Тестируем производительность ZFS и mdadm+ext4 на SSD Sandisk CloudSpeed
для выбора технологии создания локального дискового массива.
Цель данного тестирования — выяснить, с какой реальной скоростью смогут работать виртуальные машины в raw файловых образах, если разместить их на 4-х производительных SSD-дисках. Тестирование будет производится в 32 потока, чтобы приблизительно создать условия работы реального гипервизора.

Замеры будем производить при помощи инструмента fio.
Для mdadm+ext4 были выбраны опции --buffered=0 --direct=1. ZFS не умеет работать с этими опциями, поэтому ожидается, что результат ZFS будет несколько выше. Для сравнения я также отключу эти опции в одном из тестов и для варианта с mdadm.
Мы будем проводить тест с файлом размером в 10ГБ. Предположительно, что этого размера достаточно, чтобы оценить производительность файловой системы при выполнении рутинных операций. Разумеется, если увеличить объем тестовых данных, то общие цифры по всем тестам будут значительно ниже, так как мы сведем на нет все дополнительные средства кеширования и предсказания на файловых системах. Но такой цели нет. Нам нужны не сухие цифры синтетического тестирования, а что-то более приближенное к реальной жизни.
Производитель:
Supermicro X9DRT-HF+
Процессоры:
2x Intel® Xeon® CPU E5-2690 0 @ 2.90GHz C2
Техпроцесс — 32 нм
Количество ядер — 8
Количество потоков — 16
Базовая частота процессора — 2,90 ГГц
Максимальная турбо частота — 3,80 ГГц
Кэш 20 МБ SmartCache
Скорость шины — 8 GT/s QPI
TDP — 135 Вт
Оперативная память:
16x 16384 MB
Тип: DDR3 Registered (Buffered)
Частота: 1333 MHz
Производитель: Micron
Дисковый контроллер:
LSI SAS 2008 RAID IT mode
Твердотельные диски:
4x 1.92Tb SSD Sandisk CloudSpeed ECO Gen. II
SSD, 2.5", 1920 Гб, SATA-III, чтение: 530 Мб/сек, запись: 460 Мб/сек, MLC
Заявленный IOPS произвольного чтения/записи 76000/14000 IOPS
Время наработки на отказ 2000000 ч.
Ядро:
Linux 4.13.4-1-pve #1 SMP PVE 4.13.4-26 (Mon, 6 Nov 2017 11:23:55 +0100) x86_64
Версия ZFS:
v0.7.3-1
Планировщик IO:
Тестовый инструмент:
fio-2.16
# Параметры создания ZFS массива на одном диске
# Параметры создания zraid (raid5 аналога на ZFS)
# Параметры создания zraid2 (raid6 аналога на ZFS)
# Параметры создания striped mirror (raid10 аналога на ZFS)
# Общие параметры для ZFS массивов
Под arc выделено 1/4 всей памяти или 52 ГБ
# Параметры создания массива mdadm raid5
# Параметры создания массива mdadm raid6
# Общие параметры для mdadm 5/6 массивов
# Параметры создания массива mdadm raid10
# Параметры создания таблицы разметки GPT
# Параметры создания ext4 файловой системы
# Параметры монтирования ext4 файловой системы в fstab

В тесте на чтение явно видно влияние буфера ARC на работу файловой системы ZFS. ZFS демонстрирует ровную и высокую скорость во всех тестах. Если выключить --buffered=0 --direct=1 скорость на mdadm raid10 + ext4 по ZFS оказывается в 3 раза медленнее и в 10 раз медленнее по части задержек и IOPS.
Наличие дополнительных дисков в zraid не дает существенного прироста скорости для ZFS. ZFS 0+1 — это так же медленно, как и zraid.
Вот тут ARC никак не спасает ZFS. Цифры наглядно показывают положение дел.

Опять же, буферы помогают ZFS давать ровный результат на всех массивах. mdadm raid6 явно пасует перед raid5 и raid10. Буферизированный и кэшированный mdadm raid10 дает вдвое лучший результат через все варианты на ZFS.

Картина аналогичная и по случайному чтению. ZFS не помогают его буферы и кеши. Он сливает со страшной силой. Особенно пугает результат одиночного диска на ZFS и в целом результаты по ZFS отвратительные.
По mdadm raid5/6 все ожидаемо. Raid5 медленный, raid6 еще медленней, а raid10 примерно на 25-30 % быстрее одиночного диска. Raid10 с буферизацией уносит массив в космос.
Как всем известно, ZFS не быстр.
Он содержит десятки других важных возможностей и достоинств, но это не отменяет того факта, что он существенно медленнее, чем mdadm+ext4, даже с учетом работы кешей и буферов, систем предсказаний и так далее. По этой части неожиданностей нет.
ZFS версий v0.7.x не стал существенно быстрее.
Возможно, быстрее чем v0.6.x, но далек до mdadm+ext4.
Можно найти информацию, что zraid/2 — это улучшенная версия raid5/6, но не по части производительности.
Использование zraid/2 или 0+1 не позволяет добиться более высокой скорости от массива, чем одиночный диск ZFS.
В лучшем случае, скорость будет не ниже или совсем немного выше. В худшем, наличие дополнительных дисков замедлит общую скорость работы. Raid для ZFS — это средство повышения надежности, но не производительности.
Наличие большого ARC не позволит компенсировать отставание ZFS по производительности относительно того же ext4.
Как вы можете увидеть, даже буфер размером в 50 ГБ не способен существенно помочь ZFS не отставать от младшего брата EXT4. Особенно на операциях случайной записи и чтения.
Использовать ли ZFS для виртуализации?
Каждый ответит сам. Лично я отказался от ZFS в пользу mdadm + raid10.
Спасибо Вам большое за внимание.
для выбора технологии создания локального дискового массива.
Цель данного тестирования — выяснить, с какой реальной скоростью смогут работать виртуальные машины в raw файловых образах, если разместить их на 4-х производительных SSD-дисках. Тестирование будет производится в 32 потока, чтобы приблизительно создать условия работы реального гипервизора.
Другие наши публикации
- Zabbix 2.2 верхом на nginx + php-fpm и mariadb
- HAPRoxy для Percona или Galera на CentOS. Его настройка и мониторинг в Zabbix
- «Идеальный» www-кластер. Часть 1. Frontend: NGINX + Keepalived (vrrp) на CentOS
- «Идеальный» кластер. Часть 2.1: Виртуальный кластер на hetzner
- «Идеальный» кластер. Часть 2.2: Высокодоступный и масштабируемый web-сервер, лучшие технологии на страже вашего бизнеса
- «Идеальный» кластер. Часть 3.1 Внедрение MySQL Multi-Master кластера
- Ускорение и оптимизация PHP-сайта. Какие технологии стоит выбирать при настройке сервера под PHP
- Сравнение скорости исполнения кода Drupal для PHP 5.3-5.6 и 7.0. «Битва оптимизаторов кода» apc vs xcache vs opcache
- Производительность Bitrix Старт на Proxmox и Virtuozzo 7 & Virtuozzo Storage
- Virtuozzo Storage: Реальный опыт эксплуатации, советы по оптимизации и решению проблем
Замеры будем производить при помощи инструмента fio.
Для mdadm+ext4 были выбраны опции --buffered=0 --direct=1. ZFS не умеет работать с этими опциями, поэтому ожидается, что результат ZFS будет несколько выше. Для сравнения я также отключу эти опции в одном из тестов и для варианта с mdadm.
Мы будем проводить тест с файлом размером в 10ГБ. Предположительно, что этого размера достаточно, чтобы оценить производительность файловой системы при выполнении рутинных операций. Разумеется, если увеличить объем тестовых данных, то общие цифры по всем тестам будут значительно ниже, так как мы сведем на нет все дополнительные средства кеширования и предсказания на файловых системах. Но такой цели нет. Нам нужны не сухие цифры синтетического тестирования, а что-то более приближенное к реальной жизни.
В качестве тестового стенда используем следующую конфигурацию:
Производитель:
Supermicro X9DRT-HF+
Процессоры:
2x Intel® Xeon® CPU E5-2690 0 @ 2.90GHz C2
Техпроцесс — 32 нм
Количество ядер — 8
Количество потоков — 16
Базовая частота процессора — 2,90 ГГц
Максимальная турбо частота — 3,80 ГГц
Кэш 20 МБ SmartCache
Скорость шины — 8 GT/s QPI
TDP — 135 Вт
Оперативная память:
16x 16384 MB
Тип: DDR3 Registered (Buffered)
Частота: 1333 MHz
Производитель: Micron
Дисковый контроллер:
LSI SAS 2008 RAID IT mode
Твердотельные диски:
4x 1.92Tb SSD Sandisk CloudSpeed ECO Gen. II
SSD, 2.5", 1920 Гб, SATA-III, чтение: 530 Мб/сек, запись: 460 Мб/сек, MLC
Заявленный IOPS произвольного чтения/записи 76000/14000 IOPS
Время наработки на отказ 2000000 ч.
Ядро:
Linux 4.13.4-1-pve #1 SMP PVE 4.13.4-26 (Mon, 6 Nov 2017 11:23:55 +0100) x86_64
Версия ZFS:
v0.7.3-1
Планировщик IO:
cat /sys/block/sdb/queue/scheduler [noop] deadline cfq
Тестовый инструмент:
fio-2.16
Параметры сборки массивов
# Параметры создания ZFS массива на одном диске
zpool create -f -o ashift=12 /dev/sdb
# Параметры создания zraid (raid5 аналога на ZFS)
zpool create -f -o ashift=12 test raidz /dev/sdb /dev/sdc /dev/sdd /dev/sde
# Параметры создания zraid2 (raid6 аналога на ZFS)
zpool create -f -o ashift=12 test raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde
# Параметры создания striped mirror (raid10 аналога на ZFS)
zpool create -f -o ashift=12 test mirror sdb sdc mirror sdd sde
# Общие параметры для ZFS массивов
ZFS set atime=off test ZFS set compression=off test ZFS set dedup=off test ZFS set primarycache=all test
Под arc выделено 1/4 всей памяти или 52 ГБ
cat /etc/modprobe.d/ZFS.conf options ZFS zfs_arc_max=55834574848
# Параметры создания массива mdadm raid5
mdadm --zero-superblock /dev/sd[bcde] mdadm --create --verbose --force --assume-clean --bitmap=internal --bitmap-chunk=131072 /dev/md0 --level=5 --raid-devices=4 /dev/sd[bcde]
# Параметры создания массива mdadm raid6
mdadm --zero-superblock /dev/sd[bcde] mdadm --create --verbose --force --assume-clean --bitmap=internal --bitmap-chunk=131072 /dev/md0 --level=6 --raid-devices=4 /dev/sd[bcde]
# Общие параметры для mdadm 5/6 массивов
echo 32768 > /sys/block/md0/md/stripe_cache_size blockdev --setra 65536 /dev/md0 echo 600000 > /proc/sys/dev/raid/speed_limit_max echo 600000 > /proc/sys/dev/raid/speed_limit_min
# Параметры создания массива mdadm raid10
mdadm --zero-superblock /dev/sd[bcde] mdadm --create --verbose --force --assume-clean --bitmap=internal --bitmap-chunk=131072 /dev/md0 --level=10 --raid-devices=4 /dev/sd[bcde]
# Параметры создания таблицы разметки GPT
parted -a optimal /dev/md0 mktable gpt mkpart primary 0% 100% q
# Параметры создания ext4 файловой системы
mkfs.ext4 -m 0 -b 4096 -E stride=128,stripe-width=256 /dev/md0p1 (/dev/sdb) Где stripe-width=256 для raid6 и raid10 и stripe-width=384 для raid5
# Параметры монтирования ext4 файловой системы в fstab
UUID="xxxxx" /test ext4 defaults,noatime,lazytime 1 2
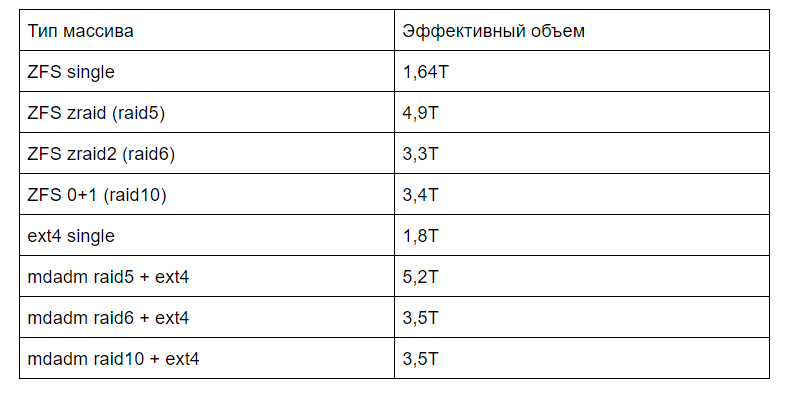
Результаты
fio --directory=/test/ --name=read --rw=read --bs=4k --size=200G --numjobs=1 --time_based --runtime=60 --group_reporting --ioengine libaio --iodepth=32 # Для ext4 + параметры --buffered=0 --direct=1
В тесте на чтение явно видно влияние буфера ARC на работу файловой системы ZFS. ZFS демонстрирует ровную и высокую скорость во всех тестах. Если выключить --buffered=0 --direct=1 скорость на mdadm raid10 + ext4 по ZFS оказывается в 3 раза медленнее и в 10 раз медленнее по части задержек и IOPS.
Наличие дополнительных дисков в zraid не дает существенного прироста скорости для ZFS. ZFS 0+1 — это так же медленно, как и zraid.
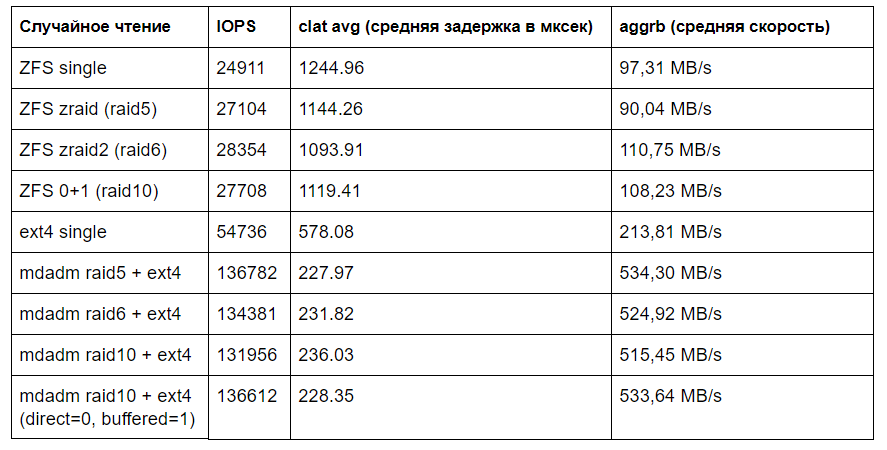
fio --directory=/ --name=test --rw=randread --bs=4k --size=10G --numjobs=1 --time_based --runtime=60 --group_reporting --ioengine libaio --iodepth=32 --buffered=0 --direct=1 # Для ext4 + параметры --buffered=0 --direct=1
Вот тут ARC никак не спасает ZFS. Цифры наглядно показывают положение дел.
fio --directory=/ --name=test --rw=write --bs=4k --size=10G --numjobs=1 --group_reporting --ioengine libaio --iodepth=32 --buffered=0 --direct=1 # Для ext4 + параметры --buffered=0 --direct=1
Опять же, буферы помогают ZFS давать ровный результат на всех массивах. mdadm raid6 явно пасует перед raid5 и raid10. Буферизированный и кэшированный mdadm raid10 дает вдвое лучший результат через все варианты на ZFS.
fio --directory=/ --name=test --rw=randwrite --bs=4k --size=10G --numjobs=1 --group_reporting --ioengine libaio --iodepth=32 --buffered=0 --direct=1 # Для ext4 + параметры --buffered=0 --direct=1
Картина аналогичная и по случайному чтению. ZFS не помогают его буферы и кеши. Он сливает со страшной силой. Особенно пугает результат одиночного диска на ZFS и в целом результаты по ZFS отвратительные.
По mdadm raid5/6 все ожидаемо. Raid5 медленный, raid6 еще медленней, а raid10 примерно на 25-30 % быстрее одиночного диска. Raid10 с буферизацией уносит массив в космос.
Выводы
Как всем известно, ZFS не быстр.
Он содержит десятки других важных возможностей и достоинств, но это не отменяет того факта, что он существенно медленнее, чем mdadm+ext4, даже с учетом работы кешей и буферов, систем предсказаний и так далее. По этой части неожиданностей нет.
ZFS версий v0.7.x не стал существенно быстрее.
Возможно, быстрее чем v0.6.x, но далек до mdadm+ext4.
Можно найти информацию, что zraid/2 — это улучшенная версия raid5/6, но не по части производительности.
Использование zraid/2 или 0+1 не позволяет добиться более высокой скорости от массива, чем одиночный диск ZFS.
В лучшем случае, скорость будет не ниже или совсем немного выше. В худшем, наличие дополнительных дисков замедлит общую скорость работы. Raid для ZFS — это средство повышения надежности, но не производительности.
Наличие большого ARC не позволит компенсировать отставание ZFS по производительности относительно того же ext4.
Как вы можете увидеть, даже буфер размером в 50 ГБ не способен существенно помочь ZFS не отставать от младшего брата EXT4. Особенно на операциях случайной записи и чтения.
Использовать ли ZFS для виртуализации?
Каждый ответит сам. Лично я отказался от ZFS в пользу mdadm + raid10.
Спасибо Вам большое за внимание.

