Казанский университет Иннополис в порядке эксперимента учит студентов-программистов разработке хардвера. Причем под разработкой хардвера имеется в виду не программирование микроконтроллеров внутри скажем роботов, а проектирование цифровых схем на уровне регистровых передач (Register Transfer Level — RTL), с использованием языков описания аппаратуры (Hardware Description Language — HDL) и лабораторными занятиями на программируемых логических интегральных схемах (ПЛИС / FPGA — Field Programmable Gate Array).
Зачем это нужно программистам? Ведь электронике учат на (гораздо менее массовых) факультетах электроники, где студент сначала изучает физику электричества, аналоговые схемы, делает пару лаб с мультиплексорами, после чего все это забывает и идет работать программистом.
Одна из причин, зачем цифровая схемотехника программисту — в последнее время происходит бум нейросетей. Если вы хотите чтобы обучение сложной сети занимало не недели / дни / часы, а часы / минуты / секунды, без аппаратных ускорителей не обойтись. Только специализированный хардвер выполнит параллельно большое количество умножений малой точности с одновременными транзакциями к океану памяти. В будущем нас ждут специализированные ASIC (application-specific integrated circuits) для AI, причем повсюду. В них будет как традиционный процессор, так и большие AI блоки на борту, с возможностью частичной реконфигурации.
От Гугла и Микрософта до Сколково и Иннополиса растет понимание, что нужны специалисты, которые могут строить такие сопроцессоры. Они должны владеть хардверной микроархитектурой, одновременно с пониманием софтверной экосистемы и алгоритмов. А владение микроархитектурой стоит на понимании уровня регистровых передач. Как это реализуется сейчас в Иннополисе:

Курс компьютерной архитектуры в Иннополисе разрабатывает его ректор Александр Тормасов, вместе с приглашенными им в Казань иностранными специалистами: итальянским профессором Giancarlo Succi, который работает в Иннополисе деканом, и Muhammad Fahim, который до Иннополиса работал в университетах Южной Кореи и Пакистана.
Сам ректор Тормасов до Иннополиса работал завкфедрой информатики МФТИ и возглавлял отдел перспективных разработок SWsoft (позже Parallels), где занимался виртуализацией. Paralells является одной из немногих российских компаний, широко известных в Америке — как минимум пара американских инженеров были удивлены, когда я сказал им, что Parallels является российской компанией, они думали что это американская компания. Кроме этого Тормасов возглавляет российское отделение IEEE Computer Society.
Тормасов любил вводить всякие новомодные штучки еще 30 лет назад — тогда он обучал студентов МФТИ использовать Unix, shell, awk итд. Линукса тогда еще не было, а Unix был на австралийских компьютерах Labtam с процессором National Semicondustor NS32000. До Тормасова студенты работали на БЭСМ-6 с Фортраном и перфокартами.
Итак, недавно Тормасов попросил меня прочитать по скайпу пару лекций про HDL, RTL и FPGA для его курса компьютерной архитектуры. На эти лекции у него ходит более 200 студентов, так что у эксперимента неплохая выборка. Лекции Тормасов попросил прочитать на английском, по-видимому потому что 1) в Иннополисе есть иностранные студенты 2) Giancarlo Succi и Muhammad Fahim тоже читают на английском и 3) студентам нужно тренировать comprehension, в том числе на мой тяжелый украинский акцент.
Целью первой лекции было дать студентам достаточно информации, чтобы они могли симулировать простейшую схему на программном симуляторе, а также синтезировать эту схему и сконфигурировать ею ПЛИС. Также нужно было наглядно показать, что схема — это не программа:
Слайды первой лекции в формате PDF.
Целью второй лекции было дать обзор того, что их ожидает, если они захотят копать тему цифровой логики глубже. Им нужно понять концепцию D-триггера, последовательностной логики, конечного автомата и конвейера. Тогда они смогут делать интересные схемы, которые повторяют действия, передают информацию с датчиков и т.д. — вплоть до процессорных ядер и дальше.
Слайды второй лекции в формате PDF.
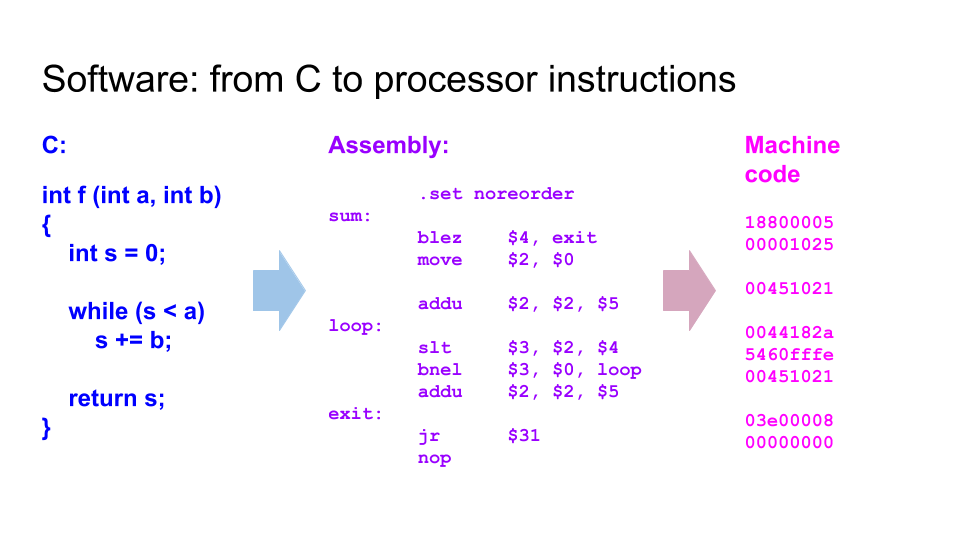
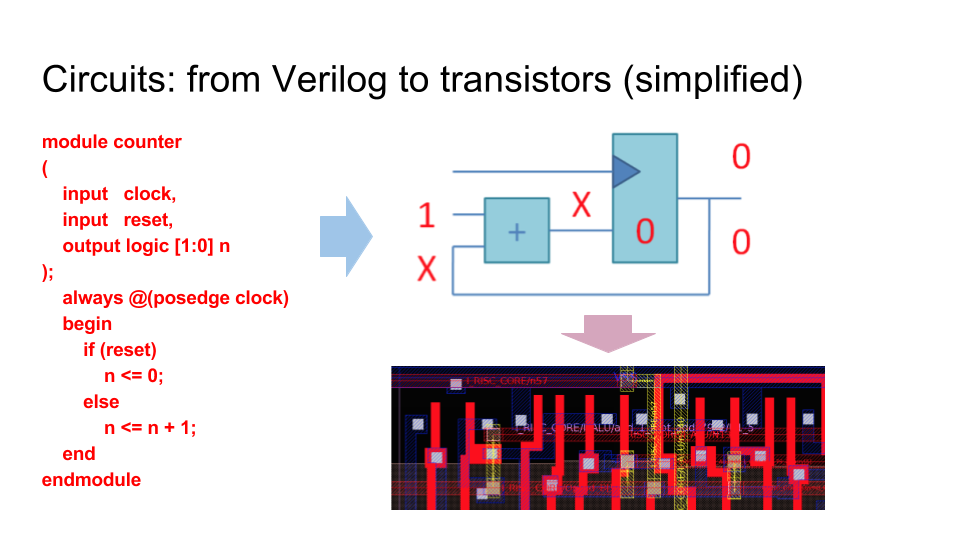
Несколько ключевых слайдов. Разница между схемами и программами. Языки программирования (например Си) компилируются в цепочки инструкция, которые процессор выбирает з памяти. Языки описания аппаратуры (например Verilog) синтезируется в граф из логических элементов, которые в конечном итоге превращаются в транзисторы и дорожки на микросхеме, которая выпекается на фабрике:
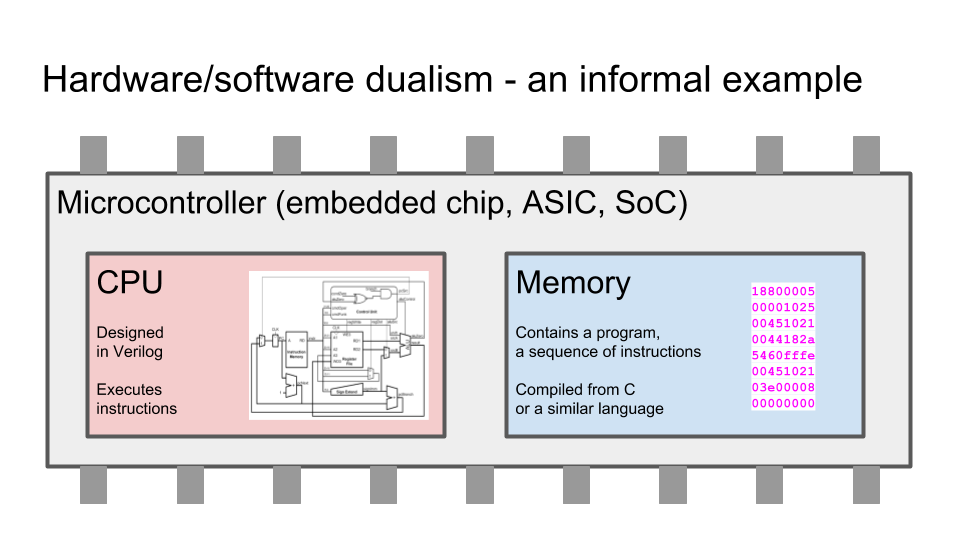
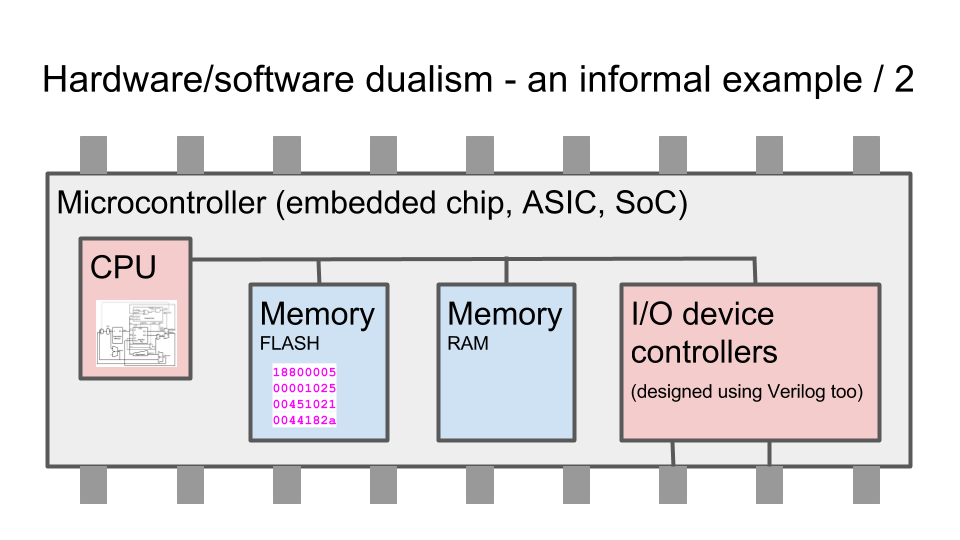
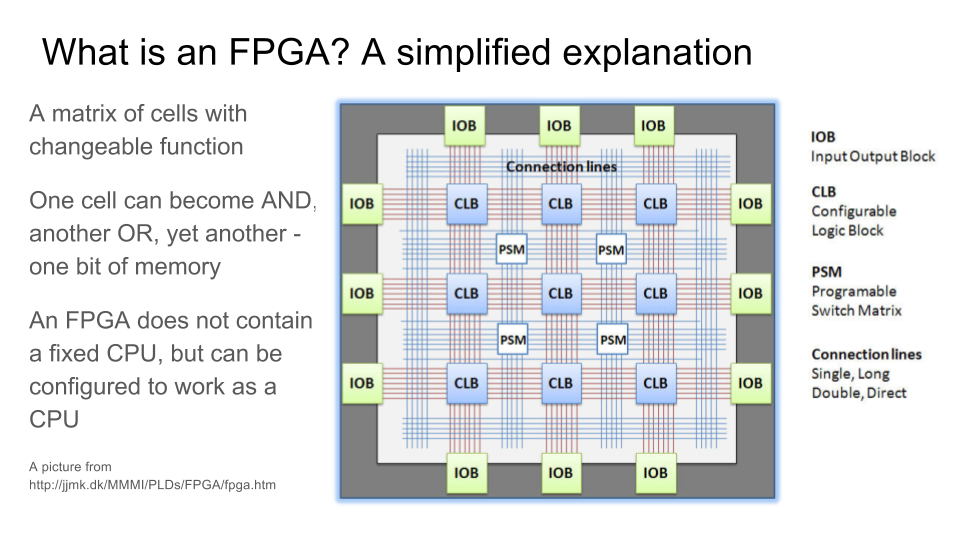
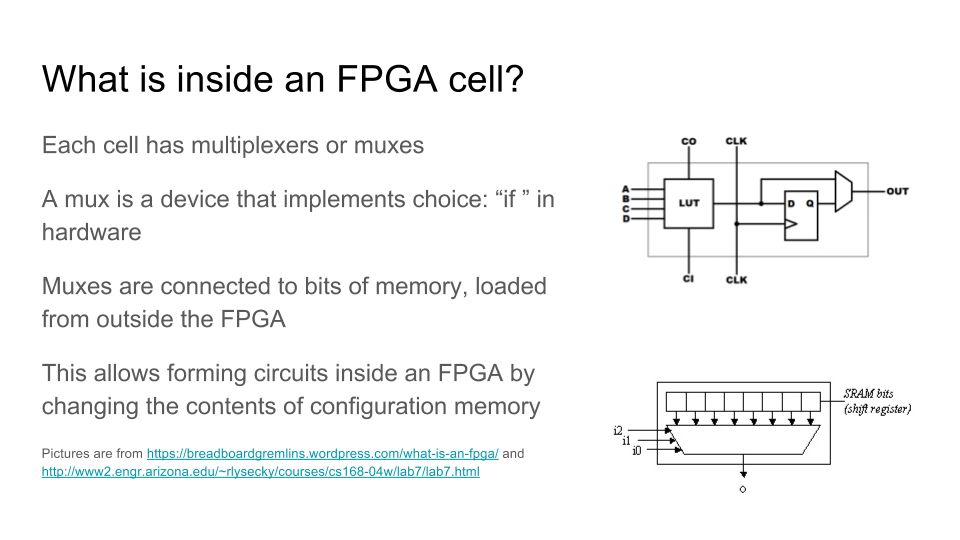
Как работает ПЛИС / FPGA — матрица из логических элементов, функцию которых можно менять с помощью мультиплексоров, подсоединенных к битам конфигурационной памяти:
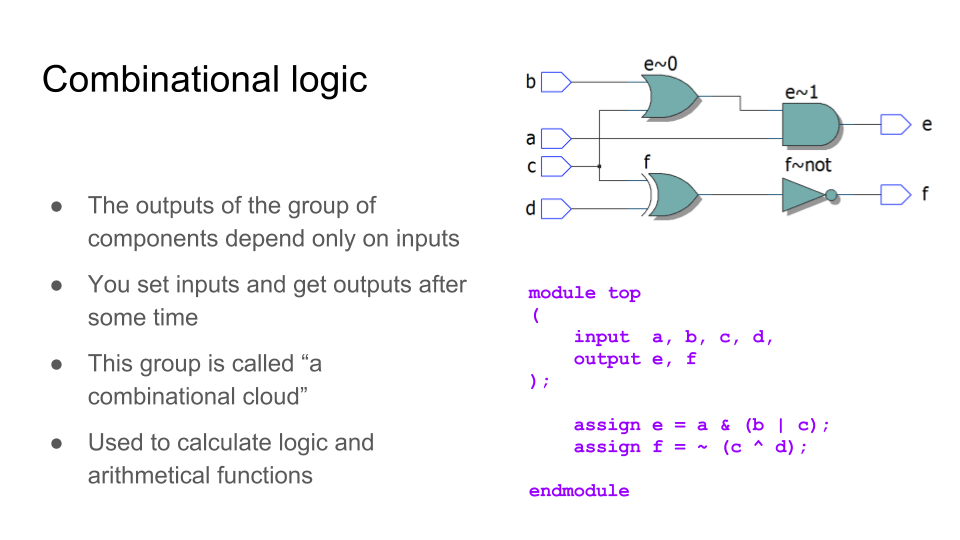
Простейшая схема. Комбинационная логика — кладем на вход некие данные, через некоторое время (с задержкой распространения) получаем на выходе ответ.
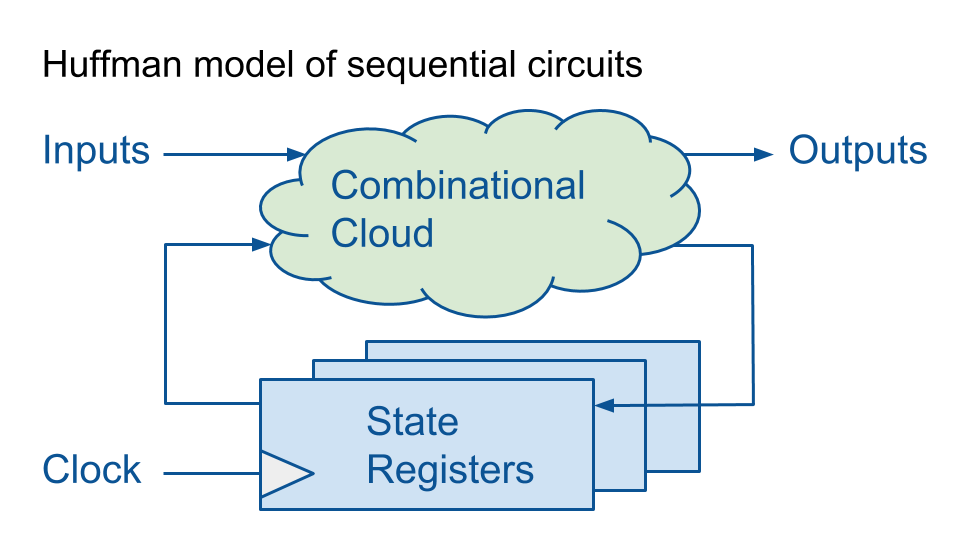
Модель Хаффмана — удобна для введения последовательностной логики. Комбинационная логика соединяется с регистрами — запоминающими элементами.
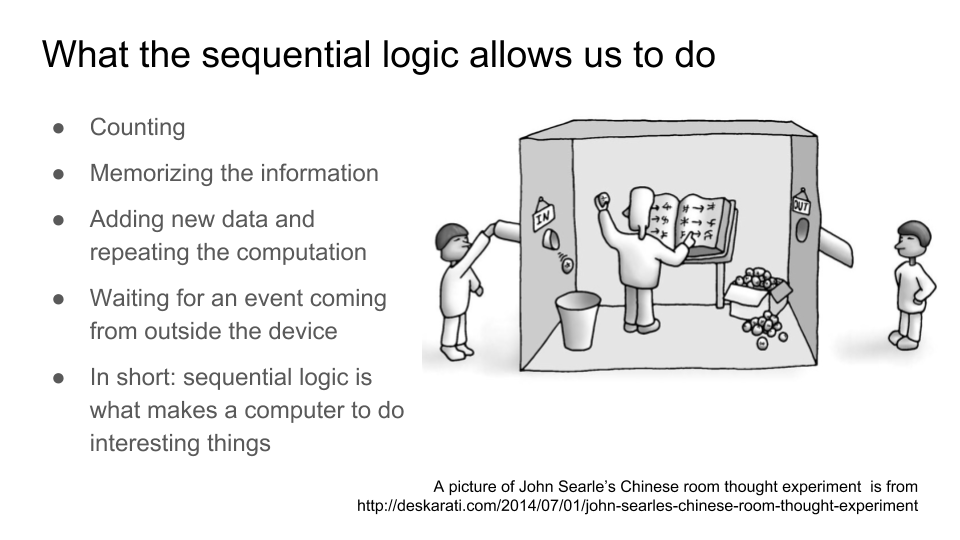
Последовательностная логика позволяет вычислительным устройствам делать нетривиальные вещи. Без нее, только на комбинационной логике, мы могли бы только вычислять таблицы функций, значения которых однозначно определяются из аргументами. Последовательностная логика добавляет к схеме текущее состояние, в результате чего мы может считать, ожидать события, повторять операции на основе старых и новых данных и т.д. Здесь я ссылаюсь на «китайскую комнату» — популярный парадокс, который всплывает при обсуждении темы «может ли машина мыслить?» Китайская комната — это по-сути одна из реализаций модели Хаффмана, обобщения конечного автомата:
Главная концепция, которую нужно понять в вводном курсе цифровой схемотехники — это функция D-триггера, базового элемента состояния. Если логические элементы И-ИЛИ-НЕ можно в принципе объяснить даже детям в детском саду, то с D-триггерами у школьников есть ментальный барьер. И не только у школьников, но и у программистов с опытом, которым мешает понять цифровую логику намертво вросшая в их мозг ментальная модель выполнения программ как цепочек инструкций. Вместо этого нужно использовать ментальную модель, в которой много событий просходит одновременно, например одновременная запись в тысячи или миллионы D-триггеров.
D-триггер — это устройство, которое хранит 1 бит информации в течение одного цикла тактового сигнала. У него есть три главных внешних сигнала — тактовый сигнал (clock, CLK), вход для записи (D) и выход для чтения (Q). На выходе Q выводится хранимое состояние D-триггера, а вход D в течении практически всего цикла D-триггер игнорирует. Вход D записывается в текущее состояние в течение короткого мига апертуры (aperture), когда синхронизирующий тактовый сигнал CLK меняется из нуля в единицу. К моменту апертуры, при правильно выбранной частоте тактового сигнала, на входе D-триггера находится устаканившийся результат вычислений комбинационной логики. А до этого момента на входе может находится всякий мусор, так как вычисления в аппаратуре не происходят мгновенно.
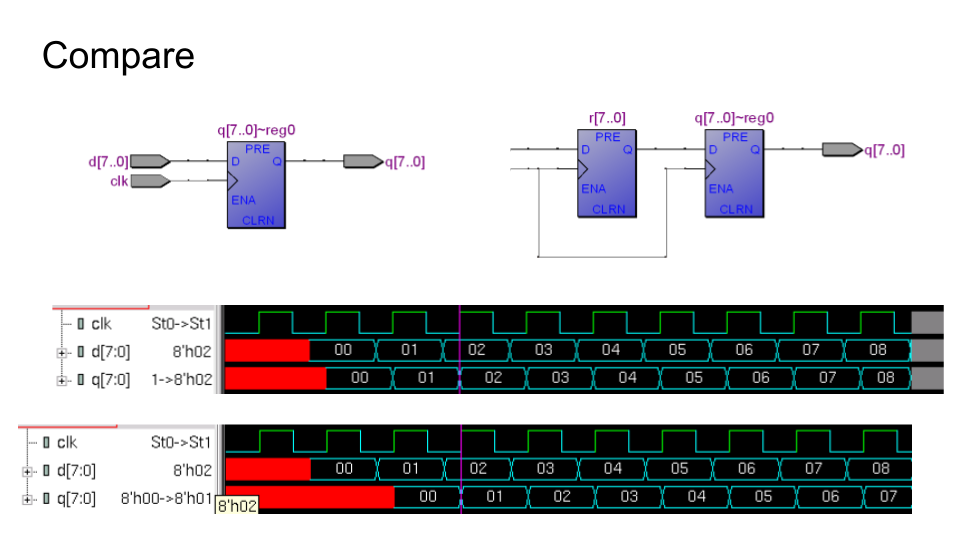
Из D-триггеров строятся регистры, хранилища для наборов в нескольких бит. На выходе регистра целый цикл находится значение, записанное в него в предыдущем цикле. Если поставить регистры один за другим, на выводе из этой комбинации будет значение из пред-предыдущего цикла:
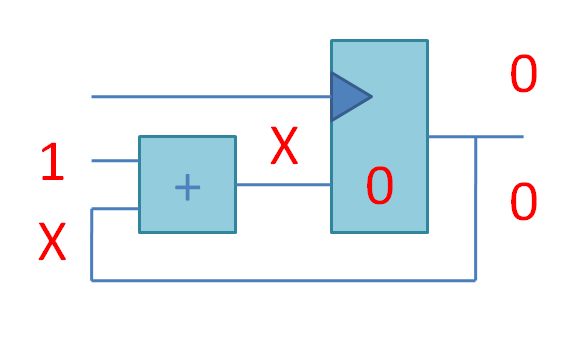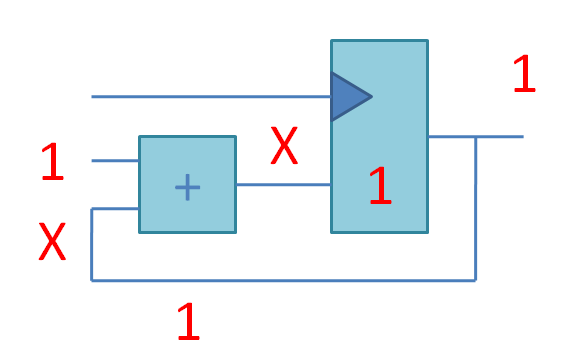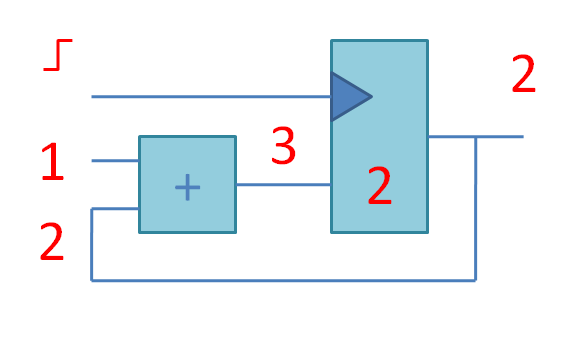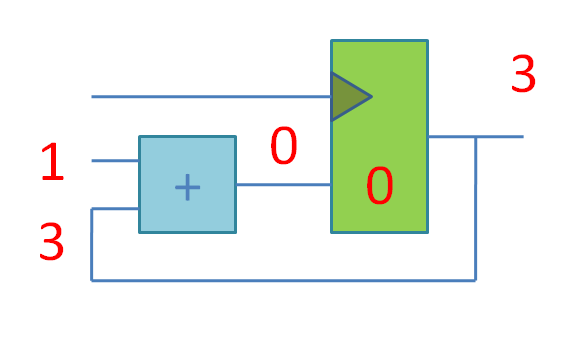
Если соединить комбинационный сумматор и регистр, то получится счетчик. На этой анимации X означает «неустаканившееся значение». Частота тактового сигнала подобрана так, чтобы запись в регистр происходила тогда, когда сложение с единицей гарантированно закончилось, и нужно записать сумму в регистр. Эта сумма будет использована как одно из слагаемых в следующем цикле:
Потом идут слайды про конечные автоматы, которые я сделал на основе книжки Цифровая схемотехника и архитектура компьютера. Дэвид М. Харрис, Сара Л. Харрис. А затем несколько слайдов про принцип конвейерной обработки.
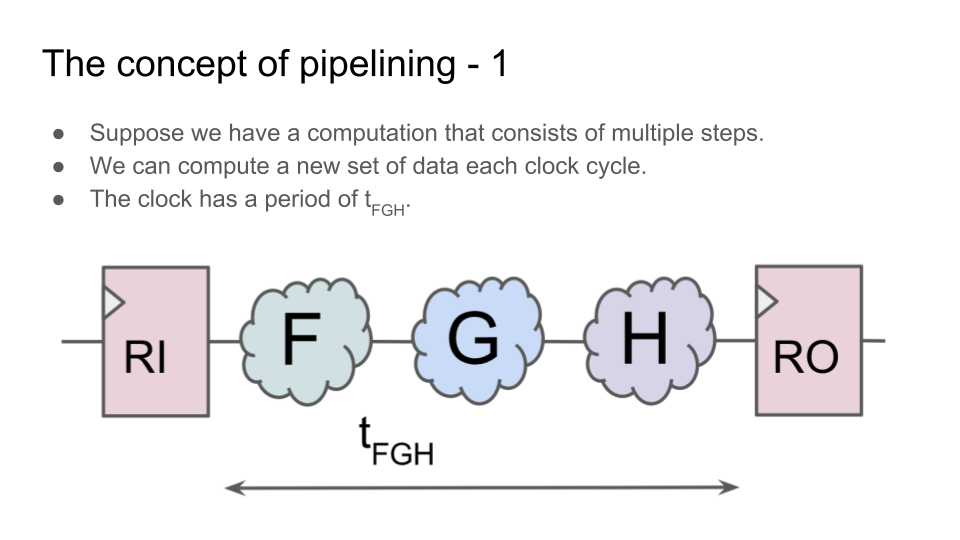
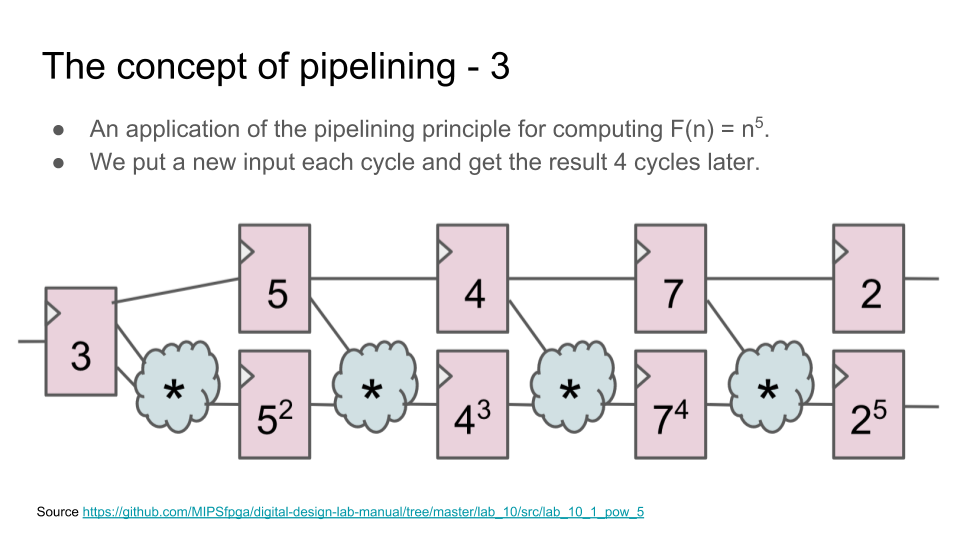
Конвейер — это одна из ключевых концепций современной разработки цифровой электроники. Конвейер возникает не только в дизайне процессора (execution pipe), но и в чем угодно: в дизайне арифметического блока, в блоке для транзакций к памяти, в обработке пакетов внутри роутерного чипа, и в шейдерах для трехмерной графики. Проще всего объяснить базовую идею конвейера на примере арифметического блока, например блока для возведения в степень.
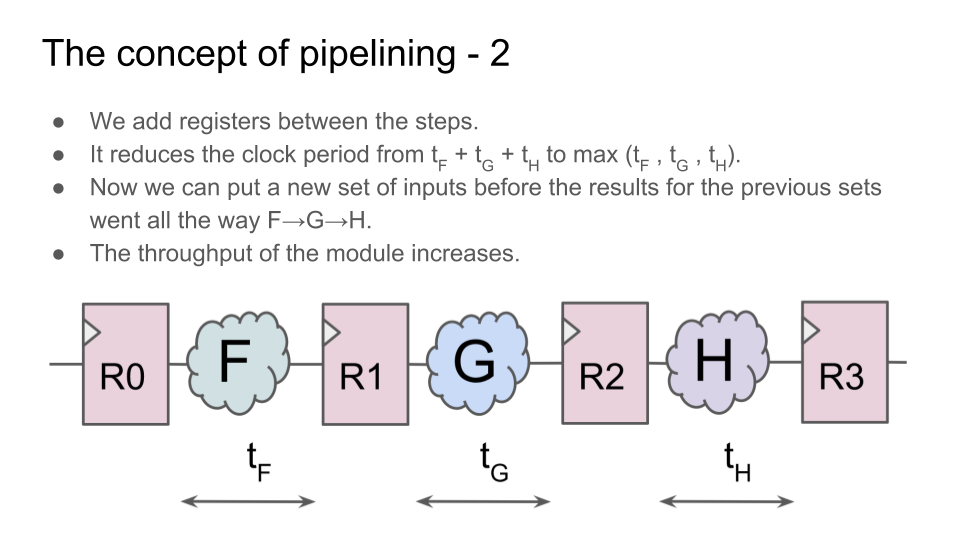
Возмем какую-нибудь операцию, которую можно разделить на несколько последовательных шагов. Теперь вместо того, чтобы выполнять все шаги за один цикл, поставим между шагами регистры. Хотя теперь операция выполняется не за один цикл, а за несколько, но:
1) схема может работать на более высокой тактовой частоте;
2) при этом операнды для нового вычисления можно подавать на вход сразу после первого цикла предыдущего вычисления, не дожидаясь окончания всех циклов предыдущего вычисления;
3) поэтому общая пропускная способность блока будет выше, чем у блока, в котором вычисления выполняются за один цикл:
Видео второй лекции:
Теперь о платах для лабораторных работ. Так как курс только ввели в порядке эксперимента, бюджета на FPGA платы в Иннополисе не выделили. Я одолжил Иннополису 10 плат, которые я купил на свои деньги, но плат катастрофически не хватает (на курсе 210 студентов). «Дайте больше плат!» — самый частый отзыв студентов на лабы с FPGA.
В принципе, преподавателям раздает платы Intel / Altera, реже Xilinx, но в небольшом количестве. Университеты покупают платы у Xilinx и Altera и на свои деньги, но довольно часто это связано с бюрократией и волокитой. Киевский Политехнический Институт в лице Евгения Короткого недавно купил FPGA платы на грант от киевского муниципалитета, для обучения FPGA школьников. Зеленоградское предприятие Элвис-НеоТек, московская компания НауТех, питерский Макро Груп и калифорнийский MIPS выделяли FPGA платы университетам для образовательных нужд (МГУ, МИЭТ, ИТМО, МЭИ, КПИ, и другие). Но для того, чтобы обновить все программы в центральных и региональных университетах и сделать понимание RTL частью общего образования в хайтеке (как это сделано в американских вузах и как это быстро делают китайцы в КНР), нужно на два порядка больше плат. Это с одной стороны проблема, но с другой стороны — возможность региональным компаниям и частным лицам занятся благотворительностью по отношению к своим местным университетам и физматшколам. Массовое владение этими технологиями может иметь далеко идущие последствия для России и других стран региона — примерно как введение информатики в советских школах в 1985 году привело к Яндексам и другим развитым российским софтверным компаниям в 21 веке.
Для базовых упражнений в разработке цифровой логики на уровне регистровых передач подходят практически любые платы (Xilinx, Altera, Lattice и т.д.) В Иннополисе мы сейчас используем плату Terasic DE10-Lite. Она недорогая и годится даже для синтеза небольших промышленных процессорных ядер (если вам хочется с этим поэкспериментировать — это следущий уровень):

Но если закупать платы сотнями в условиях нехватки денег, то одно из решений — брать платы с али экспресс с не самыми последними FPGA. Правда для некоторых из них прийдется использовать и не самую свежую версию софтвера для синтеза, но по большому счету это неважно. Также на них не самые удобные переключатели и их мало, но зато стоят в районе двадцати долларов (тысячи рублей). К платам c Intel / Altera FPGA нужен адаптер USB Blaster, и его лучше покупать отдельно — некоторые USB Blaster на AliExpress работают с последним софтвером Intel Quartus, версии 17.1, но другие совместимы только с версией 13.0sp1 2013 года.

Еще дешевле — покупать FPGA платы без периферийных устройств. Это может быть интересным для руководителей кружков школьников, особенно если у них есть завалы всяких сенсоров, дальномерок, светодиодных матриц, динамиков и других устройств, которые можно подключить к FPGA плате и сделать на ней привлекательные проекты. Для школьников может быть интересно сделать один и тот же проект сначала с микросхемами малой степени интеграции, потом с ПЛИС, потом с микроконтроллером.

Наконец, помимо Terasic, Digilent и других азиатских, американских и европейских производителей плат есть и российские: Марсоход и завод по изготовлению ПЛИС в Воронеже. На сайте Марсохода есть неплохие инструкции для образовательных проектов. Они могут развиться в один из центров российского коммьюнити в этой области. ПЛИС-ы из Воронежа дорогие, но если воронежский завод будет их раздавать университетам, то на них тоже можно делать все эти упражнения.

Зачем это нужно программистам? Ведь электронике учат на (гораздо менее массовых) факультетах электроники, где студент сначала изучает физику электричества, аналоговые схемы, делает пару лаб с мультиплексорами, после чего все это забывает и идет работать программистом.
Одна из причин, зачем цифровая схемотехника программисту — в последнее время происходит бум нейросетей. Если вы хотите чтобы обучение сложной сети занимало не недели / дни / часы, а часы / минуты / секунды, без аппаратных ускорителей не обойтись. Только специализированный хардвер выполнит параллельно большое количество умножений малой точности с одновременными транзакциями к океану памяти. В будущем нас ждут специализированные ASIC (application-specific integrated circuits) для AI, причем повсюду. В них будет как традиционный процессор, так и большие AI блоки на борту, с возможностью частичной реконфигурации.
От Гугла и Микрософта до Сколково и Иннополиса растет понимание, что нужны специалисты, которые могут строить такие сопроцессоры. Они должны владеть хардверной микроархитектурой, одновременно с пониманием софтверной экосистемы и алгоритмов. А владение микроархитектурой стоит на понимании уровня регистровых передач. Как это реализуется сейчас в Иннополисе:
Курс компьютерной архитектуры в Иннополисе разрабатывает его ректор Александр Тормасов, вместе с приглашенными им в Казань иностранными специалистами: итальянским профессором Giancarlo Succi, который работает в Иннополисе деканом, и Muhammad Fahim, который до Иннополиса работал в университетах Южной Кореи и Пакистана.
Сам ректор Тормасов до Иннополиса работал завкфедрой информатики МФТИ и возглавлял отдел перспективных разработок SWsoft (позже Parallels), где занимался виртуализацией. Paralells является одной из немногих российских компаний, широко известных в Америке — как минимум пара американских инженеров были удивлены, когда я сказал им, что Parallels является российской компанией, они думали что это американская компания. Кроме этого Тормасов возглавляет российское отделение IEEE Computer Society.
Тормасов любил вводить всякие новомодные штучки еще 30 лет назад — тогда он обучал студентов МФТИ использовать Unix, shell, awk итд. Линукса тогда еще не было, а Unix был на австралийских компьютерах Labtam с процессором National Semicondustor NS32000. До Тормасова студенты работали на БЭСМ-6 с Фортраном и перфокартами.
Итак, недавно Тормасов попросил меня прочитать по скайпу пару лекций про HDL, RTL и FPGA для его курса компьютерной архитектуры. На эти лекции у него ходит более 200 студентов, так что у эксперимента неплохая выборка. Лекции Тормасов попросил прочитать на английском, по-видимому потому что 1) в Иннополисе есть иностранные студенты 2) Giancarlo Succi и Muhammad Fahim тоже читают на английском и 3) студентам нужно тренировать comprehension, в том числе на мой тяжелый украинский акцент.
Целью первой лекции было дать студентам достаточно информации, чтобы они могли симулировать простейшую схему на программном симуляторе, а также синтезировать эту схему и сконфигурировать ею ПЛИС. Также нужно было наглядно показать, что схема — это не программа:
Слайды первой лекции в формате PDF.
Целью второй лекции было дать обзор того, что их ожидает, если они захотят копать тему цифровой логики глубже. Им нужно понять концепцию D-триггера, последовательностной логики, конечного автомата и конвейера. Тогда они смогут делать интересные схемы, которые повторяют действия, передают информацию с датчиков и т.д. — вплоть до процессорных ядер и дальше.
Слайды второй лекции в формате PDF.
Несколько ключевых слайдов. Разница между схемами и программами. Языки программирования (например Си) компилируются в цепочки инструкция, которые процессор выбирает з памяти. Языки описания аппаратуры (например Verilog) синтезируется в граф из логических элементов, которые в конечном итоге превращаются в транзисторы и дорожки на микросхеме, которая выпекается на фабрике:
Как работает ПЛИС / FPGA — матрица из логических элементов, функцию которых можно менять с помощью мультиплексоров, подсоединенных к битам конфигурационной памяти:
Простейшая схема. Комбинационная логика — кладем на вход некие данные, через некоторое время (с задержкой распространения) получаем на выходе ответ.
Модель Хаффмана — удобна для введения последовательностной логики. Комбинационная логика соединяется с регистрами — запоминающими элементами.
Последовательностная логика позволяет вычислительным устройствам делать нетривиальные вещи. Без нее, только на комбинационной логике, мы могли бы только вычислять таблицы функций, значения которых однозначно определяются из аргументами. Последовательностная логика добавляет к схеме текущее состояние, в результате чего мы может считать, ожидать события, повторять операции на основе старых и новых данных и т.д. Здесь я ссылаюсь на «китайскую комнату» — популярный парадокс, который всплывает при обсуждении темы «может ли машина мыслить?» Китайская комната — это по-сути одна из реализаций модели Хаффмана, обобщения конечного автомата:
Главная концепция, которую нужно понять в вводном курсе цифровой схемотехники — это функция D-триггера, базового элемента состояния. Если логические элементы И-ИЛИ-НЕ можно в принципе объяснить даже детям в детском саду, то с D-триггерами у школьников есть ментальный барьер. И не только у школьников, но и у программистов с опытом, которым мешает понять цифровую логику намертво вросшая в их мозг ментальная модель выполнения программ как цепочек инструкций. Вместо этого нужно использовать ментальную модель, в которой много событий просходит одновременно, например одновременная запись в тысячи или миллионы D-триггеров.
D-триггер — это устройство, которое хранит 1 бит информации в течение одного цикла тактового сигнала. У него есть три главных внешних сигнала — тактовый сигнал (clock, CLK), вход для записи (D) и выход для чтения (Q). На выходе Q выводится хранимое состояние D-триггера, а вход D в течении практически всего цикла D-триггер игнорирует. Вход D записывается в текущее состояние в течение короткого мига апертуры (aperture), когда синхронизирующий тактовый сигнал CLK меняется из нуля в единицу. К моменту апертуры, при правильно выбранной частоте тактового сигнала, на входе D-триггера находится устаканившийся результат вычислений комбинационной логики. А до этого момента на входе может находится всякий мусор, так как вычисления в аппаратуре не происходят мгновенно.
Из D-триггеров строятся регистры, хранилища для наборов в нескольких бит. На выходе регистра целый цикл находится значение, записанное в него в предыдущем цикле. Если поставить регистры один за другим, на выводе из этой комбинации будет значение из пред-предыдущего цикла:
Если соединить комбинационный сумматор и регистр, то получится счетчик. На этой анимации X означает «неустаканившееся значение». Частота тактового сигнала подобрана так, чтобы запись в регистр происходила тогда, когда сложение с единицей гарантированно закончилось, и нужно записать сумму в регистр. Эта сумма будет использована как одно из слагаемых в следующем цикле:
Потом идут слайды про конечные автоматы, которые я сделал на основе книжки Цифровая схемотехника и архитектура компьютера. Дэвид М. Харрис, Сара Л. Харрис. А затем несколько слайдов про принцип конвейерной обработки.
Конвейер — это одна из ключевых концепций современной разработки цифровой электроники. Конвейер возникает не только в дизайне процессора (execution pipe), но и в чем угодно: в дизайне арифметического блока, в блоке для транзакций к памяти, в обработке пакетов внутри роутерного чипа, и в шейдерах для трехмерной графики. Проще всего объяснить базовую идею конвейера на примере арифметического блока, например блока для возведения в степень.
Возмем какую-нибудь операцию, которую можно разделить на несколько последовательных шагов. Теперь вместо того, чтобы выполнять все шаги за один цикл, поставим между шагами регистры. Хотя теперь операция выполняется не за один цикл, а за несколько, но:
1) схема может работать на более высокой тактовой частоте;
2) при этом операнды для нового вычисления можно подавать на вход сразу после первого цикла предыдущего вычисления, не дожидаясь окончания всех циклов предыдущего вычисления;
3) поэтому общая пропускная способность блока будет выше, чем у блока, в котором вычисления выполняются за один цикл:
Видео второй лекции:
Теперь о платах для лабораторных работ. Так как курс только ввели в порядке эксперимента, бюджета на FPGA платы в Иннополисе не выделили. Я одолжил Иннополису 10 плат, которые я купил на свои деньги, но плат катастрофически не хватает (на курсе 210 студентов). «Дайте больше плат!» — самый частый отзыв студентов на лабы с FPGA.
В принципе, преподавателям раздает платы Intel / Altera, реже Xilinx, но в небольшом количестве. Университеты покупают платы у Xilinx и Altera и на свои деньги, но довольно часто это связано с бюрократией и волокитой. Киевский Политехнический Институт в лице Евгения Короткого недавно купил FPGA платы на грант от киевского муниципалитета, для обучения FPGA школьников. Зеленоградское предприятие Элвис-НеоТек, московская компания НауТех, питерский Макро Груп и калифорнийский MIPS выделяли FPGA платы университетам для образовательных нужд (МГУ, МИЭТ, ИТМО, МЭИ, КПИ, и другие). Но для того, чтобы обновить все программы в центральных и региональных университетах и сделать понимание RTL частью общего образования в хайтеке (как это сделано в американских вузах и как это быстро делают китайцы в КНР), нужно на два порядка больше плат. Это с одной стороны проблема, но с другой стороны — возможность региональным компаниям и частным лицам занятся благотворительностью по отношению к своим местным университетам и физматшколам. Массовое владение этими технологиями может иметь далеко идущие последствия для России и других стран региона — примерно как введение информатики в советских школах в 1985 году привело к Яндексам и другим развитым российским софтверным компаниям в 21 веке.
Для базовых упражнений в разработке цифровой логики на уровне регистровых передач подходят практически любые платы (Xilinx, Altera, Lattice и т.д.) В Иннополисе мы сейчас используем плату Terasic DE10-Lite. Она недорогая и годится даже для синтеза небольших промышленных процессорных ядер (если вам хочется с этим поэкспериментировать — это следущий уровень):
Но если закупать платы сотнями в условиях нехватки денег, то одно из решений — брать платы с али экспресс с не самыми последними FPGA. Правда для некоторых из них прийдется использовать и не самую свежую версию софтвера для синтеза, но по большому счету это неважно. Также на них не самые удобные переключатели и их мало, но зато стоят в районе двадцати долларов (тысячи рублей). К платам c Intel / Altera FPGA нужен адаптер USB Blaster, и его лучше покупать отдельно — некоторые USB Blaster на AliExpress работают с последним софтвером Intel Quartus, версии 17.1, но другие совместимы только с версией 13.0sp1 2013 года.
Еще дешевле — покупать FPGA платы без периферийных устройств. Это может быть интересным для руководителей кружков школьников, особенно если у них есть завалы всяких сенсоров, дальномерок, светодиодных матриц, динамиков и других устройств, которые можно подключить к FPGA плате и сделать на ней привлекательные проекты. Для школьников может быть интересно сделать один и тот же проект сначала с микросхемами малой степени интеграции, потом с ПЛИС, потом с микроконтроллером.
Наконец, помимо Terasic, Digilent и других азиатских, американских и европейских производителей плат есть и российские: Марсоход и завод по изготовлению ПЛИС в Воронеже. На сайте Марсохода есть неплохие инструкции для образовательных проектов. Они могут развиться в один из центров российского коммьюнити в этой области. ПЛИС-ы из Воронежа дорогие, но если воронежский завод будет их раздавать университетам, то на них тоже можно делать все эти упражнения.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Для чего вам интересно использовать навыки проектирования на уровне регистровых передач?
76.71%Проектирование сопроцессоров для AI56
27.4%Проектирование интегрированных чипов для интернета вещей20
17.81%Проектирование сетевых чипов для роутеров и инфраструктуры интернета13
28.77%Проектирование графических процессоров для ускорения трехмерной графики21
45.21%Проектирование микропроцессорных ядер и многоядерных кластеров33
30.14%Написание программ для автоматизации проектирования на уровне регистровых передач22
Проголосовали 73 пользователя. Воздержались 25 пользователей.

