Про Higload Cup уже было несколько статей, поэтому о том, что это было писать не буду, кто пропустил можете почитать в «История 13 места на Highload Cup 2017».
Так же постараюсь не повторяться и поделюсь интересными, с моей точки зрения, решениями. Под катом:
и много кода.
Первую версию я написал на Go, используя net/http и encoding/json. И она легла на 2 000 RPS. После этого net/http был заменён на fasthttp, а encoding/json на easyjson. Такая конфигурация позволила уйти спать на первом месте, но с утра я уже был кажется на третьем. Здесь возникла дилемма: оптимизировать код на Go или сразу писать на C++, чтобы иметь более гибкий инструмент ближе к финалу, когда важны будут наносекунды.
Я выбрал второй вариант, при этом решил использовать только системные библиотеки и написать свой HTTP сервер, который не тратит время на ненужные в данном случае вещи и JSON парсер/сериализатор. Ещё изначально хотелось поиграться с libnuma и SSE 4.2 командами, но до этого не дошло, так как, забегая вперёд, самая долгая операция была write в сокет.
Весь приведённый ниже код не является «production ready», он написан для конкретных тесткейсов конкурса, в нём нет защиты от переполнения, точнее там вообще нет никакой защиты, использовать его в таком виде не безопасно!
Есть всего 3 таблицы:
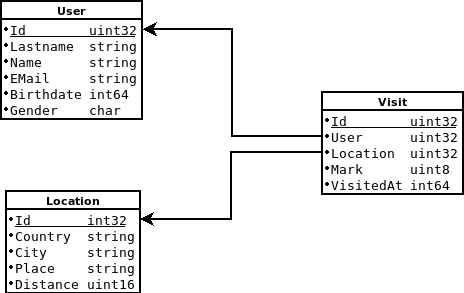
В патронах к танку нашлось чуть больше 1 000 000 пользователей, около 800 000 location'ов и чуть больше 10 000 000 визитов.
Сервис должен возвращать элементы из этих таблиц по Id. Первое желание было сложить их в map'ы, но к счастью Id оказались практически без пропусков, поэтому можно саллоцировать непрерывные массивы и хранить элементы там.
Также сервис должен уметь работать с агрегированной информацией, а именно
Чтобы делать это эффективно, нужны индексы.
Для каждого пользователя я завёл поле
В случае со средней оценкой location'а, порядок не важен, поэтому для каждого location'а я завёл поле типа
При любом добавлении/изменении визита нужно было не забывать обновлять данные в затрагиваемых индексах. В коде это выглядит так:
Вообще среднее количество элементов в индексе 10, максимальное — 150. Так что можно было бы обойтись просто массивом, что повысило бы локальность данных и не сильно замедлило модификацию.
Те JSON парсеры, которые я нашёл для C/C++, строят дерево при парсинге, а это лишние аллокации, что в highload неприемлемо. Так же есть те, которые складывают данные напрямую в переменные, но в таком случае нельзя узнать, какие поля были в JSON объекте, а это важно, так как при изменении объекта JSON приходит не с полным набором полей, а только с теми, которые надо изменить.
JSON, который должен парсить сервис очень простой, это одноуровневый объект, который содержит только известные поля, внутри строк нет кавычек. JSON для пользователя выглядит так:
Т.е. довольно просто написать для него парсер на мета языке
Осталось только определить на что заменить команды мета языка и парсер готов:
В получении списка мест, которые посетил пользователь есть фильтр по стране, который может быть в виде URI encoded строки:
Строки в JSON объектах могут быть вида
Из HTTP запроса нужно достать метод (GET/POST), query (path + parameters) и в случае POST запроса тело. Парсить и хранить заголовки нет смысла, за исключением заголовка Content-Lentgth для POST запросов, но как оказалось позже и это не надо, так как все запросы вмещаются в один read. В итоге получился вот такой парсер:
Хендлеров совсем мало, поэтому просто switch по методу, а внутри поиск префикса простым сравнением:
Яндекс.Танк не обращает внимание на заголовок «Connection» в патронах, а смотрит только на этот заголовок в ответе от сервера. Поэтому не нужно рвать соединение, а нужно работать в режиме Keep-Alive всегда.
Для реализации асинхронного взаимодействия естественно был выбран epoll. Я знаю 3 популярных варианта работы с epoll в многопоточном приложении:
Я сравнивал 2 и 3 варианты и на локальных тестах третий вариант немного выиграл, выглядит он так:
Уже после закрытия приёма решений я решил отказаться от epoll и сделать классическую префорк модель, только с 1 500 потоков (Я.Танк открывал 1000+ соединений). По умолчанию каждый поток резервирует 8MB под стек, что даёт 1 500 * 8MB = 11,7GB. А по условиям конкурса приложению выделяется 4GB RAM. Но к счастью размер стека можно уменьшить с помощью функции
Теперь потоки занимают 1 500 * 32KB = 47MB.
На локальных тестах такое решение показало результаты чуть хуже чем epoll.
Для профайлинга я использовал gperftools, который показал, что самая долгая операция была
По умолчанию ядро для оптимизации сети склеивает маленькие кусочки данных в один пакет (алгоритм Нейгла), что в данном случае только мешает нам, так сервис всегда отправляет маленькие пакеты и их отправить надо как можно быстрее. Так что отключаем его:
Данная опция позволяет отправлять ответ не дожидаясь ACK'а от клиента при TCP handshake'е:
На всякий случай выставил и эту опцию, хотя до конца не понимаю принцип её работы:
Размеры буферов тоже влияют на скорость передачи сети. По умолчанию используется около 16KB. Без изменения настроек ядра их можно увеличить до примерно 400KB, хотя попросить можно любой размер:
При таком размере появились битые пакеты и таймауты.
Обычно используется функция
Ещё 1 способ работать с IO асинхронно. В aio есть функция
Идея была в простая, так как в epoll приходит несколько событий одновременно, то можно подготовить ответы для всех клиентов и отправить одновременно. К сожалению улучшений не принесло, пришлось отказаться.
Как оказалось это была ключевая особенность, которая позволяла уменьшить количество штрафа на примерно 30 секунд, но, к сожалению, об этом я узнал слишком поздно.
Спасибо организаторам за конкурс, хоть всё проходило не очень гладко. Было очень увлекательно и познавательно.
Так же постараюсь не повторяться и поделюсь интересными, с моей точки зрения, решениями. Под катом:
- Немного про структуру данных
- Парсинг JSON'а на define'ах
- URI unescape
- UTF decode
- HTTP Server
- Тюнинг сети
и много кода.
Велосипеды
Первую версию я написал на Go, используя net/http и encoding/json. И она легла на 2 000 RPS. После этого net/http был заменён на fasthttp, а encoding/json на easyjson. Такая конфигурация позволила уйти спать на первом месте, но с утра я уже был кажется на третьем. Здесь возникла дилемма: оптимизировать код на Go или сразу писать на C++, чтобы иметь более гибкий инструмент ближе к финалу, когда важны будут наносекунды.
Я выбрал второй вариант, при этом решил использовать только системные библиотеки и написать свой HTTP сервер, который не тратит время на ненужные в данном случае вещи и JSON парсер/сериализатор. Ещё изначально хотелось поиграться с libnuma и SSE 4.2 командами, но до этого не дошло, так как, забегая вперёд, самая долгая операция была write в сокет.
Весь приведённый ниже код не является «production ready», он написан для конкретных тесткейсов конкурса, в нём нет защиты от переполнения, точнее там вообще нет никакой защиты, использовать его в таком виде не безопасно!
Немного про структуру данных
Есть всего 3 таблицы:
В патронах к танку нашлось чуть больше 1 000 000 пользователей, около 800 000 location'ов и чуть больше 10 000 000 визитов.
Сервис должен возвращать элементы из этих таблиц по Id. Первое желание было сложить их в map'ы, но к счастью Id оказались практически без пропусков, поэтому можно саллоцировать непрерывные массивы и хранить элементы там.
Также сервис должен уметь работать с агрегированной информацией, а именно
- возвращать список посещённых пользователем location'ов в отсортированном по дате посещения порядке
- возвращать среднюю оценку для location'а
Чтобы делать это эффективно, нужны индексы.
Для каждого пользователя я завёл поле
std::set<uint32_t, visitsCmp>, где visitsCmp позволяет хранить id визитов в отсортированном по дате визита порядке. Т.е. при выводе не нужно копировать визиты в отдельный массив и сортировать, а можно сразу выводить в сериализованном виде в буфер. Выглядит он так:struct visitsCmp { Visit* visits; bool operator()(const uint32_t &i, const uint32_t &j) const { if (visits[i].VisitedAt == visits[j].VisitedAt) { return visits[i].Id < visits[j].Id; } else { return visits[i].VisitedAt < visits[j].VisitedAt; } }
В случае со средней оценкой location'а, порядок не важен, поэтому для каждого location'а я завёл поле типа
std::unordered_set<uint32_t>, в котором содержатся в визиты конкретного location'а.При любом добавлении/изменении визита нужно было не забывать обновлять данные в затрагиваемых индексах. В коде это выглядит так:
bool DB::UpdateVisit(Visit& visit, bool add) { if (add) { memcpy(&visits[visit.Id], &visit, sizeof(Visit)); // Добвляем визит в индексы users[visit.User].visits->insert(visit.Id); locations[visit.Location].visits->insert(visit.Id); return true; } // Если изменилась дата визита, то надо пересортировать визиты пользователя if (visit.Fields & Visit::FIELD_VISITED_AT) { users[visits[visit.Id].User].visits->erase(visit.Id); visits[visit.Id].VisitedAt = visit.VisitedAt; users[visits[visit.Id].User].visits->insert(visit.Id); } if (visit.Fields & Visit::FIELD_MARK) { visits[visit.Id].Mark = visit.Mark; } // Если изменилась пользователь то надо удалить у старого пользователя из индекса и добавить новому if (visit.Fields & Visit::FIELD_USER) { users[visits[visit.Id].User].visits->erase(visit.Id); users[visit.User].visits->insert(visit.Id); visits[visit.Id].User = visit.User; } // Аналогично, если изменился location if (visit.Fields & Visit::FIELD_LOCATION) { locations[visits[visit.Id].Location].visits->erase(visit.Id); locations[visit.Location].visits->insert(visit.Id); visits[visit.Id].Location = visit.Location; } return true; }
Вообще среднее количество элементов в индексе 10, максимальное — 150. Так что можно было бы обойтись просто массивом, что повысило бы локальность данных и не сильно замедлило модификацию.
Парсинг JSON'а на define'ах
Те JSON парсеры, которые я нашёл для C/C++, строят дерево при парсинге, а это лишние аллокации, что в highload неприемлемо. Так же есть те, которые складывают данные напрямую в переменные, но в таком случае нельзя узнать, какие поля были в JSON объекте, а это важно, так как при изменении объекта JSON приходит не с полным набором полей, а только с теми, которые надо изменить.
JSON, который должен парсить сервис очень простой, это одноуровневый объект, который содержит только известные поля, внутри строк нет кавычек. JSON для пользователя выглядит так:
{ "id": 1, "email": "robosen@icloud.com", "first_name": "Данила", "last_name": "Стамленский", "gender": "m", "birth_date": 345081600 }
Т.е. довольно просто написать для него парсер на мета языке
bool User::UmnarshalJSON(const char* data, int len) { JSON_SKIP_SPACES() JSON_START_OBJECT() while (true) { JSON_SKIP_SPACES() // Конец объекта if (data[0] == '}') { return true; // Разделитель полей } else if (data[0] == ',') { data++; continue; // Поле "id" } else if (strncmp(data, "\"id\"", 4) == 0) { data += 4; JSON_SKIP_SPACES() JSON_FIELDS_SEPARATOR() JSON_SKIP_SPACES() // Прочитать и сохранить значение в поле Id JSON_LONG(Id) // Выставить флаг, что поле Id было в JSON Fields |= FIELD_ID; // Поле "lastname" } else if (strncmp(data, "\"last_name\"", 11) == 0) { data += 11; JSON_SKIP_SPACES() JSON_FIELDS_SEPARATOR(); JSON_SKIP_SPACES() // Прочитать и сохранить значение в поле Id JSON_STRING(LastName) // Выставить флаг, что поле LastName было в JSON Fields |= FIELD_LAST_NAME; } else if (strncmp(data, "\"first_name\"", 12) == 0) { data += 12; JSON_SKIP_SPACES() JSON_FIELDS_SEPARATOR() JSON_SKIP_SPACES() JSON_STRING(FirstName) Fields |= FIELD_FIRST_NAME; } else if (strncmp(data, "\"email\"", 7) == 0) { data += 7; JSON_SKIP_SPACES() JSON_FIELDS_SEPARATOR() JSON_SKIP_SPACES() JSON_STRING(EMail) Fields |= FIELD_EMAIL; } else if (strncmp(data, "\"birth_date\"", 12) == 0) { data += 12; JSON_SKIP_SPACES() JSON_FIELDS_SEPARATOR() JSON_SKIP_SPACES() JSON_LONG(BirthDate) Fields |= FIELD_BIRTH_DATE; } else if (strncmp(data, "\"gender\"", 8) == 0) { data += 8; JSON_SKIP_SPACES() JSON_FIELDS_SEPARATOR() JSON_SKIP_SPACES() JSON_CHAR(Gender) Fields |= FIELD_GENDER; } else { JSON_ERROR(Unknow field) } } return true; }
Осталось только определить на что заменить команды мета языка и парсер готов:
#define JSON_ERROR(t) fprintf(stderr, "%s (%s:%d)\n", #t, __FILE__, __LINE__); return false; #define JSON_SKIP_SPACES() data += strspn(data, " \t\r\n") #define JSON_START_OBJECT() if (data[0] != '{') { \ JSON_ERROR(Need {}) \ } \ data++; #define JSON_FIELDS_SEPARATOR() if (data[0] != ':') { \ JSON_ERROR(Need :) \ } \ data++; #define JSON_LONG(field) char *endptr; \ field = strtol(data, &endptr, 10); \ if (data == endptr) { \ JSON_ERROR(Invalid ## field ## value); \ } \ data = endptr; #define JSON_STRING(field) if (data[0] != '"') {\ JSON_ERROR(Need dquote); \ } \ auto strend = strchr(data+1, '"'); \ if (strend == NULL) { \ JSON_ERROR(Need dquote); \ } \ field = strndup(data+1, strend - data - 1); \ data = strend + 1; #define JSON_CHAR(field) if (data[0] != '"') {\ JSON_ERROR(Need dquote); \ } \ if (data[2] != '"') {\ JSON_ERROR(Need dquote); \ } \ field = data[1]; \ data += 3;
URI unescape
В получении списка мест, которые посетил пользователь есть фильтр по стране, который может быть в виде URI encoded строки:
/users/1/visits?country=%D0%A0%D0%BE%D1%81%D1%81%D0%B8%D1%8F. Для декодинга на StackOverflow было найдено замечательное решение, в которое я дописал поддержку замены + на пробел:int percent_decode(char* out, char* in) { static const char tbl[256] = { -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, -1, -1, -1, -1, -1, -1, -1, 10, 11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 10, 11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1 }; char c, v1, v2; if (in != NULL) { while ((c = *in++) != '\0') { switch (c) { case '%': if (!(v1 = *in++) || (v1 = tbl[(unsigned char) v1]) < 0 || !(v2 = *in++) || (v2 = tbl[(unsigned char) v2]) < 0) { return -1; } c = (v1 << 4) | v2; break; case '+': c = ' '; break; } *out++ = c; } } *out = '\0'; return 0; }
UTF decode
Строки в JSON объектах могут быть вида
"\u0420\u043E\u0441\u0441\u0438\u044F". В общем случае это не страшно, но у нас есть сравнение со страной, поэтому одно поле нужно уметь декодировать. За основу я взял percent_decode, только в случае с Unicode не достаточно превратить \u0420 в 2 байта 0x0420, этому числу надо поставить в соответствие UTF символ. К счастью у нас только символы кириллицы и пробелы, поэтому если посмотреть на таблицу, то можно заметить, что есть всего один разрыв последовательностей между буквами «п» и «р», так что для преобразования можно использовать смещение:void utf_decode(char* in) { static const char tbl[256] = { -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, -1, -1, -1, -1, -1, -1, -1, 10, 11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 10, 11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1 }; char *out = in; while (in[0] != 0) { if (in[0] == '\\' && in[1] == 'u') { uint16_t u = tbl[in[2]] << 12 | tbl[in[3]] << 8 | tbl[in[4]] << 4 | tbl[in[5]]; // Все ASCII символы оставляем как есть if (u < 255) { out[0] = u; out++; } else { uint16_t w; // < 'р' if (u >= 0x0410 && u <= 0x043f) { w = u - 0x0410 + 0xd090; // >= 'р' } else { w = u - 0x0440 + 0xd180; } out[0] = w >> 8; out[1] = w; out += 2; } in += 6; } else { out[0] = in[0]; in++; out++; } } out[0] = 0; }
HTTP Server
Парсер
Из HTTP запроса нужно достать метод (GET/POST), query (path + parameters) и в случае POST запроса тело. Парсить и хранить заголовки нет смысла, за исключением заголовка Content-Lentgth для POST запросов, но как оказалось позже и это не надо, так как все запросы вмещаются в один read. В итоге получился вот такой парсер:
... auto body = inBuf.Data; const char *cendptr; char *endptr; while (true) { switch (state) { case METHOD: body += strspn(body, " \r\n"); if (strncmp(body, "GET ", 4) == 0) { method = GET; body += 4; } else if (strncmp(body, "POST ", 5) == 0) { body += 5; method = POST; } else { state = DONE; WriteBadRequest(); return; } body += strspn(body, " "); cendptr = strchr(body, ' '); if (cendptr == NULL) { WriteBadRequest(); return; } strncpy(path.End, body, cendptr - body); path.AddLen(cendptr - body); cendptr = strchr(cendptr + 1, '\n'); if (cendptr == NULL) { WriteBadRequest(); return; } state = HEADER; body = (char*) cendptr + 1; break; case HEADER: cendptr = strchr(body, '\n'); if (cendptr == NULL) { WriteBadRequest(); return; } if (cendptr - body < 2) { if (method == GET) { doRequest(); return; } state = BODY; } body = (char*) cendptr + 1; case BODY: requst_body = body; doRequest(); return; } ...
Routing
Хендлеров совсем мало, поэтому просто switch по методу, а внутри поиск префикса простым сравнением:
... switch (method) { case GET: if (strncmp(path.Data, "/users", 6) == 0) { handlerGetUser(); } else if (strncmp(path.Data, "/locations", 10) == 0) { handlerGetLocation(); } else if (strncmp(path.Data, "/visits", 7) == 0) { handlerGetVisit(); } else { WriteNotFound(); } break; case POST: if (strncmp(path.Data, "/users", 6) == 0) { handlerPostUser(); } else if (strncmp(path.Data, "/locations", 10) == 0) { handlerPostLocation(); } else if (strncmp(path.Data, "/visits", 7) == 0) { handlerPostVisit(); } else { WriteNotFound(); } break; default: WriteBadRequest(); } ...
Keep-Alive
Яндекс.Танк не обращает внимание на заголовок «Connection» в патронах, а смотрит только на этот заголовок в ответе от сервера. Поэтому не нужно рвать соединение, а нужно работать в режиме Keep-Alive всегда.
Работа с сетью
Для реализации асинхронного взаимодействия естественно был выбран epoll. Я знаю 3 популярных варианта работы с epoll в многопоточном приложении:
- N потоков имеют общий epoll + 1 поток ждёт accept в блокирующем режиме и регистрирует клиентские сокеты в epoll
- N потоков имеют N epoll'ов + 1 поток ждёт accept в блокирующем режиме и регистрирует клиентские сокеты в epoll'ах, допустим используя RoundRobin.
- Каждый поток имеет свой epoll, в котором зарегистрирован серверный сокет, находящийся в неблокирующем состоянии и клиентские сокеты, которое этот поток захватил.
Я сравнивал 2 и 3 варианты и на локальных тестах третий вариант немного выиграл, выглядит он так:
void Worker::Run() { int efd = epoll_create1(0); if (efd == -1) { FATAL("epoll_create1"); } connPool = new ConnectionsPool(db); // Регистрируем серверный сокет в epoll auto srvConn = new Connection(sfd, defaultDb); struct epoll_event event; event.data.ptr = srvConn; event.events = EPOLLIN; if (epoll_ctl(efd, EPOLL_CTL_ADD, sfd, &event) == -1) { perror("epoll_ctl"); abort(); } struct epoll_event *events; events = (epoll_event*) calloc(MAXEVENTS, sizeof event); while (true) { auto n = epoll_wait()(efd, events, MAXEVENTS, -1); for (auto i = 0; i < n; i++) { auto conn = (Connection*) events[i].data.ptr; if ((events[i].events & EPOLLERR) || (events[i].events & EPOLLHUP) || (!(events[i].events & EPOLLIN))) { /* An error has occured on this fd, or the socket is not ready for reading (why were we notified then?) */ fprintf(stderr, "epoll error\n"); close(conn->fd); if (conn != srvConn) { connPool->PutConnection(conn); } continue; // Если событие пришло для серверного сокета, то нужно сделать accept } else if (conn == srvConn) { /* We have a notification on the listening socket, which means one or more incoming connections. */ struct sockaddr in_addr; socklen_t in_len; in_len = sizeof in_addr; int infd = accept4(sfd, &in_addr, &in_len, SOCK_NONBLOCK); if (infd == -1) { if ((errno == EAGAIN) || (errno == EWOULDBLOCK)) { continue; } else { perror("accept"); continue;; } } int val = true; if (setsockopt(infd, IPPROTO_TCP, TCP_NODELAY, &val, sizeof(val)) == -1) { perror("TCP_NODELAY"); } event.data.ptr = connPool->GetConnection(infd); event.events = EPOLLIN | EPOLLET; if (epoll_ctl(efd, EPOLL_CTL_ADD, infd, &event) == -1) { perror("epoll_ctl"); abort(); } continue; // Событие для клиентского сокета, надо подготовить и отправить ответ } else { bool done = false; bool closeFd = false; while (true) { ssize_t count; count = read(conn->fd, conn->inBuf.Data, conn->inBuf.Capacity); conn->inBuf.AddLen(count); if (count == -1) { /* If errno == EAGAIN, that means we have read all data. So go back to the main loop. */ if (errno != EAGAIN) { perror("read"); done = true; } else { continue; } break; } else if (count == 0) { /* End of file. The remote has closed the connection. */ done = true; closeFd = true; break; } if (!done) { done = conn->ProcessEvent(); break; } } if (done) { if (closeFd) { close(conn->fd); connPool->PutConnection(conn); } else { conn->Reset(conn->fd); } } } } } }
Уже после закрытия приёма решений я решил отказаться от epoll и сделать классическую префорк модель, только с 1 500 потоков (Я.Танк открывал 1000+ соединений). По умолчанию каждый поток резервирует 8MB под стек, что даёт 1 500 * 8MB = 11,7GB. А по условиям конкурса приложению выделяется 4GB RAM. Но к счастью размер стека можно уменьшить с помощью функции
pthread_attr_setstacksize. Минимальный размер стека — 16KB. Т.к. внутри потоков у меня ничего большого в стек не кладётся я выбрал размер стека 32KB:pthread_attr_t attr; pthread_attr_init(&attr); if (pthread_attr_setstacksize(&attr, 32 * 1024) != 0) { perror("pthread_attr_setstacksize"); } pthread_create(&thr, &attr, &runInThread, (void*) this);
Теперь потоки занимают 1 500 * 32KB = 47MB.
На локальных тестах такое решение показало результаты чуть хуже чем epoll.
Тюнинг сети
Для профайлинга я использовал gperftools, который показал, что самая долгая операция была
std::to_string. Это было довольно быстро исправлено, но теперь основное время было в операциях epoll_wait, write и writev. На первое я не обратил внимания, что, возможно, стоило попадания в призёры, а что делать с write начал изучать, попутно находя ускорения для acceptTCP_NODELAY
По умолчанию ядро для оптимизации сети склеивает маленькие кусочки данных в один пакет (алгоритм Нейгла), что в данном случае только мешает нам, так сервис всегда отправляет маленькие пакеты и их отправить надо как можно быстрее. Так что отключаем его:
int val = 1; if (setsockopt(sfd, IPPROTO_TCP, TCP_NODELAY, &val, sizeof(val)) == -1) { perror("TCP_NODELAY"); }
TCP_DEFER_ACCEPT
Данная опция позволяет отправлять ответ не дожидаясь ACK'а от клиента при TCP handshake'е:
int val = 1; if (setsockopt(sfd, IPPROTO_TCP, TCP_DEFER_ACCEPT, &val, sizeof(val)) == -1) { perror("TCP_DEFER_ACCEPT"); }
TCP_QUICKACK
На всякий случай выставил и эту опцию, хотя до конца не понимаю принцип её работы:
int val = 1; if (setsockopt(sfd, IPPROTO_TCP, TCP_QUICKACK, &val, sizeof(val)) == -1) { perror("TCP_QUICKACK"); }
SO_SNDBUF и SO_RCVBUF
Размеры буферов тоже влияют на скорость передачи сети. По умолчанию используется около 16KB. Без изменения настроек ядра их можно увеличить до примерно 400KB, хотя попросить можно любой размер:
int sndsize = 2 * 1024 * 1024; if (setsockopt(sfd, SOL_SOCKET, SO_SNDBUF, &sndsize, (int) sizeof(sndsize)) == -1) { perror("SO_SNDBUF"); } if (setsockopt(sfd, SOL_SOCKET, SO_RCVBUF, &sndsize, (int) sizeof(sndsize)) == -1) { perror("SO_RCVBUF"); }
При таком размере появились битые пакеты и таймауты.
accept4
Обычно используется функция
accept для получения клиентского сокета и 2 вызова fcntl для выставления флага fcntl. Вместо 3 системных вызова нужно использовать accept4, которая позволяет сделать тоже самое передав последним аргументом флаг SOCK_NONBLOCK за 1 системный вызов:int infd = accept4(sfd, &in_addr, &in_len, SOCK_NONBLOCK);
aio
Ещё 1 способ работать с IO асинхронно. В aio есть функция
lio_listio, позволяющая объединить в 1 системный вызов несколько write/read, что должно уменьшить задержки на переключение в пространство ядра.Идея была в простая, так как в epoll приходит несколько событий одновременно, то можно подготовить ответы для всех клиентов и отправить одновременно. К сожалению улучшений не принесло, пришлось отказаться.
epoll_wait(...., -1) -> epoll_wait(...., 0)
Как оказалось это была ключевая особенность, которая позволяла уменьшить количество штрафа на примерно 30 секунд, но, к сожалению, об этом я узнал слишком поздно.
Postscriptum
Спасибо организаторам за конкурс, хоть всё проходило не очень гладко. Было очень увлекательно и познавательно.

