
Коллизии существуют для большинства хеш-функций, но для самых хороших из них количество коллизий близко к теоретическому минимуму. Например, за десять лет с момента изобретения SHA-1 не было известно ни об одном практическом способе генерации коллизий. Теперь такой есть. Сегодня первый алгоритм генерации коллизий для SHA-1 представили сотрудники компании Google и Центра математики и информатики в Амстердаме.
Вот доказательство: два документа PDF с разным содержимым, но одинаковыми цифровыми подписями SHA-1.
$ls -l sha*.pdf -rw-r--r--@ 1 amichal staff 422435 Feb 23 10:01 shattered-1.pdf -rw-r--r--@ 1 amichal staff 422435 Feb 23 10:14 shattered-2.pdf $shasum -a 1 sha*.pdf 38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-1.pdf 38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-2.pdf
На сайте shattered.it можно проверить любой файл на предмет того, входит ли он в пространство возможных коллизий. То есть можно ли подобрать другой набор данных (файл) с таким же хешем. Вектор атаки здесь понятен: злоумышленник может подменить «хороший» файл своим экземпляром с закладкой, вредоносным макросом или загрузчиком трояна. И этот «плохой» файл будет иметь такой же хеш или цифровую подпись.
Криптографические хеш-функции вроде SHA-1 — это универсальный криптографический инструмент, который повсеместно используется в практических приложениях. Они нужны при построении ассоциативных массивов, при поиске дубликатов в наборах данных, при построении уникальных идентификаторов, при вычислении контрольных сумм для обнаружения ошибок. Например, на хеши SHA-1 полностью полагается система управлениями версиями программного обеспечения Git.
Но ещё важнее, что хеширование критически важно в сфере информационной безопасности: оно используется при сохранении паролей, при выработке электронной подписи и т.д. В общем виде, хеш-функции преобразуют любой большой массив данных в небольшое сообщение.
Учитывая повсеместное распространение хеш-функций очень важным требованием является минимальное количество коллизий, когда два различных блока входных данных преобразуются в два одинаковых хеша.
В официальном сообщении авторы говорят, что эта находка стала результатом двухлетнего исследования, которая началась вскоре после публикации в 2013 году работы криптографа Марка Стивенса из Центра математики и информатики в Амстердаме о теоретическом подходе к созданию коллизии SHA-1. Он же в дальнейшем продолжил поиск практических методов взлома вместе с коллегами из Google.
Компания Google давно выразила своё недоверие SHA-1, особенно в качестве использования этой функции для подписи сертификатов TLS. Ещё в 2014 году, вскоре после публикации работы Стивенса, группа разработчиков Chrome объявила о постепенном отказе от использования SHA-1. Теперь они надеются, что практическая атака на SHA-1 увеличит понимание у сообщества информационной безопасности, так что многие ускорят отказ от SHA-1.
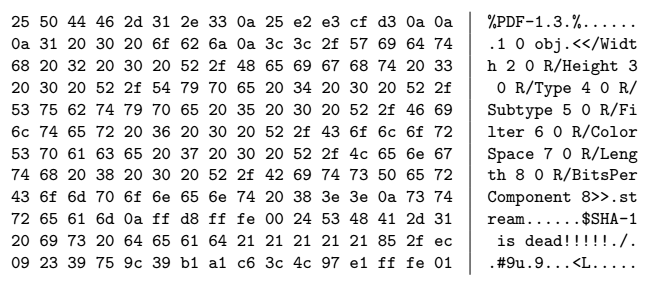
Специалисты начали поиск практического метода атаки с создания PDF-префикса, специально подобранного для генерации двух документов с разным контентом, но одинаковым хешем SHA-1.
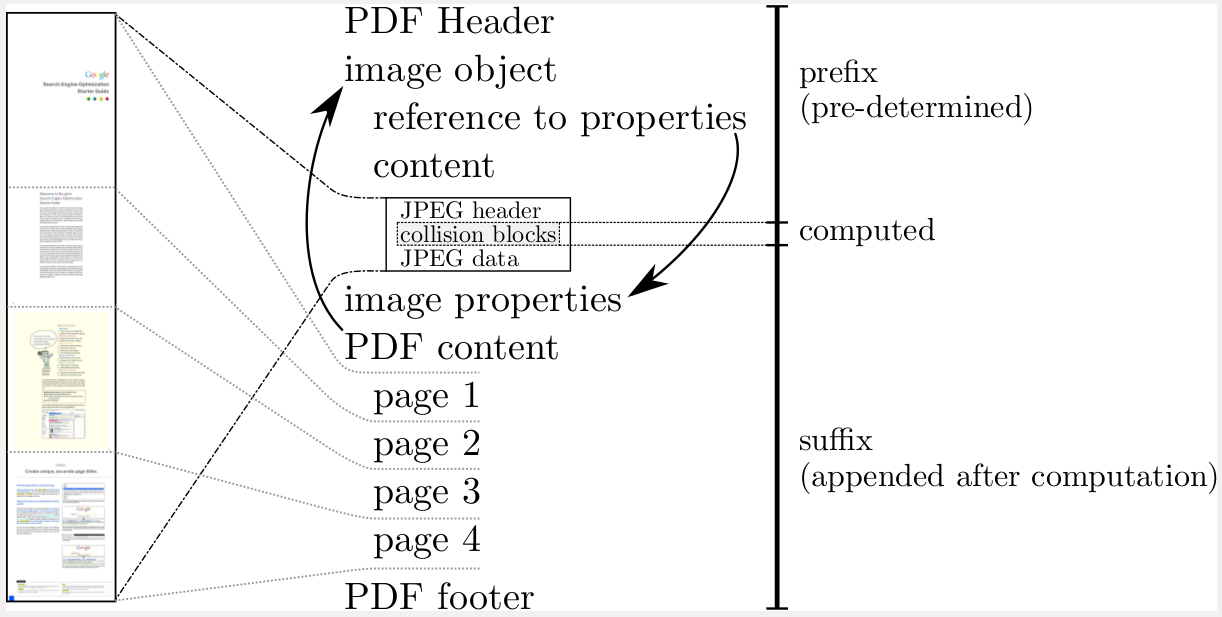
PDF-префикс
Идентичный префикс для коллизии, рассчитанной на инфраструктуре Google
Затем они использовали инфраструктуру Google, чтобы произвести вычисления и проверить теоретические выкладки. Разработчики говорят, что это было одно из самых крупных вычислений, которые когда-либо проводила компания Google. В общей сложности было произведено девять квинтиллионов вычислений SHA-1 (9 223 372 036 854 775 808), что потребовало 6500 процессорных лет на первой фазе и 110 лет GPU на второй фазе атаки.
Числа кажутся большими, но на самом деле такая атака вполне практически реализуема для злоумышленника, у которого есть крупный компьютерный кластер или просто деньги на оплату процессорного времени в облаке. По оценке Google, атака проводится примерно в 100 000 быстрее, чем брутфорс, который можно считать непрактичным.
Чтобы представить число хешей, которые обсчитала Google во время брутфорса, можно упомянуть, что примерно такое же количество хешей SHA-256 обсчитывается в сети Bitcoin каждые три секунды, так что в атаке нет ничего фантастического. Вполне можно предположить, что в криптографических отделах некоторых организаций с большими дата-центрами уже давно обсчитываются коллизии SHA-1. Правда, чтобы подобрать коллизию для конкретного сертификата TLS, нужен какой-то другой метод, потому что идентичный префикс из научной работы Google для PDF там не подойдёт. С другой стороны, содержимое сертификатов во многом совпадает, так что теоретически префикс для коллизии можно подобрать.
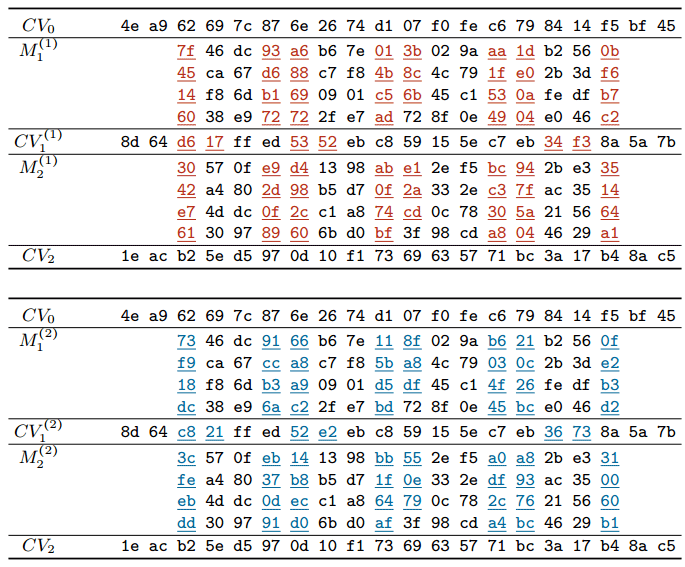
Сейчас Марк Стивенс с соавторами опубликовали научную работу, в которой описывают общие принципы генерации документов с блоками сообщений, которые подвержены коллизии SHA-1.
Блоки сообщений, которые подвержены коллизии SHA-1
В соответствии с принятыми правилами раскрытия уязвимостей Google обещает через 90 дней опубликовать в открытом доступе полный код для проведения атаки. Тогда кто угодно может создавать разные документы с одинаковыми цифровыми подписями SHA-1. Возможно, даже разные сертификаты, разные обновления программного обеспечения в Git, разные раздачи на торрентах (хеши DHT), разные старые ключи PGP/GPG и т.д. Впрочем, не стоит преувеличивать опасность таких атак, ведь далеко не каждый документ будет подвержен атаке на поиск коллизии. То есть злоумышленнику придётся изначально создавать два файла: один «хороший», а второй «плохой» с такой же подписью. Затем распространять «хороший» документ по нормальным каналам (например, через Git или торрент-трекер), а впоследствии пробовать подменить его «плохим» файлом с той же цифровой подписью. Впрочем, всё это чисто теоретические рассуждения.
Защита от документов, подверженных коллизии хешей SHA-1 уже встроена в программное обеспечение Gmail и GSuite. Как уже упоминалось выше, детектор уязвимых документов работает в открытом доступе на сайте shattered.io. Кроме того, библиотека для обнаружения коллизий опубликована на Github.
В качестве защиты от атаки на отыскание коллизий SHA-1 компания Google рекомендует перейти на более качественные криптографические хеш-функции SHA-256 и SHA-3.

