Рынок труда представляет собой классическое формирование спроса и предложения на рабочую силу. И если со стороны спроса на труд, многие кадровые агентства и порталы по поиску работы представляют собой некоторую аналитику по имеющимся предложениям (правда, не всегда в необходимом виде). То со стороны предложения (соискателей) аналитики гораздо меньше, да и та, что есть, не является универсальной для каждого, и чаще всего представляет собой просто срез по желаемому доходу в каких-то общих сферах, или просто по названию резюме.
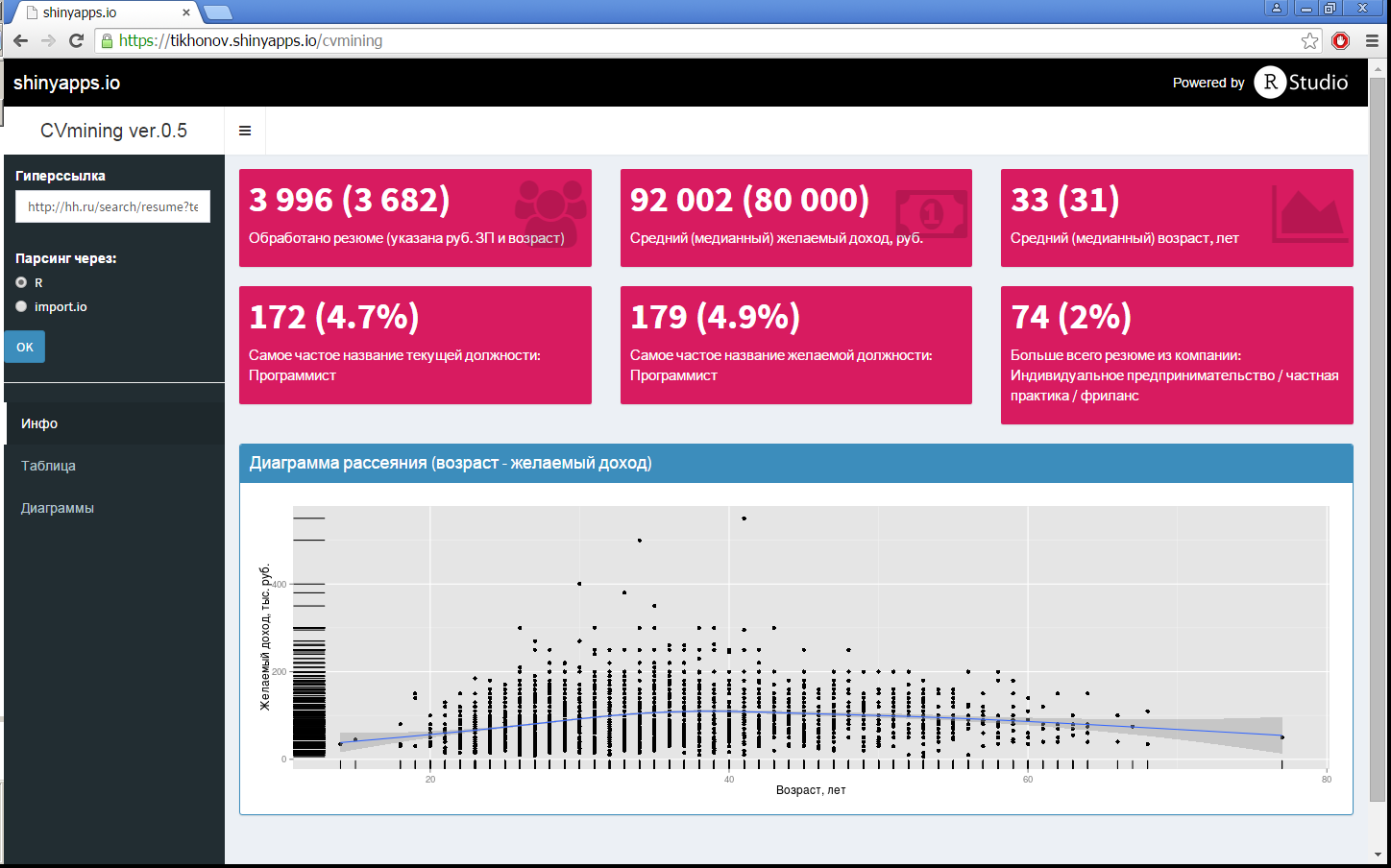
Мне же был интересен инструмент, который по произвольной выборке резюме (по названию, ключевым словам и прочее) показывал бы основные характеристики такой выборки, распределение зарплат, возрастов, и многое другое, как в графическом виде, так и виде произвольных перцентилей. Итог моего желания, ниже под катом.
Итак, для визуализации данных, нужны собственно данные, наиболее крупным источником таких данных является сайт HeadHunter. Зная, что у него есть API, я подумал, что вот сейчас то, с ним, быстро все получу, и не придется ничего парсить, но прочитав его описание, увидел, что доступ по нему к базе именно резюме можно получить только для работодателей, и более того, только для целей предложения работы. Но ничего, и в открытом доступе hh.ru есть раздел с резюме людей, которые открыли их всему Интернету, и их то мы видим, а их достаточно много, около трети от общего числа. Из этих людей нас интересует те, которые указали желаемый доход, а их подавляющее большинство – 80%.
В итоге сбор данных, реализовал двумя способами – сбором данных используя API import.io (первоначально, как более быстрый для реализации), и непосредственно сбор и парсинг осуществляется используя R, этот способ, в итоге оказался на 20% быстрее. Так максимальное число резюме — 5 000 (ограничение hh.ru) собираются за 3 минуты, но обычно в интересующем запросе их гораздо меньше, так что непосредственная временная разница между двумя способами сбора составляет несколько секунд.
Вероятнее всего, данная выборка, является смещенной, я исхожу из предположения, что люди в большинстве своем, открывающие резюме всему интернету, более заинтересованы в поиске работы, и вследствие этого, их ожидания по доходу, вероятнее всего несколько занижены. Но без доступа к полной базе, проверить эту гипотезу, нельзя, поэтому что есть, то есть.
Анализируя полученные результаты, всегда можно помнить об этой смещенности, и, например, накидывать несколько процентов на полученные результаты. Также решил дополнительно разделять выборку на две части: резюме, обновленное до полугода и старше, для оценки тенденции, есть ли пресловутое влияние кризиса на ожидания и возраст соискателей или же нет.
Так как формирование исходного запроса на сайте hh, достаточно мощное, то нецелесообразно отдельно дублировать его в приложении R-Shiny, поэтому исходный произвольный запрос формируется на самом сайте hh, а в приложении надо просто указать эту гиперссылку (в данном примере использовался следующий запрос (сам не заинтересован в подобном запросе): Москва, IT/Телеком, Программирование/разработка, опыт от 3 лет). Данная гиперссылка автоматически преобразуется в вывод ста объявлений на страницу (для ускорения сбора данных), и осуществляется сбор данных (без захода внутрь резюме), так как основные характеристики выборки уже указаны на этой исходной странице. После необходимых преобразований (исключения резюме без рублевой зарплаты и возраста, если это не было сделано на самом сайте hh, обработки дат резюме), помимо сводной картинки из заголовка поста, строятся разные диаграммы по данной выборке, они показаны на рис. 1, 3. Сделано это все, используя пакет Shiny Dashboard. По диаграммам рис.1 можно увидеть плотности распределений, как зарплат, так и возрастов, с указанием децилей этих значений (кстати, визуально видно, что качественно ожидания соискателей более полгода назад и сейчас – не отличаются).
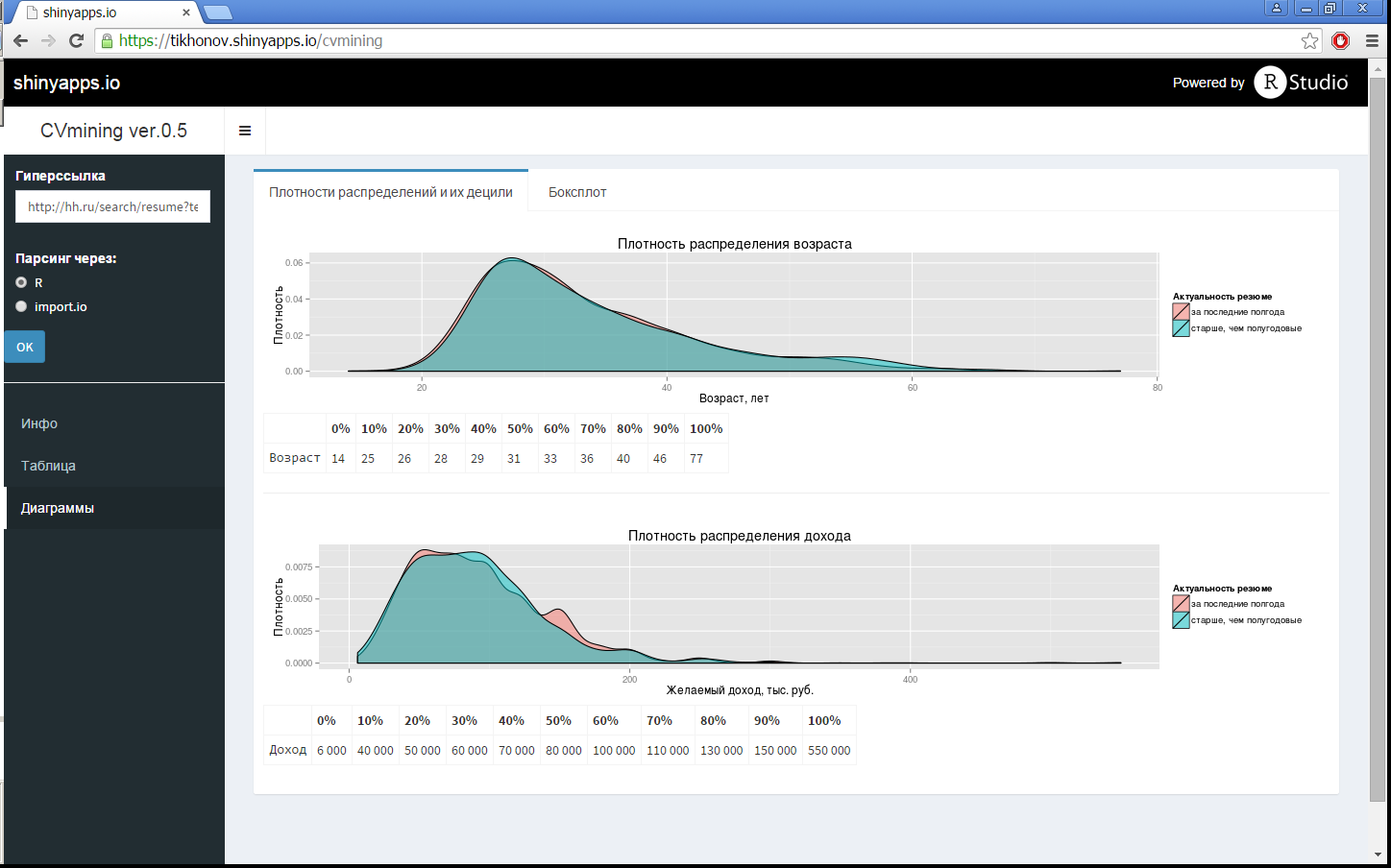
Рис. 1. Плотности распределений возрастов и зарплат с указанием децилей
Также в отдельном пункте бокового меню (рис. 2), выводятся все резюме в удобном табличном виде, в котором дополнительно сортировкой или поисковыми фильтрами, можно что-то найти конкретное.
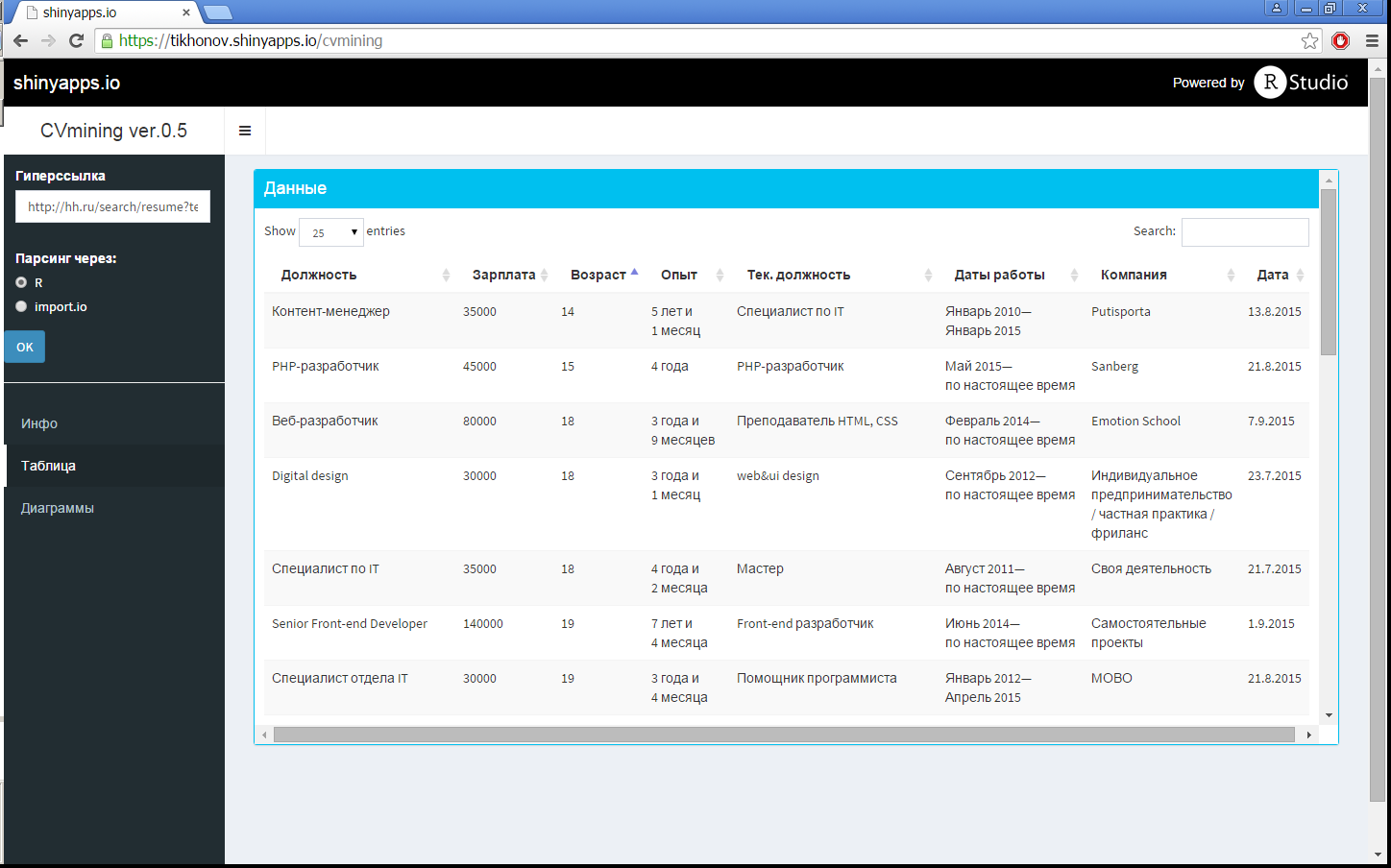
Рис.2 Таблица данных
На последней диаграмме (рис. 3) можно увидеть, как основные характеристики дохода (минимум, три квартиля, максимум и выбросы) по конкретному возрасту, так и общую тенденцию по доходу (помимо диаграммы рассеяния из заголовка поста, на которой указана сглаживающая кривая).
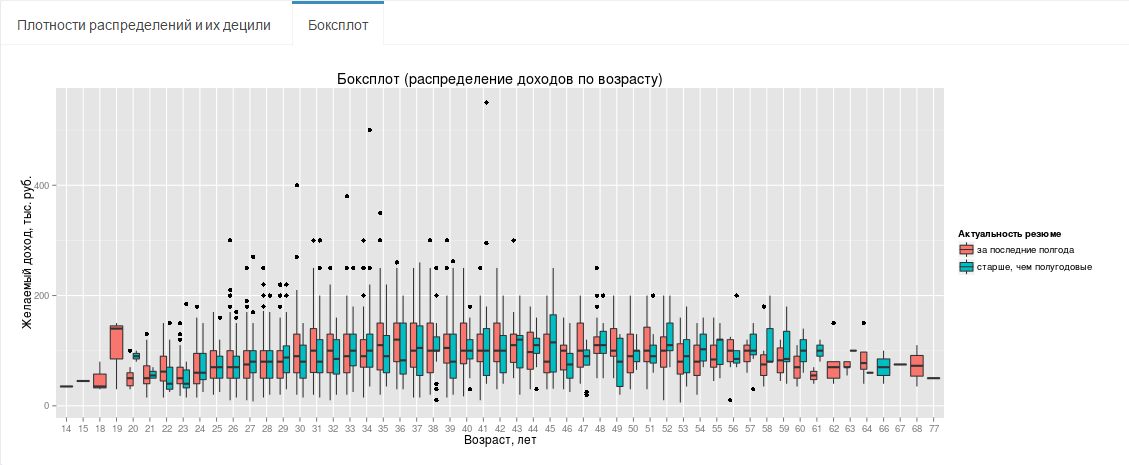
Рис.3 Боксплот (распределение дохода по возрастам)
В очередном посте про R, я хотел показать, что многие произвольные «данные вокруг нас» можно быстро и легко обработать и представить в наглядном и более удобном для восприятия виде. В данном случае, можно, например, оценить как «широкий» взгляд на отрасль, сферу труда, или же наоборот, «узкий» — максимально детализировав свой запрос по многим параметрам (ключевым словам, направлению), увидеть основные тенденции.
Мне же был интересен инструмент, который по произвольной выборке резюме (по названию, ключевым словам и прочее) показывал бы основные характеристики такой выборки, распределение зарплат, возрастов, и многое другое, как в графическом виде, так и виде произвольных перцентилей. Итог моего желания, ниже под катом.
Сбор данных
Итак, для визуализации данных, нужны собственно данные, наиболее крупным источником таких данных является сайт HeadHunter. Зная, что у него есть API, я подумал, что вот сейчас то, с ним, быстро все получу, и не придется ничего парсить, но прочитав его описание, увидел, что доступ по нему к базе именно резюме можно получить только для работодателей, и более того, только для целей предложения работы. Но ничего, и в открытом доступе hh.ru есть раздел с резюме людей, которые открыли их всему Интернету, и их то мы видим, а их достаточно много, около трети от общего числа. Из этих людей нас интересует те, которые указали желаемый доход, а их подавляющее большинство – 80%.
В итоге сбор данных, реализовал двумя способами – сбором данных используя API import.io (первоначально, как более быстрый для реализации), и непосредственно сбор и парсинг осуществляется используя R, этот способ, в итоге оказался на 20% быстрее. Так максимальное число резюме — 5 000 (ограничение hh.ru) собираются за 3 минуты, но обычно в интересующем запросе их гораздо меньше, так что непосредственная временная разница между двумя способами сбора составляет несколько секунд.
Обзор данных
Вероятнее всего, данная выборка, является смещенной, я исхожу из предположения, что люди в большинстве своем, открывающие резюме всему интернету, более заинтересованы в поиске работы, и вследствие этого, их ожидания по доходу, вероятнее всего несколько занижены. Но без доступа к полной базе, проверить эту гипотезу, нельзя, поэтому что есть, то есть.
Анализируя полученные результаты, всегда можно помнить об этой смещенности, и, например, накидывать несколько процентов на полученные результаты. Также решил дополнительно разделять выборку на две части: резюме, обновленное до полугода и старше, для оценки тенденции, есть ли пресловутое влияние кризиса на ожидания и возраст соискателей или же нет.
Графический веб-интерфейс
Так как формирование исходного запроса на сайте hh, достаточно мощное, то нецелесообразно отдельно дублировать его в приложении R-Shiny, поэтому исходный произвольный запрос формируется на самом сайте hh, а в приложении надо просто указать эту гиперссылку (в данном примере использовался следующий запрос (сам не заинтересован в подобном запросе): Москва, IT/Телеком, Программирование/разработка, опыт от 3 лет). Данная гиперссылка автоматически преобразуется в вывод ста объявлений на страницу (для ускорения сбора данных), и осуществляется сбор данных (без захода внутрь резюме), так как основные характеристики выборки уже указаны на этой исходной странице. После необходимых преобразований (исключения резюме без рублевой зарплаты и возраста, если это не было сделано на самом сайте hh, обработки дат резюме), помимо сводной картинки из заголовка поста, строятся разные диаграммы по данной выборке, они показаны на рис. 1, 3. Сделано это все, используя пакет Shiny Dashboard. По диаграммам рис.1 можно увидеть плотности распределений, как зарплат, так и возрастов, с указанием децилей этих значений (кстати, визуально видно, что качественно ожидания соискателей более полгода назад и сейчас – не отличаются).
Рис. 1. Плотности распределений возрастов и зарплат с указанием децилей
Также в отдельном пункте бокового меню (рис. 2), выводятся все резюме в удобном табличном виде, в котором дополнительно сортировкой или поисковыми фильтрами, можно что-то найти конкретное.
Рис.2 Таблица данных
На последней диаграмме (рис. 3) можно увидеть, как основные характеристики дохода (минимум, три квартиля, максимум и выбросы) по конкретному возрасту, так и общую тенденцию по доходу (помимо диаграммы рассеяния из заголовка поста, на которой указана сглаживающая кривая).
Рис.3 Боксплот (распределение дохода по возрастам)
Заключение
В очередном посте про R, я хотел показать, что многие произвольные «данные вокруг нас» можно быстро и легко обработать и представить в наглядном и более удобном для восприятия виде. В данном случае, можно, например, оценить как «широкий» взгляд на отрасль, сферу труда, или же наоборот, «узкий» — максимально детализировав свой запрос по многим параметрам (ключевым словам, направлению), увидеть основные тенденции.

