в словах, написанных в смешанном регистре (например, «ШАХматЫ») будет в любом случае использована обычная таблица транслитерации (то есть, получится ShAHmatY). Но это уже, в общем-то, не так важно.
Либо, как вариант, можно было бы сделать ещё более универсально — применять replace для слов, написанных в нижнем регистре, а остальные слова обрабатывать посимвольно. Но это уже, вероятно, было бы медленнее, потому что таких слов, скорее всего, получится много.
Тем не менее, вернёмся ко второму написанному варианту. Принцип у него заключается в том, чтобы выделить те русские буквы, которые представляются в виде сразу нескольких латинских символов, в отдельный словарь, после чего по циклу создать словарь (таблицу транслитерации) из пар символов, где для каждой из таких букв (Ж, Ц, Ч, Ш, Щ, Ю и Я) есть 33 разных варианта, с каждой из строчных букв русского алфавита. Соответственно, остаётся сначала сделать замену для таких пар символов, а затем для всех остальных символов, которые остались не транслитерированы.
Но именно такой вариант оказался очень медленным (на самом деле медленной оказалась реализация — но об этом ниже).
Если говорить более точно, то он быстрее первого варианта только при очень большом количестве символов — около 10 тысяч.
А при обработке строк от 100 до 1000 символов первый вариант оказывается приблизительно в 10 раз быстрее.
Что ж, 7 * 33 = 231. То есть 231 дополнительная замена. Конечно, в словаре мы не встретим многих из этих сочетаний букв — то есть, теоретически, можно было бы сделать и меньшее количество операций замены. Но, с другой стороны, текст может состоять не только из слов, которые есть в словаре, да и вообще лишний раз вносить подобные ограничения не хочется.
На самом деле, как оказалось, дело не в том, что производится большое количество операций замены, а в том, как именно реализована замена символов (смотри четвёртый вариант).
Впрочем, сначала рассмотрим третий вариант.
Третий вариант чем-то похож на второй, но тут уже нет 231 отдельной замены для каждой возможной комбинации Ж, Ц, Ч, Ш, Щ, Ю и Я со строчными буквами. Вместо этого там используется регулярное выражение, которое применяется всего для 7 замен. Каждая из букв, соответствующих нескольким латинским буквам, после которой следует строчный символ ([а-я]) заменяется на латинское представление данной буквы, после которого следует тот же строчный символ (без транслитерации). После этого, соответственно, оставшиеся строчные буквы заменяются отдельно, как, впрочем, и прописные. При замене прописных букв, соответствующих нескольким латинским символам, для латинского представления буквы применяется метод upper().
И вот этот вариант уже как раз оказался очень быстрым по сравнению со вторым.
На строках в 100 символов он, надо отметить, медленнее, чем первый вариант. А вот на строке в 1000 символов он уже в два раза быстрее первого варианта, и в 19,5 раз быстрее второго.
В принципе, на этом можно бы было закончить, но реально есть ещё кое-что, что можно и нужно добавить.
Если написать import this, то мы получаем всем известный текст, дзэн языка Python. Помимо прочего, там есть фраза о том, что «должен быть один — и, желательно, только один — очевидный способ сделать это». Однако любой, кто достаточно долго программировал на Python, знает о том, что нередки случаи, когда есть довольно много способов сделать одно и то же, и при использовании любого из них результат может быть абсолютно одинаковым, но время, затрачиваемое на выполнение операции, может отличаться очень сильно.
Так, например u"Ваше имя — %s" % username выполняется намного быстрее, чем u"Ваше имя — "+username. Об этом хорошо и подробно написано в статье «Efficient String Concatenation in Python».
Аналогично и здесь — строку можно заменить через re.sub, а можно воспользоваться строковым методом replace. Причём если при какой-либо замене не используются регулярные выражения, то настоятельно рекомендуется пользоваться именно вторым способом, который, к тому же, работает намного быстрее. Кстати, в том же pytils используется именно строковой метод replace.
Итак, четвёртый вариант (второй вариант с правками). Отредактированы всего три строчки, но производительность увеличилась колоссально.
Этот вариант лучше всех остальных при строках в 1000 и в 10000 символов. На строках в 100 символов разница по сравнению с тем, что было (второй вариант), тоже очень велика.
Но как насчёт того, чтобы отредактировать и третий вариант? Ведь из трёх циклов, где осуществляется замена символов, регулярные выражения используются только в одном. Что ж, отлично, отредактируем и третий вариант тоже.
Пятый вариант отличается от третьего только тем, что в двух циклах, где для замены не используются регулярные выражения, операция замены производится с помощью строкового метода replace.
Без сомнения, это должно было сильно повлиять на производительность: скорость у пятого варианта получилась в среднем в 1,5 раза больше, чем у третьего. Причём оказалось, что на строке в 100 символов пятый вариант работает даже быстрее первого (то есть быстрее посимвольной обработки).

Получается, что алгоритмы с заменой оказались быстрее, чем посимвольная обработка, для строк в 100, 1000 и 10000 символов.
И всё же у каждого варианта есть свои достоинства и недостатки. К примеру, даже несмотря на то, что в пятом варианте строка в 100 символов обрабатывается быстрее, чем с помощью посимвольного прохождения по строке, на совсем маленьких строках (в несколько символов — а бывает и такое) посимвольная обработка всё равно окажется самым быстрым вариантом.
Возможно, наиболее правильное решение — это комбинация самого лучшего алгоритма для обработки коротких строк и самого лучшего алгоритма для обработки длинных строк. То есть прежде всего проверяем длину строки, и, затем, в зависимости от этого используем либо тот, либо другой алгоритм.
В завершение хочу привести цитату Майка Хертеля (Mike Haertel — автор GNU Grep) из его сообщения в списке рассылки freebsd-current относительно того, почему GNU Grep работает настолько быстро:
«Ключ к тому, чтобы сделать программы быстрыми — добиться, чтобы они практически ничего не делали».
Если есть ещё какие-то мысли — смело дописывайте, дополняйте. Если появятся ещё какие-то доработки, думаю, для многих это может быть интересно.
Казалось бы, чего тут вообще писать — задача едва сложнее print "Hello world". И это отчасти так — но не совсем.
Дело в том, что некоторые буквы в русском языке при транслитерации преобразуются не в одну, а сразу несколько латинских букв: это Ж, Ц, Ч, Ш, Щ, Ю и Я. По сути, если бы правилами транслитерации предполагалось преобразовывать их в одну латинскую букву, то транслитерация русского в английский действительно была бы не намного сложнее той самой простейшей программы.
Но, поскольку правила транслитерации мы менять точно не собираемся, то посмотрим, что получится при использовании обычной транслитерации.
К примеру, фраза «ШАПКА и Юля» преобразуется в «SHAPKA и YUlya», либо в «ShAPKA и Yulya» — в зависимости от того, что задано в таблице транслитерации для «Ш» и «Ю» (иногда задаётся «SH» и «YU», а иногда «Sh» и «Yu»).
То есть регистр следующей буквы в стандартных функциях транслитерации не учитывается, и все буквы в верхнем регистре заменяются по общим правилам. Поэтому в ходе транслитерации для слов «ЧАША» и «Щи» легко получается что-то вроде «ChAShA» или «SCHi», когда реально мы скорее хотели получить «CHASHA» и «Schi».
Тем не менее, все найденные реализации транслитерации из кириллицы в латиницу на Python, как выяснилось, эту особенность не учитывали. Это и многочисленные решения, приведённые на форумах, и библиотека pytils, реализующая транслитерацию в одном из своих модулей.
Значит, напишем свою функцию транслитерации, с блэкджеком и^W^W^W^H^H. :)
Итак, первый вариант — пройтись по строке посимвольно. В этом случае всегда известно, какой символ следующий (если это не последний символ в строке).
Принцип такой:
- Для каждого символа проверяется, есть ли он среди ключей словаря lower_case_letters.
- Если есть, то он заменяется на значение для данного ключа в lower_case_letters.
- Если нет, то проверяется, есть ли этот символ среди ключей словаря capital_letters.
- Если есть, то проверяется, последний ли это символ в строке (если длина строки больше, чем позиция текущего символа + 1 — значит, это ещё не последний символ, при условии, что позиция отсчитывается от нуля).
- Если символ не последний, то проверяется, есть ли следующий символ среди ключей словаря lower_case_letters.
- Если нет, либо если это последний символ в строке, то текущий символ заменяется на значение для данного ключа в словаре capital_letters, при этом для значения применяется метод upper() — то есть из «Sh» получается «SH», и так далее.
- Если же следующий символ есть среди ключей словаря lower_case_letters — то метод upper() не применяется.
Преимущества этого варианта в том, что он немного короче следующих четырёх (на самом деле всего на несколько строчек), и, что более интересно, он очень быстро работает с очень маленькими строками. А вот с большими строками он наоборот работает очень медленно — то есть время, необходимое на транслитерацию строки, сильно зависит от количества символов в строке — на графике можно увидеть, как именно меняется время транслитерации при разном количестве символов.
Для большей точности время выполнения (и на этом, и на другом графике) указано не для одной операции транслитерации, а для 500. Процессор, установленный на компьютере — Intel Core 2 Quad CPU Q9400 @ 2.66GHz.

Что ж, стало очевидно, что для более быстрой обработки длинных строк нужно как-то использовать замену каждого отдельного символа сразу по всей строке (replace). А по сути, заменяться же может и не один символ, а сразу группа символов. Так и появился второй вариант.
Вообще, надо сказать, что замена групп символов — не единственное решение, которое приходило в голову. Сначала, например, возникла идея делить строку на слова, затем для каждого слова проверять регистр (если слово, в котором все символы переводятся в верхний регистр, равно первоначальному слову, значит, такое слово целиком в верхнем регистре), и, если слово написано в верхнем регистре, то применять отдельную таблицу транслитерации, специально для слов в верхнем регистре. Соответственно, в этом случае буква «Ш» в слове «Шахматы» будет транслитерирована как «Sh», а вот в слове «ШАХМАТЫ» уже как «SH».
Правда, в словах, написанных в смешанном регистре (например, «ШАХматЫ») будет в любом случае использована обычная таблица транслитерации (то есть, получится ShAHmatY). Но это уже, в общем-то, не так важно.
Либо, как вариант, можно было бы сделать ещё более универсально — применять replace для слов, написанных в нижнем регистре, а остальные слова обрабатывать посимвольно. Но это уже, вероятно, было бы медленнее, потому что таких слов, скорее всего, получится много.
Тем не менее, вернёмся ко второму написанному варианту. Принцип у него заключается в том, чтобы выделить те русские буквы, которые представляются в виде сразу нескольких латинских символов, в отдельный словарь, после чего по циклу создать словарь (таблицу транслитерации) из пар символов, где для каждой из таких букв (Ж, Ц, Ч, Ш, Щ, Ю и Я) есть 33 разных варианта, с каждой из строчных букв русского алфавита. Соответственно, остаётся сначала сделать замену для таких пар символов, а затем для всех остальных символов, которые остались не транслитерированы.
Но именно такой вариант оказался очень медленным (на самом деле медленной оказалась реализация — но об этом ниже).
Если говорить более точно, то он быстрее первого варианта только при очень большом количестве символов — около 10 тысяч.
А при обработке строк от 100 до 1000 символов первый вариант оказывается приблизительно в 10 раз быстрее.
Что ж, 7 * 33 = 231. То есть 231 дополнительная замена. Конечно, в словаре мы не встретим многих из этих сочетаний букв — то есть, теоретически, можно было бы сделать и меньшее количество операций замены. Но, с другой стороны, текст может состоять не только из слов, которые есть в словаре, да и вообще лишний раз вносить подобные ограничения не хочется.
На самом деле, как оказалось, дело не в том, что производится большое количество операций замены, а в том, как именно реализована замена символов (смотри четвёртый вариант).
Впрочем, сначала рассмотрим третий вариант.
Третий вариант чем-то похож на второй, но тут уже нет 231 отдельной замены для каждой возможной комбинации Ж, Ц, Ч, Ш, Щ, Ю и Я со строчными буквами. Вместо этого там используется регулярное выражение, которое применяется всего для 7 замен. Каждая из букв, соответствующих нескольким латинским буквам, после которой следует строчный символ ([а-я]) заменяется на латинское представление данной буквы, после которого следует тот же строчный символ (без транслитерации). После этого, соответственно, оставшиеся строчные буквы заменяются отдельно, как, впрочем, и прописные. При замене прописных букв, соответствующих нескольким латинским символам, для латинского представления буквы применяется метод upper().
И вот этот вариант уже как раз оказался очень быстрым по сравнению со вторым.
На строках в 100 символов он, надо отметить, медленнее, чем первый вариант. А вот на строке в 1000 символов он уже в два раза быстрее первого варианта, и в 19,5 раз быстрее второго.
В принципе, на этом можно бы было закончить, но реально есть ещё кое-что, что можно и нужно добавить.
Если написать import this, то мы получаем всем известный текст, дзэн языка Python. Помимо прочего, там есть фраза о том, что «должен быть один — и, желательно, только один — очевидный способ сделать это». Однако любой, кто достаточно долго программировал на Python, знает о том, что нередки случаи, когда есть довольно много способов сделать одно и то же, и при использовании любого из них результат может быть абсолютно одинаковым, но время, затрачиваемое на выполнение операции, может отличаться очень сильно.
Так, например u"Ваше имя — %s" % username выполняется намного быстрее, чем u"Ваше имя — "+username. Об этом хорошо и подробно написано в статье «Efficient String Concatenation in Python».
Аналогично и здесь — строку можно заменить через re.sub, а можно воспользоваться строковым методом replace. Причём если при какой-либо замене не используются регулярные выражения, то настоятельно рекомендуется пользоваться именно вторым способом, который, к тому же, работает намного быстрее. Кстати, в том же pytils используется именно строковой метод replace.
Итак, четвёртый вариант (второй вариант с правками). Отредактированы всего три строчки, но производительность увеличилась колоссально.
Этот вариант лучше всех остальных при строках в 1000 и в 10000 символов. На строках в 100 символов разница по сравнению с тем, что было (второй вариант), тоже очень велика.
Но как насчёт того, чтобы отредактировать и третий вариант? Ведь из трёх циклов, где осуществляется замена символов, регулярные выражения используются только в одном. Что ж, отлично, отредактируем и третий вариант тоже.
Пятый вариант отличается от третьего только тем, что в двух циклах, где для замены не используются регулярные выражения, операция замены производится с помощью строкового метода replace.
Без сомнения, это должно было сильно повлиять на производительность: скорость у пятого варианта получилась в среднем в 1,5 раза больше, чем у третьего. Причём оказалось, что на строке в 100 символов пятый вариант работает даже быстрее первого (то есть быстрее посимвольной обработки).

Получается, что алгоритмы с заменой оказались быстрее, чем посимвольная обработка, для строк в 100, 1000 и 10000 символов.
И всё же у каждого варианта есть свои достоинства и недостатки. К примеру, даже несмотря на то, что в пятом варианте строка в 100 символов обрабатывается быстрее, чем с помощью посимвольного прохождения по строке, на совсем маленьких строках (в несколько символов — а бывает и такое) посимвольная обработка всё равно окажется самым быстрым вариантом.
Возможно, наиболее правильное решение — это комбинация самого лучшего алгоритма для обработки коротких строк и самого лучшего алгоритма для обработки длинных строк. То есть прежде всего проверяем длину строки, и, затем, в зависимости от этого используем либо тот, либо другой алгоритм.
В завершение хочу привести цитату Майка Хертеля (Mike Haertel — автор GNU Grep) из его сообщения в списке рассылки freebsd-current относительно того, почему GNU Grep работает настолько быстро:
The key to making programs fast is to make them do practically nothing. ;-)
«Ключ к тому, чтобы сделать программы быстрыми — добиться, чтобы они практически ничего не делали».
Если есть ещё какие-то мысли — смело дописывайте, дополняйте. Если появятся ещё какие-то доработки, думаю, для многих это может быть интересно.
