
Привет, Хабр.
Мир javascript развивается с невероятной скоростью: новые стандарты языка, новые фреймворки, и в браузере, и на сервере и в десктопных приложениях и так далее… Но иногда хочется вместо изучения новой супер-фичи погрузиться в какую-то более базовую тему. И погрузиться глубоко, до самых исходников.
И в этот момент под моим пристальным взглядом оказалась незаметная строчка «native code», которая так или иначе появляется перед глазами любого JS разработчика в консоли Chrome или Node.js:
[].sort.toString();
"function sort() { [native code] }"
Итак, кому интересно, какая реализация сортировки скрывается в V8 за надписью [native code] — добро пожаловать под кат.
Для изучения воспользуемся репозиторием v8-git-mirror на github. Здесь и далее я буду ссылаться на код из версии 4.6.9, которая была актуальна на момент написания статьи.
Репозиторий V8 велик, и я решил начал поиски с простой команды find:
find ./src -iname "*array*"
./src/array-iterator.js
./src/array.js
./src/arraybuffer.js
./src/harmony-array-includes.js
./src/harmony-array.js
...
Названия этих файлов будто знакомы. Кажется, нам нужен именно array.js. Что из себя представляет его содержимое?
В общем-то это обыкновенный код на js, за исключением различных макросов и define-ов, которые написаны в UPPERCASE и определены в файле macros.py, и вызовов функций, определенных уже где-то в недрах кода на C++, начинающиеся на % или $. Но не стоит пугаться, все не js-ное имеет вполне понятное назначения исходя из названия, например, %_CallFunction очевидно вызывает функцию и т.д. Так что продолжим поиск кода сортировки.
Начнем с конца, с того места, где метод сортировки добавляется в Array.prototype:
// Set up non-enumerable functions of the Array.prototype object and
// set their names.
// ...
utils.InstallFunctions(GlobalArray.prototype, DONT_ENUM, [
// ...
"sort", getFunction("sort", ArraySort),
"filter", getFunction("filter", ArrayFilter, 1),
"forEach", getFunction("forEach", ArrayForEach, 1),
// ...
]);
Ага, нам нужна функция ArraySort. Она определена в этом же файле:
function ArraySort(comparefn) {
CHECK_OBJECT_COERCIBLE(this, "Array.prototype.sort");
var array = $toObject(this);
var length = TO_UINT32(array.length);
return %_CallFunction(array, length, comparefn, InnerArraySort);
}
В ней проверяется может ли быть this преобразован к объекту (в соответствии со спецификацией), и если нет, то будет выброшено исключение TypeError. Затем this таки преобразуется в объект, длина конвертируется в uint32 и вызывается InnerArraySort. В этих 281 строчках и реализована сортировка в V8.
Как многие догадываются, это быстрая сортировка (quicksort) — один из самых распространенных неустойчивых алгоритмов внутренней сортировки со средней сложностью O(nlog n). Появилась в V8 быстрая сортировка не сразу, а 25 сентября 2008 года, заменив собой пирамидальную сортировку (heapsort), для улучшения производительности.
Не везде выбор сортировки остановился именно на quicksort; например, в SpiderMonkey (js движок Firefox) используется сортировка слиянием (merge sort) — исходники.
Чтобы изучать нюансы реализации дальше, неплохо бы вспомнить, что представляет из себя шаг алгоритма быстрой сортировки (упрощенно):
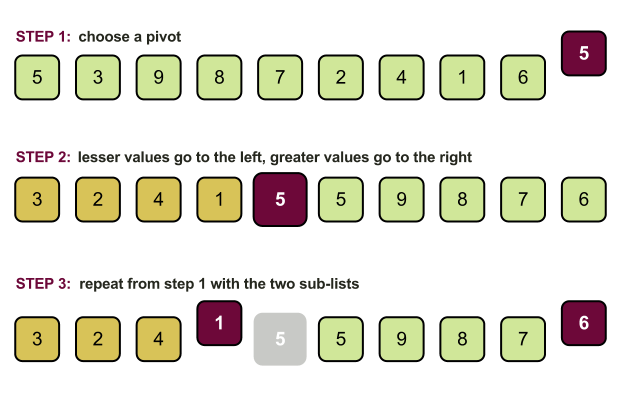
- Выбираем опорный элемент (pivot) из массива;
- Реорганизуем массив, приводим к виду: элементы меньшие pivot, pivot, элементы большие pivot;
- Повторяем рекурсивно для левой и правой частей массива.
С течением времени реализация сортировки внутри V8 обзавелась множеством различных оптимизаций. В первую очередь оптимизации связанны с методом выбора опорного элемента, хвостовой рекурсией и алгоритмом работы на массивах малого размера. Давайте рассмотрим их в порядке появления.
Первой доработкой было добавление сортировки вставками (Insertion sort) для массивов малого размера. Вот ее исходный код:
var InsertionSort = function InsertionSort(a, from, to) {
for (var i = from + 1; i < to; i++) {
var element = a[i];
for (var j = i - 1; j >= from; j--) {
var tmp = a[j];
var order = %_CallFunction(UNDEFINED, tmp, element, comparefn);
if (order > 0) {
a[j + 1] = tmp;
} else {
break;
}
}
a[j + 1] = element;
}
};
Разработчики долго не могли прийти к согласию, какой массив считать «малым». Много коммитов за прошедшие 7 лет уменьшали барьер (все началось с 22 элементов), и на данный момент сошлись на длине в 10 элементов.
Теперь о методе выбора опорного элемента, который также подвергся ряду изменений.
Первая реализация использовала случаный выбор индекса для опорного элемента (исходник):
var pivot_index = $floor($random() * (to - from)) + from;
Затем, был изменен на выбор медианы из трех (первый, последний и серединный элемент).
Но в конечном итоге простой выбор медианы из трех дополнился весьма необычным методом определения среднего элемента для медианы на больших массивах (свыше 1000 элементов). Из исходного массива выбираются элементы (с шагом чуть большее 200) и записываются в новый массив. Затем этот массив сортируется, и его средний элемент становится средним элементом для поиска медианы. Эта функция называется GetThirdIndex:
var GetThirdIndex = function(a, from, to) {
var t_array = [];
// Use both 'from' and 'to' to determine the pivot candidates.
var increment = 200 + ((to - from) & 15);
for (var i = from + 1, j = 0; i < to - 1; i += increment, j++) {
t_array[j] = [i, a[i]];
}
%_CallFunction(t_array, function(a, b) {
return %_CallFunction(UNDEFINED, a[1], b[1], comparefn);
}, ArraySort);
var third_index = t_array[t_array.length >> 1][0];
return third_index;
}
И, наконец, о рекурсии. Проблема базового алгоритма с двумя рекурсивными вызовами (на левую и правую части массива) заключается в том, что при неудачном выборе опорного элемента глубина рекурсии будет соизмерима с размером массива. Это не только значительно ухудшает скорость выполнения, но и выливается в оценку O(n) по памяти для худшего случая. В реализации сортировки для V8 эту проблему так же устранили: сортировка вызывается рекурсивно только для меньшего подмассива, а сортировка большего продолжается в основном цикле. Данная оптимизация гарантирует оценку потребления памяти O(log n). Обычно такую оптимизацию хвостовой рекурсии может выполнить компилятор, а в нашем случае с JS ее пришлось осуществить вручную.
Вот такая быстрая сортировка сейчас используется в V8. Но рассказ о сортировке в js движке был бы неполным без некоторых моментов, которые проще показать на примерах.
Начнем с общеизвестного. Что будет, если не передать функцию компаратор:
var arr = [1, 2, 11];
arr.sort();
[1, 11, 2]
В этом случае используется дефолтный компаратор, который сортирует в лексикографическом порядке:
comparefn = function (x, y) {
if (x === y) return 0;
if (%_IsSmi(x) && %_IsSmi(y)) {
return %SmiLexicographicCompare(x, y);
}
x = $toString(x);
y = $toString(y);
if (x == y) return 0;
else return x < y ? -1 : 1;
};
Следущий пример-загадка:
var arr = [2, undefined, 1];
arr.sort(function () {
return 0;
});
Ответ

[2, 1, undefined]

Wat? Но логика есть. Все потому, что перед сортировкой массив реорганизуется функцией SafeRemoveArrayHoles, а именно: все значимые элементы заменяют собой undefined-ы в начале массива, тем самым все undefined накапливаются в конце.
И напоследок, пожалуй, самое веселое. Array.prototype.sort сортирует не только массивы и объекты, подобные массивам. В сортировке могут принять участие даже значения из прототипа. Все недостающие свойства (от нуля до величины свойства length) будут скопированы (функция CopyFromPrototype) из прототипа в сам объект, а затем отсортированы:
function Arr() {
this[1] = 1;
}
Arr.prototype[0] = 2;
Arr.prototype.length = 2
var arr = new Arr();
Array.prototype.sort.call(arr, function (a, b) {
return a - b;
});
Arr {0: 1, 1: 2}
На этом описание сортировки можно завершать. Теперь мы знаем все, что на самом деле скрывается за надписью [native code], и можем сделать ряд полезных выводов:
- V8 пишут и улучшают обычные люди, такие же как мы с вами. Один и тот же кусок кода переписывался и дополнялся на протяжении 7 лет: не все оптимизации были применены сразу, и возможно эту реализацию можно еще как-то ускорить или переписать опять :)
- Как бы не улучшали методы поиска опорного элемента, эта процедура все равно зависит от входных данных. Случай «неудачного» выбора опорного элемента и последующая деградация производительности возможны. Вообще, стоит присмотреться именно к вашим входным данным, может для них выгоднее использовать, например, сортировку подсчетом;
- Быстрая сортировка — неустойчивая (пример от Waxer). А вот если нужна устойчивость, то можно поступить по разному. Можно дополнить элементы массива их первоначальным индексом и несколько изменить компаратор, чтобы он учитывал это. Либо же реализовать в js какую-нибудь устойчивую сортировку, например, Timsort. Но это все уже выходит за рамки этой статьи.
Надеюсь, читать это исследование вам было так же интересно, как мне его проводить. Удачи в изучении исходников!
