В первой части статьи были кратко обсуждены блок-схемы и имеющиеся инструменты для работы с ними. Затем были обсуждены все графические примитивы, необходимые для создания графического представления кода. Пример среды, поддерживающей такое графическое представление показан на картинке ниже.
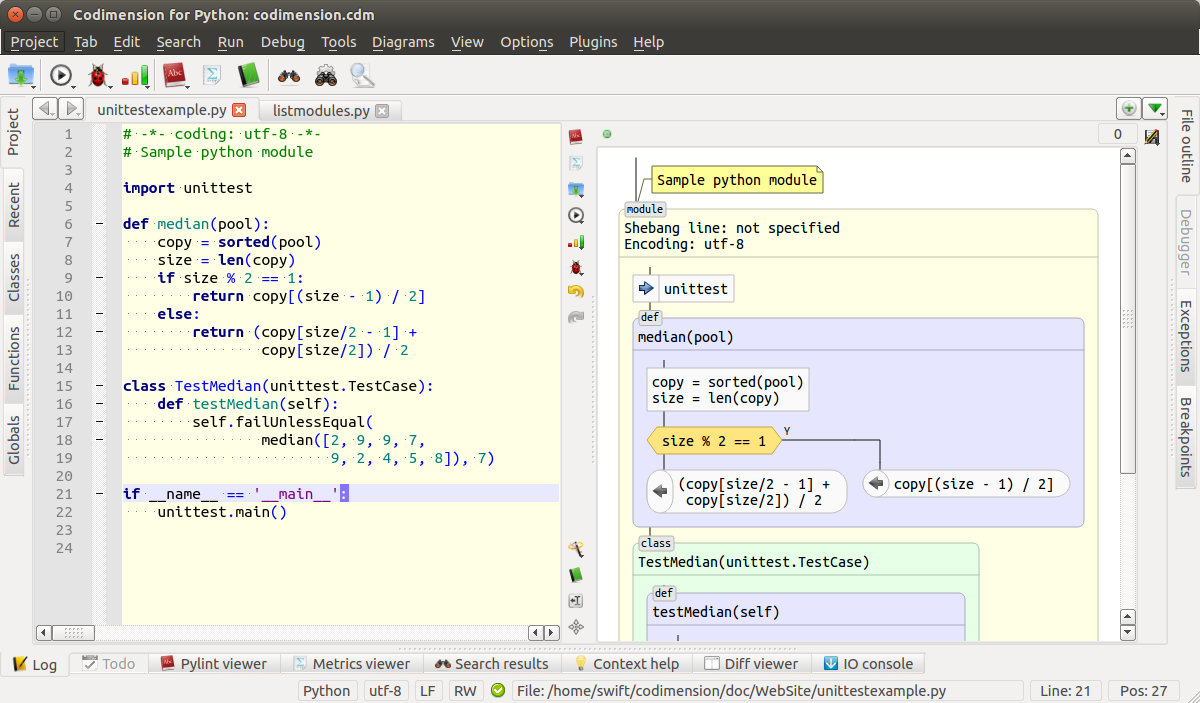
Среда, поддерживающая графическое представление кода
Во второй части речь пойдет о реализации, выполненной, в основном, на Питоне. Будут обсуждены реализованная и планируемая функциональность, а также предлагаемый микро язык разметки.
Реализация технологии выполнена в рамках проекта с открытыми исходными текстами, названного Codimension. Все исходные тексты доступны под лицензией GPL v.3 и размещены в трех репозиториях на github: два модуля расширения Питона cdm-pythonparser и cdm-flowparser плюс собственно среда IDE. Модули расширения, в основном, написаны на C/C++, а IDE на Питоне серии 2. Для графической части использовалась Питон обертка библиотеки QT — PyQT.
Разработка выполнена на Linux и для Linux. В основном использовался дистрибутив Ubuntu.
Среда предназначена для работы с проектами, написанными на Питоне серии 2.
На диаграмме ниже представлена архитектура IDE.
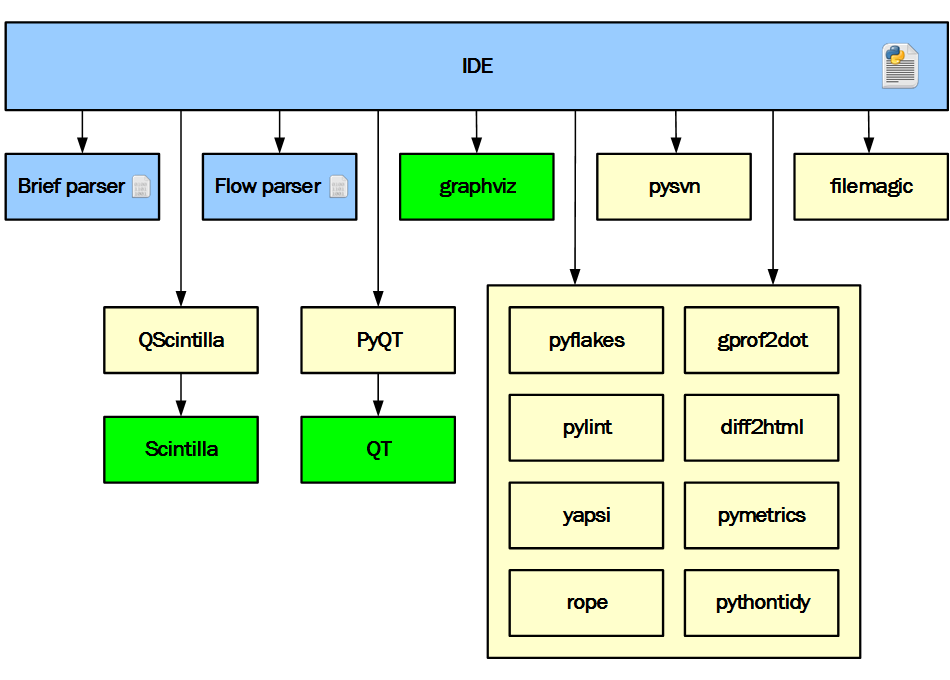
Архитектура IDE
Голубым на диаграмме обозначены части, разработанные в проекте. Желтым — сторонние Питон модули, а зеленым — сторонние бинарные модули.
С самого начала проекта было очевидно, что одному разработчику совершенно не под силу разработать все требуемые компоненты с чистого листа в разумные сроки. Поэтому уже существующие Питон пакеты использовались везде, где это было возможно и разумно. Приведенная диаграмма отлично отражает принятое решение.
Только три части разработаны в рамках проекта. IDE написана на Питоне с целью ускорения разработки и упрощения проведения экспериментов. Модули расширения написаны на C/C++ для лучшей отзывчивости IDE. Задача brief parser состоит в том, чтобы сообщить обо всех найденных в Питон файле (или буфере) сущностях, таких как импорты, классы, функции, глобальные переменные, строки документации и т.д. Наличие такой информации позволяет реализовать, например, такую функциональность: структурировано показать содержимое файла и обеспечить навигацию, предоставить анализ определенных, но нигде не использованных функций, классов и глобальных переменных в проекте. Задача flow parser предоставить в удобном виде данные, необходимые для отрисовки диаграммы.
Все остальные компоненты — сторонние. PyQT использовалась для интерфейсной и сетевой части. QScintilla в качестве основного текстового редактора и некоторых других элементов, таких как перенаправленный ввод/вывод отлаживаемых скриптов или показ svn версии файла определенной ревизии. Graphviz использовался для расчета расположения графических элементов на диаграмме зависимостей и т.п. Также использовались и другие готовые Питон пакеты: pyflakes, pylint, filemagic, rope, gprof2dot и т.д.
Реализация перехода от текста к графике построена по принципу конвейера. На каждой стадии выполняется определенная часть работы, а результаты передаются на следующую стадию. Диаграмма ниже показывает все стадии конвейера, слева которого на вход поступает исходный текст, а справа на выходе получается нарисованная диаграмма.

Конвейер от кода к графике
Начинается работа с построения синтаксического дерева по исходному тексту. Затем дерево обходится, и все обнаруженные блоки кода, циклы, функции и т.д. раскладываются в иерархическую структуру данных. После этого, по исходному коду делается еще один проход, в результате которого собирается информация о комментариях. На дальнейших стадиях конвейера удобнее иметь комментарии уже ассоциированными с распознанными конструкциями языка, а не как отдельные данные. Поэтому следующим этапом выполняется слияние комментариев с иерархической структурой, представляющей код. Описанные действия выполняются flow parser модулем расширения, который написан на C/C++ для достижения наилучшей производительности.
Последующие стадии реализованы уже внутри IDE и написаны на Питоне. Это обеспечивает большую легкость экспериментирования с отрисовкой по сравнению с реализацией на C++.
Сначала в структуре данных, названной виртуальным холстом, размещаются графические элементы в соответствии со структурой данных, полученной от модуля расширения. Затем наступает фаза рендеринга, основная задача которой рассчитать размеры всех графических элементов. Наконец, все графические элементы отрисовываются должным образом.
Обсудим все эти стадии в деталях.
Это самая первая стадия на пути от текста к графике. Ее задача — парсинг исходного текста и составление иерархической структуры данных. Это удобно делать с помощью синтаксического дерева, построенного по исходному тексту. Очевидно, что разрабатывать новый парсер Питона специально для проекта не хотелось, а наоборот, было желание воспользоваться чем-то уже готовым. К счастью, прямо в разделяемой библиотеке интерпретатора Питона нашлась подходящая функция. Это C — функция, которая строит дерево в памяти для указанного кода. Для визуализации работы этой функции была написана утилита, которая наглядно показывает построенное дерево. Например, для исходного текста:
Будет построено такое дерево (для краткости приведен только фрагмент):
В выводе каждая строка соответствует узлу дерева, вложенность показана отступами, а для узлов показана вся доступная информация.
В общем, дерево выглядит очень хорошо: есть информация о строке и колонке, есть тип каждого узла, который соответствует формальной грамматике Питона. Но есть и проблемы. Во-первых, в коде были комментарии, но информация о них в дереве нет. Во-вторых, информация о номерах строки и колонки для кодировке не соответствует действительности. В-третьих, само название кодировки изменилось. В коде была latin-1, а синтаксическое дерево рапортует iso-8859-1. В случае многострочных строковых литералов тоже есть проблема: в дереве нет информации о номерах строк. Все эти сюрпризы должны быть учтены в коде, который занимается обходом дерева. Однако все описанные проблемы скорее мелочи, по сравнению со сложностью целого парсера.
В модуле расширения определяются типы, которые будут видны в Питон коде на последующих стадиях. Типы соответствуют всем распознаваемым элемента, например Class, Import, Break и т.д. Помимо специфических для каждого случая членов данных и функций, все они предназначены для описания элемента в терминах фрагментов: где кусочек текста начинается и где заканчивается.
При обходе дерева формируется иерархическая структура, экземпляр класса ControlFlow, в который уложены все распознанные элементы нужным образом.
Из-за того, что информации о комментариях не оказалось в синтаксическом дереве (очевидно, что интерпретатору в них нет необходимости), а они нужны для отображения кода без потерь, пришлось вводить дополнительный проход по исходному коду. За этот проход извлекается информация о каждой строке комментария. Сделать это просто, благодаря простой грамматике Питона и отсутствию как многострочных комментариев, так и препроцессора.
Комментарии собираются в виде списка фрагментов, где каждый фрагмент описывает одну строчку комментария набором атрибутов: номер строки, номер колонки начала и конца, абсолютные позиции в файле начала и конца комментария.
Например для кода:
Будет собрано три фрагмента вида:
При построении диаграммы удобнее иметь дело не с двумя разными структурами данных — исполняемый код и комментарии — а с одной. Это упрощает процесс размещения элементов на виртуальном холсте. Поэтому в модуле расширения выполняется еще один этап: слияние комментариев с распознанными элементами.
Рассмотрим пример:
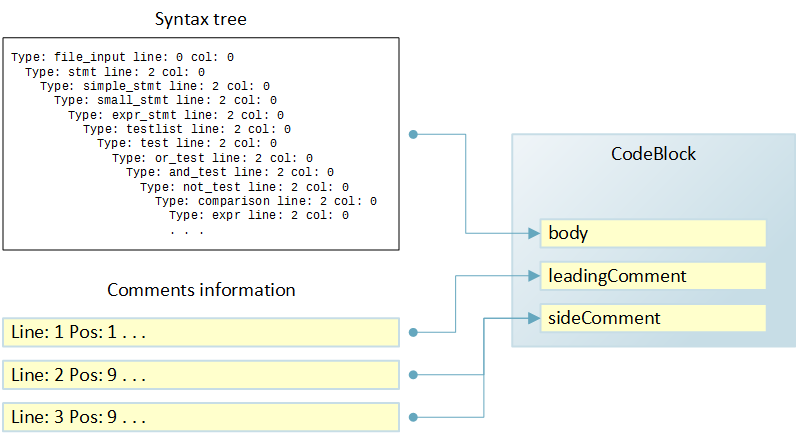
Слияние комментариев с кодом
В результате прохода по синтаксическому дереву для кода выше будет сформирован, в числе прочих, экземпляр класса CodeBlock. Он, в числе прочих полей, имеет поля body, leadingComment и sideComment, описывающие соответствующие элементы в терминах фрагментов. Поле body будет заполнено информацией из синтаксического дерева, а поля комментариев будут содержать None.
По результатам прохода для сбора комментариев будет сформирован список из трех фрагментов. При слиянии первый фрагмент будет использован для заполнения поля leadingComment в CodeBlock, а второй и третий фрагменты для поля sideComment. Слияние происходит на основе номеров строк, доступных для обоих источников информации.
Таким образом, на выходе этапа слияния имеется полностью готовая единая иерархическая структура данных о содержимом файла или буфера в памяти.
Описанные выше стадии конвейера написаны на C/C++ и оформлены в виде Питон модуля. Из общих соображений, работу всех этих стадий хотелось сделать быстрой, чтобы избежать неприятных задержек при перерисовках диаграмм в паузах модификации текста. Для проверки производительности модуль был запущен на имеющейся платформе:
для обработки всех файлов стандартной инсталляции Питона 2.7.6. При наличии 5707 файлов обработка заняла около 6 секунд. Конечно, файлы имеют разный размер и от него зависит время работы модуля, но результат в среднем около 1 миллисекунды на файл не на самом быстром оборудовании, мне кажется более чем приемлемым. На практике текст, который нужно обработать, чаще всего уже содержится в памяти и время дисковых операций уходит совсем, что также положительно влияет на производительность.
Цель этой стадии конвейера — разместить на виртуальном холсте все необходимые элементы с учетом взаимосвязей между ними. Виртуальный холст можно представить себе как полотно с прямоугольными ячейками. Ячейка может быть пустой, может содержать один графический элемент или вложенный виртуальный холст. На данном этапе важно только взаимное размещение элементов, а не точные размеры.
При этом холст не имеет фиксированного размера и может расти вниз и вправо по мере надобности. Такой подход соответствует подготовленной структуре данных и способу рисования диаграммы. Начинается процесс в левом верхнем углу. По мере надобности добавляются новые строки и колонки. Например, для следующего блока кода будет добавлена новая строка, а если у блока есть боковой комментарий — то новая колонка.
Набор графических элементов, которые могут быть размещены в ячейках, примерно соответствует распознаваемым элементам языка с небольшим расширением. Например, в ячейке может понадобиться соединитель, ведущий сверху вниз, а в языке такой элемент отсутствует.
Для виртуального холста используется список списков (двумерный массив), пустой в начале процесса.
Рассмотрим простой пример в качестве иллюстрации процесса.

Размещение графических элементов на холсте
Слева на картинке выше показана структура данных, сформированная по результатам анализа кода. Экземпляр ControlFlow содержит несколько атрибутов и контейнер suite, в котором всего один элемент — экземпляр CodeBlock.
В исходном состоянии холст пуст, и начинается обход ControlFlow. Модуль было решено рисовать как область видимости, т.е. как прямоугольник с закругленными краями. Для удобства последующих расчетов размеров графических элементов с учетом отступов, прямоугольник области видимости условно разбит на составляющие: грани и углы. В самом верхнем углу диаграммы будет находиться левый верхний угол прямоугольника модуля, поэтому добавляем новую строку к холсту, а в строке добавляем одну колонку и помещаем в ячейку scope corner элемент. Верхнюю грань прямоугольника можно не размещать правее, так как запас по вертикали уже есть за счет первой ячейки, а отрисовка прямоугольника все равно будет осуществляться как единая фигура в момент, когда будет обнаружен scope corner на этапе обхода холста.
Переходим к следующей строке. У модуля есть заголовок, в котором указаны строка запуска и кодировка. Значения соответствующих полей None, но заголовок все равно надо рисовать. Поэтому добавляем к холсту новую строку. На диаграмме заголовок должен находиться внутри прямоугольника с небольшим отступом, поэтому сразу размещать заголовок в созданной строке нельзя. В первой ячейке должна быть помещена левая грань, а затем заголовок. Поэтому добавляем две колонки и в первой размещаем scope left, а во второй — scope header. Размещать правую грань в третьей ячейке не нужно. Во-первых, сейчас еще неизвестно сколько колонок будет в самой широкой строке. А во-вторых, прямоугольник области видимости все равно будет нарисован целиком в момент обнаружения scope corner.
У модуля могла бы быть строка документации, и для нее понадобилась бы еще одна строка. Но строки документации нет, поэтому переходим к suite. Первый элемент в suite — это блок кода. Добавляем новую строку, а в ней добавляем колонку для левой грани. Затем добавляем еще одну колонку и размещаем в ячейке графический элемент для блока кода. В примере у блока есть боковой комментарий, который должен располагаться справа, поэтому добавляем еще одну колонку и располагаем в ячейке боковой комментарий.
Больше в suite нет элементов, поэтому процесс подготовки виртуального холста заканчивается. Левый нижний угол прямоугольника и нижнюю грань можно не добавлять по причинам, подобным описанным выше для верхней и правой граней. Необходимо только учесть, что они подразумеваются при расчете геометрических размеров графических элементов.
Задача этой стадии конвейера состоит в вычислении размеров всех графических примитивов для рисования на экране. Делается это путем обхода всех размещенных ячеек, вычисления необходимых размеров и сохранения их в атрибутах ячейки.
Каждая ячейка имеет две вычисленных ширины и две высоты — минимально необходимые и фактически требуемые с учетом размеров соседних ячеек.
Сначала обсудим, как рассчитывается высота. Происходит это построчно. Рассмотрим строку, в которой размещены элементы, соответствующие оператору присваивания. Здесь видно, что оператор присваивания занимает одну текстовую строку, а комментарий — две. Значит, ячейка с комментарием потребует больше вертикальных пикселей на экране при отрисовке. С другой стороны, все ячейки в строке должны быть одной высоты, иначе ячейки ниже будут нарисованы со смещением. Отсюда вытекает простой алгоритм. Необходимо обойти все ячейки в строке и рассчитать для каждой минимальную высоту. Затем выбрать максимальное значение из только что вычисленных и сохранить его как фактически требуемую высоту.
Немного сложнее дело обстоит с расчетом ширины ячеек. С этой точки зрения есть два типа строк:
Хорошим примером зависимых строк является оператор if. Ветвь, которая будет нарисована под блоком условия, может быть произвольной сложности, а значит и произвольной ширины. А вторая ветвь, которая должна быть нарисована правее, имеет соединитель от блока условия, находящийся в строке выше. Значит, ширина ячейки соединителя должна быть рассчитана в зависимости от строк, располагающихся ниже.
Таким образом, для независимых строк ширина рассчитывается за один проход и минимальная ширина совпадает с фактической.
Для регионов зависимых строк алгоритм сложнее. Сначала рассчитываются минимальные ширины всех ячеек в регионе. А затем для каждой колонки рассчитывается фактическая ширина как максимальное значение минимально требуемой ширины для всех ячеек в колонке региона. То есть очень похоже на то, что сделано для вычисления высоты в строке.
Вычисления производятся рекурсивно для вложенных виртуальных холстов. При вычислениях учитываются различные настройки: метрика выбранного шрифта, поля для различных ячеек, отступы текста и т.п. По завершению работы фазы все необходимое уже подготовлено для размещения графических примитивов уже на экранном холсте.
Стадия рисования очень проста. Так как для интерфейса пользователя используется библиотека QT, то создается графическая сцена с рассчитанными на предыдущем этапе размерами. Затем осуществляется рекурсивный обход виртуального холста и на графическую сцену добавляются необходимые элементы с нужными координатами.
Процесс обхода начинается с верхнего левого угла и текущие координаты устанавливаются в 0, 0. Затем обходится строка, после обработки каждой ячейки ширина прибавляется к текущей координате x. При переходе к следующей строке, координата x сбрасывается в 0, а к координате y прибавляется высота только что обработанной строки.
На этом процесс получения графики по коду заканчивается.
Обсудим теперь функциональность, которая уже реализована и то, что можно добавить в будущем.
Список того, что сделано, довольно короткий:
Совместное применение уже реализованных индивидуальных изменений примитивов, как показывает практика, может существенно изменить вид диаграммы.
Возможности, которыми можно дополнить имеющуюся основу, ограничиваются только фантазией. Здесь перечислены самые очевидные.
Возможности, перечисленные в предыдущем разделе, можно разделить на две группы:
Например функциональность масштабирования совершенно не зависит от кода. Текущий масштаб, скорее, должен быть сохранен как текущая настройка IDE.
С другой стороны, переключение ветвей if связано с конкретным оператором и информация об этом должна быть каким-то образом сохранена. Ведь при следующей сессии работы if должен быть нарисован так, как было предписано раньше.
Очевидно, что есть два пути сохранения дополнительной информации: либо прямо в исходном тексте, либо в отдельном файле или даже множестве файлов. При принятии решения были приняты во внимание такие соображения:
Таким образом, если есть компактное решение для сохранения дополнительной информации непосредственно в файлах с исходным текстом, то лучше воспользоваться им. Такое решение нашлось и было названо CML: Codimension markup language.
CML — это микро язык разметки, использующий комментарии питона. Каждый CML комментарий состоит из одной или нескольких соседних строк. Формат первой строки выбран следующим:
А формат строк продолжения следующим:
Литералы cml и cml+ это то, что отличает CML комментарий от других. Версия, представляющая из себя целое число, введена в расчете на будущее, если CML будет эволюционировать. Тип определяет как именно повлияет комментарий на диаграмму. В качестве типа используется строковый идентификатор, например rt (сокращение от replace text). А пары ключ=значения предоставляют возможность описать все необходимые параметры.
Как видно, формат простой и легко читается человеком. Таким образом удовлетворяется требование возможности извлечения дополнительной полезной информации не только при использовании IDE, но и при просмотре текста. При этом единственным добровольным соглашением между теми, кто использует и не использует графику является такое: не поломать CML комментарии.
Распознавание CML комментария для замены текста уже реализовано. Он может появиться как лидирующий комментарий перед блоком, например:

Блок кода с измененным текстом
Поддержки со стороны графического интерфейса пока нет. Добавить такой комментарий сейчас можно только из текстового редактора. Назначение параметра text вполне очевидно, а тип rt выбран исходя из сокращения слов replace text.
Распознавание CML комментария для переключения ветвей if также уже реализовано. Поддержка есть как со стороны текста, так и со стороны графики. По выбору из контекстного меню блока условия комментарий будет вставлен в нужное место кода, а затем диаграмма генерируется заново.

Оператор if с ветвью N справа
В приведенном примере ветвь N нарисована справа от условия.
Видно, что этот CML комментарий не требует никаких параметров. А его тип sw выбран исходя из сокращения слова switch.
Распознавание CML комментария для смены цвета уже реализовано. Он может появиться как лидирующий комментарий перед блоком, например:

Блок с индивидуальными цветами
Поддерживается смена цвета для фона (параметр background), цвета шрифта (параметр foreground) и цвета граней (параметр border). Тип cc выбран исходя из сокращения слов custom colors.
Поддержки со стороны графического интерфейса пока нет. Добавить такой комментарий сейчас можно только из текстового редактора.
Поддержки этого типа комментария сейчас нет, однако уже понятно, как функциональность может быть реализована.
Последовательность действий может быть такой. Пользователь выделяет на диаграмме группу блоков с учетом ограничения: группа имеет один вход и один выход. Далее из контекстного меню выбирается пункт: объединить в группу. Затем пользователь вводит заголовок для блока, который будет нарисован вместо группы. По окончанию ввода диаграмма перерисовывается в обновленном виде.
Очевидно, что для группы как единой сущности, есть точки в коде где она начинается и где она заканчивается. Значит, в эти места можно вставить комментарии CML, например такие:
Здесь параметр uuid автоматически генерируется в момент создания группы и нужен он для того, чтобы правильно находить пары начала группы и ее конца, так как уровней вложенности может быть сколько угодно. Назначение параметра title очевидно — это текст введенный пользователем. Типы записей gb и ge введены из соображения сокращений слов group begin и group end соответственно.
Наличие uuid также позволяет диагностировать различные ошибки. Например, в результате редактирования текста один из пары CML комментариев мог быть удален. Еще один случай возможного применения uuid — запоминания в IDE групп, которые должны быть показаны в следующей сессии как свернутые.
Практика использования инструмента показала, что у технологии есть интересные побочные эффекты, которые совершенно не рассматривались при первоначальной разработке.
Во-первых, оказалось удобным использовать сгенерированные диаграммы для документации и для обсуждения с коллегами, часто не имеющими отношения к программированию, но являющимися экспертами в предметной области. В таких случаях готовился код, не предназначенный для выполнения, но соответствующий логике действий и отвечающий формальному синтаксису питона. Сгенерированная диаграмма либо вставлялась в документацию, либо печаталась и обсуждалась. Дополнительное удобство проявилось в легкости внесения изменений в логику — диаграмма моментально перерисовывается со всеми нужными отступами и выравниваем без необходимости ручных операций с графикой.
Во-вторых, проявился интересный чисто психологический эффект. Разработчик, открывая свой же давно написанный код с использованием Codimension замечал, что диаграмма выглядит некрасиво — слишком сложна или запутанна. И с целью получения более изящной диаграммы вносил изменения в текст, фактически выполняя рефакторинг и упрощение кода. Что в свою очередь приводит к уменьшению сложности понимания и дальнейшей поддержки кода.
В-третьих, несмотря на то, что разработка выполнена для Питона, технология вполне может быть распространена и на другие языки программирования. Питон был выбран как полигон для испытаний по нескольким причинам: язык популярный, но в то же время синтаксически простой.
Я бы хотел поблагодарить всех, кто помогал в работе над этим проектом. Спасибо моим коллегам Дмитрию Казимирову, Илье Логинову, Дэвиду Макэлхани и Сергею Фуканчику за помощь с различными аспектами разработки на разных этапах.
Отдельные благодарности авторам и разработчикам Питон пакетов с открытыми исходными текстами, которые были использованы в работе над Codimension IDE.
Среда, поддерживающая графическое представление кода
Во второй части речь пойдет о реализации, выполненной, в основном, на Питоне. Будут обсуждены реализованная и планируемая функциональность, а также предлагаемый микро язык разметки.
Общая информация
Реализация технологии выполнена в рамках проекта с открытыми исходными текстами, названного Codimension. Все исходные тексты доступны под лицензией GPL v.3 и размещены в трех репозиториях на github: два модуля расширения Питона cdm-pythonparser и cdm-flowparser плюс собственно среда IDE. Модули расширения, в основном, написаны на C/C++, а IDE на Питоне серии 2. Для графической части использовалась Питон обертка библиотеки QT — PyQT.
Разработка выполнена на Linux и для Linux. В основном использовался дистрибутив Ubuntu.
Среда предназначена для работы с проектами, написанными на Питоне серии 2.
Архитектура
На диаграмме ниже представлена архитектура IDE.
Архитектура IDE
Голубым на диаграмме обозначены части, разработанные в проекте. Желтым — сторонние Питон модули, а зеленым — сторонние бинарные модули.
С самого начала проекта было очевидно, что одному разработчику совершенно не под силу разработать все требуемые компоненты с чистого листа в разумные сроки. Поэтому уже существующие Питон пакеты использовались везде, где это было возможно и разумно. Приведенная диаграмма отлично отражает принятое решение.
Только три части разработаны в рамках проекта. IDE написана на Питоне с целью ускорения разработки и упрощения проведения экспериментов. Модули расширения написаны на C/C++ для лучшей отзывчивости IDE. Задача brief parser состоит в том, чтобы сообщить обо всех найденных в Питон файле (или буфере) сущностях, таких как импорты, классы, функции, глобальные переменные, строки документации и т.д. Наличие такой информации позволяет реализовать, например, такую функциональность: структурировано показать содержимое файла и обеспечить навигацию, предоставить анализ определенных, но нигде не использованных функций, классов и глобальных переменных в проекте. Задача flow parser предоставить в удобном виде данные, необходимые для отрисовки диаграммы.
Все остальные компоненты — сторонние. PyQT использовалась для интерфейсной и сетевой части. QScintilla в качестве основного текстового редактора и некоторых других элементов, таких как перенаправленный ввод/вывод отлаживаемых скриптов или показ svn версии файла определенной ревизии. Graphviz использовался для расчета расположения графических элементов на диаграмме зависимостей и т.п. Также использовались и другие готовые Питон пакеты: pyflakes, pylint, filemagic, rope, gprof2dot и т.д.
Конвейер от кода к графике
Реализация перехода от текста к графике построена по принципу конвейера. На каждой стадии выполняется определенная часть работы, а результаты передаются на следующую стадию. Диаграмма ниже показывает все стадии конвейера, слева которого на вход поступает исходный текст, а справа на выходе получается нарисованная диаграмма.
Конвейер от кода к графике
Начинается работа с построения синтаксического дерева по исходному тексту. Затем дерево обходится, и все обнаруженные блоки кода, циклы, функции и т.д. раскладываются в иерархическую структуру данных. После этого, по исходному коду делается еще один проход, в результате которого собирается информация о комментариях. На дальнейших стадиях конвейера удобнее иметь комментарии уже ассоциированными с распознанными конструкциями языка, а не как отдельные данные. Поэтому следующим этапом выполняется слияние комментариев с иерархической структурой, представляющей код. Описанные действия выполняются flow parser модулем расширения, который написан на C/C++ для достижения наилучшей производительности.
Последующие стадии реализованы уже внутри IDE и написаны на Питоне. Это обеспечивает большую легкость экспериментирования с отрисовкой по сравнению с реализацией на C++.
Сначала в структуре данных, названной виртуальным холстом, размещаются графические элементы в соответствии со структурой данных, полученной от модуля расширения. Затем наступает фаза рендеринга, основная задача которой рассчитать размеры всех графических элементов. Наконец, все графические элементы отрисовываются должным образом.
Обсудим все эти стадии в деталях.
Построение синтаксического дерева
Это самая первая стадия на пути от текста к графике. Ее задача — парсинг исходного текста и составление иерархической структуры данных. Это удобно делать с помощью синтаксического дерева, построенного по исходному тексту. Очевидно, что разрабатывать новый парсер Питона специально для проекта не хотелось, а наоборот, было желание воспользоваться чем-то уже готовым. К счастью, прямо в разделяемой библиотеке интерпретатора Питона нашлась подходящая функция. Это C — функция, которая строит дерево в памяти для указанного кода. Для визуализации работы этой функции была написана утилита, которая наглядно показывает построенное дерево. Например, для исходного текста:
#!/bin/env python # encoding: latin-1 def f(): # What printed? print 154
Будет построено такое дерево (для краткости приведен только фрагмент):
$ ./tree test.py
Type: encoding_decl line: 0 col: 0 str: iso-8859-1
Type: file_input line: 0 col: 0
Type: stmt line: 4 col: 0
Type: compound_stmt line: 4 col: 0
Type: funcdef line: 4 col: 0
Type: NAME line: 4 col: 0 str: def
Type: NAME line: 4 col: 4 str: f
Type: parameters line: 4 col: 5
Type: LPAR line: 4 col: 5 str: (
Type: RPAR line: 4 col: 6 str: )
Type: COLON line: 4 col: 7 str: :
Type: suite line: 4 col: 8
Type: NEWLINE line: 4 col: 8 str:
Type: INDENT line: 6 col: -1 str:
Type: stmt line: 6 col: 4
Type: simple_stmt line: 6 col: 4
Type: small_stmt line: 6 col: 4
Type: print_stmt line: 6 col: 4
. . .
В выводе каждая строка соответствует узлу дерева, вложенность показана отступами, а для узлов показана вся доступная информация.
В общем, дерево выглядит очень хорошо: есть информация о строке и колонке, есть тип каждого узла, который соответствует формальной грамматике Питона. Но есть и проблемы. Во-первых, в коде были комментарии, но информация о них в дереве нет. Во-вторых, информация о номерах строки и колонки для кодировке не соответствует действительности. В-третьих, само название кодировки изменилось. В коде была latin-1, а синтаксическое дерево рапортует iso-8859-1. В случае многострочных строковых литералов тоже есть проблема: в дереве нет информации о номерах строк. Все эти сюрпризы должны быть учтены в коде, который занимается обходом дерева. Однако все описанные проблемы скорее мелочи, по сравнению со сложностью целого парсера.
В модуле расширения определяются типы, которые будут видны в Питон коде на последующих стадиях. Типы соответствуют всем распознаваемым элемента, например Class, Import, Break и т.д. Помимо специфических для каждого случая членов данных и функций, все они предназначены для описания элемента в терминах фрагментов: где кусочек текста начинается и где заканчивается.
При обходе дерева формируется иерархическая структура, экземпляр класса ControlFlow, в который уложены все распознанные элементы нужным образом.
Сбор комментариев
Из-за того, что информации о комментариях не оказалось в синтаксическом дереве (очевидно, что интерпретатору в них нет необходимости), а они нужны для отображения кода без потерь, пришлось вводить дополнительный проход по исходному коду. За этот проход извлекается информация о каждой строке комментария. Сделать это просто, благодаря простой грамматике Питона и отсутствию как многострочных комментариев, так и препроцессора.
Комментарии собираются в виде списка фрагментов, где каждый фрагмент описывает одну строчку комментария набором атрибутов: номер строки, номер колонки начала и конца, абсолютные позиции в файле начала и конца комментария.
Например для кода:
#!/bin/env python # encoding: latin-1 def f(): # What printed? print 154
Будет собрано три фрагмента вида:
Line: 1 Pos: 1 … Line: 2 Pos: 1 … Line: 5 Pos: 5 …
Слияние комментариев с фрагментами кода
При построении диаграммы удобнее иметь дело не с двумя разными структурами данных — исполняемый код и комментарии — а с одной. Это упрощает процесс размещения элементов на виртуальном холсте. Поэтому в модуле расширения выполняется еще один этап: слияние комментариев с распознанными элементами.
Рассмотрим пример:
# leading comment a = 10 # side comment 1 # side comment 2
Слияние комментариев с кодом
В результате прохода по синтаксическому дереву для кода выше будет сформирован, в числе прочих, экземпляр класса CodeBlock. Он, в числе прочих полей, имеет поля body, leadingComment и sideComment, описывающие соответствующие элементы в терминах фрагментов. Поле body будет заполнено информацией из синтаксического дерева, а поля комментариев будут содержать None.
По результатам прохода для сбора комментариев будет сформирован список из трех фрагментов. При слиянии первый фрагмент будет использован для заполнения поля leadingComment в CodeBlock, а второй и третий фрагменты для поля sideComment. Слияние происходит на основе номеров строк, доступных для обоих источников информации.
Таким образом, на выходе этапа слияния имеется полностью готовая единая иерархическая структура данных о содержимом файла или буфера в памяти.
Производительность модуля
Описанные выше стадии конвейера написаны на C/C++ и оформлены в виде Питон модуля. Из общих соображений, работу всех этих стадий хотелось сделать быстрой, чтобы избежать неприятных задержек при перерисовках диаграмм в паузах модификации текста. Для проверки производительности модуль был запущен на имеющейся платформе:
- Intel Core i5-3210M ноутбук
- Ubuntu 14.04 LTS
для обработки всех файлов стандартной инсталляции Питона 2.7.6. При наличии 5707 файлов обработка заняла около 6 секунд. Конечно, файлы имеют разный размер и от него зависит время работы модуля, но результат в среднем около 1 миллисекунды на файл не на самом быстром оборудовании, мне кажется более чем приемлемым. На практике текст, который нужно обработать, чаще всего уже содержится в памяти и время дисковых операций уходит совсем, что также положительно влияет на производительность.
Размещение на виртуальном холсте
Цель этой стадии конвейера — разместить на виртуальном холсте все необходимые элементы с учетом взаимосвязей между ними. Виртуальный холст можно представить себе как полотно с прямоугольными ячейками. Ячейка может быть пустой, может содержать один графический элемент или вложенный виртуальный холст. На данном этапе важно только взаимное размещение элементов, а не точные размеры.
При этом холст не имеет фиксированного размера и может расти вниз и вправо по мере надобности. Такой подход соответствует подготовленной структуре данных и способу рисования диаграммы. Начинается процесс в левом верхнем углу. По мере надобности добавляются новые строки и колонки. Например, для следующего блока кода будет добавлена новая строка, а если у блока есть боковой комментарий — то новая колонка.
Набор графических элементов, которые могут быть размещены в ячейках, примерно соответствует распознаваемым элементам языка с небольшим расширением. Например, в ячейке может понадобиться соединитель, ведущий сверху вниз, а в языке такой элемент отсутствует.
Для виртуального холста используется список списков (двумерный массив), пустой в начале процесса.
Рассмотрим простой пример в качестве иллюстрации процесса.
a = 10 # side comment 1 # side comment 2
Размещение графических элементов на холсте
Слева на картинке выше показана структура данных, сформированная по результатам анализа кода. Экземпляр ControlFlow содержит несколько атрибутов и контейнер suite, в котором всего один элемент — экземпляр CodeBlock.
В исходном состоянии холст пуст, и начинается обход ControlFlow. Модуль было решено рисовать как область видимости, т.е. как прямоугольник с закругленными краями. Для удобства последующих расчетов размеров графических элементов с учетом отступов, прямоугольник области видимости условно разбит на составляющие: грани и углы. В самом верхнем углу диаграммы будет находиться левый верхний угол прямоугольника модуля, поэтому добавляем новую строку к холсту, а в строке добавляем одну колонку и помещаем в ячейку scope corner элемент. Верхнюю грань прямоугольника можно не размещать правее, так как запас по вертикали уже есть за счет первой ячейки, а отрисовка прямоугольника все равно будет осуществляться как единая фигура в момент, когда будет обнаружен scope corner на этапе обхода холста.
Переходим к следующей строке. У модуля есть заголовок, в котором указаны строка запуска и кодировка. Значения соответствующих полей None, но заголовок все равно надо рисовать. Поэтому добавляем к холсту новую строку. На диаграмме заголовок должен находиться внутри прямоугольника с небольшим отступом, поэтому сразу размещать заголовок в созданной строке нельзя. В первой ячейке должна быть помещена левая грань, а затем заголовок. Поэтому добавляем две колонки и в первой размещаем scope left, а во второй — scope header. Размещать правую грань в третьей ячейке не нужно. Во-первых, сейчас еще неизвестно сколько колонок будет в самой широкой строке. А во-вторых, прямоугольник области видимости все равно будет нарисован целиком в момент обнаружения scope corner.
У модуля могла бы быть строка документации, и для нее понадобилась бы еще одна строка. Но строки документации нет, поэтому переходим к suite. Первый элемент в suite — это блок кода. Добавляем новую строку, а в ней добавляем колонку для левой грани. Затем добавляем еще одну колонку и размещаем в ячейке графический элемент для блока кода. В примере у блока есть боковой комментарий, который должен располагаться справа, поэтому добавляем еще одну колонку и располагаем в ячейке боковой комментарий.
Больше в suite нет элементов, поэтому процесс подготовки виртуального холста заканчивается. Левый нижний угол прямоугольника и нижнюю грань можно не добавлять по причинам, подобным описанным выше для верхней и правой граней. Необходимо только учесть, что они подразумеваются при расчете геометрических размеров графических элементов.
Рендеринг
Задача этой стадии конвейера состоит в вычислении размеров всех графических примитивов для рисования на экране. Делается это путем обхода всех размещенных ячеек, вычисления необходимых размеров и сохранения их в атрибутах ячейки.
Каждая ячейка имеет две вычисленных ширины и две высоты — минимально необходимые и фактически требуемые с учетом размеров соседних ячеек.
Сначала обсудим, как рассчитывается высота. Происходит это построчно. Рассмотрим строку, в которой размещены элементы, соответствующие оператору присваивания. Здесь видно, что оператор присваивания занимает одну текстовую строку, а комментарий — две. Значит, ячейка с комментарием потребует больше вертикальных пикселей на экране при отрисовке. С другой стороны, все ячейки в строке должны быть одной высоты, иначе ячейки ниже будут нарисованы со смещением. Отсюда вытекает простой алгоритм. Необходимо обойти все ячейки в строке и рассчитать для каждой минимальную высоту. Затем выбрать максимальное значение из только что вычисленных и сохранить его как фактически требуемую высоту.
Немного сложнее дело обстоит с расчетом ширины ячеек. С этой точки зрения есть два типа строк:
- такие, у которых ширина должна рассчитываться с учетом ширины ячеек в соседней строке
- такие, ширина ячеек которых может рассчитываться без учета соседних строк
Хорошим примером зависимых строк является оператор if. Ветвь, которая будет нарисована под блоком условия, может быть произвольной сложности, а значит и произвольной ширины. А вторая ветвь, которая должна быть нарисована правее, имеет соединитель от блока условия, находящийся в строке выше. Значит, ширина ячейки соединителя должна быть рассчитана в зависимости от строк, располагающихся ниже.
Таким образом, для независимых строк ширина рассчитывается за один проход и минимальная ширина совпадает с фактической.
Для регионов зависимых строк алгоритм сложнее. Сначала рассчитываются минимальные ширины всех ячеек в регионе. А затем для каждой колонки рассчитывается фактическая ширина как максимальное значение минимально требуемой ширины для всех ячеек в колонке региона. То есть очень похоже на то, что сделано для вычисления высоты в строке.
Вычисления производятся рекурсивно для вложенных виртуальных холстов. При вычислениях учитываются различные настройки: метрика выбранного шрифта, поля для различных ячеек, отступы текста и т.п. По завершению работы фазы все необходимое уже подготовлено для размещения графических примитивов уже на экранном холсте.
Рисование
Стадия рисования очень проста. Так как для интерфейса пользователя используется библиотека QT, то создается графическая сцена с рассчитанными на предыдущем этапе размерами. Затем осуществляется рекурсивный обход виртуального холста и на графическую сцену добавляются необходимые элементы с нужными координатами.
Процесс обхода начинается с верхнего левого угла и текущие координаты устанавливаются в 0, 0. Затем обходится строка, после обработки каждой ячейки ширина прибавляется к текущей координате x. При переходе к следующей строке, координата x сбрасывается в 0, а к координате y прибавляется высота только что обработанной строки.
На этом процесс получения графики по коду заканчивается.
Настоящее и будущее
Обсудим теперь функциональность, которая уже реализована и то, что можно добавить в будущем.
Список того, что сделано, довольно короткий:
- Автоматическое обновление диаграммы в паузах изменения кода.
- Ручная синхронизация видимых текста и графики в обоих направлениях. Если фокус ввода находится в текстовом редакторе, и нажата специальная комбинация клавиш, то на диаграмме выполняется поиск примитива, наиболее соответствующего текущему положению курсора. Далее примитив подсвечивается, а диаграмма прокручивается так, чтобы сделать примитив видимым. В обратном направлении синхронизация выполняется по двойному щелчку по примитиву, который приводит к перемещению текстового курсора к нужной строке кода и прокрутке текстового редактора, если необходимо.
- Масштабирование диаграммы. Текущая реализация использует встроенные средства масштабирования библиотеки QT. В будущем планируется заменить ее на масштабирование через изменение размера шрифта и пересчет размеров всех элементов.
- Экспорт диаграммы в PDF, PNG и SVG. Качество выходных документов определяется реализацией библиотеки QT, так как именно ее средства использованы для этой функциональности.
- Навигационная панель областей видимости. Графика интенсивно использует идею области видимости, поэтому типичная диаграмма содержит множество вложенных областей. Навигационная панель показывает текущий путь в терминах вложенных областей видимости для текущей позиции курсора мыши над графической сценой.
- Индивидуальное переключение размещения веток для оператора if. По умолчанию ветка N рисуется ниже, а ветка Y правее. Диаграмма позволяет поменять местами расположение веток, используя контекстное меню блока условия.
- Индивидуальная замена текста любого графического примитива. Иногда возникает желание заменить текст какого-нибудь блока на произвольный. Например, условие в терминах переменных и вызовов функций может быть длинным и совсем не очевидным, тогда как фраза на естественном языке может лучше описать происходящее. Диаграмма позволяет заменить отображаемый текст на произвольный и показывает исходный во всплывающей подсказке.
- Индивидуальная замена цветов любого примитива. Иногда возникает желание привлечь внимание к какому-либо участку кода путем подсветки графических примитивов. Например, потенциально опасный участок можно подсветить красным цветом или выбрать общий цвет для элементов, отвечающих за общую функциональность. Диаграмма позволяет изменить цвета фона, шрифта и обводки примитивов.
Совместное применение уже реализованных индивидуальных изменений примитивов, как показывает практика, может существенно изменить вид диаграммы.
Возможности, которыми можно дополнить имеющуюся основу, ограничиваются только фантазией. Здесь перечислены самые очевидные.
- Автоматическая синхронизация текста и графики при прокрутке.
- Поддержка редактирования на диаграмме: удаление, перемещение и добавление блоков. Редактирование текста внутри отдельных блоков. Копирование и вставка блоков.
- Поддержка групповых операций с блоками.
- Визуализация отладки на диаграмме. Как минимум подсветка текущего блока и текущей строки в нем.
- Поддержка поиска на диаграмме.
- Поддержка печати.
- Управление скрытием / показом различных элементов: комментариев, строк документации, тел функций, классов, циклов и т.п.
- Подсветка различных типов импортов: внутри проекта, системные, неопознанные.
- Поддержка дополнительных неязыковых блоков или картинок на диаграммах.
- Умное масштабирование. Можно ввести несколько фиксированных уровней масштаба: все элементы, без комментариев и строк документации, только заголовки классов и функций, зависимости между файлами в подкаталоге и указатели внешних связей. Если закрепить такое поведение за колесом мыши с каким-либо модификатором, то можно будет получать обзорную информацию чрезвычайно быстро.
- Свертка нескольких блоков в один и развертывание обратно. Группа блоков, выполняющих совместную задачу может быть выделена на диаграмме и свернута в один блок со своей собственной графикой и предоставленным текстом. Естественное ограничение здесь — группа должна иметь один вход и один выход. Такая функциональность может пригодиться при работе с неизвестным кодом. Когда приходит понимание, что делают несколько расположенных блоков, можно сократить сложность диаграммы, объединив группу и заменив ее одним блоком с, нужной подписью, например «MD5 calculation». Разумеется, в любой момент можно будет вернуться к подробностям. Эту функцию можно рассматривать как введение третьего измерения в диаграмму.
CML v.1
Возможности, перечисленные в предыдущем разделе, можно разделить на две группы:
- Требующие сохранения информации в связи с кодом.
- Полностью независимые от кода.
Например функциональность масштабирования совершенно не зависит от кода. Текущий масштаб, скорее, должен быть сохранен как текущая настройка IDE.
С другой стороны, переключение ветвей if связано с конкретным оператором и информация об этом должна быть каким-то образом сохранена. Ведь при следующей сессии работы if должен быть нарисован так, как было предписано раньше.
Очевидно, что есть два пути сохранения дополнительной информации: либо прямо в исходном тексте, либо в отдельном файле или даже множестве файлов. При принятии решения были приняты во внимание такие соображения:
- Представим себе, что над проектом работает команда разработчиков и часть из них с успехом использует графические возможности представления кода. А другая часть из принципиальных соображений для работы с кодом использует только vim. В этом случае, если дополнительная информация хранится отдельно от кода, то ее консистентность при попеременном редактировании кода членами разных лагерей будет поддержать чрезвычайно сложно, если вообще возможно. Наверняка дополнительная информация окажется несоответствующей действительности в какой-то момент времени.
- Если выбран подход дополнительных файлов, то они скорее замусоривают содержимое проекта и требуют дополнительных усилий от команды при работе с системами контроля версий.
- Когда разработчик вводит дополнительную разметку — например заменяет длинный код непонятного условия подходящей фразой — это делается не для развлечения, а потому что такая пометка имеет ценность. Хорошо бы сохранить эту ценность доступной и для тех, кто не пользуется графикой хотя бы и не в таком красивом виде.
Таким образом, если есть компактное решение для сохранения дополнительной информации непосредственно в файлах с исходным текстом, то лучше воспользоваться им. Такое решение нашлось и было названо CML: Codimension markup language.
CML — это микро язык разметки, использующий комментарии питона. Каждый CML комментарий состоит из одной или нескольких соседних строк. Формат первой строки выбран следующим:
# cml <версия> <тип> [пары ключ=значение]
А формат строк продолжения следующим:
# cml+ <продолжение предыдущей cml строки>
Литералы cml и cml+ это то, что отличает CML комментарий от других. Версия, представляющая из себя целое число, введена в расчете на будущее, если CML будет эволюционировать. Тип определяет как именно повлияет комментарий на диаграмму. В качестве типа используется строковый идентификатор, например rt (сокращение от replace text). А пары ключ=значения предоставляют возможность описать все необходимые параметры.
Как видно, формат простой и легко читается человеком. Таким образом удовлетворяется требование возможности извлечения дополнительной полезной информации не только при использовании IDE, но и при просмотре текста. При этом единственным добровольным соглашением между теми, кто использует и не использует графику является такое: не поломать CML комментарии.
CML: замена текста
Распознавание CML комментария для замены текста уже реализовано. Он может появиться как лидирующий комментарий перед блоком, например:
# cml 1 rt text="Believe me, I do the right thing here" False = 154
Блок кода с измененным текстом
Поддержки со стороны графического интерфейса пока нет. Добавить такой комментарий сейчас можно только из текстового редактора. Назначение параметра text вполне очевидно, а тип rt выбран исходя из сокращения слов replace text.
CML: переключение ветвей if
Распознавание CML комментария для переключения ветвей if также уже реализовано. Поддержка есть как со стороны текста, так и со стороны графики. По выбору из контекстного меню блока условия комментарий будет вставлен в нужное место кода, а затем диаграмма генерируется заново.
# cml 1 sw if False == 154: print("That’s expected") else: print("Hmmm, has the code above been run?")
Оператор if с ветвью N справа
В приведенном примере ветвь N нарисована справа от условия.
Видно, что этот CML комментарий не требует никаких параметров. А его тип sw выбран исходя из сокращения слова switch.
CML: смена цвета
Распознавание CML комментария для смены цвета уже реализовано. Он может появиться как лидирующий комментарий перед блоком, например:
# cml 1 cc background="255,138,128" # cml+ foreground="0,0,255" # cml+ border="0,0,0" print("Danger! Someone has damaged False")
Блок с индивидуальными цветами
Поддерживается смена цвета для фона (параметр background), цвета шрифта (параметр foreground) и цвета граней (параметр border). Тип cc выбран исходя из сокращения слов custom colors.
Поддержки со стороны графического интерфейса пока нет. Добавить такой комментарий сейчас можно только из текстового редактора.
CML: свертка группы
Поддержки этого типа комментария сейчас нет, однако уже понятно, как функциональность может быть реализована.
Последовательность действий может быть такой. Пользователь выделяет на диаграмме группу блоков с учетом ограничения: группа имеет один вход и один выход. Далее из контекстного меню выбирается пункт: объединить в группу. Затем пользователь вводит заголовок для блока, который будет нарисован вместо группы. По окончанию ввода диаграмма перерисовывается в обновленном виде.
Очевидно, что для группы как единой сущности, есть точки в коде где она начинается и где она заканчивается. Значит, в эти места можно вставить комментарии CML, например такие:
# cml gb uuid="..." title="..." . . . # cml ge uuid="..."
Здесь параметр uuid автоматически генерируется в момент создания группы и нужен он для того, чтобы правильно находить пары начала группы и ее конца, так как уровней вложенности может быть сколько угодно. Назначение параметра title очевидно — это текст введенный пользователем. Типы записей gb и ge введены из соображения сокращений слов group begin и group end соответственно.
Наличие uuid также позволяет диагностировать различные ошибки. Например, в результате редактирования текста один из пары CML комментариев мог быть удален. Еще один случай возможного применения uuid — запоминания в IDE групп, которые должны быть показаны в следующей сессии как свернутые.
Побочные эффекты
Практика использования инструмента показала, что у технологии есть интересные побочные эффекты, которые совершенно не рассматривались при первоначальной разработке.
Во-первых, оказалось удобным использовать сгенерированные диаграммы для документации и для обсуждения с коллегами, часто не имеющими отношения к программированию, но являющимися экспертами в предметной области. В таких случаях готовился код, не предназначенный для выполнения, но соответствующий логике действий и отвечающий формальному синтаксису питона. Сгенерированная диаграмма либо вставлялась в документацию, либо печаталась и обсуждалась. Дополнительное удобство проявилось в легкости внесения изменений в логику — диаграмма моментально перерисовывается со всеми нужными отступами и выравниваем без необходимости ручных операций с графикой.
Во-вторых, проявился интересный чисто психологический эффект. Разработчик, открывая свой же давно написанный код с использованием Codimension замечал, что диаграмма выглядит некрасиво — слишком сложна или запутанна. И с целью получения более изящной диаграммы вносил изменения в текст, фактически выполняя рефакторинг и упрощение кода. Что в свою очередь приводит к уменьшению сложности понимания и дальнейшей поддержки кода.
В-третьих, несмотря на то, что разработка выполнена для Питона, технология вполне может быть распространена и на другие языки программирования. Питон был выбран как полигон для испытаний по нескольким причинам: язык популярный, но в то же время синтаксически простой.
Благодарности
Я бы хотел поблагодарить всех, кто помогал в работе над этим проектом. Спасибо моим коллегам Дмитрию Казимирову, Илье Логинову, Дэвиду Макэлхани и Сергею Фуканчику за помощь с различными аспектами разработки на разных этапах.
Отдельные благодарности авторам и разработчикам Питон пакетов с открытыми исходными текстами, которые были использованы в работе над Codimension IDE.

