 Эванс написал хорошую книжку с хорошими идеями. Но этим идеям не хватает методологической основы. Опытным разработчикам и архитекторам на интуитивном уровне понятно, что надо быть как можно ближе к предметной области заказчика, что с заказчиком надо разговаривать. Но не понятно как оценить проект на соответствие Ubiquitous Language и реального языка заказчика? Как понять, что домен разделен на Bounded Context правильно? Как вообще определить используется DDD в проекте или нет?
Эванс написал хорошую книжку с хорошими идеями. Но этим идеям не хватает методологической основы. Опытным разработчикам и архитекторам на интуитивном уровне понятно, что надо быть как можно ближе к предметной области заказчика, что с заказчиком надо разговаривать. Но не понятно как оценить проект на соответствие Ubiquitous Language и реального языка заказчика? Как понять, что домен разделен на Bounded Context правильно? Как вообще определить используется DDD в проекте или нет?Последний пункт особенно актуален. На одном из своих выступлений Грег Янг попросил поднять руки тех, кто практиукует DDD. А потом попросил опустить тех, кто создает классы с набором публичных геттеров и сеттеров, располагает логику в «сервисах» и «хелперах» и называет это DDD. По залу прошел смешок:)
Как же правильно структурировать бизнес-логику в DDD-стиле? Где хранить «поведение»: в сервисах, сущностях, extension-методах или везде по чуть-чуть? В статье я расскажу о том, как проектирую предметную область и какими правилами пользуюсь.
Все люди лгут
 Не специально конечно:) Дело в том, что бизнес-приложения создаются для широкого спектра задач и удовлетоврения интересов различных групп пользователей. Бизнес-процессы от начала до конца в лучшем случае понимает только топ-менеджмент. Не редко понимает неверно, кстати. Внутри подразделенеий пользователи видят только некоторую часть. Поэтому результатом интервьюирования всех заинтересованных сторон обычно становится клубок противоречий. Из этого правила вытекает следующее.
Не специально конечно:) Дело в том, что бизнес-приложения создаются для широкого спектра задач и удовлетоврения интересов различных групп пользователей. Бизнес-процессы от начала до конца в лучшем случае понимает только топ-менеджмент. Не редко понимает неверно, кстати. Внутри подразделенеий пользователи видят только некоторую часть. Поэтому результатом интервьюирования всех заинтересованных сторон обычно становится клубок противоречий. Из этого правила вытекает следующее.Сначала аналитика, потом проектирование и лишь затем — разработка
 Начинать нужно не со структуры БД или набора классов, а с бизнес-процессов. Мы используем BPMN и UML Activity в сочетнии с контрольными примерами. Диаграммы хорошо читаются даже теми, кто не знаком со стандартами. Контрольные примеры в табличной форме помогают лучше обозначить пограничные кейсы и устранить противоречия.
Начинать нужно не со структуры БД или набора классов, а с бизнес-процессов. Мы используем BPMN и UML Activity в сочетнии с контрольными примерами. Диаграммы хорошо читаются даже теми, кто не знаком со стандартами. Контрольные примеры в табличной форме помогают лучше обозначить пограничные кейсы и устранить противоречия.Абстрактные разговоры — просто потеря времени. Люди убеждены, что детали не значительны и «незачем вообще их обсуждать, ведь все уже ясно». Просьба заполнить таблицу контрольных примеров наглядно показывает, что вариантов на самом деле не 3 а 26 (это не преувеличение, а результат аналитики на одном из наших проектов).
Таблицы и диаграммы — основной инструмент коммуникации между бизнесом, аналитикой и разработкой. Параллельно составлению BPMN — диаграмм и таблиц контрольных примеров начинаем записывать термины в тезаурус проекта. Словарь поможет позже для проектирования сущностей.
Выделяем контексты
 Единую предметную модель для всего приложения можно создать только в случае, когда на уровне топ-менеджмента принята и реализована политика использования единого непротиворечивого языка в рамках всей организации. Т.е. когда отдел продаж говорит производству «аккаунт», они оба понимают слово одинаково. Это один и тот же аккаунт, а не «аккаунт в CRM» и «юр.лицо клиента».
Единую предметную модель для всего приложения можно создать только в случае, когда на уровне топ-менеджмента принята и реализована политика использования единого непротиворечивого языка в рамках всей организации. Т.е. когда отдел продаж говорит производству «аккаунт», они оба понимают слово одинаково. Это один и тот же аккаунт, а не «аккаунт в CRM» и «юр.лицо клиента». В реальной жизни я такого не видел. Поэтому желательно сразу грубо «нарезать» предметную модель на несколько частей. Чем меньше они связаны, тем лучше. Обычно все-таки получается нащупать некоторый набор общих терминов. Я называю это ядром предметной области. Любой контекст может зависеть от ядра. При этом крайне желательно избегать зависимостей между контекстами. Потенциально такой подход приводит к «распуханию» ядра, однако взаимная зависимость контекстов порождает сильную связность, что хуже «толстого» ядра.
Архитектура
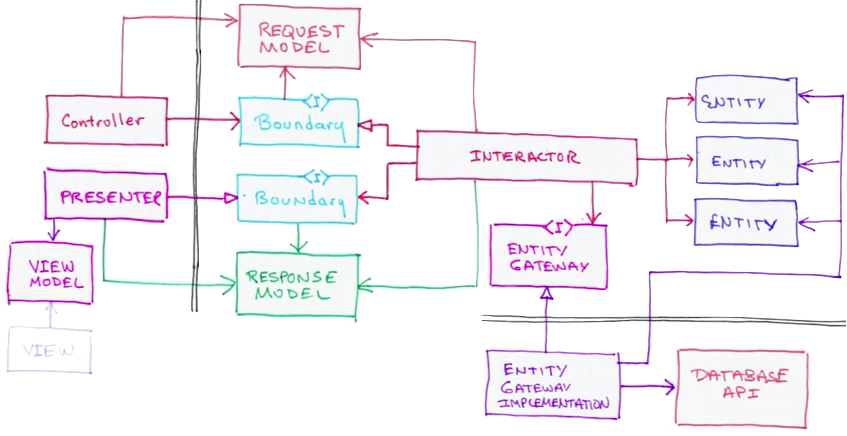
Порты и адаптеры, луковая архитектура, clean architecture — все эти подходы базируются на идее использовать домен в качестве ядра приложения. Эванс вскользь затрагивает этот вопрос, когда говорит о «домене» и «инфраструктуре». Бизнес-логика не оперирует понятиями «транзакция», «база данных», «контроллер», «lazy load» и т.д. n-layer — архитектура не позволяет разнести эти понятия. Запрос будет приходить в контроллер, передаваться в «бизнес-логику», а «бизнес-логика» будет взаимодействовать с
DAL. А DAL это сплошные «транзакции», «таблицы», «блокировки» и т.д. Clean Architecture позволяет инвертиртировать зависимости и отделить мух от котлет. Конечно совсем абстрагироваться от деталей реализации не получится. RDBMS, ORM, сетевое взаимодействие все-равно наложат свои ограничения. Но в случае использования Clean Architecture это можно контролировать. В n-layer придерживаться «единого языка» гораздо сложнее из-за того что на самом нижнем слое лежит структура хранения.Clean Architecture хорошо работает в паре с Bounded Context. Разные контексты могут представлять собой разные подсистемы. Простые контексты лучше реализовывать с помощью простого CRUD. Для контекстов с асимметричной нагрузкой хорошо подойдет CQRS. Для подсистем, требующих Audit Log'а есть смысл использовать Event Sourcing. Для нагруженных на чтение и запись подсистемах с ограничениями по пропускной способности и задержкам есть смысл рассмотреть event driven — подход. На первый взгляд это может показаться неудобным. Например я работал с CRUD-подсистемой и мне пришла задача из CQRS-подсистемы. Придется некоторе время смотреть на все эти Command и Query как на новые ворота. Альтернатива — проектировать систему в едином стиле — недальновидна. Архитектура — это набор инструментов, а каждый инструмент подходит для решения конкретной задачи.Структура проекта
.NET-проекты я структурирую следущим образом:
/App /ProjectName.Web.Public /ProjectName.Web.Admin /ProjectName.Web.SomeOtherStuff /Domain /ProjectName.Domain.Core /ProjectName.Domain.BoundedContext1 /ProjectName.Domain.BoundedContext1.Services /ProjectName.Domain.BoundedContext2 /ProjectName.Domain.BoundedContext2.Command /ProjectName.Domain.BoundedContext2.Query /ProjectName.Domain.BoundedContext3 /Data /ProjectName.Data /Libs /Problem1Resolver /Problem2Resolver
Проекты из папки
Libs не зависят от домена. Они решают только свою локальную задачу, например формирование отчетов, парсинг csv, механизмы кеширования и т.д. Структура домена соответствует BoundedContext'ам. Проекты из папки Domain не зависят от Data. В Data находятся DbContext, миграции, конфигурации, относящиеся к DAL. Data зависит от сущностей Domain для построения миграций. Проекты из папки App используют IOC-контейнер для внедерния зависимостей. Таким образом получается добиться максимальной изоляции кода домена от инфраструктуры.Моделируем сущности
Под сущностью будем понимать объект предметной области, обладающий уникальным идентификатором. Для примера возьмем класс, описывающий российскую компанию, в контексте получения аккредитации в неком ведомстве.
[DisplayName("Юридическое лицо (компания)")] public class Company : LongIdBase , IHasState<CompanyState> { public static class Specs { public static Spec<Supplier> ByInnAndKpp(string inn, string kpp) => new Spec<Supplier>(x => x.Inn == inn && x.Kpp == kpp); public static Spec<Supplier> ByInn(string inn) => new Spec<Supplier>(x => x.Inn == inn); } // Для EF protected Company () { } public Company (string inn, string kpp) { DangerouslyChangeInnAndKpp(inn, kpp); } public void DangerouslyChangeInnAndKpp(string inn, string kpp) { Inn = inn.NullIfEmpty() ?? throw new ArgumentNullException(nameof(inn)); Kpp = kpp.NullIfEmpty() ?? throw new ArgumentNullException(nameof(kpp)); this.ValidateProperties(); } [Display(Name = "ИНН")] [Required] [DisplayFormat(ConvertEmptyStringToNull = true)] [Inn] public string Inn { get; protected set; } [Display(Name = "КПП")] [DisplayFormat(ConvertEmptyStringToNull = true)] [Kpp] public string Kpp { get; protected set; } [Display(Name = "Статус организации")] public CompanyState State { get; protected set; } [DisplayFormat(ConvertEmptyStringToNull = true)] public string Comment { get; protected set; } [Display(Name = "Дата изменения статуса")] public DateTime? StateChangeDate { get; protected set; } public void Accept() { StateChangeDate = DateTime.UtcNow; State = AccreditationState.Accredited; } public void Decline(string comment) { StateChangeDate = DateTime.UtcNow; State = AccreditationState.Declined; Comment = comment.NullIfEmpty() ?? throw new ArgumentNullException(nameof(comment)); }
Чтобы правильно выбрать агрегаты и отношения зачастую одной итерации недостаточно. Сначала я накидываю основную структуру классов, определяю отношения один к одному, один ко многим и многие ко многим и описываю структуру данных. Затем трассирую структуру по бизнес процессам, сверяясь с BMPN и контрольными примерами. Если какой-то кейс не укладывается в структуру, значит при проектировании допущена ошибка и структуру необходимо изменить. Результирующую структуру можно оформить в виде диаграммы и дополнительно согласовать с экспертами в предметной области.
Эксперты могут указать на ошибки и неточности проектирования. Иногда в процессе выясняется, что для некоторых сущностей нет подходящего термина. Тогда я предлагаю варианты и через некоторое время находится подходящий. Новый термин вносится в тезаурус. Очень важно обсуждать и договариваться о терминологии совместно. Это исключает большой пласт проблем непонимания в будущем.
Выбор уникального идентификатора
К счастью, Эванс дает четкие рекомендации на этот счет: сначала ищем идентификатор в предметной области: ИНН, КПП, паспортные данные и т.д. Если нашли — используем его. Не нашли — полагаемся на
GUID или генерируемые базой данных Id. Иногда целесообразно использовать в качестве Id идентификатор, отличный от доменного, даже если последний существует. Например, если сущность должна быть версинируемой и система должна хранить все предыдущие версии или если идентификатор из предметной модели — сложный композит и не дружит с persistance.Настоящие конструкторы
Для материализации объектов ORM чаще всего используют reflection. EF сможет дотянуться до protected-конструктора, а программисты – нет. Им придется создать корректное юр. лицо, идентифицируемое по ИНН и КПП. Конструктор снабжен гардами. Создать не корректный объект просто не получится. Extension-метод
ValidateProperties вызывает валидацию по DataAnnotation — атрибутам, а NullIfEmpty не дает передать пустые строки.public static class Extensions { public static void ValidateProperties(this object obj) { var context = new ValidationContext(obj); Validator.ValidateObject(obj, context, true); } public static string NullIfEmpty(this string str) => string.IsNullOrEmpty(str) ? null : str; }
Для валидации ИНН специально написан атрибут следующего вида:
public class InnAttribute : RegularExpressionAttribute { public InnAttribute() : base(@"^(\d{10}|\d{12})$") { ErrorMessage = "ИНН должен быть последовательностью из 10/12 цифр."; } public InnAttribute(CivilLawSubject civilLawSubject) : base(civilLawSubject == CivilLawSubject.Individual ? @"^\d{12}$" : @"^\d{10}$") { ErrorMessage = civilLawSubject == CivilLawSubject.Individual ? "ИНН физического лица должен быть последовательностью из 12 цифр." : "ИНН юридического лица должен быть последовательностью из 10 цифр."; } }
Конструктора без параметров объявлен защищенным, чтобы его использовала только для ORM. Для материализации используется reflection, поэтому модификатор доступа — не помеха. В «настоящий» конструктор переданы оба необходимых поля: ИНН и КПП. Остальные поля юр.лица в контексте системы не обязательные и заполняются представителем компании позже.
Инкапсуляция и валидация
Свойства ИНН и КПП объявлены с protected — сеттером. EF опять сможет до них дотянуться, а программисту придется воспользоваться функцией
DangerouslyChangeInnAndKpp. Название функции явно намекает, что смена ИНН и КПП – ситуация не штатная. В функцию передается два параметра, что означает, что если менять ИНН и КПП, то только вместе. ИНН+КПП можно было бы даже сделать композитным ключом. Но для совместимости я оставил long Id. Наконец, при вызове этой функции сработают валидаторы и если ИНН и КПП не корректны, будет выброшен ValidationException.Можно еще больше усилить систему типов. Однако в описанном по ссылке подходе есть существенный недостаток: отсутствие поддержки со стороны стандартной инфраструктуры ASP.NET. Поддержку можно дописать, но такой инфраструктурный код чего-то стоит и его нужно сопровождать.
Свойства для чтения, специализированные методы для изменения
По бизнес-процессу организацию можно «принять» или «отклонить», причем в случае отклонения необходимо оставить комментарий. Если бы все свойства были публичными, то узнать об этом можно было только из документации. В данном случае правила смены статусов видны из сигнатур методов. В статье я привел только фрагмент класса юр.лица. На самом деле там гораздо больше полей и понимание что с чем связано очень помогает, особенно при подключении новых членов команды. Если свойство можно бесконтрольно менять в отрыве от других без явных бизнес-операций setter можно тоже сделать публичным. Однако такое свойство должно насторожить: если нет явных операций, связанных с данными, возможно эти данные не нужны?
Альтернативный вариант — использовать паттерн «состояние» и вынести поведение в отдельные классы.
Спецификации
Некоторое время было не ясно, что лучше писать extension’ы модифицирующие
Queryable или возиться с деревьями выражений. В конечном итоге, реализация LinqSpecs оказалась самой удобной.Extension-методы
Ad hoc полиморфизм для интерфейсов (чтобы не приходилось реализовывать методы в каждом наследнике) рано или поздно появится в C#. Пока приходится довольствоваться extension-методами.
public interface IHasId { object Id { get; } } public interface IHasId<out TKey> : IHasId where TKey: IEquatable<TKey> { new TKey Id { get; } } public static bool IsNew<TKey>(this IHasId<TKey> obj) where TKey : IEquatable<TKey> { return obj.Id == null || obj.Id.Equals(default(TKey)); }
Extension-методы подходят для использования в LINQ для большей выразительности. Однако, методы
ByInnAndKpp и ByInn нельзя использовать внутри других выражений. Их не сможет разобрать провайдер. Более подробно про использование extension-методов а-ля DSL рассказал Дино Эспозито на одном из DotNext.public static class CompanyDataExtensions { public static CompanyData ByInnAndKpp( this IQueryable<CompanyData> query, string inn, string kpp) => query .Where(x => x.Company, Supplier.Specs.ByInnAndKpp(inn, kpp)) .FirstOrDefault(); public static CompanyData ByInn( this IQueryable<CompanyData> query, string inn) => query .Where(x => x.Company, Supplier.Specs.ByInn(inn)); }
Обратите внимание на необычный Where с двумя параметрами.
EF Core стал поддерживать InvokeExpression. В прикладном коде используется так:var priceInfos = DbContext .CompanyData .ByInn("инн") .ToList();
Альтернативный вариант — использовать
SelectMany.var priceInfos = DbContext .Company // имеется в виду другой extension-метод с подходящей сигнатурой .ByInnAndKpp("инн", "кпп") .SelectMany(x => x.Company) .ToList();
Вопрос эквивалентности вариантов сSelectиSelectManyс точки зренияIQueryProviderя еще до конца не изучил. Буду благодарен любой информации на эту тему в комментариях.
Связанные коллекции
public virtual ICollection<Document> Documents { get; protected set; }
Желательно использовать только в блоке
Select для преобразования в SQL-запрос, потому что код вида company.Documents.Where(…).ToList() не построит запрос к БД, а сначала поднимет в оперативную память все связанные сущности, а потому применит Where к выборке в памяти. Таким образом, наличие коллекций в модели может крайней негативно отразиться на производительности приложения. При этом рефакторинг будет произвести сложно, потому что придется передавать необходимые IQueryable из вне. Чтобы контролировать качество запросов нужно поглядывать в miniProfiler.Сервисы (Service)
В анемичной модели вообще вся логика хранится в сервисах. Я предпочитаю добавлять сервисы только по необходимости, если логика неуместна в коде агрегата или описывает взаимодействие между агрегатами. Лучший вариант, когда домен содержит точные названия для сервиса — «касса», «склад», «кол-центр». В этом случае постфикс «Service» можно опустить. Набор методов в каждом классе соответствует набору use case'ов, сгруппированных по элементам пользовательского интерфейса. Работает хорошо, если интерфейс разработан в стиле
Task Based UI.Write-методы принимают на вход сущности или DTO. Валидация запроса производится в отдельном слое строго до выполнения метода. Если метод может завершиться неудачей, следует явно обозначить это в сигнатуре с помощью типа
Result. Исключения остаются для исключительных ситуаций.Read-методы возвращают DTO для сериализации и отправки на клиент. Благодаря
Queryable Extensions в AutoMapper и Mapster можно использовать маппинги для трансляции в выражения для Select, что позволяет не тащить всю сущность из БД целиком.Менеджеры (Manager)
Использую редко, для операций в рамках одного агрегата.
AspNet.Identity, например содержит UserManager. В основном менеджеры нужны, когда необходимо реализовать логику над агрегатом, не относящуюся непосредственно к домену.TPT для union-type
Иногда одна сщуность может быть связана с одной из нескольких других. Для создания непротиворечивой системы хранения можно использовать TPT, а для control flow — pattern matching. Этот подход подробно описан в отдельной статье.
Queryable Extensions для проекций в DTO
Использование
DataMapper позволяет снизить количество boilerplate-кода, а использование Queryable Extensions — строить запросы на получение DTO без необходимости писать Select вручную. Таким образом можно повторно использовать выражения для маппинга в оперативной памяти и построения деревьев выражений для IQueryProvider. AutoMapper довольно прожорлив по памяти и не быстр, поэтому со временем заменил его на Mapster.CQRS для отдельных подсистем
При работе в условиях высокой неопределенности риск ошибки проектирования также велик. Прежде чем проектировать структуру БД, принимать решения о денормализации или писать хранимые процедуры есть смысл прибегнуть к быстрому макетированию и проверить гипотезы. Когда есть уверенность: что на входе, а что на выходе можно заняться оптимизацией.
В отсутствии команд реализации
IQuery возвращают одинаковые результаты на одинаковых входных данных. Поэтому тела таких методов можно агрессивно кешировать. Таким образом, после замены реализаций инфраструктурный код (контроллеры) останется без изменений, а модифицировать придется только тело метода IQuery. Подход позволяет оптимизировать приложение точечно по небольшим кусочкам, а не все целиком.Подход ограничено-применим для очень-очень нагруженных ресурсов из-за накладных расходов на IOC-контейнер и memory traffic для per request lifestyle. Однако, все IQuery можно сделать singleton'ами, если не инжектировать зависимости от БД в конструктор, а вместо этого использовать конструкцию using.Работа с унаследованным кодом
При работе с существующей кодовой базой следует определиться с форматом работы: «поддержка» или «развитие». В первом случае не предполагается появление новой функциональности и доработка системы. Максимум — добавить несколько новых отчетов, пару форм тут и там. Во втором — есть необходимость значительной переработки предметной модели и / или архитектуры в целом. Если проект необходимо именно «поддерживать», а не «развивать», лучше следовать существующим правилам, независимо от того на сколько они удачные. Если перед вами откровенный говнокод, от предложения посупортить его лучше отказаться.
Развитие проекта — задача более сложная. Тема рефакторинга выходит за рамки данной статьи. Отмечу лишь два самых полезных паттерна: «антикоррупционный слой» и «душитель». Они очень похожи. Основная идея — выстроить «фасад» между старой и новой кодовыми базами и постепенно
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Как вы работаете с предметной областью
17.16%Domain Driven Design127
7.3%Data Driven Design54
41.89%Как бог на душу положит310
33.65%Хоп-хоп и в продакшн249
Проголосовали 740 пользователей. Воздержались 146 пользователей.

