
Мне постоянно приходится слышать от студентов и начинающих гейм-дизайнеров – да, честно говоря, и от бывалых программистов тоже – один и тот же вопрос, который звучит примерно так: “Какую архитектуру AI мне выбрать для своего проекта?”. Этим вопросом пестрят форумы, его можно услышать на конференции разработчиков игр GDC, и, конечно же, его не один раз вспоминают во время пре-продакшна создатели любой игры – от AAA-класса до инди. Я работаю консультантом по игровому AI, поэтому я постоянно слышу ее от своих клиентов.
Обычно, самый лучший ответ на этот вопрос – «Когда как». Вот только подобный ответ мало кого устраивает, поэтому после него мне приходится устраивать самый настоящий допрос.
Это напоминает мне о тех временах, когда я еще работал официантом. Тогда люди часто обращались ко мне с вопросом – «А что вы посоветуете?» или, что еще коварнее, — «Какое блюдо здесь самое вкусное?». Те из вас, кто никогда не работал в ресторанном бизнесе, вряд ли могут представить себе, сколько неудобств создает этот вопрос тому, к кому он был обращен. Ведь, казалось бы, любой из нас и так понимает, что вкусы у всех разные… так откуда же именно официанту знать, ради чего вы сюда пришли? В таких ситуациях мне всегда приходилось прибегать к ответным вопросам. «Насколько вы проголодались? Вы спешите куда-нибудь или готовы подождать? Какое у вас сегодня настроение? Как насчет стейка? А может, курицу? Что, у вас аллергия на арахис? А, так вы все-таки спешите? О… так вы вегетарианец? Это же все меняет!». Смысл подобного «допроса» не в том, чтобы навязать посетителю что-то – смысл скорее в том, чтобы помочь ему определиться для себя, чего ему хочется сейчас и на самом деле.
Когда дело доходит до разговоров об архитектуре искусственного интеллекта, то обсуждение начинает напоминать описанную ситуацию. В конце концов, когда существует несколько путей для решения проблемы, то не всегда какой-то один из них обязательно будет лучшим. Как я уже намекнул выше – чаще всего сделанный выбор будет зависеть от обстоятельств. Что вы пытаетесь сделать? Есть ли у вас технические ограничения? Каков ваш опыт? Сколько времени отведено на разработку? Насколько ваши гейм-дизайнеры нуждаются в контроле? Серьезно, все это вещи, которыми должна быть забита голова у разработчика. Я же, словно официант, могу лишь помочь вам с поиском правильного ответа и задать верный вектор мышления, после чего у нас с вами на руках будут ответы на все наши вопросы.
Как вы, наверное, уже догадались, в книгах по данной теме и в статьях на сайтах принято освещать только одну сторону вопроса – как эти архитектуры устроены внутри, — а вот про их плюсы и минусы вы нигде не найдете ни слова. К чему это в итоге приводит? К тому, как все новые и новые Бабушкины с непробиваемой уверенностью кричат потом на каждом углу «Я создам свой [просто невероятный AI] при помощи [не имеющей ничего общего с ним технологии]!!». Не поймите меня неправильно, все эти источники знаний очень полезны – для того, кто хочет разобраться, как все это реализуется на практике. Но они все равно упускают важный момент – почему нужно поступить так, а не иначе.
На GDC 2010 мы выступали на секции AI, где представили доклад под названием «Выбор архитектуры AI: какое средство выбрать для своей работы?». Основой его создания послужил эксперимент, в ходе которого мы лоб в лоб столкнули четыре технологии и наблюдали за тем, какая из них лучше всего подходит для четырех совершенно разных ситуаций игрового AI. Каждой архитектуре был «отдан на откуп» один из наших сотрудников, чьей обязанностью стала защита своего выбора и активная критика чужого. (Раскрою страшную тайну: естественно, каждая из 4 игровых ситуаций была выбрана не случайно – для каждого из типов архитектур было по одному проекту) И в каждой ситуациями, заточенной под один «лучший» ответ, три «проигравших» участника справились с доказательством того, что их архитектура тоже могла бы сработать. Просто они не были не самым оптимальным выбором.
Но условие эффективности входит в нашу проблему, не так ли? Ясное дело — большей части архитектур AI по силам справиться с большинством возможных ситуаций. Но это утверждение зачастую приводит разработчиков к чувству ложной безопасности. Тот AI, который разработчик получает в конечном итоге, часто бывает достаточно сложен, что вынуждает регулярно тратить время на то, чтобы заниматься его дополнительным «причесыванием». Часто мы наблюдаем подобный эффект из-за того, что неподходящий – или, как бы мы сказали в терминах своей проблемы, «не самый оптимальный» — подход делает вещи значительно сложнее, чем им следовало бы быть. И это возвращает нас к первоначальному вопросу – «какую архитектуру AI следует использовать?» Мой ответ вы уже знаете, и он звучит просто — «когда как».
Одна суть, разные формы
Давайте вернемся к метафоре с едой. Выбор архитектуры AI сильно напоминает выбор блюда из мексиканской кухни – и это действительно так и есть в большинстве случаев. «Это все суть одно и то же — без разницы, как оно выглядит и как оно называется».
Позвольте мне объяснить, почему я так думаю. Содержимое большей части блюд мексиканской кухни может быть сведено к комбинации очень небольшого списка возможных ингридиентов: томаты, сыр, фасоль, лук… да вы и сами в курсе. Те из нас, кто не относит себя к вегетерианцам, могут смело добавить в этот список мясо (настоящее или соевое). Думайте об этих ингредиентах как о поведенческом содержимом нашего AI. Это то, что придает всему блюду свой собственный аромат и уникальность в целом. Но причем тут то, как оно выглядит? Когда вы заказываете одно из мексиканских блюд, вы делаете это, основываясь на его внешней форме – тако… буррито… и так далее. Почему же тогда мы мыслим терминами внешнего вида, когда, казалось бы, как раз содержимое должно играть для нас первоочередную роль?
Ответ кроется в том, что “снаружи” – некоторого рода обертка или оболочка – это всего лишь механизм для доставки “содержимого”. Смысл ее существования лишь в том, чтобы сохранить все содержимое в целости и сохранности ровно до того момента, пока вы не соберетесь наконец как следует откусить от вашей покупки. В таком контексте подобный “механизм доставки до потребителя” до боли напоминает смысл архитектур AI. Они служат лишь для упаковки и доставки «вкусного» поведенческого содержимого, которое нам хотелось бы дать возможность испытать игрокам. Но зачем же тогда придумано столько разных форм для такой простейшей функции? И какую из этих форм стоит использовать мне? Что ж, тут все зависит от обстоятельств…
Все эти выводы остаются справедливыми и в том случае, когда мы обсуждаем наши системы AI. В своих разговорах мы оперируем терминами механизма, а не содержимого. Мы пишем свой конечный автомат, «behavior tree» или планировщик – и выглядит это точно так же, как если бы мы наполняли содержимым наш тако или буррито. Как только мы решимся, как мы будем все “заворачивать”, мы сможем положить туда любую (или даже всю!) вкуснятину, которая только взбредет нам в голову. Однако… тут есть свои “за” и “против”.
Тостада, или обыкновенное нагромождение всего, что можно

Начнем с самого простого — возьмем, скажем, тостаду. Собственно говоря, это даже не полноценное блюдо, а всего лишь простой способ «доставки» мексиканской еды. Вы можете с легкостью добавлять и удалять из нее ингридиенты, но вы серьезно ограничены в отношении того, сколько вы сможете положить на нее — потому что рано или поздно содержимое начнет вываливаться со всех сторон. И пусть поначалу ее и немножко сложно взять в руки, но если вы возьмете ее правильным образом, то все останется на месте.
Тем не менее, тостада — это не самая стабильная «платформа». Если вы нечаянно зацепите не с той стороны, то все содержимое тут же вывалится. На этом сюрпризы не заканчиваются — как только вы начнете ее кусать, то есть риск, что в любой момент она может развалится в самом непредсказуемом месте, и все начнет вываливаться наружу. Вот и получается, что какими бы ни были ваши намерения относительно приема пищи, тостада окажется совершенно не подходящим «контейнером» для любого, кто попытается съесть ее – по сути, это просто круглая плоская лепешка, на которую сверху положено все, что требуется — и вам остается только надеяться на то, что там же оно и останется.
С точки зрения AI, эквивалентом является… у меня язык не поворачивается назвать это архитектурой… Скорее, это просто добавление правил поведения то тут, то там по всему нашему исходному коду — причем все это дело с чистой совестью пущено на самотек. Проблема тут налицо — как и в случае с тостадой, вы можете добавлять в нее что-то ровно до того момента, пока вся конструкция не станет слишком нестабильной. К тому же, получившийся в итоге монстр будет довольно неповоротлив. Но самая большая беда кроется в том, что когда вам потребуется взять какой-то один кусочек от целого, то у вас не будет никаких гарантий, что все остальное не развалится, как карточный домик.
Добавляем немного структуры, или конечный автомат тако

Наша тостада страдала от недостатка структурированности, которая помогла бы поддержать стабильность. Она могла немного рассыпаться с одной стороны или вообще развалиться. Однако, если мы уделим хотя бы немного внимания вопросу организации, то мы сможем быть уверены в том, что наше содержимое гораздо лучше само в себе! В мире мексиканской кухни все просто: загните края и, глядите, у вас уже получилось тако! Как результат – мы не только сможем сложить больше содержимого, но так же и взять тако в руки и донести до укромного уголка, где мы сможем им как следует насладиться.
Подобное добавление «структуры» для правил поведения приводит нас к чему-то похожему на самую простую архитектуру АИ – конечному автомату (FSM). Базовой частью FSM является состояние. Это, то что агент AI делает в конкретный заданный момент времени. (Но и это утверждение правдиво только отчасти – «продвинутые» агенты способны использовать несколько параллельно работающих FSM… забудьте пока об этом – вам сейчас достаточно считать, что каждый FSM находится в одном состоянии)
(Прим. перев.: С. Рассел и П. Норвиг определяют искусственный интеллект как науку об агентах, которые получают результаты актов восприятия из своей среды и выполняют действия. Каждый такой агент реализует функцию, которая отображает последовательности актов восприятия в действия.)
Причина, по которой поведение агента теперь организовано лучше – в том, что все, о чем ему требуется знать, содержится в коде для состояния, в котором он находится. К примеру, анимации, которые ему необходимо “проиграть” для конкретного состояния, заложены в теле кода этого состояния. Другая часть конечного автомата состояний – это необходимая “логика” определения того, что нужно делать дальше. Сюда можно также отнести переход в другое состояние — или наоборот, сохранение своего состояния.
Логика перехода для каждого из состояний может быть как простой, так и сложной – в зависимости от наших требований. Скажем, она может представлять собой простой таймер, который по истечению определенного времени сообщает о том, что нужно перейти в новое состояние. Переход в другое состояние можно привязать и к датчику случайных чисел – например, в состоянии A может быть задано, что при каждой проверке наблюдается 10% шанс перехода в состояние B. Мы можем пойти дальше, и сделать переход в новое состояние еще более случайным – скажем, с верояностью в 1/3 будет происходить переход в состояние B, и с 2/3 – в состояние C.
Чаще всего конечные автоматы используют сложные механизмы срабатывания, которые связаны с игровой логикой и ситуацией. К примеру, состояние “сторожить” может иметь следующую логику: “если [игрок входит в комнату] и [у него в руке Тако Власти] и [у меня есть Сокрушающая Сальса], то атаковать игрока”, в результате которой мое состояние меняется со “сторожить” на “атаковать”. Заметьте, что в условии перехода есть три индивидуальных критерия. Мы можем завести еще одно состояние, логика которого будет следующей: “если [игрок входит в комнату] и [держит Тако Силы] и [у меня НЕТ Сокрушающей Сальсы], то бежать” – и тут уже я перехожу из состояния “сторожить” в “бежать”.
Итак, для каждого состояния существует некий код, который отвечает за то, что делать, пока мы находимся в этом состоянии, и (что тоже важно) – какое существует условие перехода из него, и куда мы попадем в результате. И хотя некоторые из условий будут использовать одни и те же проверки, в конечном итоге каждое состояние имеет свой собственный набор переходов в другие состояния, и эти переходы используются исключительно для него. Увы, подобный подход не лишен своих недостатков.
Изобр. 1 – С добавлением новых состояний к конечному автомату, число переходов начинает расти в разы быстрее
Во-первых, с ростом числа состояний количество потенциальных переходов тоже растет – и происходит это с пугающей скоростью. Если исходить из предположения о том, что из каждого заданного состояния мы можем попасть в любое другое состояние, то число переходов увеличится довольно быстро. Точнее говоря, число переходов составит [число состояний ] × ( [ число состояний ] – 1 ). На изобр. 1 показано, как четыре состояния создают двенадцать переходов. Если мы добавим одно состояние, то количество переходов вырастет до двадцати, еще одно – уже тридцать, и так далее. А игры, на минуточку, обычно состоят из десятков состояний, со всевозможными переходами туда и обратно – и тут-то становится ясно, что вы столкнулись с многократно возросшей сложностью.
Однако, на свалку подобное решение отправляет совсем другая причина – и это количество труда, который приходится проделывать при добавлении каждого нового состояния к уже существующим. Для того, чтобы сделать состояние достижимым, вам придется пройтись по всем другим состояниям, которые теоретически могут переходить в новое. Возвращаясь к нашему примеру – для добавления состояния E мы должны изменить состояния A – D для добавления перехода к новому состоянию. Да и любое другое изменение уже существующей логики приведет к той же проблеме – вам придется постоянно держать в голове, какие из состояний могут понадобиться, и проходить по каждому из них.
Кстати говоря, любая логика, которая вовлечена в переход, также нуждается в пересмотре — для того, чтобы ее можно было совместить с той логикой, которая уже была здесь до этого. Как только мы столкнемся со всем этим огромным числом состояний, в которых должна содержаться логика переходов, да еще и с возможной сложностью организации их взаимодействия, мы поймем, что наш FSM-тако страдает от тех же проблем хрупкости, что и тостада, о которой мы говорили чуть раньше. Конечно, благодаря новой форме, мы уже можем положить в нее чуть больше содержимого, и даже больше того — нам будет чуть проще держать ее в руке. Но всего один укус способен разрушить все, и содержимое тако окажется на наших коленях. Чем больше она становится – тем ближе потенциальная катастрофа.
Более мягкий подход, или “Behavior Tree”

Итак, проблема с тако была в следующем: несмотря на то, что тако может честно хранить в себе небольшое количество содержимого (уж точно побольше, чем тостадо), оно все еще остается слишком хрупким. Проблема не в самой форме тако, а в том, что для него была использована твердая оболочка. Если бы только можно было то же содержимое сложить подобным же способом, но только бы сделать и оболочку-“контейнер” менее склонной к осыпанию в том случае, если мы немного надавим на нее… Ответ, конечно же, существует – и это мягкий тако. Его аналогом в мире архитектур AI является популярный принцип, называемый «behavior tree».
Сейчас мне кажется необходимым указать вам на различие между действием и решением. В конечном автомате, который обсуждался выше, наши агенты находились в определенном состоянии в конкретный момент времени — это означает, что они “делали что-то” в любой отдельно взятый момент времени (даже если этим “что-то” было “делать ничего”). Внутри каждого состояния находилась логика принятия решений, которая сообщала им, требуется ли сменить состояние на какое-то другое и, собственно говоря, в какое состояние им следует перейти. На практике, эта логика зачастую не имеет почти ничего общего с состоянием, в котором она содержится, и больше связана с тем, что происходит снаружи состояния или даже снаружи самого агента. Скажем, если я слышу выстрел, то для меня не слишком уж и важно чем я занят в это время – я вздрогну, спрячусь в укрытие, а то и наделаю в штаны – в общем, в первую очередь я отреагирую, любым из адекватных вариантов поведения. Сам собой напрашивается вопрос – зачем мне одна и та же логика принятия решения на “Реагировать на выстрел”, да еще и в каждом из состояний, в котором я могу пребывать в это время?
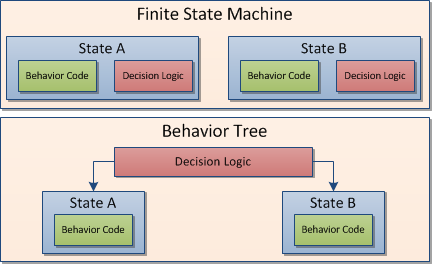
Изобр. 2 – В случае “behavior tree”, логика принятия решений отделена от кода самого состояния
Вот в чем сила
Главным преимуществом такого подхода становится то, что вся логика принятия решений находится в одном месте. Мы можем сделать ее настолько сложной и запутанной, насколько захочется, — и нам не придется переживать при этом насчет обязательной синхронизации между различными состояниями. Если мы добавляем новое поведение, то мы добавляем код для его вызова в одно место вместо того, чтобы проходить по всем существующим состояниям. Если же нам надо отредактировать логику перехода для определенного поведения, то это тоже надо будет сделать всего в одном месте.
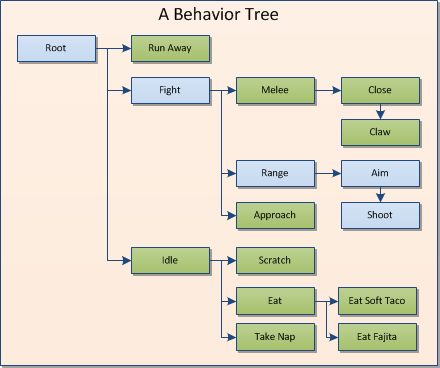
Изобр. 3 — Простое “behavior tree”. На данный момент, агент принял решение произвести дальнюю атаку
Другим преимуществом применения “behavior tree” служит то, что это очень формальный метод построения поведения. При помощи набора инструментов, шаблонов и структур могут быть реализованы очень интересные и выразительные поведения – даже последовательные поведения, которые связаны и должны происходить друг за другом (изобр. 3). В этом кроется одна из причин того, что именно дерево поведения стало одним из частых выборов для архитектур AI в современных играх – ее использовали и в Halo 2-3, и в Spore.
Подробное разъяснение того, как работают «behavior tree», как их строить и как они реализуются в коде, выходит за рамки этой статьи. Скажем только, что в их случае вероятность того, что оболочка все-таки разорвется и содержимое высыпется вам на колени, крайне мала. А поскольку риск подобной катастрофы становится намного меньше в то время, как структура становится более стройной, то вы сможете “положить” внутрь гораздо больше поведенческого содержимого.
Всем, кого заинтересовали «behavior tree», я настоятельно рекомендую изучить статью Бьорна Кнафла “Introduction to Behavior Trees” из блога #AltDevBlogADay.
Гибридное тако, или иерархический конечный автомат
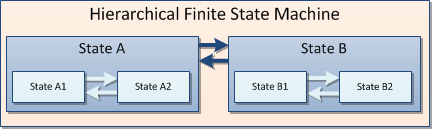
Изобр. 4 – В иерархической FSM некоторые из состояний содержат другие состояния, что делает управление связанными состояниями удобнее
Небольшое замечание, после которого мы навсегда оставим землю тако. Одно из преимуществ “behavior tree” — точнее говоря, его древовидная структура — иногда применяется и к конечному автомату. В иерархическом конечном автомате (HFSM) есть несколько уровней состояний. Тогда состояния верхнего уровня будут заняты взаимодействиями только с состояниями своего уровня. С другой стороны, состояния нижнего уровня, находящиеся внутри родителя, могут переходить только друг в друга. Подобное многоуровневое разделение ответственности придает плоскому FSM дополнительную организацию и позволяет взять часть сложности под контроль.
Если переложить HFSM на лад наших мексиканских метафор, то мы получим нечто, схожее с одним из твердых тако, обернутых в оболочку от мягкого тако. В нем по-прежнему не так много места для содержимого, однако все это хотя бы уже не стремится вывалиться наружу.
Создание «с нуля» — Планирование вашей фахиты

Если вы похожи характером на мою жену, то вам захочется получить в свои руки возможность самостоятельно выбирать, чего бы вы хотели увидеть в мексиканском блюде – не весь набор вместе, а каждый отдельный ингредиент. Вот почему она обычно заказывает фахиту. В то время, как фахита выглядит похожей на тако, да и «ведет себя» так же (особенно как тот вариант, что с мягкой оболочкой), метод ее сборки иной. Вместо того, чтобы отдать вам в руки уже готовую «конструкцию», вас обслужат совсем по-другому – принесут лепешки и пару тарелок с будущим содержимым блюда. Таким образом, вы сможете сами собрать себе персональное блюдо. Вы можете выбрать то, что в нем будет лежать первым и что пойдет дальше. Итог полностью зависит от того, чего вам хочется здесь и сейчас.
Эквивалентом в мире AI является планировщик (planner). Пусть результатом работы планировщика и является состояние (как и в случае FSM или «behavior tree»), принцип того, как он добирается до состояния, заметно отличается от уже описанных.
Как и в случае «behavior tree», толчком к использованию планировщика в качестве архитектуры служит отделение AI от кода, который «делает все остальное». Планировщик сравнивает свою ситуацию – состояние мира в определенный момент – с коллекцией индивидуальных атомарных действий, которые он может сделать. Следом он объединяет одну или несколько этих задач в последовательность («план»), так чтобы его текущая цель была достигнута.
В отличие от других архитектур, которые “идут” от своего текущего состояния и смотрят “вперед”, планировщик работает в обратном направлении от своей цели (изобр. 5). Например, если целью является “убить игрока”, то планировщик может выяснить, что подходящим методом для данной цели будет “пристрелить игрока”. Конечно же, для этого потребуется ружье. Если у агента не окажется ружья, то ему надо будет его найти. Если поблизости ничего такого нет, тогда ему придется пойти туда, где по его сведениям оно есть. Если он ничего такого не знает, то стоит начать поиски. Результатом поиска в обратном порядке станет план, который выполняется в прямом порядке. Конечно же, если другим методом для достижения цели «убить игрока» будет метание Тако Силы, а агент уже держит его в руке, то тут вряд ли стоит долго думать – лучше швырнуть названное тако в противника.

Изобр. 5 – Планировщик нашел два различных метода достижения цели “убить игрока” и выбрал самый короткий путь.
Планирование расходится с FSM и BT в том, что, в отличие от них, в нем нет жесткого управления действиями. В этом и заключается разница между планировщиками – они находят решение для ситуаций, основываясь на том, что можно сделать и как эти возможные действия могут быть связаны между собой. Прелесть использования подобной структуры состоит в том, что при возникновении новых производных ситуаций она зачастую самостоятельно найдет способ действия, а программист и дизайнер смогут вздохнуть спокойно – ведь им не придется прописывать все поведение в коде или скриптовых правилах.
С точки зрения реализации, главным плюсом планировщика является то, что новое действие может быть добавлено прямо в игру и архитектура сможет распознать, как его надо использовать. Такая возможность значительно ускоряет разработку. Все, что требуется от автора – это сказать “вот то, что ты можешь сделать… так берись и делай”.
Недостаток архитектуры уже очевиден, это заметное уменьшение контроля со стороны автора. В случае FSM или BT, творческие решения были исключением из предсказуемых, управляемых вручную систем. При использовании планировщика теперь уже скриптовые моменты становятся исключениями; придется либо обхитрить, либо заставить планировщик услышать ваш приказ «нет… на самом деле, я хочу, чтобы ты сделал сейчас именно это».
Архитектуры, основанные на планировщике, используются реже, чем «behavior tree», но их неоднократно использовали в известных играх. Самый известный пример – это хоррор-шутер от Monolith, F.E.A.R. Джефф Оркин назвал свою систему Целеориентированным планированием действий (Goal-Oriented Action Planning, GOAP). За подробностями — добро пожаловать на страницу Джеффа.
Более свежим примером использования планировщика можно назвать серию Killzone. В частности, в Killzone 2 была использована иерархическая сеть задач (HTN). Подробности можно прочитать здесь.
Собираем все в миску и получаем салат из полезностей

Переходим к следующей архитектуре — подходу, который менее структурирован, чем FSM или BT, и получил популярность в последние годы. Его принято называть “методом оценки полезности” (“utility-based”). Как и в случае планировщика, эта система не имеет предопределенных действий. Вместо этого, решения о потенциальных действиях принимаются на основании взвешивания факторов – почему это хорошо? почему это плохо? – и выбором самого подходящего решения. Сильно смахивает на привычный нам планировщик, в котором сделали небольшое изменение – теперь AI сам решает, как ему будет поступить лучше сейчас.
Вместо того, чтобы строить план, как это сделал бы планировщик-фахита, подобная система просто выберет следующий возможный шаг. Вот почему лучшим сравнением для нее будет салатом из тако, который положили в большую чашу. Там все ингридиенты перемешаны между собой и одинаково доступны в любой момент времени. Однако, вы просто выбираете, во что хотите ткнуть вилкой или палочкой и съедаете это. Вам хочется вот тот кусочек курочки? Оливку? Кусочек салата? Выбирайте все, что вы хотите – хотите прямо сейчас.
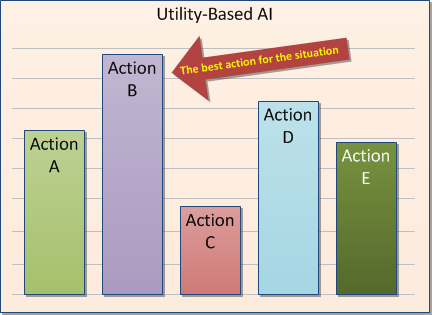
Изобр. 6 – Обыкновенная система с оценкой полезности взвешивает все возможные действия по различным критериям и выбирает лучший.
Одним из самых очевидных примеров подобной системы AI это The Sims. Ее следы там долго искать не придется – достаточно будет просто взглянуть на интерфейс. Вкратце, все выглядит так: каждое потенциальное действие в игре основано на комбинации текущих потребностей агента и возможности удовлетворить нужную потребность выбранным предметом или действием. Затем агент прибегает к традиционному для этой архитектуры подходу и взвешивает все суммы для определения «лучшего» на текущий момент действия. Выигрывает действие с наивысшим рейтингом (изобр. 6).
Несмотря на то, что системы с оценкой полезности можно использовать для разных типов игр, лучше всего они подходят для ситуаций, где есть большой выбор из потенциальных действий одного плана, которые может предпринять AI – и зачастую среди них нет очевидного, «правильного» ответа. В таком случае применение подобной архитектуры AI и ее математического подхода становится оправданным и даже необходимым. Определять самое «разумное» действие приходится не только в The Sims – система успешно применяется и в RPG, и в RTS, и в симуляторах.
Как и в случае с «behavior tree» или планировщиками, система с оценкой полезности действия полагается на реакции на события. После того, как действие выбрано, агент будет должен выполнить переход в это состояние, ну а на плечах системы лежит ответственность за выбор, какое состояние станет следующим. Однако, код принятия решений, как и в случае предыдущих архитектур, будет содержаться в одном месте. Это делает настройку и изменение системы заметно удобнее, да и преимущество планировщика в плане простоты добавления новых поведений тоже сохраняется. При добавлении поведения с уже распределенными весами, AI автоматически принимает его во внимание и начинает использовать в необходимых ситуациях. Вот почему все игры серии The Sims так расширяемы – новые объекты, отражающие поведение, просто включаются в готовую систему логики решений, при этом никаких изменений в уже созданном коде не требуется.
С другой стороны, недостаток подобной системы как раз в том, что не всегда возможно предсказать, что в конечном результате произойдет. В случае с деревом BT можно легко совершить его обход и найти ветви и узлы, которые будут активны в конкретной ситуации. В случае с нашей системой ее решения сложно представить в двоичном виде “да — нет”, и определение ее поведения становится задачей нетривиальной. Все это не к тому, что в подобной системе AI будет неконтролируемым или неконфигурируемым. На самом деле, такие системы наоборот предоставляют глубокий уровень контроль. Разница в том, что вместо того, чтобы под вашим чутким командованием выбирать, что стоит делать в конкретной ситуации, система сама предлагает возможные варианты – и эта способность может оказаться неплохим вариантом для AI игрового проекта. В этом плане система с оценкой полезности имеет общие черты с планировщиками – AI просто смотрит на доступные возможности и затем решает, какие из них подходят лучше всего.
За дальнейшей информацией по теме рекомендую обратиться к моей книге ”Behavioral Mathematics for Game AI”, или, если у вас есть доступ к GDC Vault, то вы можете просмотреть мои лекции на AI Summit (вместе с Kevin Dill) от 2010 и 2012, “Improving AI Decision Modeling through Utility Theory” и “Embracing the Dark Art of Mathematical Modeling”.
Заворачивается все! или буррито нейросетей

Моя буйная фантазия подошла к концу, и нам осталось обсудить буррито. В других примерах все содержимое было доступно для взгляда и открыто. В случае с фахитой, вы (как пользователи AI) могли сами собрать то, чего бы вам хотелось получить на каждой “итерации” процесса. В салате из тако, твердых и мягких тако, и даже в случае тостады вы могли “приправить их по вкусу”. Добавить еще немножко сыра сверху? Или кетчупа? Даже если бы вы не могли увидеть содержимое, вы могли хотя бы взглянуть на то, что вы можете съесть перед тем, как откусите в первый раз. Загадки в том, из чего состоит ваш обед, никогда не было – все было как на ладони.
А вот с буррито вас ждет совсем другая история. Буррито должен быть свернут, а детали его «устройства» — спрятаны от нашего взгляда. И, хотя буррито (как и нейронная сеть) очень гибок, вы никогда не будете уверены в том, что вы ощутите со следующим укусом. Не нравится сметана? Или не любите оливки? Хехе, уже поздно – вы уже откусили. Хотите исправить положение? Разверните ваш буррито, вытаскивайте все лишнее и сворачивайте заново, «с чистого листа».
Тем же самым рискует и покупатель, отважившийся на использование в своем проекте AI на основе нейросети. Так как работа нейросети основана на «обучении», то для нее потребуются реальные данные или тесты. Рано или поздно наступит момент, когда вы решите закончить обучение и сказать «Вот что у меня получилось». Если к вам на огонек зайдет дизайнер, заглянет через плечо и скажет «Выглядит неплохо, но ты знаешь, в [случае] я бы хотел чтобы [вот это действие] повторялось чуть чаще», то знайте, что вы попали – вы ничего не сможете изменить. Вы уже свернули свой буррито. Вам остается только попытаться заново обучить нейросеть и верить в лучшее.
В этом и есть суть всех недостатков нейросетей. Несмотря на достоинства – вы можете сложить в нее огромное количество поведений, получив целый коктейль возможностей – невозможность контролировать их может свести с ума. И, к сожалению, этот недостаток выводит нейросеть из игры – как и другие решения, основанные на машинном обучении, которые не приспособлены для игрового AI, где немалая степень контроля происходящего на экране не просто желательна, а практически всегда необходима.
Тем не менее, история знает несколько примеров удачного использования нейросетей в играх – например, Майкл Роббинс использовал нейросети для улучшения тактического AI в Supreme Commander 2 от Gas Powered Games (на GDC Vault есть лекция про это с AI Summit, ищите “Off the Beaten Path: Non-Traditional Uses of AI”.)
Подведение итогов
Вот мы и подошли к концу нашего кулинарного путешествия-исследования архитектур игрового AI. Вспомним напоследок, с чего оно начиналось.
Чем дальше в лес (и чем больше «содержимого»), тем больше одна архитектура начинает напоминать другую. Разница в том, как будет упаковано «содержимое» – нас интересует его форма, ее «за» и «против». Мой обзор трудно назвать исчерпывающим – он очень далек от этого. Моей целью было показать возможные варианты и предположить, по какой из причин вы можете выбрать тот или другой вариант. А теперь давайте на всякий случай пройдемся по всем блюдам еще раз…
Вы можете просто разбросать правила поведения по вашему исходному коду – но это будет никакая не “архитектура”. Если вы хотите собрать ваш AI в логичные блоки, то вы можете создать конечный автомат (FSM). FSM прост в своей конструкции и легко доступен для понимания (в том числе и не-программистам). Для небольшого числа простых агентов с небольшим числом поведений это отличный вариант, а вот как только их становится больше, начинается настоящая головная боль. Если вы распределите состояния по уровням, то получите иерархический конечный автомат (HFSM), что поможет вам избежать части этих проблем.
Хотите получить еще больше гибкости? Уберите код, который отвечает за проведение рассуждений, из кода самих состояний. Хотите, чтобы дизайнеру или сценаристу стал понятен ваш AI? Организуйте его в «behavior tree» — поведенческие деревья очень наглядны. Но главное преимущество BT все же не в этом – и вы поймете это, когда вам придется «масштабировать» свой AI. Если в обычном случае вам придется проделать много дополнительной работы, то в случае BT вы с легкостью сможете добавить новые ветки и узлы. Однако, несмотря на надежность и удобность реализации BT, он пока еще сохраняет преимущество управляемости – потому что состоит из классических жестких правил класса «если X, то делай Y».
Как и «behavior tree», планировщик — очень удобное и гибкое средство, что пригодится любому автору. Но если BT руководствуется строгими правилами, то планировщик просто «разрешает» ту или иную ситуацию, выбирая поведение, которое на его взгляд лучше ей соответствует. Подобная особенность может быть полезной, но вот гейм-дизайнерам есть чего опасаться – их степень контроля над ситуацией резко падает.
То же самое касается и систем, основанных на оценке полезности, которые отходят от скриптового подхода и позволяют персонажам самостоятельно решать, куда и зачем им идти – что порядком смущает гейм-дизайнеров. Такие системы можно расширить до огромного числа сложных правил срабатывания и возможных решений. Тем не менее, догадаться, что же произойдет в той или иной ситуации, временами становится практически невозможно, — хотя возможно создать инструменты, которые помогут с этой проблемой.
Для тех, кто не боится трудностей, есть еще вариант “черного ящика” – это нейронная сеть. Даже программисты не всегда уверены в том, что творится в ее маленьких нейронах… В чем же ее преимущество? В том, что нейросеть может обучиться тому же, что умеет человек-игрок. Есть жанры игр, в которых подобное поведение просто необходимо. К тому же, их чуть проще создавать, ведь вам нужно лишь разработать принцип обучения и обучить ее.
И не ждите простого ответа – ведь в вашем случае единственного и “правильного” ответа нет. Более того, вам никто не мешает использовать сразу несколько архитектур в одной игре. Ваш выбор будет зависеть от того, что вам нужно, от вашей команды и прошлого опыта разработки игр – и один из перечисленных выше путей в итоге окажется именно тем, что вам нужно.
Как и в любом техническом вопросе, если можно что-то попробовать – то это нужно попробовать, и только потом решать, что из этого выбрать. Даже если вас хватит только на то, чтобы набросать пару небольших примеров. Запомните: вы ищете то, что вам понравится, а моя роль – лишь помочь с пониманием того, чего же вам хочется на самом деле.
А теперь… кушать подано!

