В этой статье пойдет речь о том, как решалась небольшая задачка поиска дубликатов по фрагменту или кропу картинки.

Есть у меня один могильничек где пользователи иногда добавляют, по их мнению, красивые картинки.
Которые потом модерируются самими пользователями.
И бывают случаи когда одна и таже картинка добавляется несколько раз. Что решалось обычно вместе с постмодерацией.
Но пришло время, когда стало непросто каждый раз проверять была ли уже загружена подобная или такая же картинка.
И появилась идея, что пора присмотреться к автоматическому поиску дубликатов.
Вначале взор пал на SURF дескрипторы, которые давали очень неплохие результаты.
Но из-за сложности проверки на совпадения с коллекцией картинок решил не спешить и посмотреть на другие решения.
Интуитивно хотелось бы выделить какие-то признаки у картинки, на подобие SIFT/SURF дескрипторов, но с возможностью быстрой проверки на совпадение.
После небольших усилий, столкнулся с идеей перцептуальных хешей.
Они казались достаточно простыми как для создания, так и для поиска по базе.
Вкратце, перцептуальный хеш — это свертка каких-то признаков, которые описывают картинку.
Основное достоинство таких хешей в том, что их просто сравнивать с другими хешами с помощью расстояния Хэмминга.
Идеально если расстояние хешей двух картинок равно нулю. Тогда значит, что эти картинки (скорее всего) идентичны.
Особенно подкупало, что это расстояние можно было считать с помощью не сильно сложного SQL запроса:
Осталось разобраться каким образом лучше получать такие хеши.
В последующей статье было дано описания трех способов выделения такого типа хешей.
Кроме самого простого алгоритма проверки на среднее значение, которое было названо aHash (Average Hash) и наиболее актуального варианта реализованного в проекте с открытым исходным кодом pHash (Perceptual Hash), было дано еще одно описание — dHash (Difference Hash), предложенный David Oftedal, а именно сравнение не со среднем значением пикселей, а с предыдущем.
После некоторых тестов выяснилось, что
aHash неработоспособный и дает огромное количество ложных срабатываний,
dHash работает на порядок лучше, но все равно неудовлетворительно много ошибок,
pHash показал себя лучше всех с наиболее актуальными результатами, но больше чувствителен к модификациям картинки.
В общем случае pHash способен проверить идентичность картинки даже если на нее была нанесена небольшая копирайт метка. Нечувствителен к цвету, контрастности, яркости, размеру и даже к слабым геометрическим изменениям.
При всех подобных достоинствах, есть вполне законное ограничение: хеш описывают всю картинку и больше предназначен для поиска полного дубликата.
Другими словами такие хеши неактуальны при задачах поиска дубликатов картинок с кропом, модификациями с масштабом, размером сторон картинок либо непосредственно частичного или серьезного вмешательства в содержание картинки.
После небольшого анализа ситуации, пришел к выводу, что вряд ли пользователи будут добавлять картинки с модификациями содержания.
Например, дорисовывать цветочек, огромную мокрую метку или менять фотографию как-то по-другому.
А вот добавления картинок с кропом вполне реально. Например, вырезать важную часть, изменить соотношение сторон, увеличить что-то и тд.
Поэтому, кроме проверки на полное либо частичное совпадение, нужно было проверять на кроп, по крайней мере, небольшой.
Один хеш на одну картинку целесообразно неспособен решить подобную задачу.
Но, из-за простоты реализации таких хешей, хотелось немного подумать каким образом можно обойти это ограничение и найти кроп изображения с их помощью.
Раз один хеш не годится, надо бы получать список хешей. Где каждый хеш описывает только свою часть изображения.
Но как нам узнать где и как резать картинку?
Вот тут и пригодилось получение локальных признаков с помощью SURF.
Другими словами нужно было как-то вырезать картинки по найденным точкам.

рис 1. Найденные точки с запрашиваемого изображения

рис 2. Найденные точки из сохраненного изображения
Так как нам требуется порезать картинку таким образом, чтобы совпали (хотя бы немного) похожие области, была испробована k-means кластеризация ключевых точек (фич).
Казалось, что если картинка сильно не менялась в содержании и найденные локальные признаки остаются почти неизменными, то наверное центроиды после кластеризации этих локальных точек тоже должны примерно совпадать.
Это и есть основная идея данного подхода.

рис 3. Точкой показан центр одного кластера

рис 4. Точки описывают центры трех кластеров. Если присмотреться, то верхний центроид почти совпадает с центром из рис 3.
Что бы найти такие центроиды, которые примерно будут сходиться, нужно было произвести кластеризацию, например, 20 раз, меняя количество кластеров.
И резать можно было по крайним точкам каждого кластера.
При пределе в 20 кластеров получается 21*20/2 = 210 центроидов. И всего хешей на одну картинку 210 + хеш полной картинки = 211 хешей.
Но мы отбрасываем вырезки меньше чем 32 пикселя и в итоге получается, например, 191 хешей.
Такой подход показал результаты лучше, чем просто сравнение хешей полных картинок, но все равно оказался неудовлетворительным из-за явных промахов. Вроде бы визуально нарезки совпадают, но проверка их хешей проваливается.
Тут уже и подкралась идея бросить эту затею и копать в другом направлении.
Но, напоследок, решил проверить какую роль играет фиксированный формат сторон или координат. И оказалось, что это позволило увеличить количество совпадений.
Методом тыка подобрал, что бы координата вырезаемой картинки была кратна восьми.

рис 5. Вырезанные совпадающие картинки методом кластеризации
Далее необходимо было проверить работоспособность подобной модели на практике.
Быстренько было все перенесено в могильничек с картинками и проиндексирована вся база.
Получилось 1 235 картинок и 194 710 хешей в базе.
И тут оказалось, что BIT_COUNT( hash1 ^ hash2 ) довольно дорогая операция и требует дополнительного внимания.
И выполнять 200 запросов занимает больше времени нежели выполнить один большой запрос со всеми 200 хешами сразу.
На моем слабеньком сервере такой большой запрос выполняется не меньше 2 секунд.
Всего на поиск одной картинки требуется 200 * 194 710 = 38 942 000 операций по подсчету расстояния Хэмминга.
Поэтому решил проверить какая будет разница если написать свою реализацию вычисления расстояния в MySQL.
Разница оказалась незначительная и, более того, не в пользу пользовательских функций.
Ради интереса попробовал реализовать поиск по коллекции хешей на C++.
Где идея до невозможности проста: получить весь список хешей из базы и пройтись по ним, раcсчитав расстояние вручную.
И такая идея отрабатывает в два раза быстрее, чем через SQL запрос.
Далее, из-за большого количества хешей, потребовалось сформулировать правила определения дубликатов.
Например, если совпал один хеш из двухсот, считать картинку дубликатом? Наверное нет.
Также нашлись случаи когда больше 20% хешей совпало, но картинка точно не является дубликатом.
А бывает и 10% совпадений, но является дубликатом.
Так что количество только найденных хешей к общему числу не является гарантией проверки.
Чтобы отфильтровать заведомо неверные совпадения было использовано вычисление SURF дескрипторов найденных картинок и подсчет количества совпадений с запрашиваемой.
Что позволило показывать актуальные результаты, но требует дополнительного времени обработки. Скорее всего есть более оптимальные варианты.
Такой подход позволил находить кропнутые в разумных пределах картинки за удовлетворительное время.
Хотя является далеко не оптимальным и оставляет множество возможностей для маневров или оптимизаций (например, вполне целесообразно проверить хеши после кластеризации и отбросить дубликаты, что сократит количество хешей в два, а может и больше раз).
Но, надеюсь, интересен для простого любопытства, хоть и неакадемического.
habrahabr.ru/post/120562 — Описание хешей, перевод
ru.wikipedia.org/wiki/Расстояние_Хэмминга — Расстояние Хэмминга
en.wikipedia.org/wiki/SURF — SURF ключевые точки
ru.wikipedia.org/wiki/K-means — Кластеризация
phash.org — pHash проект
www.hackerfactor.com/blog/index.php?/archives/529-Kind-of-Like-That.html — Сравнение видов хешей
01101001.net/differencehash.php — Difference Hash
github.com/valbok/img.chk/blob/master/bin/example.py — Мой вариант реализации выделения хешей из изображения
github.com/valbok/leie/blob/master/classes/image/leieImage.php — Еще один мой вариант хешей, но на PHP

Предисловие
Есть у меня один могильничек где пользователи иногда добавляют, по их мнению, красивые картинки.
Которые потом модерируются самими пользователями.
И бывают случаи когда одна и таже картинка добавляется несколько раз. Что решалось обычно вместе с постмодерацией.
Но пришло время, когда стало непросто каждый раз проверять была ли уже загружена подобная или такая же картинка.
И появилась идея, что пора присмотреться к автоматическому поиску дубликатов.
Расследование
Вначале взор пал на SURF дескрипторы, которые давали очень неплохие результаты.
Но из-за сложности проверки на совпадения с коллекцией картинок решил не спешить и посмотреть на другие решения.
Интуитивно хотелось бы выделить какие-то признаки у картинки, на подобие SIFT/SURF дескрипторов, но с возможностью быстрой проверки на совпадение.
После небольших усилий, столкнулся с идеей перцептуальных хешей.
Они казались достаточно простыми как для создания, так и для поиска по базе.
Вкратце, перцептуальный хеш — это свертка каких-то признаков, которые описывают картинку.
Основное достоинство таких хешей в том, что их просто сравнивать с другими хешами с помощью расстояния Хэмминга.
Идеально если расстояние хешей двух картинок равно нулю. Тогда значит, что эти картинки (скорее всего) идентичны.
Особенно подкупало, что это расстояние можно было считать с помощью не сильно сложного SQL запроса:
SELECT * FROM image_hash WHERE BIT_COUNT( 0x2f1f76767e5e7f33 ^ hash ) <= 10Осталось разобраться каким образом лучше получать такие хеши.
В последующей статье было дано описания трех способов выделения такого типа хешей.
Кроме самого простого алгоритма проверки на среднее значение, которое было названо aHash (Average Hash) и наиболее актуального варианта реализованного в проекте с открытым исходным кодом pHash (Perceptual Hash), было дано еще одно описание — dHash (Difference Hash), предложенный David Oftedal, а именно сравнение не со среднем значением пикселей, а с предыдущем.
После некоторых тестов выяснилось, что
aHash неработоспособный и дает огромное количество ложных срабатываний,
dHash работает на порядок лучше, но все равно неудовлетворительно много ошибок,
pHash показал себя лучше всех с наиболее актуальными результатами, но больше чувствителен к модификациям картинки.
В общем случае pHash способен проверить идентичность картинки даже если на нее была нанесена небольшая копирайт метка. Нечувствителен к цвету, контрастности, яркости, размеру и даже к слабым геометрическим изменениям.
При всех подобных достоинствах, есть вполне законное ограничение: хеш описывают всю картинку и больше предназначен для поиска полного дубликата.
Другими словами такие хеши неактуальны при задачах поиска дубликатов картинок с кропом, модификациями с масштабом, размером сторон картинок либо непосредственно частичного или серьезного вмешательства в содержание картинки.
Попытка решения
После небольшого анализа ситуации, пришел к выводу, что вряд ли пользователи будут добавлять картинки с модификациями содержания.
Например, дорисовывать цветочек, огромную мокрую метку или менять фотографию как-то по-другому.
А вот добавления картинок с кропом вполне реально. Например, вырезать важную часть, изменить соотношение сторон, увеличить что-то и тд.
Поэтому, кроме проверки на полное либо частичное совпадение, нужно было проверять на кроп, по крайней мере, небольшой.
Один хеш на одну картинку целесообразно неспособен решить подобную задачу.
Но, из-за простоты реализации таких хешей, хотелось немного подумать каким образом можно обойти это ограничение и найти кроп изображения с их помощью.
Раз один хеш не годится, надо бы получать список хешей. Где каждый хеш описывает только свою часть изображения.
Но как нам узнать где и как резать картинку?
Вот тут и пригодилось получение локальных признаков с помощью SURF.
Другими словами нужно было как-то вырезать картинки по найденным точкам.
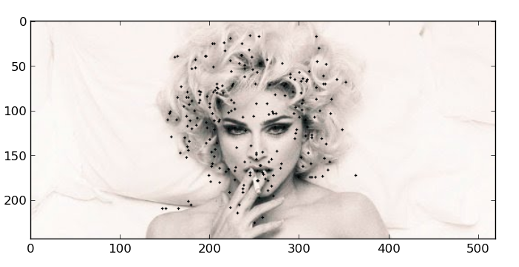
рис 1. Найденные точки с запрашиваемого изображения

рис 2. Найденные точки из сохраненного изображения
Так как нам требуется порезать картинку таким образом, чтобы совпали (хотя бы немного) похожие области, была испробована k-means кластеризация ключевых точек (фич).
Казалось, что если картинка сильно не менялась в содержании и найденные локальные признаки остаются почти неизменными, то наверное центроиды после кластеризации этих локальных точек тоже должны примерно совпадать.
Это и есть основная идея данного подхода.

рис 3. Точкой показан центр одного кластера

рис 4. Точки описывают центры трех кластеров. Если присмотреться, то верхний центроид почти совпадает с центром из рис 3.
Что бы найти такие центроиды, которые примерно будут сходиться, нужно было произвести кластеризацию, например, 20 раз, меняя количество кластеров.
И резать можно было по крайним точкам каждого кластера.
При пределе в 20 кластеров получается 21*20/2 = 210 центроидов. И всего хешей на одну картинку 210 + хеш полной картинки = 211 хешей.
Но мы отбрасываем вырезки меньше чем 32 пикселя и в итоге получается, например, 191 хешей.
Такой подход показал результаты лучше, чем просто сравнение хешей полных картинок, но все равно оказался неудовлетворительным из-за явных промахов. Вроде бы визуально нарезки совпадают, но проверка их хешей проваливается.
Тут уже и подкралась идея бросить эту затею и копать в другом направлении.
Но, напоследок, решил проверить какую роль играет фиксированный формат сторон или координат. И оказалось, что это позволило увеличить количество совпадений.
Методом тыка подобрал, что бы координата вырезаемой картинки была кратна восьми.

рис 5. Вырезанные совпадающие картинки методом кластеризации
Прототип
Далее необходимо было проверить работоспособность подобной модели на практике.
Быстренько было все перенесено в могильничек с картинками и проиндексирована вся база.
Получилось 1 235 картинок и 194 710 хешей в базе.
И тут оказалось, что BIT_COUNT( hash1 ^ hash2 ) довольно дорогая операция и требует дополнительного внимания.
И выполнять 200 запросов занимает больше времени нежели выполнить один большой запрос со всеми 200 хешами сразу.
На моем слабеньком сервере такой большой запрос выполняется не меньше 2 секунд.
Всего на поиск одной картинки требуется 200 * 194 710 = 38 942 000 операций по подсчету расстояния Хэмминга.
Поэтому решил проверить какая будет разница если написать свою реализацию вычисления расстояния в MySQL.
Разница оказалась незначительная и, более того, не в пользу пользовательских функций.
Ради интереса попробовал реализовать поиск по коллекции хешей на C++.
Где идея до невозможности проста: получить весь список хешей из базы и пройтись по ним, раcсчитав расстояние вручную.
Пример расчета расстояния Хэмминга на С++
typedef unsigned long long longlong;
inline longlong hamming_distance( longlong hash1, longlong hash2 )
{
longlong x = hash1 ^ hash2;
const longlong m1 = 0x5555555555555555ULL;
const longlong m2 = 0x3333333333333333ULL;
const longlong h01 = 0x0101010101010101ULL;
const longlong m4 = 0x0f0f0f0f0f0f0f0fULL;
x -= (x >> 1) & m1;
x = (x & m2) + ((x >> 2) & m2);
x = (x + (x >> 4)) & m4;
return (x * h01)>>56;
}
И такая идея отрабатывает в два раза быстрее, чем через SQL запрос.
Далее, из-за большого количества хешей, потребовалось сформулировать правила определения дубликатов.
Например, если совпал один хеш из двухсот, считать картинку дубликатом? Наверное нет.
Также нашлись случаи когда больше 20% хешей совпало, но картинка точно не является дубликатом.
А бывает и 10% совпадений, но является дубликатом.
Так что количество только найденных хешей к общему числу не является гарантией проверки.
Чтобы отфильтровать заведомо неверные совпадения было использовано вычисление SURF дескрипторов найденных картинок и подсчет количества совпадений с запрашиваемой.
Что позволило показывать актуальные результаты, но требует дополнительного времени обработки. Скорее всего есть более оптимальные варианты.
Эпилог
Такой подход позволил находить кропнутые в разумных пределах картинки за удовлетворительное время.
Хотя является далеко не оптимальным и оставляет множество возможностей для маневров или оптимизаций (например, вполне целесообразно проверить хеши после кластеризации и отбросить дубликаты, что сократит количество хешей в два, а может и больше раз).
Но, надеюсь, интересен для простого любопытства, хоть и неакадемического.
Ссылки
habrahabr.ru/post/120562 — Описание хешей, перевод
ru.wikipedia.org/wiki/Расстояние_Хэмминга — Расстояние Хэмминга
en.wikipedia.org/wiki/SURF — SURF ключевые точки
ru.wikipedia.org/wiki/K-means — Кластеризация
phash.org — pHash проект
www.hackerfactor.com/blog/index.php?/archives/529-Kind-of-Like-That.html — Сравнение видов хешей
01101001.net/differencehash.php — Difference Hash
github.com/valbok/img.chk/blob/master/bin/example.py — Мой вариант реализации выделения хешей из изображения
github.com/valbok/leie/blob/master/classes/image/leieImage.php — Еще один мой вариант хешей, но на PHP
