В прошлый раз (почти год назад) мы определяли части речи в русском тексте, производили морфологический анализ слов. В этой статье мы пойдем на уровень выше, к синтаксическому анализу целых предложений.
Наша цель заключается в создании парсера русского языка, т.е. программы, которая на вход бы принимала произвольный текст, а на выходе выдавала бы его синтаксическую структуру. Например, так:
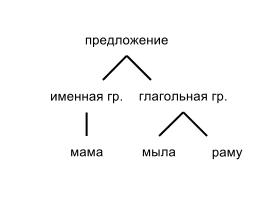
"Мама мыла раму": (предложение (именная гр. (сущ мама)) (глаг. гр. (глаг мыла) (именная гр. (сущ раму))) (. .)))
Это называется синтаксическим деревом предложения. В графическом виде его можно представить следующим образом (в упрощенном виде):
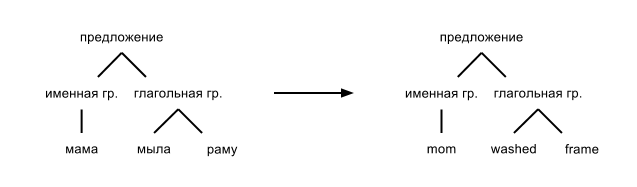
Определение синтаксической структуры предложения (парсинг) является одним из основных этапов в цепочке анализа текста. Зная структуру предложения, мы можем сделать более глубокий анализ и другие интересные вещи. Например, мы можем создать систему автоматического перевода. В упрощенном виде это выглядит так: перевести каждое слово по словарю, а затем сгенерировать предложение из синтаксического дерева:
На хабре уже было несколько статей про парсинг предложений (1, 2), а на конференции Диалог даже проводятся соревнования парсеров. Однако, в этой статье я хотел бы рассказать о том как же именно парсить русский язык, заместо сухой теории.
Проблемы и задачи
Итак, зачем я хочу парсить русский язык и почему это является нерешенной проблемой? Во-первых, парсить человеческие языки (в отличие от компьютерных) сложно из-за большого количества неоднозначностей (напр. омонимия), исключений из правил, новых слов и пр. Во-вторых, большое количество разработок и исследований существует для английского языка, но гораздо меньше для русского. Найти открытый парсер для русского практически невозможно. Все существующие наработки (например, ЭТАП, ABBYY и прочие) закрыты для публики. Тем не менее, для любой серьезной задачи анализа текстов необходимо иметь синтаксический парсер.
Немного теории
Несмотря на то, что это практическая статья, а не теоретическая, мне необходимо дать немного теории, чтобы знать, чем мы будем заниматься. Итак, пусть у нас есть простое предложение «Мама мыла раму.» Что мы хотим получить в качестве результата от парсера? Существует большое количество моделей, описывающих человеческие языки, из которых я бы выделил две наиболее популярных:
- Грамматика составляющих (constituency grammar)
- Грамматика зависимостей (dependency grammar)
Первая из них (грамматика составляющих) пытается разбить предложение на более мелкие структуры — группы, а затем каждую группу на более мелкие группы, и так далее пока не дойдем до отдельных слов или словосочетаний. Первый пример в этой статье был приведен используя как раз таки формализм грамматики составляющих:
- разбиваем предложение на именную и глагольную группы
- именную группу разбиваем на существительное (мама)
- глагольную группу на глагол (мыла) и на вторую именную группу
- вторую глагольную группу на существительное (раму)
Чтобы разобрать предложение использую грамматику составляющих, можно воспользоваться парсерами формальных языков (про это было много статей на хабре: 1, 2). Проблема будет впоследствии в снятии неоднозначностей, т.к. одному и тому же предложению будут соответствовать несколько синтаксических деревьев. Однако, самая большая проблема заключается в том, что грамматика составляющих не очень хорошо подходит для русского языка, т.к. в русском языке порядок слов в предложении зачастую можно менять местами, не меняя смысла. Для русского нам лучше подойдет грамматика зависимостей.
В грамматике зависимостей порядок слов не важен, т.к. мы хотим лишь знать от какого слова зависит каждое слово в предложении и тип этих связей. На примере это выглядит так:

В данном предложении «мама» зависит от глагола «мыть» и является субъектом, «рама» также зависит от глагола «мыть», но является «объектом». Даже если мы поменяем порядок слов в предложении, связи все равно останутся теми же. Итак, от нашего парсера мы хотим получить список зависимостей для слов в предложении. Это может выглядеть так:
"Мама мыла раму": субъект(мама, мыла) объект(раму, мыла)
На этом с теорией закончим и перейдем к практике.
Существующие подходы
Существует два основных подхода при создании синтаксического парсера:
- Метод, основанный на правилах (rule based)
- Машинное обучение с учителем (supervised machine learning)
Также можно объединить оба метода и еще существуют методы машинного обучения без учителя, где парсер сам пытается создать правила, пытаясь найти закономерности в неразмеченных текстах (Протасов, 2006).
Метод, основанный на правилах, применяется практически во всех коммерческих системах, т.к. он дает наибольшую точность. Основная идея заключается в создании набора правил, которые определяют, как проставлять связи в предложении. Например, в нашем предложении «Мама мыла раму» мы можем применять следующие правила (допустим, что мы уже сняли все неоднозначности и точно знаем грамматические категории слов):
- слово («мама») в именительном падеже, женском роде и единственном числе должно зависеть от глагола («мыла») в единственном числе, прошедшем времени, женском роде и тип связи должен быть «субъект»
- слово («раму») в винительном падеже должно зависеть от глагола и тип связи должен быть «объект»
В системе может быть много подобных правил, а также анти-правил, которые указывают, когда НЕ нужно проставлять связи, например, если у существительного и глагола различаются род или число, то между ними нет связи. Также существуют правила третьего типа, которые указывают какую пару слов следует предпочесть, если возможны несколько вариантов. Например, в предложении «мама мыло окно»: и «мама», и «окно» могут выступать в качестве субъекта, однако, мы можем предпочесть предстоящее глаголу слово, чем последующее.
Данный подход очень ресурсоемок, т.к. для создания парсера требуется хорошая команда лингвистов, которые должны буквально описать весь русский язык. Поэтому нам более интересен второй подход — машинное обучение с учителем.
Идея в парсинге, использующем машинном обучение, как и во всех остальных задачах машинного обучения довольно таки проста: мы даем компьютеру много примеров с правильными ответами, на которых система должна обучиться самостоятельно. Чтобы обучить синтаксические парсеры — в качестве данных для обучения используют специально размеченные корпуса (treebanks), коллекции текстов, в которых размечена синтаксическая структура. Наше предложение в таком корпусе может выглядеть следующим образом:
1 Мама сущ.им.ед.жен. 2 субъект 2 мыла глаг.ед.жен.прош 0 - 3 раму сущ.вин.ед.жен. 2 объект
В этом формате мы записываем каждое предложение в виде строки, где каждая строка описывает отдельное слово в виде записей разделенных табуляцией. Для каждого слова нам нужно хранить следующие данные:
- номер слова в предложении (1)
- словоформа (мама)
- грамматические категории (сущ.им.ед.жен.)
- номер главного слова (2)
- тип связи (субъект)
В этой статье, к сожалению, не хватит места описать детальные алгоритмы разных парсеров. Я лишь покажу, как можно обучить существующий парсер для работы с русским языком.
Обучаем парсер
Есть несколько открытых парсеров, которые можно обучить для работы с русским языком. Вот два, которые я пробовал обучать:
- MST Parser, основанных на задаче нахождения минимального остовного дерева
- MaltParser, основан на машинном обучении (хотя и MST Parser тоже, но там немного другая идея)
Обучение MST-парсера занимает гораздо больше времени и он также дает худшие результаты по сравнению с MaltParser, поэтому далее мы сфокусируемся на втором из них.
Итак, для начала требуется скачать MaltParser и распаковать скачанный архив.
> wget http://maltparser.org/dist/maltparser-1.7.1.tar.gz > tar xzvf maltparser-1.7.1.tar.gz > cd maltparser-1.7.1
Парсер написан на яве, поэтому для его работы вам потребуется JVM. Если вы работаете с английским, французским или шведским, то вы можете скачать уже готовые модели для этих языков. Однако, мы работаем с русским, поэтому нам будет веселее.
Чтобы обучить новую языковую модель нам потребуется размеченный корпус. Для русского существует на данный момент только один синтаксически размеченный корпус — СинТагРус, который входит в состав НКРЯ. Мне удалось получить доступ к СинТагРус на условиях нераспространения и исследовательских целей. Корпус представляет собой набор текстов размеченных в формате XML:
<S ID="8"> <W DOM="2" FEAT="S ЕД МУЖ ИМ НЕОД" ID="1" LEMMA="КАБИНЕТ" LINK="предик">Кабинет</W> <W DOM="_root" FEAT="V НЕСОВ ИЗЪЯВ ПРОШ ЕД МУЖ" ID="2" LEMMA="ОТЛИЧАТЬСЯ">отличался</W> <W DOM="2" FEAT="S ЕД ЖЕН ТВОР НЕОД" ID="3" LEMMA="СКРОМНОСТЬ" LINK="2-компл">скромностью</W>, <W DOM="3" FEAT="A ЕД ЖЕН ТВОР" ID="4" LEMMA="ПРИСУЩИЙ" LINK="опред">присущей</W> <W DOM="4" FEAT="S ЕД МУЖ ДАТ ОД" ID="5" LEMMA="СЕМЕН" LINK="1-компл">Семену</W> <W DOM="5" FEAT="S ЕД МУЖ ДАТ ОД" ID="6" LEMMA="ЕРЕМЕЕВИЧ" LINK="аппоз">Еремеевичу</W>. </S>
Для обучения парсера нам необходимо перевести файлы в формат malttab. Для этих целей был написан небольшой скрипт, который читает XML и выдает нужный формат, попутно нормализуя грамматические категории:
Кабинет S.m.nom.sg 2 предик отличался V.m.real.sg 0 ROOT скромностью S.f.ins.sg 2 2-компл присущей A.f.ins.sg 3 опред Семену S.dat.m.sg 4 1-компл Еремеевичу S.dat.m.sg 5 аппоз
В документации говорится, что для обучения парсера его необходимо запустить со следующими параметрами:
> java -jar maltparser-1.7.1.jar -c russian -i /path/to/corpus.conll -m learn -с название модели (на выходе получится файл russian.mco) -i входной файл - размеченный корпус -m режим работы, в данном случае это learn - обучение
Однако, я запускал обучение с дополнительными аргументами:
> java -Xmx8000m -jar maltparser-1.7.1.jar -c russian -i /path/to/corpus.tab -if appdata/dataformat/malttab.xml -m learn -l liblinear -Xmx8000m увеличиваем доступную память -if appdata/dataformat/malttab.xml изменяем формат входных данных на malttab (по умолчанию парсер использует формат CoNLL, но он сложнее) -l liblinear используем для обучения линейные SVM вместо более медленной библиотеки LIBSVM
В итоге мы получим файл russian.mco, который содержит обученную модель и необходимые конфигурационные данные. Теперь у нас есть все (ну или почти все), что нужно, чтобы парсить русские тексты.
Парсим русский язык
Запуск парсинга производится следующим образом:
> java -jar maltparser-1.7.1.jar -c russian -i /path/to/input.tab -o out.tab -m parse -с название нашей модели -i входной файл, который необходимо распарсить -o выходной файл, куда будет записан результат -m parse режим парсинга
Единственное, что нам нужно для парсинга произвольного текста — это скрипт, который бы подготовил текст в формат malttab. Для этого скрипт должен:
- Разбить текст на предложения (сегментация на предложения)
- Разбить каждое предложение на слова (токенизация)
- Определить грамматические категории для каждого слова (морфологический анализ)
Эти три задачи гораздо проще чем синтаксический анализ. И к счастью для русского существуют открытые либо бесплатные системы для морфологического анализа. В предыдущей статье мы даже этим немного занимались, там же вы можете найти отсылки к другим существующим системам. Для своих целей я написал морфологический анализатор на основе машинного обучения, который я тренировал на том же СинТагРус. Возможно, в следующий раз опишу и его.
Я произвел обучение на 1/6 части СинТагРус и получил модель для русского языка, которую вы можете попросить для личных целей. Чтобы ею воспользоваться, нужно чтобы грамматические категории совпадали с теми, которые использовал я при обучении модели.
Данная модель показала точность (accuracy) в 78,1%, что довольно таки неплохо и для большинства целей вполне подходит. Модель, обученная на всем корпусе дает точность в 79,6%.
Заключение
Синтаксический анализ является одним из базовых этапов для более сложных анализов текста. Открытых парсеров для русского языка днем с огнем не сыщешь. В этой статье я попытался заполнить этот пробел. При желании (и доступе к СинТагРус) вы можете обучить открытые парсеры и работать с русским языком. Точность обученного парсера не идеальная, хотя для многих задач она вполне приемлима. Однако, на мой взгляд, это хорошая стартовая площадка для улучшения результатов.
Я не специализируюсь на парсерах, а также не являюсь специалистом в русской лингвистике, но буду рад выслушать любую критику, пожелания и предложения. В следующий раз надеюсь написать либо про морфологический анализатор, который был использован вместе с парсером, либо про собственный парсер на питоне (если к тому времени закончу над ним работу).
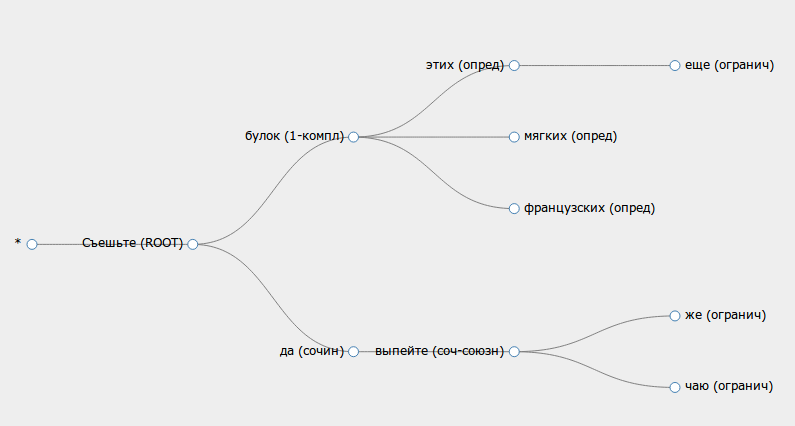
Я выложил простое онлайн демо, которое, пока не упало, выглядит так:

Весь код (кроме корпуса) доступен здесь: github.com/irokez/Pyrus
В заключение я хотел бы поблагодарить НКРЯ, а в частности ИППИ РАН за предоставление доступа к СинТагРус.

