Определиться, какую книгу по программированию читать следующей, трудно, да и рискованно.
Как и положено разработчику, наверняка, у вас мало времени, и львиную его долю вы тратите на чтение книг. Вы могли бы программировать. Вы могли бы отдыхать. Но вместо этого вы выделяете драгоценное время на развитие своих навыков.

Итак, какую книгу вам стоит прочитать? Мы с коллегами часто обсуждаем прочитанную литературу, и я заметил, что наши мнения по конкретным книгам сильно отличаются.
Поэтому я решил углубиться в проблему. Моя идея была такова: проанализировать самый популярный в мире ресурс для программистов на предмет ссылок на известный книжный магазин, а затем подсчитать, сколько раз упоминается каждая из книг.
К счастью, Stack Exchange (материнская компания Stack Overflow) только что опубликовала свой дамп данных. Я сел и начал кодить.
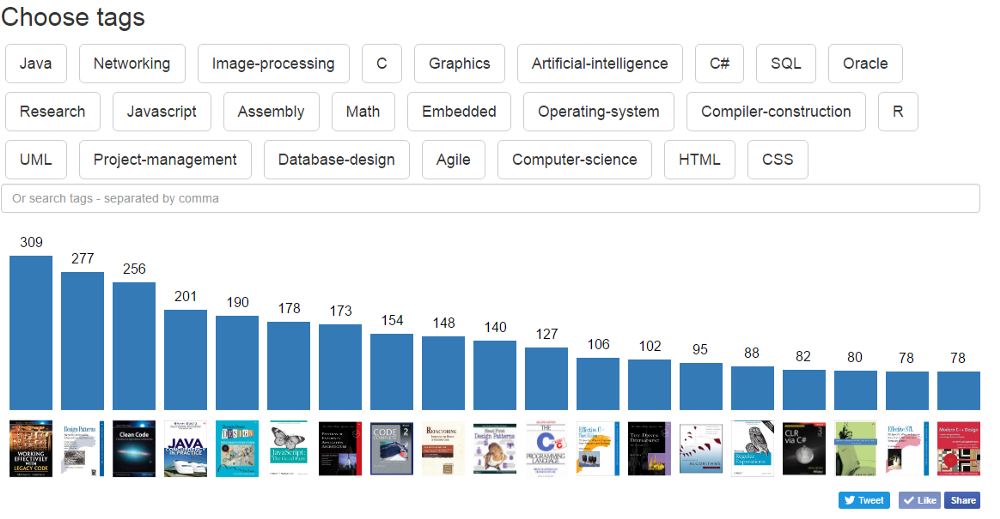
Скриншот созданного мной инструмента: dev-books.com
Вскоре после этого я запустил dev-books.com, который позволяет вам изучать все собранные и отсортированные мной данные. В итоге я получил более 100 000 посетителей и множество отзывов, в которых люди просили описать весь технический процесс.
Итак, сегодня я расскажу вам, как я все это сделал.
Получение и импорт данных
Я взял дамп базы данных Stack Exchange из archive.org.
С самого начала я понял, что невозможно импортировать XML-файл размером 48 ГБ в только что созданную базу данных (PostgreSQL) с использованием популярных методов, таких как myxml: = pg_read_file ('path / to / my_file.xml'), потому что у меня не было 48 ГБ оперативной памяти на сервере. Поэтому я решил использовать парсер SAX.
Все значения хранились между тегами , поэтому я использовал скрипт Python для парсинга:
После трех дней импорта (за это время была импортирована почти половина XML) я понял, что допустил ошибку: значение ParentID должен было иметь вид ParentId.
В тот момент я не хотел ждать еще неделю и перешел с AMD E-350 (2 x 1.35GHz) на Intel G2020 (2 x 2.90GHz). Но и это не ускорило процесс.
Следующее решение — batch insert:
StringIO позволяет вам использовать переменную типа файла для обработки функции copy_from, которая использует COPY. Таким образом, весь процесс импорта занял всего лишь ночь.
Отлично, теперь настало время создавать индексы. Теоретически индексы GiST медленнее, чем GIN, но занимают меньше места. Поэтому я решил использовать GiST. Еще день спустя у меня был индекс, который занимал 70 ГБ.
Когда я попробовал ввести пару тестовых запросов, то понял, что для их обработки требуется слишком много времени. Почему? Из-за ожидания Disk I/O. SSD GOODRAM C40 120Gb очень помог, пусть это и не самый быстрый SSD на сегодняшний день.
Я создал новый кластер PostgreSQL:
Затем изменил путь в моем сервис конфиге (использовал дистрибутив Manjaro):
Я перезагрузил конфигурацию и запустил postgreSQL:
На этот раз потребовалась пара часов для импорта, но я использовал GIN. Индексирование занимало 20 ГБ памяти на SSD, а простые запросы обрабатывались меньше минуты.
Извлечение книг из базы данных
Когда мои данные были наконец импортированы, я начал искать посты, в которых упоминались книги, а затем скопировал их в отдельную таблицу с помощью SQL:
Следующим шагом было найти все гиперссылки внутри этих постов:
В этот момент я осознал, что StackOverflow проксирует такие ссылки следующим образом:
Я создал еще одну таблицу для всех постов со ссылками:
При этом я использовал регулярные выражения, чтобы извлечь все номера ISBN. Теги Stack Overflow я извлек в отдельную таблицу с помощью regexp_split_to_table.
После извлечения и подсчета данных по самым популярным тегам выяснилось, что топ-20 книг с максимальным количеством упоминаний примерно одинаков по всем тегам.
Мой следующий шаг: доработка тегов.
Идея заключалась в том, чтобы взять топ-20 наиболее часто упоминаемых книг по каждому тегу и исключать те книги, которые уже были обработаны.
Поскольку это была «разовая» работа, я решил воспользоваться массивами PostgreSQL. Я написал скрипт для создания запроса, вот такой:
С данными на руках я направился в Интернет.
Создание веб-приложения

Nginx vs. Apache
Поскольку я не веб-разработчик и определенно не эксперт в вопросах создания веб-интерфейсов, я решил сделать очень простое одностраничное приложение на базе стандартной темы от Bootstrap.
Я создал опцию «искать по тегу», а затем извлек самые популярные теги, чтобы сделать каждый поиск кликабельным.
Я визуализировал результаты поиска с помощью гистограммы. Пробовал также Hightcharts и D3, но они больше подходят для дашбордов. У них обнаружились некоторые проблемы с реагированием, и их оказалось довольно сложно настроить. Имея это в виду, я создал свою собственную чутко реагирующую диаграмму на основе SVG. Чтобы обеспечить эту чуткость реагирования, она должна была меняться при смене ориентации экрана:
Сбой веб-сервера
Едва я успел запустить dev-books.com, как уже обнаружил на своем сайте огромную толпу людей. Apache не мог обслуживать более 500 посетителей одновременно, поэтому я быстро настроил Nginx и по ходу дела переключился на него. Я был очень удивлен, когда количество посетителей в режиме реального времени тут же возросло до 800 человек.
Заключение
Надеюсь, что объяснил все достаточно ясно. Если у вас есть вопросы, не стесняйтесь задавать их. Вы можете найти меня в твиттере и на Facebook.
Как и обещал, в конце марта я опубликую свой полный отчет от Amazon.com и Google Analytics. Пока результаты получаются очень неожиданные.
Как и положено разработчику, наверняка, у вас мало времени, и львиную его долю вы тратите на чтение книг. Вы могли бы программировать. Вы могли бы отдыхать. Но вместо этого вы выделяете драгоценное время на развитие своих навыков.

Итак, какую книгу вам стоит прочитать? Мы с коллегами часто обсуждаем прочитанную литературу, и я заметил, что наши мнения по конкретным книгам сильно отличаются.
Поэтому я решил углубиться в проблему. Моя идея была такова: проанализировать самый популярный в мире ресурс для программистов на предмет ссылок на известный книжный магазин, а затем подсчитать, сколько раз упоминается каждая из книг.
К счастью, Stack Exchange (материнская компания Stack Overflow) только что опубликовала свой дамп данных. Я сел и начал кодить.

Скриншот созданного мной инструмента: dev-books.com
«Если вам любопытно, чаще всего рекомендуют книгу «Эффективная работа с унаследованным кодом» (Michael Feathers), а следом идет труд «Приёмы объектно-ориентированного проектирования. Паттерны проектирования» (Erich Gamma). Хотя названия у этих книг сухие, как пустыня Атакама, содержание у них, надо думать, довольно качественное. Вы можете сортировать книги по тегам, например, JavaScript, C, Graphics и так далее. Само собой, на этих двух наименованиях список рекомендаций не заканчивается, но это, безусловно, отличные варианты для старта, если вы только начинаете кодить или хотите прокачать свои навыки» — обзор на Lifehacker.com.
Вскоре после этого я запустил dev-books.com, который позволяет вам изучать все собранные и отсортированные мной данные. В итоге я получил более 100 000 посетителей и множество отзывов, в которых люди просили описать весь технический процесс.
Итак, сегодня я расскажу вам, как я все это сделал.
Получение и импорт данных
Я взял дамп базы данных Stack Exchange из archive.org.
С самого начала я понял, что невозможно импортировать XML-файл размером 48 ГБ в только что созданную базу данных (PostgreSQL) с использованием популярных методов, таких как myxml: = pg_read_file ('path / to / my_file.xml'), потому что у меня не было 48 ГБ оперативной памяти на сервере. Поэтому я решил использовать парсер SAX.
Все значения хранились между тегами , поэтому я использовал скрипт Python для парсинга:
def startElement(self, name, attributes):
if name == ‘row’:
self.cur.execute(“INSERT INTO posts (Id, Post_Type_Id, Parent_Id, Accepted_Answer_Id, Creation_Date, Score, View_Count, Body, Owner_User_Id, Last_Editor_User_Id, Last_Editor_Display_Name, Last_Edit_Date, Last_Activity_Date, Community_Owned_Date, Closed_Date, Title, Tags, Answer_Count, Comment_Count, Favorite_Count) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)”,
(
(attributes[‘Id’] if ‘Id’ in attributes else None),
(attributes[‘PostTypeId’] if ‘PostTypeId’ in attributes else None),
(attributes[‘ParentID’] if ‘ParentID’ in attributes else None),
(attributes[‘AcceptedAnswerId’] if ‘AcceptedAnswerId’ in attributes else None),
(attributes[‘CreationDate’] if ‘CreationDate’ in attributes else None),
(attributes[‘Score’] if ‘Score’ in attributes else None),
(attributes[‘ViewCount’] if ‘ViewCount’ in attributes else None),
(attributes[‘Body’] if ‘Body’ in attributes else None),
(attributes[‘OwnerUserId’] if ‘OwnerUserId’ in attributes else None),
(attributes[‘LastEditorUserId’] if ‘LastEditorUserId’ in attributes else None),
(attributes[‘LastEditorDisplayName’] if ‘LastEditorDisplayName’ in attributes else None),
(attributes[‘LastEditDate’] if ‘LastEditDate’ in attributes else None),
(attributes[‘LastActivityDate’] if ‘LastActivityDate’ in attributes else None),
(attributes[‘CommunityOwnedDate’] if ‘CommunityOwnedDate’ in attributes else None),
(attributes[‘ClosedDate’] if ‘ClosedDate’ in attributes else None),
(attributes[‘Title’] if ‘Title’ in attributes else None),
(attributes[‘Tags’] if ‘Tags’ in attributes else None),
(attributes[‘AnswerCount’] if ‘AnswerCount’ in attributes else None),
(attributes[‘CommentCount’] if ‘CommentCount’ in attributes else None),
(attributes[‘FavoriteCount’] if ‘FavoriteCount’ in attributes else None)
)
);
После трех дней импорта (за это время была импортирована почти половина XML) я понял, что допустил ошибку: значение ParentID должен было иметь вид ParentId.
В тот момент я не хотел ждать еще неделю и перешел с AMD E-350 (2 x 1.35GHz) на Intel G2020 (2 x 2.90GHz). Но и это не ускорило процесс.
Следующее решение — batch insert:
class docHandler(xml.sax.ContentHandler):
def __init__(self, cusor):
self.cusor = cusor;
self.queue = 0;
self.output = StringIO();
def startElement(self, name, attributes):
if name == ‘row’:
self.output.write(
attributes[‘Id’] + '\t` +
(attributes[‘PostTypeId’] if ‘PostTypeId’ in attributes else '\\N') + '\t' +
(attributes[‘ParentId’] if ‘ParentId’ in attributes else '\\N') + '\t' +
(attributes[‘AcceptedAnswerId’] if ‘AcceptedAnswerId’ in attributes else '\\N') + '\t' +
(attributes[‘CreationDate’] if ‘CreationDate’ in attributes else '\\N') + '\t' +
(attributes[‘Score’] if ‘Score’ in attributes else '\\N') + '\t' +
(attributes[‘ViewCount’] if ‘ViewCount’ in attributes else '\\N') + '\t' +
(attributes[‘Body’].replace('\\', '\\\\').replace('\n', '\\\n').replace('\r', '\\\r').replace('\t', '\\\t') if ‘Body’ in attributes else '\\N') + '\t' +
(attributes[‘OwnerUserId’] if ‘OwnerUserId’ in attributes else '\\N') + '\t' +
(attributes[‘LastEditorUserId’] if ‘LastEditorUserId’ in attributes else '\\N') + '\t' +
(attributes[‘LastEditorDisplayName’].replace('\n', '\\n') if ‘LastEditorDisplayName’ in attributes else '\\N') + '\t' +
(attributes[‘LastEditDate’] if ‘LastEditDate’ in attributes else '\\N') + '\t' +
(attributes[‘LastActivityDate’] if ‘LastActivityDate’ in attributes else '\\N') + '\t' +
(attributes[‘CommunityOwnedDate’] if ‘CommunityOwnedDate’ in attributes else '\\N') + '\t' +
(attributes[‘ClosedDate’] if ‘ClosedDate’ in attributes else '\\N') + '\t' +
(attributes[‘Title’].replace('\\', '\\\\').replace('\n', '\\\n').replace('\r', '\\\r').replace('\t', '\\\t') if ‘Title’ in attributes else '\\N') + '\t' +
(attributes[‘Tags’].replace('\n', '\\n') if ‘Tags’ in attributes else '\\N') + '\t' +
(attributes[‘AnswerCount’] if ‘AnswerCount’ in attributes else '\\N') + '\t' +
(attributes[‘CommentCount’] if ‘CommentCount’ in attributes else '\\N') + '\t' +
(attributes[‘FavoriteCount’] if ‘FavoriteCount’ in attributes else '\\N') + '\n'
);
self.queue += 1;
if (self.queue >= 100000):
self.queue = 0;
self.flush();
def flush(self):
self.output.seek(0);
self.cusor.copy_from(self.output, ‘posts’)
self.output.close();
self.output = StringIO();
StringIO позволяет вам использовать переменную типа файла для обработки функции copy_from, которая использует COPY. Таким образом, весь процесс импорта занял всего лишь ночь.
Отлично, теперь настало время создавать индексы. Теоретически индексы GiST медленнее, чем GIN, но занимают меньше места. Поэтому я решил использовать GiST. Еще день спустя у меня был индекс, который занимал 70 ГБ.
Когда я попробовал ввести пару тестовых запросов, то понял, что для их обработки требуется слишком много времени. Почему? Из-за ожидания Disk I/O. SSD GOODRAM C40 120Gb очень помог, пусть это и не самый быстрый SSD на сегодняшний день.
Я создал новый кластер PostgreSQL:
initdb -D /media/ssd/postgresq/dataЗатем изменил путь в моем сервис конфиге (использовал дистрибутив Manjaro):
vim /usr/lib/systemd/system/postgresql.service
Environment=PGROOT=/media/ssd/postgres
PIDFile=/media/ssd/postgres/data/postmaster.pidЯ перезагрузил конфигурацию и запустил postgreSQL:
systemctl daemon-reload
postgresql systemctl start postgresqlНа этот раз потребовалась пара часов для импорта, но я использовал GIN. Индексирование занимало 20 ГБ памяти на SSD, а простые запросы обрабатывались меньше минуты.
Извлечение книг из базы данных
Когда мои данные были наконец импортированы, я начал искать посты, в которых упоминались книги, а затем скопировал их в отдельную таблицу с помощью SQL:
CREATE TABLE books_posts AS SELECT * FROM posts WHERE body LIKE ‘%book%’”;Следующим шагом было найти все гиперссылки внутри этих постов:
CREATE TABLE http_books AS SELECT * posts WHERE body LIKE ‘%http%’”;В этот момент я осознал, что StackOverflow проксирует такие ссылки следующим образом:
rads.stackowerflow.com/[$isbn]/Я создал еще одну таблицу для всех постов со ссылками:
CREATE TABLE rads_posts AS SELECT * FROM posts WHERE body LIKE ‘%http://rads.stackowerflow.com%'";При этом я использовал регулярные выражения, чтобы извлечь все номера ISBN. Теги Stack Overflow я извлек в отдельную таблицу с помощью regexp_split_to_table.
После извлечения и подсчета данных по самым популярным тегам выяснилось, что топ-20 книг с максимальным количеством упоминаний примерно одинаков по всем тегам.
Мой следующий шаг: доработка тегов.
Идея заключалась в том, чтобы взять топ-20 наиболее часто упоминаемых книг по каждому тегу и исключать те книги, которые уже были обработаны.
Поскольку это была «разовая» работа, я решил воспользоваться массивами PostgreSQL. Я написал скрипт для создания запроса, вот такой:
SELECT *
, ARRAY(SELECT UNNEST(isbns) EXCEPT SELECT UNNEST(to_exclude ))
, ARRAY_UPPER(ARRAY(SELECT UNNEST(isbns) EXCEPT SELECT UNNEST(to_exclude )), 1)
FROM (
SELECT *
, ARRAY[‘isbn1’, ‘isbn2’, ‘isbn3’] AS to_exclude
FROM (
SELECT
tag
, ARRAY_AGG(DISTINCT isbn) AS isbns
, COUNT(DISTINCT isbn)
FROM (
SELECT *
FROM (
SELECT
it.*
, t.popularity
FROM isbn_tags AS it
LEFT OUTER JOIN isbns AS i on i.isbn = it.isbn
LEFT OUTER JOIN tags AS t on t.tag = it.tag
WHERE it.tag in (
SELECT tag
FROM tags
ORDER BY popularity DESC
LIMIT 1 OFFSET 0
)
ORDER BY post_count DESC LIMIT 20
) AS t1
UNION ALL
SELECT *
FROM (
SELECT
it.*
, t.popularity
FROM isbn_tags AS it
LEFT OUTER JOIN isbns AS i on i.isbn = it.isbn
LEFT OUTER JOIN tags AS t on t.tag = it.tag
WHERE it.tag in (
SELECT tag
FROM tags
ORDER BY popularity DESC
LIMIT 1 OFFSET 1
)
ORDER BY post_count
DESC LIMIT 20
) AS t2
UNION ALL
SELECT *
FROM (
SELECT
it.*
, t.popularity
FROM isbn_tags AS it
LEFT OUTER JOIN isbns AS i on i.isbn = it.isbn
LEFT OUTER JOIN tags AS t on t.tag = it.tag
WHERE it.tag in (
SELECT tag
FROM tags
ORDER BY popularity DESC
LIMIT 1 OFFSET 2
)
ORDER BY post_count DESC
LIMIT 20
) AS t3
...
UNION ALL
SELECT *
FROM (
SELECT
it.*
, t.popularity
FROM isbn_tags AS it
LEFT OUTER JOIN isbns AS i on i.isbn = it.isbn
LEFT OUTER JOIN tags AS t on t.tag = it.tag
WHERE it.tag in (
SELECT tag
FROM tags
ORDER BY popularity DESC
LIMIT 1 OFFSET 78
)
ORDER BY post_count DESC
LIMIT 20
) AS t79
) AS tt
GROUP BY tag
ORDER BY max(popularity) DESC
) AS ttt
) AS tttt
ORDER BY ARRAY_upper(ARRAY(SELECT UNNEST(arr) EXCEPT SELECT UNNEST(la)), 1) DESC;С данными на руках я направился в Интернет.
Создание веб-приложения

Nginx vs. Apache
Поскольку я не веб-разработчик и определенно не эксперт в вопросах создания веб-интерфейсов, я решил сделать очень простое одностраничное приложение на базе стандартной темы от Bootstrap.
Я создал опцию «искать по тегу», а затем извлек самые популярные теги, чтобы сделать каждый поиск кликабельным.
Я визуализировал результаты поиска с помощью гистограммы. Пробовал также Hightcharts и D3, но они больше подходят для дашбордов. У них обнаружились некоторые проблемы с реагированием, и их оказалось довольно сложно настроить. Имея это в виду, я создал свою собственную чутко реагирующую диаграмму на основе SVG. Чтобы обеспечить эту чуткость реагирования, она должна была меняться при смене ориентации экрана:
var w = $('#plot').width();
var bars = "";var imgs = "";
var texts = "";
var rx = 10;
var tx = 25;
var max = Math.floor(w / 60);
var maxPop = 0;
for(var i =0; i < max; i ++){
if(i > books.length - 1 ){
break;
}
obj = books[i];
if(maxPop < Number(obj.pop)) {
maxPop = Number(obj.pop);
}
}
for(var i =0; i < max; i ++){
if(i > books.length - 1){
break;
}
obj = books[i];
h = Math.floor((180 / maxPop ) * obj.pop);
dt = 0;
if(('' + obj.pop + '').length == 1){
dt = 5;
}
if(('' + obj.pop + '').length == 3){
dt = -3;
}
var scrollTo = 'onclick="scrollTo(\''+ obj.id +'\'); return false;" "';
bars += '<rect id="rect'+ obj.id +'" class="cla" x="'+ rx +'" y="' + (180 - h + 30) + '" width="50" height="' + h + '" ' + scrollTo + '>';
bars += '<title>' + obj.name+ '</title>';
bars += '</rect>';
imgs += '<image height="70" x="'+ rx +'" y="220" href="img/ol/jpeg/' + obj.id + '.jpeg" onmouseout="unhoverbar('+ obj.id +');" onmouseover="hoverbar('+ obj.id +');" width="50" ' + scrollTo + '>';
imgs += '<title>' + obj.name+ '</title>';
imgs += '</image>';
texts += '<text x="'+ (tx + dt) +'" y="'+ (180 - h + 20) +'" class="bar-label" style="font-size: 16px;" ' + scrollTo + '>' + obj.pop + '</text>';
rx += 60;
tx += 60;
}
$('#plot').html(
' <svg width="100%" height="300" aria-labelledby="title desc" role="img">'
+ ' <defs> '
+ ' <style type="text/css"><![CDATA['
+ ' .cla {'
+ ' fill: #337ab7;'
+ ' }'
+ ' .cla:hover {'
+ ' fill: #5bc0de;'
+ ' }'
+ ' ]]></style>'
+ ' </defs>'
+ ' <g class="bar">'
+ bars
+ ' </g>'
+ ' <g class="bar-images">'
+ imgs
+ ' </g>'
+ ' <g class="bar-text">'
+ texts
+ ' </g>'
+ '</svg>');Сбой веб-сервера
Едва я успел запустить dev-books.com, как уже обнаружил на своем сайте огромную толпу людей. Apache не мог обслуживать более 500 посетителей одновременно, поэтому я быстро настроил Nginx и по ходу дела переключился на него. Я был очень удивлен, когда количество посетителей в режиме реального времени тут же возросло до 800 человек.
Заключение
Надеюсь, что объяснил все достаточно ясно. Если у вас есть вопросы, не стесняйтесь задавать их. Вы можете найти меня в твиттере и на Facebook.
Как и обещал, в конце марта я опубликую свой полный отчет от Amazon.com и Google Analytics. Пока результаты получаются очень неожиданные.
