Пару недель назад, необходимо было освежить информацию в голове информацию по структурам данных и алгоритмам для собеседования. Первым делом полез на www.coursera.org, где хотел пробежаться по некоторым лекциям курса Алгоритмы, там же были две сводные таблички, которые в процессе изучения курса взял на заметку — отлично помогали запомнить сложность операций. Но, к моему удивлению, материалы пройденного курса стали недоступны. Быстрое гугление, в надежде, что кто-нибудь выложил лекции на торрентах, к сожалению, не дало результатов. В итоге, я нашел полную коллекцию слайдов по данному курсу. Спешу поделиться. Самое главное, что взял из этих слайдов, — это вышеупомянутые сводные таблички. Думаю многим пригодится.
Сортировки:
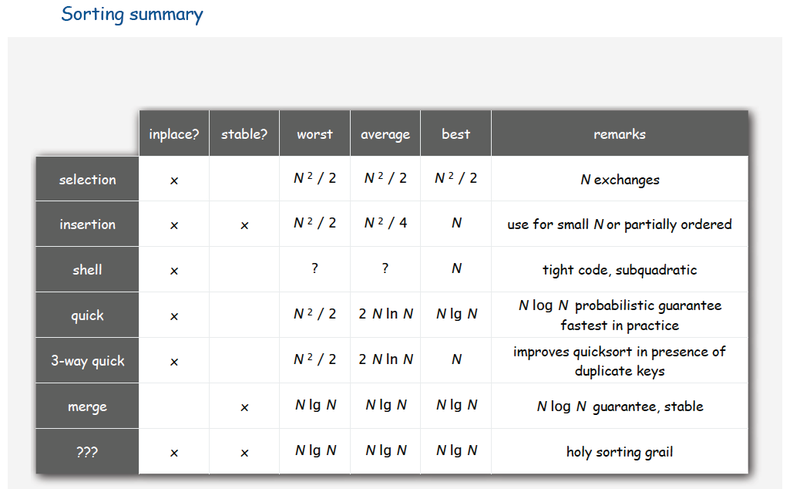
Структуры данных:

Сортировки:
Структуры данных:

