Всем привет, я занимаюсь разработкой Frontera, первым в истории фреймворком для масштабного обхода интернета сделанным на Python-е, с открытым исходным кодом. С помощью Фронтеры можно легко сделать робота который сможет выкачивать контент со скоростью тысяч страниц в секунду, при этом следуя вашей стратегии обхода и используя обычную реляционную БД или KV-хранилище для хранения базы ссылок и очереди.
Разработка Фронтеры финансируется компанией Scrapinghub Ltd., имеет полностью открытый исходный код (находится на GitHub, BSD 3-clause лицензия) и модульную архитектуру. Мы стараемся чтобы и процесс разработки тоже был максимально прозрачным и открытым.
В этой статье я собираюсь рассказать о проблемах с которыми мы столкнулись при разработке Фронтеры и эксплуатации роботов на ее основе.
Устройство распределенного робота на базе Фронтеры выглядит так:
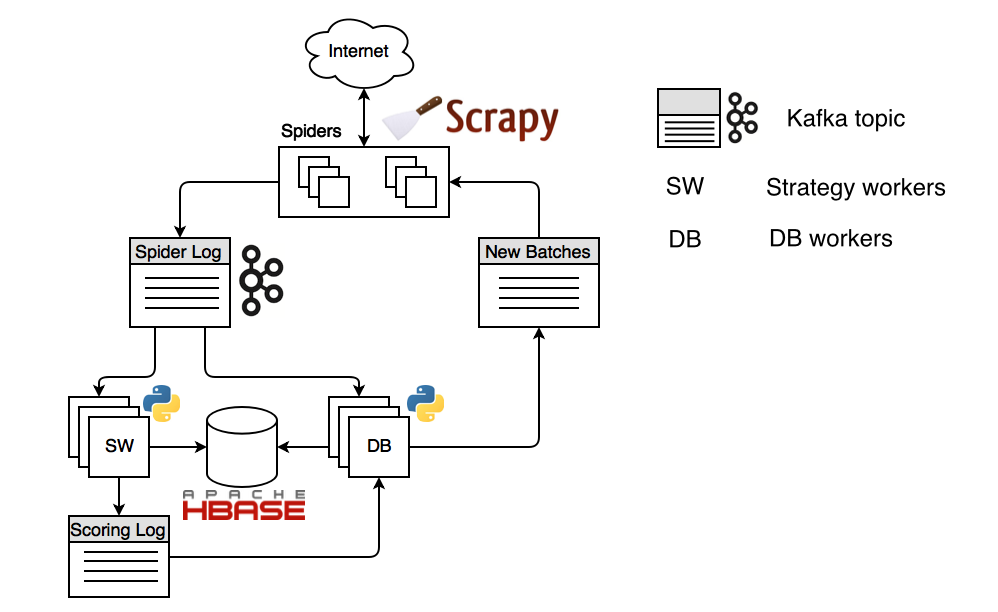
На картинке изображена конфигурация с хранилищем Apache HBase и шиной данных Apache Kafka. Процесс запускается из воркера стратегии обхода (SW), который планирует URL-ы, с которых нужно начать обход. Эти URL-ы попадают «scoring log», топик кафки (выделенный канал сообщений), потребляются воркером БД и им же планируются в топик «new batches», откуда поступают в пауки на основе Scrapy. Паук Scrapy разрешает DNS имя, поддерживает пул открытых соединений, получает контент и посылает его в топик «spider log». Откуда контент потребляется снова воркером стратегии и в зависимости от логики закодированной в стратегии обхода он планирует новые URL-ы.
Если кому-то интересно, то вот видео моего доклада о том, как мы обходили испанский интернет с помощью Фронтеры.
На текущий момент мы столкнулись с тем, что людям которые пытаются развернуть робота у себя очень тяжело дается конфигурирование распределенных компонент. К сожалению, развертывание Фронтеры на кластере предполагает понимание ее архитектуры, чтение документации, правильную настройку шины данных (message bus) и хранилища под нее. Все это очень затратно по времени и отнюдь не для начинающих. Поэтому мы хотим автоматизировать развертывание на кластере. Мы выбрали Kubernetes и Docker для достижения этих целей. Большой плюс Kubernetes в том, что он поддерживается многими облачными провайдерами (AWS, Rackspace, GCE и др.) Т.е. с помощью него можно будет развернуть Фронтеру даже не имея настроенного Kubernetes кластера.
Другая проблема в том, что Фронтера она как система водоснабжения ядерной электростанции. В ней есть потребители и производители для них очень важно контролировать такие характеристики, как скорость потока и производительность, в разных местах системы. Здесь следует напомнить, что Frontera это онлайн система. Классические роботы (Apache Nutch), напротив, работают в пакетном режиме: сначала порция планируется, затем скачивается, затем парсится и снова планируется. Одновременный парсинг и планирование не предусмотрены в таких системах. Таким образом, у нас встает проблема синхронизации скорости работы разных компонент. Довольно тяжело спроектировать робота, который обходит страницы с постоянной производительностью с большим количеством потоков, при этом сохраняет их в хранилище и планирует новые. Разнится скорость ответа веб-серверов, размер и количество страниц на сайте, количество ссылок, все это делает невозможным точную подгонку компонент по производительности. В качестве решения этой проблемы мы хотим сделать веб-интерфейс на базе Django. Он будет отображать основные параметры и если получится подсказывать какие нужно принять меры оператору робота.
Я уже упоминал о модульной архитектуре. Как и любой проект с открытым кодом мы стремимся к разнообразию технологий, которые мы поддерживаем. Поэтому сейчас у нас в Pull Request’ах готовится поддержка распределенного Redis, было уже две попытки сделать поддержку Apache Cassandra, ну и мы бы хотели поддержку RabbitMQ в качестве шины данных.
Все эти проблемы мы рассчитываем хотя бы частично решить в рамках Google Summer Of Code 2017. Если Вам что-то кажется интересным, и Вы студент, то дайте нам знать на frontera@scrapinghub.com и подайте заявку через форму GSoC. Подача заявок начинается с 20 марта и продлится до 3 апреля. Полное расписание GSoC 2017 здесь.
Конечно же, есть еще и проблемы производительности. На данный момент в Scrapinghub в пилотном режиме работает сервис по массивному скачиванию страниц на основе Фронтеры. Клиент нам предоставляет набор доменов, к которым он бы хотел получить контент, а мы их скачиваем и помещаем в S3 хранилище. Оплата за скачанный объем. В таких условиях мы стараемся качать как можно больше страниц в единицу времени. При попытке масштабировать Фронтеру до 60 спайдеров мы с толкнулись с тем, что HBase (через Thrift интерфейс) деградирует при записи в него всех найденных ссылок. Эти данные мы называем ссылочной базой, а нужна она для того, чтобы знать когда и что мы скачали, какой ответ получили и т.п. На кластере из 7 регион серверов у нас кол-во запросов доходит до 40-50K в секунду и при таких объемах время ответа сильно увеличивается. Производительность записи сильно падает. Решать такую проблему можно разными способами: например сохранять в отдельный быстрый лог, а позже его пакетными методами записывать в HBase, или же обращаться в HBase напрямую минуя Thrift, через собственный Java клиент.
Также мы постоянно работаем над улучшением надежности. Слишком большой скачанный документ или внезапные сетевые проблемы не должны приводить к остановке компонент. Тем не менее это иногда случается. Для диагностики таких случаев мы сделали обработчик сигнала ОС SIGUSR1, который сохраняет в лог текущий стек процесса. Несколько раз нам это очень сильно помогло разобраться в чем была проблема.
Мы планируем и дальше улучшать Фронтеру, и надеемся что сообщество активных разработчиков будет расти.
Разработка Фронтеры финансируется компанией Scrapinghub Ltd., имеет полностью открытый исходный код (находится на GitHub, BSD 3-clause лицензия) и модульную архитектуру. Мы стараемся чтобы и процесс разработки тоже был максимально прозрачным и открытым.
В этой статье я собираюсь рассказать о проблемах с которыми мы столкнулись при разработке Фронтеры и эксплуатации роботов на ее основе.
Устройство распределенного робота на базе Фронтеры выглядит так:
На картинке изображена конфигурация с хранилищем Apache HBase и шиной данных Apache Kafka. Процесс запускается из воркера стратегии обхода (SW), который планирует URL-ы, с которых нужно начать обход. Эти URL-ы попадают «scoring log», топик кафки (выделенный канал сообщений), потребляются воркером БД и им же планируются в топик «new batches», откуда поступают в пауки на основе Scrapy. Паук Scrapy разрешает DNS имя, поддерживает пул открытых соединений, получает контент и посылает его в топик «spider log». Откуда контент потребляется снова воркером стратегии и в зависимости от логики закодированной в стратегии обхода он планирует новые URL-ы.
Если кому-то интересно, то вот видео моего доклада о том, как мы обходили испанский интернет с помощью Фронтеры.
На текущий момент мы столкнулись с тем, что людям которые пытаются развернуть робота у себя очень тяжело дается конфигурирование распределенных компонент. К сожалению, развертывание Фронтеры на кластере предполагает понимание ее архитектуры, чтение документации, правильную настройку шины данных (message bus) и хранилища под нее. Все это очень затратно по времени и отнюдь не для начинающих. Поэтому мы хотим автоматизировать развертывание на кластере. Мы выбрали Kubernetes и Docker для достижения этих целей. Большой плюс Kubernetes в том, что он поддерживается многими облачными провайдерами (AWS, Rackspace, GCE и др.) Т.е. с помощью него можно будет развернуть Фронтеру даже не имея настроенного Kubernetes кластера.
Другая проблема в том, что Фронтера она как система водоснабжения ядерной электростанции. В ней есть потребители и производители для них очень важно контролировать такие характеристики, как скорость потока и производительность, в разных местах системы. Здесь следует напомнить, что Frontera это онлайн система. Классические роботы (Apache Nutch), напротив, работают в пакетном режиме: сначала порция планируется, затем скачивается, затем парсится и снова планируется. Одновременный парсинг и планирование не предусмотрены в таких системах. Таким образом, у нас встает проблема синхронизации скорости работы разных компонент. Довольно тяжело спроектировать робота, который обходит страницы с постоянной производительностью с большим количеством потоков, при этом сохраняет их в хранилище и планирует новые. Разнится скорость ответа веб-серверов, размер и количество страниц на сайте, количество ссылок, все это делает невозможным точную подгонку компонент по производительности. В качестве решения этой проблемы мы хотим сделать веб-интерфейс на базе Django. Он будет отображать основные параметры и если получится подсказывать какие нужно принять меры оператору робота.
Я уже упоминал о модульной архитектуре. Как и любой проект с открытым кодом мы стремимся к разнообразию технологий, которые мы поддерживаем. Поэтому сейчас у нас в Pull Request’ах готовится поддержка распределенного Redis, было уже две попытки сделать поддержку Apache Cassandra, ну и мы бы хотели поддержку RabbitMQ в качестве шины данных.
Все эти проблемы мы рассчитываем хотя бы частично решить в рамках Google Summer Of Code 2017. Если Вам что-то кажется интересным, и Вы студент, то дайте нам знать на frontera@scrapinghub.com и подайте заявку через форму GSoC. Подача заявок начинается с 20 марта и продлится до 3 апреля. Полное расписание GSoC 2017 здесь.
Конечно же, есть еще и проблемы производительности. На данный момент в Scrapinghub в пилотном режиме работает сервис по массивному скачиванию страниц на основе Фронтеры. Клиент нам предоставляет набор доменов, к которым он бы хотел получить контент, а мы их скачиваем и помещаем в S3 хранилище. Оплата за скачанный объем. В таких условиях мы стараемся качать как можно больше страниц в единицу времени. При попытке масштабировать Фронтеру до 60 спайдеров мы с толкнулись с тем, что HBase (через Thrift интерфейс) деградирует при записи в него всех найденных ссылок. Эти данные мы называем ссылочной базой, а нужна она для того, чтобы знать когда и что мы скачали, какой ответ получили и т.п. На кластере из 7 регион серверов у нас кол-во запросов доходит до 40-50K в секунду и при таких объемах время ответа сильно увеличивается. Производительность записи сильно падает. Решать такую проблему можно разными способами: например сохранять в отдельный быстрый лог, а позже его пакетными методами записывать в HBase, или же обращаться в HBase напрямую минуя Thrift, через собственный Java клиент.
Также мы постоянно работаем над улучшением надежности. Слишком большой скачанный документ или внезапные сетевые проблемы не должны приводить к остановке компонент. Тем не менее это иногда случается. Для диагностики таких случаев мы сделали обработчик сигнала ОС SIGUSR1, который сохраняет в лог текущий стек процесса. Несколько раз нам это очень сильно помогло разобраться в чем была проблема.
Мы планируем и дальше улучшать Фронтеру, и надеемся что сообщество активных разработчиков будет расти.
