Оба авторе: Лин Кларк — разработчик в группе Mozilla Developer Relations. Занимается JavaScript, WebAssembly, Rust и Servo, а также рисует комиксы о коде.
Люди называют WebAssembly фактором, меняющим правила игры, потому что эта технология ускоряет выполнение кода в вебе. Некоторые из ускорений уже реализованы, а другие появятся позже.
Одна из техник — потоковая компиляция, когда браузер компилирует код во время его загрузки. До настоящего времени эта технология рассматривалась лишь как потенциальный вариант ускорения. Но с выпуском Firefox 58 она станет реальностью.
Firefox 58 также включает в себя двухуровневый компилятор. Новый базовый компилятор компилирует код в 10–15 раз быстрее, чем оптимизирующий компилятор.
Вместе эти два изменения означают, что мы компилируем код быстрее, чем он поступает из сети.

На десктопе мы компилируем 30-60 МБ кода WebAssembly в секунду. Это быстрее, чем сеть доставляет пакеты.
Если у вас Firefox Nightly или Beta, то можете опробовать технологию на собственном устройстве. Даже на средненьком мобильном устройстве компиляция осуществляется на 8 МБ/с — это быстрее, чем скорость скачивания в большинстве мобильных сетей.
Другими словами, выполнение кода начинается сразу по окончании скачивания.
Адвокаты веб-производительности критически относятся к большому количеству JavaScript на сайтах, потому что это сильно замедляет загрузку веб-страниц.
Одна из главных причин такого замедления — время разбора и компиляции. Как заметил Стив Саудерс, раньше бутылочным горлышком веб-производительности была cеть, а теперь — CPU, а именно основной поток выполнения.
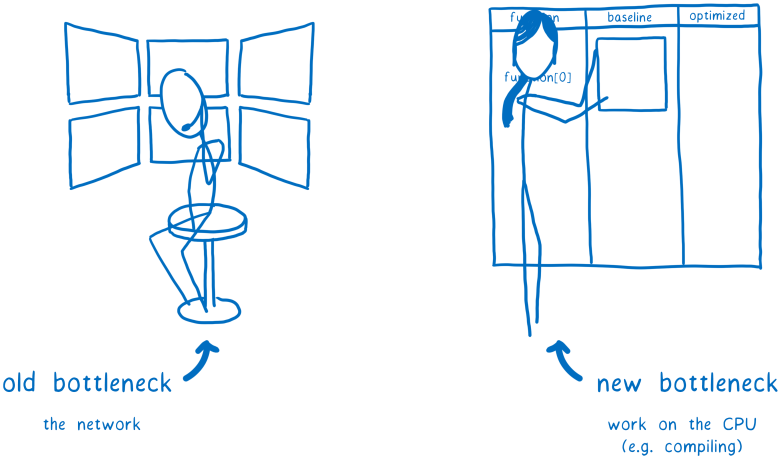
Так что мы хотим вынести как можно больше работы из основного потока. Мы также хотим как можно раньше обеспечить интерактивность страницы, поэтому используем всё время CPU. А лучше вообще уменьшить нагрузку на CPU.
С помощью JavaScript достижимы некоторые из этих целей. Можно разбирать файлы вне основного потока после их получения. Но их по-прежнему приходится разбирать, а это немалая работа. И нужно дождаться окончания разбора перед началом компиляции. А для компиляции вы возвращаетесь в основной поток, потому что обычно происходит ленивая компиляция JS на лету.
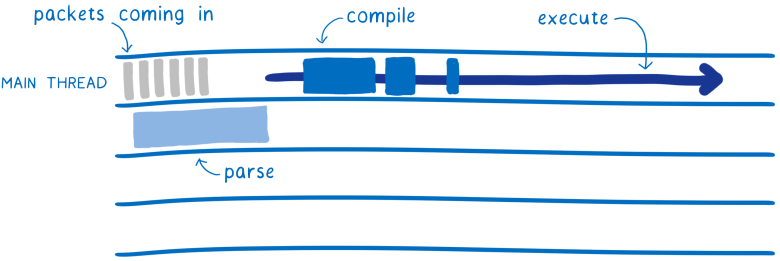
При использовании WebAssembly с самого начала меньше работы. Декодирование WebAssembly гораздо проще и быстрее, чем разбор JavaScript. И эти декодирование и компиляцию можно разбивать по нескольким потокам.
Это означает, что несколько потоков будут осуществлять базовую компиляцию, заметно ускоряя её. По окончании процесса предварительно скомпилированный код начинает исполняться в основном потоке. Не нужно делать остановку на ожидание компиляции, как в случае JS.
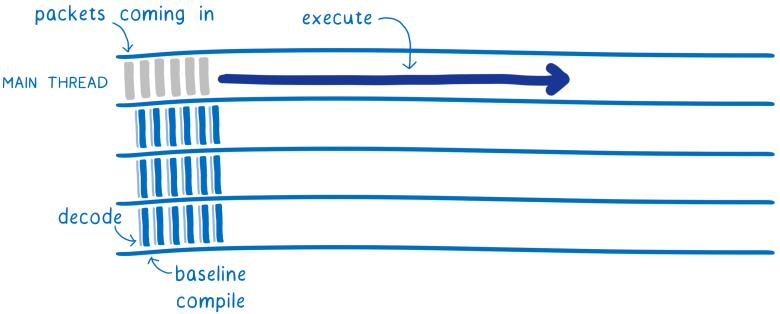
Хотя предварительно скомпилированный код запускается в основном потоке, другие потоки в этом время работают над оптимизированной версией. Когда готова оптимизированная версия, она заменяет предварительную — и код выполняется ещё быстрее.
Это делает загрузку WebAssembly более похожей на декодирование изображения, чем на загрузку JavaScript. Подумайте об этом… адвокаты производительности в штыки встречают скрипты более 150 КБ, но изображения такого размера не вызывает нареканий.

Это потому что загрузка изображений осуществляется гораздо быстрее, как объяснял Эдди Османи в статье «Цена JavaScript». И декодирование изображения не блокирует основной поток, как объяснял Алекс Расселл в статье «Вы можете себе это позволить? Бюджет веб-производительности в реальном мире».
Это не означает, что файлы WebAssembly будут такими же большими, как изображения. Хотя первые версии инструментов WebAssembly действительно создают большие файлы, но это потому что туда приходится включать значительную часть среды выполнения. Сейчас идёт активная работа, чтобы уменьшить их размер. Например, в Emscripten действует «инициатива по ужиманию». В Rust вы и сейчас можете получить довольно маленькие файлы, применив цель wasm32-unknown-unknown. И есть инструменты вроде wasm-gc и wasm-snip для ещё большей оптимизации.
Значит, файлы WebAssembly будут загружаться гораздо быстрее, чем эквивалентный JavaScript.
Это очень важно. Как заметил Иегуда Кац, это фактор, действительно меняющий правила игры.
Так давайте посмотрим, как работает новый компилятор.
Чем раньше вы начинаете компиляцию кода, тем раньше её закончите. Это то, что делает потоковая компиляция… начиная компиляцию файла .wasm как можно раньше.
Когда вы скачиваете файл, он не приходит одним куском. Вместо этого он поступает серией пакетов.
Раньше нужно было скачать все пакеты файла .wasm, затем сетевой слой браузера помещал его в ArrayBuffer.
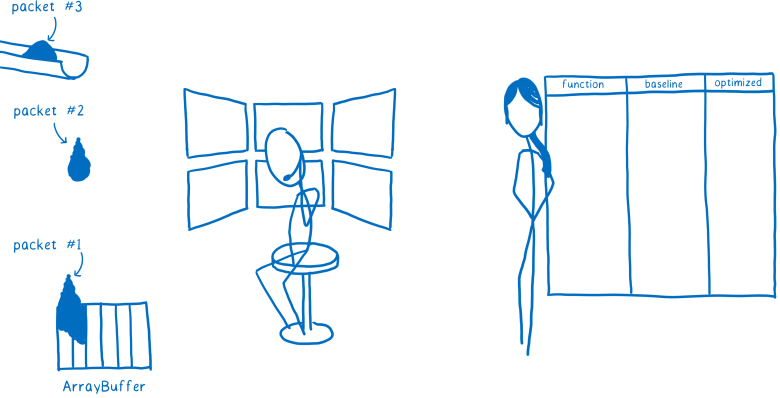
Потом этот ArrayBuffer передавался Web VM (aka движок JS). В этот момент компилятор WebAssembly начал бы компиляцию.

Но нет никакой серьёзной причины оставлять компилятор в ожидании. Технически возможно компилировать WebAssembly строчка за строчкой. Значит, процесс можно начать после поступления первого же фрагмента.
Именно так поступает наш компилятор, который использует преимущества потоковых программных интерфейсов WebAssembly.
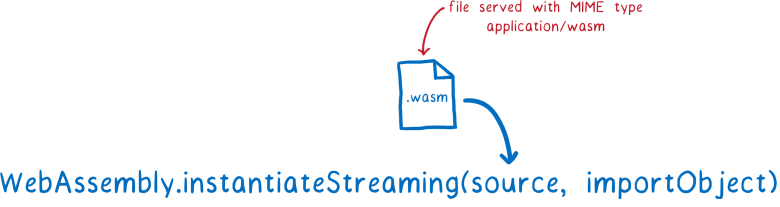
Если вы передадите объект Response в
Помимо одновременной загрузки и компиляции кода, есть ещё одно преимущество.
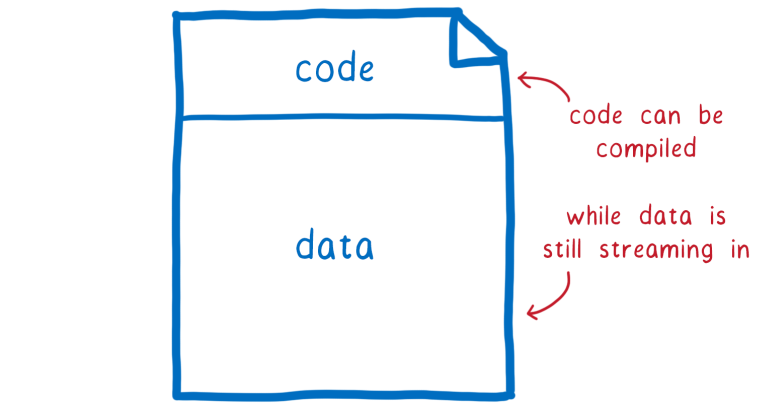
Кодовый раздел модуля .wasm идёт в самом начале, перед остальными данными (которые размещаются в объекте памяти модуля). Так что в случае потоковой компиляции код компилируется в то время, как данные модуля ещё не скачались до конца. Если вашему модулю требуется много данных, то объект памяти может быть размером в несколько мегабайт, и потоковая компиляция даст существенное увеличение производительности.
С потоковой компиляцией процесс компиляции начинается раньше. Но мы можем также сделать его быстрее.
Если хотите быстрой работы кода, то его нужно оптимизировать. Но выполнение этих оптимизаций во время компиляции занимает время, что замедляет саму компиляцию. Так что это определённый компромисс.
Но если использовать два компилятора, то можно получить преимущества и быстрой компиляции, и оптимизированного кода. Первый быстро компилирует без особых оптимизаций, а второй работает более медленно, но выдаёт более оптимизированный код.
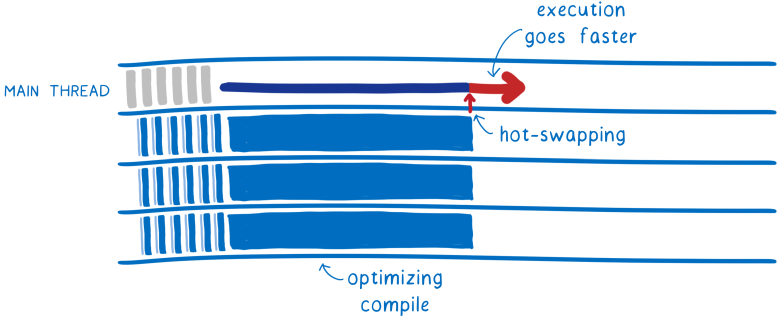
Это называется многоуровневым компилятором. Когда изначально поступает код, он компилируется компилятором Уровня 1 (или базовым компилятором). После того, как скомпилированный базовым компилятором код пошёл на запуск, компилятор Уровня 2 снова обрабатывает код и в фоновом режиме готовит более оптимизированную версию.
По завершении процесса происходит горячая замена базовой версии кода на оптимизированную версию. Это ускоряет выполнение кода.
В движках JavaScript давно используются многоуровневые компиляторы. Однако движки JS используют компилятор Уровня 2 (то есть оптимизирующий) только для «горячего» кода… который часто вызывается на исполнение.
В отличие от них, в WebAssembly компилятор Уровня 2 с охотой выполнит полную перекомпиляцию, оптимизировав весь код модуля. В будущем мы можем добавить больше опций для управления, насколько жадной или ленивой должна быть оптимизация.
Базовый компилятор экономит много времени на загрузке. Он работает в 10–15 раз быстрее, чем оптимизирующий компилятор. И скомпилированный код в нашем случае работает всего в два раза медленнее.
Это означает, что ваш код будет работать достаточно быстро даже в первые моменты, когда работает только базовая неоптимизированная версия.
В статье по Firefox Quantum я объясняла варианты грубо- и тонконастроенной параллелизации. Для компиляции WebAssembly мы используем оба типа.
Выше я упоминала, что оптимизирующий компилятор работает в фоновом режиме, освобождая основной поток для исполнения кода. Базовая скомпилированная версия может работать в то время как оптимизирующий компилятор выполняет свою рекомпиляцию.
Но на большинстве компьютеров в таком случае всё равно бóльшая часть ядер останутся незагруженными. Чтобы оптимально использовать все ядра, оба компилятора используют тонконастроенную параллелизацию для разделения работы.
Единицей параллелизации является функция. Каждая функция может быть скомпилирована независимо, на отдельном ядре. На самом деле это настолько тонкая настройка, что в реальности нам приходится группировать эти функции в бóльшие группы функций. Эти группы рассылаются по разным ядрам.
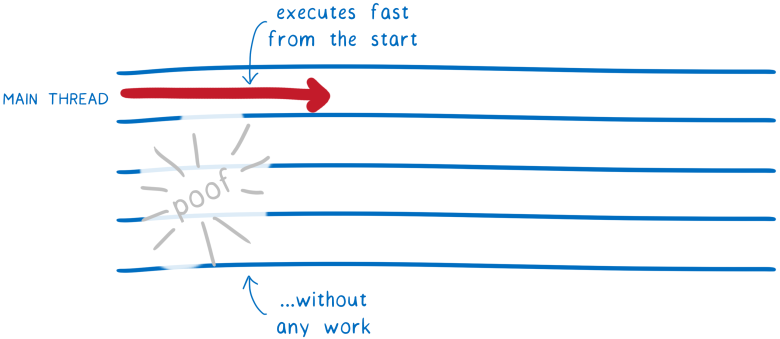
В настоящее время декодирование и компиляция выполняются повторно каждый раз, когда вы перезагружаете страницу. Но если у вас тот же файл .wasm, то он должен скомпилироваться в тот же машинный код.
Значит почти всегда эту работу можно пропустить. Именно этим мы займёмся в будущем. Декодирование и компиляция будут выполняться при первой загрузке страницы, а полученный в результате машинный код будет сохранён в кэше HTTP. Затем при запросе этого URL будет выдаваться сразу прекомпилированный машинный код.
Так время загрузки вообще исчезнет при последующих загрузках страницы.
Фундамент для этой функции уже заложен. В версии Firefox 58 мы таким образом кэшируем байткод JavaScript. Нужно только расширить эту функцию для поддержки файлов .wasm.
Люди называют WebAssembly фактором, меняющим правила игры, потому что эта технология ускоряет выполнение кода в вебе. Некоторые из ускорений уже реализованы, а другие появятся позже.
Одна из техник — потоковая компиляция, когда браузер компилирует код во время его загрузки. До настоящего времени эта технология рассматривалась лишь как потенциальный вариант ускорения. Но с выпуском Firefox 58 она станет реальностью.
Firefox 58 также включает в себя двухуровневый компилятор. Новый базовый компилятор компилирует код в 10–15 раз быстрее, чем оптимизирующий компилятор.
Вместе эти два изменения означают, что мы компилируем код быстрее, чем он поступает из сети.
На десктопе мы компилируем 30-60 МБ кода WebAssembly в секунду. Это быстрее, чем сеть доставляет пакеты.
Если у вас Firefox Nightly или Beta, то можете опробовать технологию на собственном устройстве. Даже на средненьком мобильном устройстве компиляция осуществляется на 8 МБ/с — это быстрее, чем скорость скачивания в большинстве мобильных сетей.
Другими словами, выполнение кода начинается сразу по окончании скачивания.
Почему это важно?
Адвокаты веб-производительности критически относятся к большому количеству JavaScript на сайтах, потому что это сильно замедляет загрузку веб-страниц.
Одна из главных причин такого замедления — время разбора и компиляции. Как заметил Стив Саудерс, раньше бутылочным горлышком веб-производительности была cеть, а теперь — CPU, а именно основной поток выполнения.
Так что мы хотим вынести как можно больше работы из основного потока. Мы также хотим как можно раньше обеспечить интерактивность страницы, поэтому используем всё время CPU. А лучше вообще уменьшить нагрузку на CPU.
С помощью JavaScript достижимы некоторые из этих целей. Можно разбирать файлы вне основного потока после их получения. Но их по-прежнему приходится разбирать, а это немалая работа. И нужно дождаться окончания разбора перед началом компиляции. А для компиляции вы возвращаетесь в основной поток, потому что обычно происходит ленивая компиляция JS на лету.
При использовании WebAssembly с самого начала меньше работы. Декодирование WebAssembly гораздо проще и быстрее, чем разбор JavaScript. И эти декодирование и компиляцию можно разбивать по нескольким потокам.
Это означает, что несколько потоков будут осуществлять базовую компиляцию, заметно ускоряя её. По окончании процесса предварительно скомпилированный код начинает исполняться в основном потоке. Не нужно делать остановку на ожидание компиляции, как в случае JS.
Хотя предварительно скомпилированный код запускается в основном потоке, другие потоки в этом время работают над оптимизированной версией. Когда готова оптимизированная версия, она заменяет предварительную — и код выполняется ещё быстрее.
Это делает загрузку WebAssembly более похожей на декодирование изображения, чем на загрузку JavaScript. Подумайте об этом… адвокаты производительности в штыки встречают скрипты более 150 КБ, но изображения такого размера не вызывает нареканий.
Это потому что загрузка изображений осуществляется гораздо быстрее, как объяснял Эдди Османи в статье «Цена JavaScript». И декодирование изображения не блокирует основной поток, как объяснял Алекс Расселл в статье «Вы можете себе это позволить? Бюджет веб-производительности в реальном мире».
Это не означает, что файлы WebAssembly будут такими же большими, как изображения. Хотя первые версии инструментов WebAssembly действительно создают большие файлы, но это потому что туда приходится включать значительную часть среды выполнения. Сейчас идёт активная работа, чтобы уменьшить их размер. Например, в Emscripten действует «инициатива по ужиманию». В Rust вы и сейчас можете получить довольно маленькие файлы, применив цель wasm32-unknown-unknown. И есть инструменты вроде wasm-gc и wasm-snip для ещё большей оптимизации.
Значит, файлы WebAssembly будут загружаться гораздо быстрее, чем эквивалентный JavaScript.
Это очень важно. Как заметил Иегуда Кац, это фактор, действительно меняющий правила игры.
Так давайте посмотрим, как работает новый компилятор.
Потоковая компиляция: раннее начало компиляции
Чем раньше вы начинаете компиляцию кода, тем раньше её закончите. Это то, что делает потоковая компиляция… начиная компиляцию файла .wasm как можно раньше.
Когда вы скачиваете файл, он не приходит одним куском. Вместо этого он поступает серией пакетов.
Раньше нужно было скачать все пакеты файла .wasm, затем сетевой слой браузера помещал его в ArrayBuffer.
Потом этот ArrayBuffer передавался Web VM (aka движок JS). В этот момент компилятор WebAssembly начал бы компиляцию.
Но нет никакой серьёзной причины оставлять компилятор в ожидании. Технически возможно компилировать WebAssembly строчка за строчкой. Значит, процесс можно начать после поступления первого же фрагмента.
Именно так поступает наш компилятор, который использует преимущества потоковых программных интерфейсов WebAssembly.
Если вы передадите объект Response в
WebAssembly.instantiateStreaming, новые фрагменты кода будут поступать в движок WebAssembly сразу после скачивания. Затем компилятор может начать работу над первым фрагментом, пока следующий ещё скачивается.Помимо одновременной загрузки и компиляции кода, есть ещё одно преимущество.
Кодовый раздел модуля .wasm идёт в самом начале, перед остальными данными (которые размещаются в объекте памяти модуля). Так что в случае потоковой компиляции код компилируется в то время, как данные модуля ещё не скачались до конца. Если вашему модулю требуется много данных, то объект памяти может быть размером в несколько мегабайт, и потоковая компиляция даст существенное увеличение производительности.
С потоковой компиляцией процесс компиляции начинается раньше. Но мы можем также сделать его быстрее.
Базовый компилятор 1-го уровня: ускорение компиляции
Если хотите быстрой работы кода, то его нужно оптимизировать. Но выполнение этих оптимизаций во время компиляции занимает время, что замедляет саму компиляцию. Так что это определённый компромисс.
Но если использовать два компилятора, то можно получить преимущества и быстрой компиляции, и оптимизированного кода. Первый быстро компилирует без особых оптимизаций, а второй работает более медленно, но выдаёт более оптимизированный код.
Это называется многоуровневым компилятором. Когда изначально поступает код, он компилируется компилятором Уровня 1 (или базовым компилятором). После того, как скомпилированный базовым компилятором код пошёл на запуск, компилятор Уровня 2 снова обрабатывает код и в фоновом режиме готовит более оптимизированную версию.
По завершении процесса происходит горячая замена базовой версии кода на оптимизированную версию. Это ускоряет выполнение кода.
В движках JavaScript давно используются многоуровневые компиляторы. Однако движки JS используют компилятор Уровня 2 (то есть оптимизирующий) только для «горячего» кода… который часто вызывается на исполнение.
В отличие от них, в WebAssembly компилятор Уровня 2 с охотой выполнит полную перекомпиляцию, оптимизировав весь код модуля. В будущем мы можем добавить больше опций для управления, насколько жадной или ленивой должна быть оптимизация.
Базовый компилятор экономит много времени на загрузке. Он работает в 10–15 раз быстрее, чем оптимизирующий компилятор. И скомпилированный код в нашем случае работает всего в два раза медленнее.
Это означает, что ваш код будет работать достаточно быстро даже в первые моменты, когда работает только базовая неоптимизированная версия.
Параллелизация: ещё большее ускорение
В статье по Firefox Quantum я объясняла варианты грубо- и тонконастроенной параллелизации. Для компиляции WebAssembly мы используем оба типа.
Выше я упоминала, что оптимизирующий компилятор работает в фоновом режиме, освобождая основной поток для исполнения кода. Базовая скомпилированная версия может работать в то время как оптимизирующий компилятор выполняет свою рекомпиляцию.
Но на большинстве компьютеров в таком случае всё равно бóльшая часть ядер останутся незагруженными. Чтобы оптимально использовать все ядра, оба компилятора используют тонконастроенную параллелизацию для разделения работы.
Единицей параллелизации является функция. Каждая функция может быть скомпилирована независимо, на отдельном ядре. На самом деле это настолько тонкая настройка, что в реальности нам приходится группировать эти функции в бóльшие группы функций. Эти группы рассылаются по разным ядрам.
…и затем пропуск всей этой работы за счёт полного кэширования (в будущем)
В настоящее время декодирование и компиляция выполняются повторно каждый раз, когда вы перезагружаете страницу. Но если у вас тот же файл .wasm, то он должен скомпилироваться в тот же машинный код.
Значит почти всегда эту работу можно пропустить. Именно этим мы займёмся в будущем. Декодирование и компиляция будут выполняться при первой загрузке страницы, а полученный в результате машинный код будет сохранён в кэше HTTP. Затем при запросе этого URL будет выдаваться сразу прекомпилированный машинный код.
Так время загрузки вообще исчезнет при последующих загрузках страницы.
Фундамент для этой функции уже заложен. В версии Firefox 58 мы таким образом кэшируем байткод JavaScript. Нужно только расширить эту функцию для поддержки файлов .wasm.

