Кроме взаимодействия на уровне взаимной блокировки, задачи должны взаимодействовать между собой и на уровне данных. При этом отличительная особенность ОСРВ МАКС — возможность обмена данными не только в пределах одного контроллера,

Рис. 1. Пример взаимодействия задач в пределах одного контроллера
но и между контроллерами, полностью скрывая транспортный уровень.

Рис. 2. Пример взаимодействия задач между контроллерами
При этом разные контроллеры эквивалентны разным процессам, так как их память полностью изолирована. В версии ОС, опубликованной на нашем сайте, физическим каналом между контроллерами могут быть проводные интерфейсы SPI или UART, а также — беспроводной интерфейс через радиомодули RF24.
Не рекомендуется использовать варианты SPI и UART, так как в текущей реализации через них может быть связано не более двух контроллеров.
Далее я об этом расскажу подробнее, а другие главы «Книги знаний» можно посмотреть здесь:
Часть 1. Общие сведения
Часть 2. Ядро ОСРВ МАКС
Часть 3. Структура простейшей программы
Часть 4. Полезная теория
Часть 5. Первое приложение
Часть 6. Средства синхронизации потоков
Часть 7. Средства обмена данными между задачами (настоящая статья)
Часть 8. Работа с прерываниями
Классический подход к работе ОСРВ таков: задачи обмениваются данными друг с другом, пользуясь очередями сообщений. По крайней мере, этого требуют все академические учебники. Я отношусь к программистам-практикам, поэтому признаю, что иногда проще обойтись какими-либо прямыми средствами обмена, сделанными под конкретный случай. Например, банальными кольцевыми буферами, не завязанными на систему. Но тем не менее, есть случаи, где очереди сообщений являются наиболее оптимальными объектами (хотя бы потому, что в отличие от несистемных вещей, они могут производить блокировку задач при переполнении заполняемого или пустоте опрашиваемого буфера).
Рассмотрим хрестоматийный пример. Имеется последовательный порт. Разумеется, схемотехниками, для упрощения системы, он сделан без линий управления потоком. Данные по проводам могут идти друг за другом. При этом аппаратура многих (хоть и не всех) типовых контроллеров не подразумевает большой аппаратной очереди. Если данные не успеть забрать — они будут затёрты всё новыми порциями, приходящими из принимающего регистра сдвига.
С другой стороны, допустим, задача, обрабатывающая данные, требует некоторого времени (например, для перемещения рабочего инструмента). Это вполне нормальное явление — G-код в станки с ЧПУ поступает именно с некоторым упреждением. Инструмент перемещается, а следующая строка в то же самое время бежит по проводам.
Чтобы буферный регистр контроллера не переполнялся, а байты в программе успевали бы приниматься во время основной работы, необходимо и достаточно делать их приём в обработчике прерываний. Возможен простейший вариант, когда в основную задачу передаются «сырые» байты:

Рис.3
Но в этом случае, получается слишком много операций постановки и взятия из очереди. Слишком высоки накладные расходы. Желательно ставить в очередь не «сырые» байты, а уже результаты их предобработки (начиная от строк, заканчивая уже результатами интерпретации строк для нашего примера с G-кодом). Но производить предобработку в обработчике прерывания — недопустимо, ведь в это время заблокированы часть, а иногда — и все другие прерывания (зависит от настройки приоритетов), и данные для других подсистем будут обработаны с задержкой, что иногда нарушит работоспособность изделия.
Этот постулат стоит того, чтобы повторить его несколько раз. Помнится, на одном форуме я увидел такой вопрос: «Я взял типовой распаковщик звука микрофона из формата PDM, а он работает неправильно». И к вопросу был приложен пример, в котором PDM-фильтрация производилась в контексте прерывания. Само собой разумеется, когда автор вопроса стал производить преобразования из PDM в PCM вне прерывания (как ему тут же посоветовали), все проблемы ушли сами собой. Поэтому в прерывании предобработку производить недопустимо! Нельзя варить яйца в микроволновке и выполнять излишние действия в обработчике прерывания!
Рекомендуемая во всех учебниках схема, при наличии предобработки — следующая

Рис.4
Задача предобработки, обладающая высоким приоритетом, почти всё время заблокирована. Обработчик прерывания получил байт из аппаратуры, разбудил предобработчик, передав ему этот байт, после чего вышел. С этого момента, все прерывания вновь разрешены.
Высокоприоритетный предобработчик просыпается, производит накопление данных во внутреннем буфере, после чего — засыпает, вновь давая возможность работы задачам с нормальным приоритетом. Когда строка накоплена (пришёл символ перевода строки), он интерпретирует её и помещает результат в очередь сообщений. Именно такой вариант рекомендуют все академические издания, поэтому я просто обязан был донести классическую мысль и до читателей здесь. Хотя, тут же добавлю, что сам, не как теоретик, а как практик — вижу слабое место этого метода. Выигрываем на редком обращении к очереди, но проигрываем на переключениях контекста для входа в высокоприоритетную задачу. В общем, рекомендации донесены, про недостатки этого подхода — рассказано, а как работать в реальной жизни — каждый должен найти свой метод, подбирая оптимальное соотношение производительности и простоты. Некоторые рекомендации с реальными прикидками, будут в следующей статье, посвящённой прерываниям.
Для реализации очереди сообщений используется класс MessageQueue. Так как очередь сообщений должна эффективно работать с произвольными видами данных, она выполнена в виде шаблона (тип данных подставляется ему в качестве аргумента).
Конструктор имеет вид:
MessageQueue(size_t max_size);
Параметр max_size определяет максимальный размер очереди. Если попытаться поставить в очередь элемент, когда она заполнена до отказа — ставящая задача будет заблокирована до тех пор, пока не появится свободное место (какая-либо задача не заберёт один из уже стоящих в очереди элементов).
Так как сказано уже слишком много, здесь не обойтись без примера инициализации очереди. Возьмём фрагмент теста, в котором видно, что элемент очереди имеет тип short, а размерность очереди не будет превышать 5 элементов:
В очередь можно поместить сообщение, воспользовавшись функцией:
Result Push(const T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
Параметр timeout_ms требуется для случаев, когда очередь переполнена. В этом случае, система будет пытаться дождаться момента, когда в ней появится свободное место. А данный параметр — как раз сообщает, сколько допускается ждать.
При необходимости, сообщение можно поставить не в конец очереди, а в её начало. Для этого используется функция:
Result PushFront(const T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
Чтобы изъять очередной элемент из головы очереди, используется функция:
Result Pop(T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
Здесь, соответственно, параметр тайм-аута задаёт время ожидания на случай, если очередь пуста. В течение заданного времени, система будет пытаться дождаться появления в ней сообщений, поставленных в очередь другими задачами.
Также можно получить значение элемента из головы очереди, не изымая его:
Result Peek(T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
Наконец, имеются функции для того, чтобы узнать количество сообщений, стоящих в очереди:
size_t Count()
и максимально возможного размера очереди:
size_t GetMaxSize()
Вообще-то, чисто формально, средства обмена данными между контроллерами относятся к драйверам. Но идеологически они относятся к обычным средствам обмена данными, что и является одной из основных особенностей ОСРВ МАКС, поэтому рассмотрим их в части руководства, относящейся к ядру.
Напомню, что в опубликованной версии ОС, физический обмен может осуществляться через проводные интерфейсы UART или SPI, либо через радиомодуль RF24 (также подключённый к интерфейсу SPI). Также напомним, что для активации обмена данными между контроллерами, следует вписать в файл MaksConfig.h строку:
#define MAKS_USE_SHARED_MEM 1
и определить тип физического канала при помощи установки в единицу одной из констант:
MAKS_SHARED_MEM_SPI, MAKS_SHARED_MEM_UART или MAKS_SHARED_MEM_RADIO.
Механизмы SPI и UART в текущей реализации обеспечивают связь только двух устройств, поэтому рекомендованным является именно радиовариант
Теперь, после столь затянувшейся преамбулы, начнём изучение класса SharedMemory.
Объект класса можно инициализировать при помощи функции Initialize(). Слово «можно» применено не случайно. В общем случае, для радиоварианта, инициализация не требуется.
В эту функцию передаётся структура данных. Рассмотрим кратко её поля.
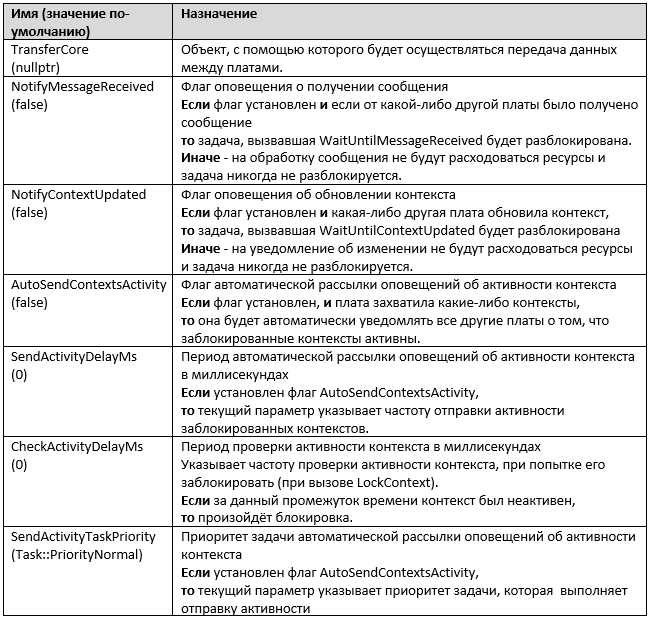
Рассмотрим примеры заполнения данной структуры и вызова функции инициализации.
Ещё вариант:
Этот класс предоставляет два механизма взаимодействия задач — сообщения и разделяемая память (с возможностью блокировок).
Так как объект «разделяемая память» всегда один, разработчики операционной системы создали файл MaksSharedMemoryExtensions.cpp, преобразующий сложные имена функций в глобальные.
Вот фрагмент этого файла:
Так как во всех приложениях, входящих в комплект поставки, используются глобальные имена функций, я в примерах для данного документа также буду использовать этот вариант именования.
Начнём с сообщений. Для их передачи используется функция SendMessage(). Функция достаточно сложная, поэтому рассмотрим её детально:
Result SendMessage(uint32_t message_id, const void * data, size_t data_length)
Аргументы:
message_id – идентификатор сообщения;
data – указатель на данные сообщения;
data_length – длина данных сообщения.
Пример использования:
Результат функции отражает статус отсылки сообщения. Было оно получено кем-либо из получателей или нет — функция умалчивает. Известно только ушло оно или нет. Для подтверждения, получатель должен самостоятельно послать обратное сообщение.
Соответственно, для ожидания сообщения на стороне получателя используется функция:
Result WaitUntilMessageReceived(SmMessageReceiveArgs & args,uint32_t timeout_ms = INFINITE_TIMEOUT)
Аргументы:
args – ссылка на объект с параметрами сообщения;
timeout_ms – тайм-аут ожидания в миллисекундах. Если значение тайм-аута равно INFINITE_TIMEOUT, то задача будет заблокирована без возможности разблокировки по тайм-ауту (бесконечное ожидание).
Параметры сообщения — это целый класс. Рассмотрим кратко его открытые члены:
uint32_t GetMessageId()
Возвращает идентификатор полученного сообщения:
size_t GetDataLength()
Возвращает размер данных полученного сообщения в байтах.
void CopyDataTo(void* target)
Копирует данные сообщения в указанный буфер. Память для буфера должна быть выделена заранее. Размер буфера должен быть не меньше, чем размер данных сообщения (результат вызова метода GetDataLength)
Таким образом, пример, обслуживающий получение сообщения, посланного в прошлом примере, выглядит так:
Контекстом называют область памяти, которую следует синхронизировать между всеми контроллерами. Цель, преследуемая при синхронизации, может быть любой. Простейший случай — одно устройство сообщает другому о выполненных этапах работы для горячего резервирования. Если оно выйдет из строя — у остальных устройств останется информация о том, как следует подхватить работу. Для устройств, достигающих цели совместно, механизм обмена через контекст может быть более удобен, чем через сообщения. Сообщения следует формировать, передавать, принимать, декодировать. А с памятью контекста можно работать, как с обычной памятью, важно лишь не забывать её синхронизировать, чтобы память одного устройства дублировалась на остальные.
Количество синхронизируемых контекстов в системе может быть произвольным. Поэтому не обязательно всё умещать в один. Под разные нужды можно заводить разные синхронизируемые контексты. Размер памяти, структура данных в ней и прочие параметры синхронизируемого контекста- это забота прикладного программиста (само собой, чем больше объём синхронизируемой памяти, тем медленнее происходит синхронизация, именно поэтому лучше использовать разные контексты малого размера под разные нужды).
Кроме того, даже моменты для сеансов синхронизации — и те выбираются прикладным программистом. ОСРВ МАКС предоставляет API для обеспечения, но вызывать его функции должен прикладной программист. Это связано с тем, что процесс обмена данными происходит относительно медленно. Если всё отдать на откуп операционной системы, то возможны задержки в то время, когда процессорное ядро должно максимально обслуживать иные задачи. Если автоматически синхронизировать контексты слишком часто — будут тратиться ресурсы, если слишком редко — данные могут устареть раньше, чем контроллеры засинхронизируются. Добавляем к этому вопрос, чьи данные важнее (например, при наличии четырёх разных абонентов), после чего становится совершенно ясно — только прикладной программист может инициировать синхронизацию. Именно он знает, когда это лучше сделать, а также кто из абонентов должен раздать свои данные остальным. ОС же обеспечивает прозрачность операции для прикладной программы.
Контекст имеет свой числовой идентификатор (задаётся прикладным программистом). Все приложения могут иметь как один синхронизируемый контекст, так и несколько. Важно только, чтобы их идентификаторы были согласованы в пределах взаимодействующих контроллеров.
Простейшие примеры синхронизируемых данных — роботы-уборщики периодически отмечают на карте убранную ими территорию, чтобы знать о ещё неубранных участках, а также сообщают кто куда собирается сейчас направиться, чтобы не мешать друг другу. Гайковёрты, работающие на одном изделии, отмечают каждую завинченную гайку после окончания завинчивания, чтобы если один выйдет из строя — другой бы закончил его часть. Плата с сенсорным экраном зафиксировала нажатие и отметила этот факт для остальных плат. Ну, и масса других случаев, где требуется разделять память, но допускается делать это несколько раз в секунду (максимум — несколько десятков раз в секунду).
Таким образом, контекст можно представить в виде, показанном рисунке:

Рис. 5. Контекст
А его назначение — можно представить на следующем рисунке:

Рис. 6. Суть синхронизации контекстов
Теперь рассмотрим функции, которые используются для синхронизации контекста:
Result GetContext(uint32_t context_id, void* data);
Копирует данные контекста в указанную область памяти, память должна быть заранее выделена. Подходит для случая когда длина данных заранее известна (например структура с простыми полями).
Аргументы:
context_id – идентификатор контекста;
data – указательна область памяти для хранения контекста;
В результате, будут возвращены данные контекста с указанным идентификатором, которые были получены при последней синхронизации. Таким образом, данная функция отработает быстро, так как данные берутся из локальной копии контекста. Существует второй вариант данной функции:
Result GetContext(uint32_tcontext_id, void *&data, size_t&data_length);
выделяет память и копирует данные и длину контекста. Подходит для случая, когда длина данных заранее неизвестна (например, массив произвольной длины).
Аргументы:
context_id – идентификатор контекста;
data – указательна область памяти для хранения контекста;
data_length – размер в байтах области памяти для хранения контекста.
В принципе, можно создать задачу, которая будет дожидаться обновления контекста, а затем — копировать его новые данные в память приложения. Для этого подойдёт следующая функция:
Result WaitUntilContextUpdated(uint32_t & context_id, uint32_t timeout_ms = INFINITE_TIMEOUT)
Аргументы:
context_id – идентификатор контекста;
timeout_ms – тайм-аут ожидания в миллисекундах. Если значение тайм-аута равно INFINITE_TIMEOUT, то задача будет заблокирована без возможности разблокировки по тайм-ауту (бесконечное ожидание).
Наконец, рассмотрим случай, когда задача хочет обновить свой контекст во всей системе (состоящей из нескольких контроллеров).
Сначала следует захватить контекст. Для этого используется следующая функция:
Result LockContext(uint32_t context_id)
Аргумент:
context_id – идентификатор контекста.
Функция требует обмена между контроллерами, поэтому может выполняться достаточно долго
Если контекст удалось захватить (при одновременной попытке захвата, победит только кто-то один, остальные — получат код ошибки), то контекст можно записать при помощи следующей функции:
Result SetContext(uint32_t context_id, const void * data, size_t data_length)
Аргументы:
context_id – идентификатор контекста;
data – указатель на область памяти для хранения контекста;
data_length – размер в байтах области памяти для хранения контекста.
Наконец, для проведения синхронизации контекста, следует вызвать функцию:
Result UnlockContext(uint32_t context_id)
Аргумент:
context_id – идентификатор контекста.
Именно после её вызова, произойдёт синхронизация контекстов во всей системе.
Функция требует обмена между контроллерами, поэтому может выполняться достаточно долго
Рассмотрим реальный пример работы с синхронизируемыми контекстами, идущий в комплекте поставки ОС. Код содержится в файле ...\maksRTOS\Source\Applications\CounterApp.cpp
В этом примере несколько устройств увеличивают некий счётчик раз в секунду (если запустить это приложение на платах с экраном, значение счётчика будет отображаться визуально). Если один из контроллеров отключить, а затем — включить, он получит текущее содержимое счётчика и будет работать вместе со всеми. Таким образом, система будет вести отсчёт до тех пор, пока в ней «жив» хотя бы один из контроллеров.
Прикладной программист, делавший этот пример, выбрал идентификатор контекста по принципу: «А почему бы и нет?»
Память, подлежащая синхронизации, выглядит проще простого:
Основные действия, интересующие нас, происходят в функции:
void CounterTask::Execute()
Сначала контроллер пытается выяснить: а не первый ли он в системе? Для этого он пытается получить контекст:
Если контроллер не первый, то контекст будет получен, а попутно будет получено и значение счётчика, которое существует в системе.
Если контроллер является первым, то контекст получен не будет. В этом случае, его следует создать, что делается следующим образом (там же попутно зануляется счётчик):
Всё, теперь контекст точно существует, был он найден в системе, к которой мы только что подключились, или создан нами. Входим в бесконечный цикл:
Там мы ждём одну секунду:
И пытаемся выиграть состязание за право раздать свой счётчик всей системе:
Если нам это удалось — раздаём
Как видно, мы раздаём контекст, но не получаем. Дело в том, что в данном примере получают контекст только вновь подключившиеся устройства. Если он получен, то дальше устройство работает автономно. Само собой, лучше поддерживать контакт постоянно, но описание такой системы займёт намного больше бумаги, а против психологии не попрёшь, большинство читателей просто зевнут и перейдут к следующему разделу, поэтому предоставим самым пытливым пользователям разбирательство с более сложными примерами в качестве самостоятельной работы. Принцип же работы разделяемой памяти, надеюсь, теперь уже более-менее понятен.
Рис. 1. Пример взаимодействия задач в пределах одного контроллера
но и между контроллерами, полностью скрывая транспортный уровень.
Рис. 2. Пример взаимодействия задач между контроллерами
При этом разные контроллеры эквивалентны разным процессам, так как их память полностью изолирована. В версии ОС, опубликованной на нашем сайте, физическим каналом между контроллерами могут быть проводные интерфейсы SPI или UART, а также — беспроводной интерфейс через радиомодули RF24.
Не рекомендуется использовать варианты SPI и UART, так как в текущей реализации через них может быть связано не более двух контроллеров.
Далее я об этом расскажу подробнее, а другие главы «Книги знаний» можно посмотреть здесь:
Часть 1. Общие сведения
Часть 2. Ядро ОСРВ МАКС
Часть 3. Структура простейшей программы
Часть 4. Полезная теория
Часть 5. Первое приложение
Часть 6. Средства синхронизации потоков
Часть 7. Средства обмена данными между задачами (настоящая статья)
Часть 8. Работа с прерываниями
Средство для обмена данными в пределах одного контроллера (очередь сообщений)
Классический подход к работе ОСРВ таков: задачи обмениваются данными друг с другом, пользуясь очередями сообщений. По крайней мере, этого требуют все академические учебники. Я отношусь к программистам-практикам, поэтому признаю, что иногда проще обойтись какими-либо прямыми средствами обмена, сделанными под конкретный случай. Например, банальными кольцевыми буферами, не завязанными на систему. Но тем не менее, есть случаи, где очереди сообщений являются наиболее оптимальными объектами (хотя бы потому, что в отличие от несистемных вещей, они могут производить блокировку задач при переполнении заполняемого или пустоте опрашиваемого буфера).
Рассмотрим хрестоматийный пример. Имеется последовательный порт. Разумеется, схемотехниками, для упрощения системы, он сделан без линий управления потоком. Данные по проводам могут идти друг за другом. При этом аппаратура многих (хоть и не всех) типовых контроллеров не подразумевает большой аппаратной очереди. Если данные не успеть забрать — они будут затёрты всё новыми порциями, приходящими из принимающего регистра сдвига.
С другой стороны, допустим, задача, обрабатывающая данные, требует некоторого времени (например, для перемещения рабочего инструмента). Это вполне нормальное явление — G-код в станки с ЧПУ поступает именно с некоторым упреждением. Инструмент перемещается, а следующая строка в то же самое время бежит по проводам.
Чтобы буферный регистр контроллера не переполнялся, а байты в программе успевали бы приниматься во время основной работы, необходимо и достаточно делать их приём в обработчике прерываний. Возможен простейший вариант, когда в основную задачу передаются «сырые» байты:
Рис.3
Но в этом случае, получается слишком много операций постановки и взятия из очереди. Слишком высоки накладные расходы. Желательно ставить в очередь не «сырые» байты, а уже результаты их предобработки (начиная от строк, заканчивая уже результатами интерпретации строк для нашего примера с G-кодом). Но производить предобработку в обработчике прерывания — недопустимо, ведь в это время заблокированы часть, а иногда — и все другие прерывания (зависит от настройки приоритетов), и данные для других подсистем будут обработаны с задержкой, что иногда нарушит работоспособность изделия.
Этот постулат стоит того, чтобы повторить его несколько раз. Помнится, на одном форуме я увидел такой вопрос: «Я взял типовой распаковщик звука микрофона из формата PDM, а он работает неправильно». И к вопросу был приложен пример, в котором PDM-фильтрация производилась в контексте прерывания. Само собой разумеется, когда автор вопроса стал производить преобразования из PDM в PCM вне прерывания (как ему тут же посоветовали), все проблемы ушли сами собой. Поэтому в прерывании предобработку производить недопустимо! Нельзя варить яйца в микроволновке и выполнять излишние действия в обработчике прерывания!
Рекомендуемая во всех учебниках схема, при наличии предобработки — следующая
Рис.4
Задача предобработки, обладающая высоким приоритетом, почти всё время заблокирована. Обработчик прерывания получил байт из аппаратуры, разбудил предобработчик, передав ему этот байт, после чего вышел. С этого момента, все прерывания вновь разрешены.
Высокоприоритетный предобработчик просыпается, производит накопление данных во внутреннем буфере, после чего — засыпает, вновь давая возможность работы задачам с нормальным приоритетом. Когда строка накоплена (пришёл символ перевода строки), он интерпретирует её и помещает результат в очередь сообщений. Именно такой вариант рекомендуют все академические издания, поэтому я просто обязан был донести классическую мысль и до читателей здесь. Хотя, тут же добавлю, что сам, не как теоретик, а как практик — вижу слабое место этого метода. Выигрываем на редком обращении к очереди, но проигрываем на переключениях контекста для входа в высокоприоритетную задачу. В общем, рекомендации донесены, про недостатки этого подхода — рассказано, а как работать в реальной жизни — каждый должен найти свой метод, подбирая оптимальное соотношение производительности и простоты. Некоторые рекомендации с реальными прикидками, будут в следующей статье, посвящённой прерываниям.
Для реализации очереди сообщений используется класс MessageQueue. Так как очередь сообщений должна эффективно работать с произвольными видами данных, она выполнена в виде шаблона (тип данных подставляется ему в качестве аргумента).
template <typename T> class MessageQueue { ...
Конструктор имеет вид:
MessageQueue(size_t max_size);
Параметр max_size определяет максимальный размер очереди. Если попытаться поставить в очередь элемент, когда она заполнена до отказа — ставящая задача будет заблокирована до тех пор, пока не появится свободное место (какая-либо задача не заберёт один из уже стоящих в очереди элементов).
Так как сказано уже слишком много, здесь не обойтись без примера инициализации очереди. Возьмём фрагмент теста, в котором видно, что элемент очереди имеет тип short, а размерность очереди не будет превышать 5 элементов:
voidMessageQueueTestApp::Initialize() { mQueue = new MessageQueue<short>(5); Task::Add(new MessageSenderTask("send"), Task::PriorityNormal, 0x50); Task::Add(new MessageReceiverTask("receive"), Task::PriorityNormal, 0x50); }
В очередь можно поместить сообщение, воспользовавшись функцией:
Result Push(const T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
Параметр timeout_ms требуется для случаев, когда очередь переполнена. В этом случае, система будет пытаться дождаться момента, когда в ней появится свободное место. А данный параметр — как раз сообщает, сколько допускается ждать.
При необходимости, сообщение можно поставить не в конец очереди, а в её начало. Для этого используется функция:
Result PushFront(const T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
Чтобы изъять очередной элемент из головы очереди, используется функция:
Result Pop(T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
Здесь, соответственно, параметр тайм-аута задаёт время ожидания на случай, если очередь пуста. В течение заданного времени, система будет пытаться дождаться появления в ней сообщений, поставленных в очередь другими задачами.
Также можно получить значение элемента из головы очереди, не изымая его:
Result Peek(T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
Наконец, имеются функции для того, чтобы узнать количество сообщений, стоящих в очереди:
size_t Count()
и максимально возможного размера очереди:
size_t GetMaxSize()
Средства обмена данными между разными контроллерами
Вообще-то, чисто формально, средства обмена данными между контроллерами относятся к драйверам. Но идеологически они относятся к обычным средствам обмена данными, что и является одной из основных особенностей ОСРВ МАКС, поэтому рассмотрим их в части руководства, относящейся к ядру.
Напомню, что в опубликованной версии ОС, физический обмен может осуществляться через проводные интерфейсы UART или SPI, либо через радиомодуль RF24 (также подключённый к интерфейсу SPI). Также напомним, что для активации обмена данными между контроллерами, следует вписать в файл MaksConfig.h строку:
#define MAKS_USE_SHARED_MEM 1
и определить тип физического канала при помощи установки в единицу одной из констант:
MAKS_SHARED_MEM_SPI, MAKS_SHARED_MEM_UART или MAKS_SHARED_MEM_RADIO.
Механизмы SPI и UART в текущей реализации обеспечивают связь только двух устройств, поэтому рекомендованным является именно радиовариант
Теперь, после столь затянувшейся преамбулы, начнём изучение класса SharedMemory.
Объект класса можно инициализировать при помощи функции Initialize(). Слово «можно» применено не случайно. В общем случае, для радиоварианта, инициализация не требуется.
В эту функцию передаётся структура данных. Рассмотрим кратко её поля.
Рассмотрим примеры заполнения данной структуры и вызова функции инициализации.
SmInitInfo info; info.TransferCore = &SpiTransferCore::GetInstance(); info.NotifyMessageReceived = true; info.AutoSendContextsActivity = true; info.SendActivityDelayMs = 100; info.CheckActivityDelayMs = 200; SpiTransferCore::GetInstance().Initialize(); SharedMemory::GetInstance().Initialize(info);
Ещё вариант:
SmInitInfo info; info.TransferCore = &SpiTransferCore::GetInstance(); info.AutoSendContextsActivity = true; info.SendActivityDelayMs = 100; info.CheckActivityDelayMs = 200; SpiTransferCore::GetInstance().Initialize(); SharedMemory::GetInstance().Initialize(info);
Этот класс предоставляет два механизма взаимодействия задач — сообщения и разделяемая память (с возможностью блокировок).
Так как объект «разделяемая память» всегда один, разработчики операционной системы создали файл MaksSharedMemoryExtensions.cpp, преобразующий сложные имена функций в глобальные.
Вот фрагмент этого файла:
Result GetContext(uint32_t context_id, void* data) { return SharedMemory::GetInstance().GetContext(context_id, data); } Result GetContext(uint32_t context_id, void* data, size_t data_length) { return SharedMemory::GetInstance().GetContext(context_id, data, data_length); } Result SetContext(uint32_t context_id, const void* data, size_t data_length) { return SharedMemory::GetInstance().SetContext(context_id, data, data_length); }
Так как во всех приложениях, входящих в комплект поставки, используются глобальные имена функций, я в примерах для данного документа также буду использовать этот вариант именования.
Сообщения
Начнём с сообщений. Для их передачи используется функция SendMessage(). Функция достаточно сложная, поэтому рассмотрим её детально:
Result SendMessage(uint32_t message_id, const void * data, size_t data_length)
Аргументы:
message_id – идентификатор сообщения;
data – указатель на данные сообщения;
data_length – длина данных сообщения.
Пример использования:
const uint32_t APP5_EXPOSE_MESSAGE_ID = 503; ... if (broadcast) { char t = 0; SendMessage(APP5_EXPOSE_MESSAGE_ID, &t, sizeof(t)); } const uint32_t APP5_AIRPLANE_MESSAGE_ID = 504; ... bool AirplaneTask::SendAirplane() { Message msg(_x, _y, _deg, _visibility); return SendMessage(APP5_AIRPLANE_MESSAGE_ID, &msg, sizeof(msg)) == ResultOk; }
Результат функции отражает статус отсылки сообщения. Было оно получено кем-либо из получателей или нет — функция умалчивает. Известно только ушло оно или нет. Для подтверждения, получатель должен самостоятельно послать обратное сообщение.
Соответственно, для ожидания сообщения на стороне получателя используется функция:
Result WaitUntilMessageReceived(SmMessageReceiveArgs & args,uint32_t timeout_ms = INFINITE_TIMEOUT)
Аргументы:
args – ссылка на объект с параметрами сообщения;
timeout_ms – тайм-аут ожидания в миллисекундах. Если значение тайм-аута равно INFINITE_TIMEOUT, то задача будет заблокирована без возможности разблокировки по тайм-ауту (бесконечное ожидание).
Параметры сообщения — это целый класс. Рассмотрим кратко его открытые члены:
uint32_t GetMessageId()
Возвращает идентификатор полученного сообщения:
size_t GetDataLength()
Возвращает размер данных полученного сообщения в байтах.
void CopyDataTo(void* target)
Копирует данные сообщения в указанный буфер. Память для буфера должна быть выделена заранее. Размер буфера должен быть не меньше, чем размер данных сообщения (результат вызова метода GetDataLength)
Таким образом, пример, обслуживающий получение сообщения, посланного в прошлом примере, выглядит так:
void MessageReceiveTask::Execute() { Message msg; while (true) { SmMessageReceiveArgs args; Result res = WaitUntilMessageReceived(args); if (res == ResultOk) { uint32_t mid = args.GetMessageId(); switch (mid) { .... case APP5_EXPOSE_MESSAGE_ID: #ifdef BOARD_LEFT _gfx->ExposeAirplaneRed(); #else _gfx->ExposeAirplaneBlue(); #endif break; case APP5_AIRPLANE_MESSAGE_ID: { args.CopyDataTo(&msg); #ifdef BOARD_LEFT _gfx->UpdateAirplaneRed(msg.X, msg.Y, msg.Deg); _gfx->SetAirplaneRedVisibility(msg.Visibility); #else _gfx->UpdateAirplaneBlue(msg.X, msg.Y, msg.Deg); _gfx->SetAirplaneBlueVisibility(msg.Visibility); #endif } break; ...
Синхронизируемый контекст
Контекстом называют область памяти, которую следует синхронизировать между всеми контроллерами. Цель, преследуемая при синхронизации, может быть любой. Простейший случай — одно устройство сообщает другому о выполненных этапах работы для горячего резервирования. Если оно выйдет из строя — у остальных устройств останется информация о том, как следует подхватить работу. Для устройств, достигающих цели совместно, механизм обмена через контекст может быть более удобен, чем через сообщения. Сообщения следует формировать, передавать, принимать, декодировать. А с памятью контекста можно работать, как с обычной памятью, важно лишь не забывать её синхронизировать, чтобы память одного устройства дублировалась на остальные.
Количество синхронизируемых контекстов в системе может быть произвольным. Поэтому не обязательно всё умещать в один. Под разные нужды можно заводить разные синхронизируемые контексты. Размер памяти, структура данных в ней и прочие параметры синхронизируемого контекста- это забота прикладного программиста (само собой, чем больше объём синхронизируемой памяти, тем медленнее происходит синхронизация, именно поэтому лучше использовать разные контексты малого размера под разные нужды).
Кроме того, даже моменты для сеансов синхронизации — и те выбираются прикладным программистом. ОСРВ МАКС предоставляет API для обеспечения, но вызывать его функции должен прикладной программист. Это связано с тем, что процесс обмена данными происходит относительно медленно. Если всё отдать на откуп операционной системы, то возможны задержки в то время, когда процессорное ядро должно максимально обслуживать иные задачи. Если автоматически синхронизировать контексты слишком часто — будут тратиться ресурсы, если слишком редко — данные могут устареть раньше, чем контроллеры засинхронизируются. Добавляем к этому вопрос, чьи данные важнее (например, при наличии четырёх разных абонентов), после чего становится совершенно ясно — только прикладной программист может инициировать синхронизацию. Именно он знает, когда это лучше сделать, а также кто из абонентов должен раздать свои данные остальным. ОС же обеспечивает прозрачность операции для прикладной программы.
Контекст имеет свой числовой идентификатор (задаётся прикладным программистом). Все приложения могут иметь как один синхронизируемый контекст, так и несколько. Важно только, чтобы их идентификаторы были согласованы в пределах взаимодействующих контроллеров.
Простейшие примеры синхронизируемых данных — роботы-уборщики периодически отмечают на карте убранную ими территорию, чтобы знать о ещё неубранных участках, а также сообщают кто куда собирается сейчас направиться, чтобы не мешать друг другу. Гайковёрты, работающие на одном изделии, отмечают каждую завинченную гайку после окончания завинчивания, чтобы если один выйдет из строя — другой бы закончил его часть. Плата с сенсорным экраном зафиксировала нажатие и отметила этот факт для остальных плат. Ну, и масса других случаев, где требуется разделять память, но допускается делать это несколько раз в секунду (максимум — несколько десятков раз в секунду).
Таким образом, контекст можно представить в виде, показанном рисунке:
Рис. 5. Контекст
А его назначение — можно представить на следующем рисунке:
Рис. 6. Суть синхронизации контекстов
Теперь рассмотрим функции, которые используются для синхронизации контекста:
Result GetContext(uint32_t context_id, void* data);
Копирует данные контекста в указанную область памяти, память должна быть заранее выделена. Подходит для случая когда длина данных заранее известна (например структура с простыми полями).
Аргументы:
context_id – идентификатор контекста;
data – указательна область памяти для хранения контекста;
В результате, будут возвращены данные контекста с указанным идентификатором, которые были получены при последней синхронизации. Таким образом, данная функция отработает быстро, так как данные берутся из локальной копии контекста. Существует второй вариант данной функции:
Result GetContext(uint32_tcontext_id, void *&data, size_t&data_length);
выделяет память и копирует данные и длину контекста. Подходит для случая, когда длина данных заранее неизвестна (например, массив произвольной длины).
Аргументы:
context_id – идентификатор контекста;
data – указательна область памяти для хранения контекста;
data_length – размер в байтах области памяти для хранения контекста.
В принципе, можно создать задачу, которая будет дожидаться обновления контекста, а затем — копировать его новые данные в память приложения. Для этого подойдёт следующая функция:
Result WaitUntilContextUpdated(uint32_t & context_id, uint32_t timeout_ms = INFINITE_TIMEOUT)
Аргументы:
context_id – идентификатор контекста;
timeout_ms – тайм-аут ожидания в миллисекундах. Если значение тайм-аута равно INFINITE_TIMEOUT, то задача будет заблокирована без возможности разблокировки по тайм-ауту (бесконечное ожидание).
Наконец, рассмотрим случай, когда задача хочет обновить свой контекст во всей системе (состоящей из нескольких контроллеров).
Сначала следует захватить контекст. Для этого используется следующая функция:
Result LockContext(uint32_t context_id)
Аргумент:
context_id – идентификатор контекста.
Функция требует обмена между контроллерами, поэтому может выполняться достаточно долго
Если контекст удалось захватить (при одновременной попытке захвата, победит только кто-то один, остальные — получат код ошибки), то контекст можно записать при помощи следующей функции:
Result SetContext(uint32_t context_id, const void * data, size_t data_length)
Аргументы:
context_id – идентификатор контекста;
data – указатель на область памяти для хранения контекста;
data_length – размер в байтах области памяти для хранения контекста.
Наконец, для проведения синхронизации контекста, следует вызвать функцию:
Result UnlockContext(uint32_t context_id)
Аргумент:
context_id – идентификатор контекста.
Именно после её вызова, произойдёт синхронизация контекстов во всей системе.
Функция требует обмена между контроллерами, поэтому может выполняться достаточно долго
Пример работы
Рассмотрим реальный пример работы с синхронизируемыми контекстами, идущий в комплекте поставки ОС. Код содержится в файле ...\maksRTOS\Source\Applications\CounterApp.cpp
В этом примере несколько устройств увеличивают некий счётчик раз в секунду (если запустить это приложение на платах с экраном, значение счётчика будет отображаться визуально). Если один из контроллеров отключить, а затем — включить, он получит текущее содержимое счётчика и будет работать вместе со всеми. Таким образом, система будет вести отсчёт до тех пор, пока в ней «жив» хотя бы один из контроллеров.
Прикладной программист, делавший этот пример, выбрал идентификатор контекста по принципу: «А почему бы и нет?»
static const uint32_t m_context_id = 42;
Память, подлежащая синхронизации, выглядит проще простого:
uint32_t m_counter;
Основные действия, интересующие нас, происходят в функции:
void CounterTask::Execute()
Сначала контроллер пытается выяснить: а не первый ли он в системе? Для этого он пытается получить контекст:
Result result = GetContext(m_context_id, & m_counter);
Если контроллер не первый, то контекст будет получен, а попутно будет получено и значение счётчика, которое существует в системе.
Если контроллер является первым, то контекст получен не будет. В этом случае, его следует создать, что делается следующим образом (там же попутно зануляется счётчик):
if ( result != ResultOk ) { m_counter = 0; result = LockContext(m_context_id); if ( result == ResultOk ) { SetContext(m_context_id, & m_counter, sizeof(m_counter)); UnlockContext(m_context_id); } }
Всё, теперь контекст точно существует, был он найден в системе, к которой мы только что подключились, или создан нами. Входим в бесконечный цикл:
while (true) {
Там мы ждём одну секунду:
Delay(MAKS_TICK_RATE_HZ);
И пытаемся выиграть состязание за право раздать свой счётчик всей системе:
result = LockContext(m_context_id);
Если нам это удалось — раздаём
if ( result == ResultOk ) { GetContext(m_context_id, & m_counter); ++ m_counter; SetContext(m_context_id, & m_counter, sizeof(m_counter)); UnlockContext(m_context_id); }
Как видно, мы раздаём контекст, но не получаем. Дело в том, что в данном примере получают контекст только вновь подключившиеся устройства. Если он получен, то дальше устройство работает автономно. Само собой, лучше поддерживать контакт постоянно, но описание такой системы займёт намного больше бумаги, а против психологии не попрёшь, большинство читателей просто зевнут и перейдут к следующему разделу, поэтому предоставим самым пытливым пользователям разбирательство с более сложными примерами в качестве самостоятельной работы. Принцип же работы разделяемой памяти, надеюсь, теперь уже более-менее понятен.

