
В начале этого года я присоединилась к команде, работающей над MongoDB Compass — графическим интерфейсом для MongoDB. Пользователи Compass через Intercom запросили инструмент, позволяющий писать запросы к базе данных, используя любой удобный им язык программирования, поддерживаемый драйвером MongoDB. То есть нам нужна была возможность трансформировать (компилировать) язык Mongo Shell в другие языки и обратно.
Данная статья может стать как практическим руководством, помогающим при написании компилятора на JavaScript, так и теоретическим ресурсом, включающим основные понятия и принципы создания компиляторов. В конце приведен не только полный список всех используемых при написании материалов, а также ссылки на дополнительную литературу, направленную на более глубокое изучение вопроса. Информация в статье подается последовательно, начиная с исследования предметной области и далее постепенно усложняя функционал разрабатываемого в качестве примера приложения. Если во время прочтения вам кажется, что вы не улавливаете переход от одного шага к другому, вы можете обратиться к полной версии данной программы и возможно это поможет устранить возникший пробел.
Содержание
- Терминология
- Исследование
- Создание компилятора
- Установка ANTLR
- Создание проекта на Node.js с использованием ANTLR
- Анализ исходного кода и построение синтаксического дерева
- Генерация кода
- Обработка ошибок
- Заключение
Терминология
Компилятор (Compiler) преобразует исходную программу на языке программирования высокого уровня, в эквивалентную программу на другом языке, которая может быть выполнена без участия компилятора.
Лексер (Lexer) — Элемент компилятора, выполняющий лексический анализ.
Лексический анализ (Tokenizing) — Процесс аналитического разбора входной последовательности символов на распознанные группы (лексемы, токены).
Парсер (Parser) — Элемент компилятора, выполняющий синтаксический анализ, результатом которого является дерево разбора.
Синтаксический анализ (Parsing) — Процесс сопоставления линейной последовательности лексем естественного или формального языка с его формальной грамматикой.
Лексема или токен (Lexeme or Token) — Последовательность допустимых символов языка программирования, имеющая смысл для компилятора.
Посетитель (Visitor) — Паттерн работы с деревом, при котором для продолжения обработки потомков необходимо вручную вызывать методы их обхода.
Слушатель (Listener or Walker) — Паттерн работы с деревом, когда методы посещения всех потомков вызываются автоматически. В Listener существует метод, вызываемый в начале посещения узла (enterNode) и метод, вызываемый после посещения узла (exitNode).
Дерево разбора или синтаксическое дерево (Parse Tree) — Структура, представляющая собой результат работы синтаксического анализатора. Она отражает синтаксис конструкций входного языка и явно содержит в себе полную взаимосвязь операций.
Абстрактное синтаксическое дерево (AST — Abstract Syntax Tree) отличается от дерева разбора тем, что в нём отсутствуют узлы и рёбра для тех синтаксических правил, которые не влияют на семантику программы.
Универсальное абстрактное синтаксическое дерево (UAST — Universal Abstract Syntax Tree) нормализованная форма AST с независимыми от языка аннотациями.
Обход дерева в глубину (DFS — Depth-first search) — Один из методов обхода графа. Стратегия поиска в глубину, как и следует из названия, состоит в том, чтобы идти «вглубь» графа, насколько это возможно.
Грамматика (Grammar) — Набор инструкций для построения лексического и синтаксического анализаторов.
Корневой узел (Root) — Самый верхний узел дерева, с которого начинается обход. Это единственный узел дерева, не имеющий предка, однако сам являющийся предком для всех остальных узлов дерева.
Лист, листовой или терминальный узел (Leaf) — Узел, не имеющий потомков.
Родитель (Parent) — Узел, имеющий потомка. Каждый узел дерева имеет ноль или более узлов-потомков.
Литерал (Literal) — Представление некоторого фиксированного значения или типа данных.
Генератор кода (Code generator) получает в качестве входных данных промежуточное представление исходной программы и трансформирует его в целевой язык.
Исследование
Можно рассмотреть три пути решения проблемы трансформации одного языка программирования в другой (Source-to-source transformation):
- Использовать существующие парсеры для конкретных языков программирования.
- Создать собственный парсер.
- Использовать инструмент или библиотеку для генерации парсеров.
Первый вариант хорош, однако покрывает только самые известные и поддерживаемые языки. Для JavaScript существуют такие парсеры, как Esprima, Falafel, UglifyJS, Jison и другие. Прежде чем писать что-то самому, стоит изучить уже имеющиеся инструменты, возможно, они полностью покрывают нужный вам функционал.
Если вам не повезло, и вы не нашли парсер для своего языка или найденный парсер не удовлетворяет всем вашим потребностям, вы можете прибегнуть ко второй опции и написать его сами.
Хорошим стартом для понимания написания компилятора с нуля может стать Super Tiny Compiler. Если убрать из файла комментарии, то останется лишь 200 строк кода, которые вмещают в себя все основные принципы современного компилятора.
Автор статьи Implementing a Simple Compiler on 25 Lines of JavaScript делится своим опытом создания компилятора на JavaScript. И охватывает такие концепции как лексический анализ, синтаксический анализ и генерация кода.
How to write a simple interpreter in JavaScript еще один ресурс, который рассматривает процесс создания интерпретатора на примере простого калькулятора.
Написание компилятора с нуля — трудоемкий процесс, требующий глубокого предварительного изучения синтаксических особенностей компилируемых языков. При этом нужно распознавать не только ключевые слова, а также их положение относительно друг друга. Правила анализа исходного кода должны быть однозначными и давать на выходе идентичный результат, при одинаковых начальных условиях.
С этим могут помочь инструменты и библиотеки для генерации парсеров. Они берут сырой исходный код, разбивают его на токены (лексический анализ), затем сопоставляет линейные последовательности токенов их формальной грамматике (синтаксический анализ) и помещают их в древовидную организованную структуру, согласно которой может быть построен новый код. Про некоторые из них рассказывается в статье Parsing in JavaScript: Tools and Libraries.

На первый взгляд может показаться, что решение проблемы у нас в кармане, однако, чтобы научить парсер распознавать исходный код, нам придется потратить еще множество человеко-часов на написание инструкций (грамматик). А в случае, если компилятор должен поддерживать несколько языков программирования, эта задача заметно усложняется.
Совершенно очевидно, что мы не первые разработчики, столкнувшиеся с подобной задачей. Работа любого IDE связана с анализом кода, Babel трансформирует современный JavaScript в стандарт поддерживаемый всеми браузерами. Это значит, что должны существовать грамматики, которые мы могли бы переиспользовать и тем самым не только облегчить себе задачу, а также избежать ряд потенциально серьезных ошибок и неточностей.
Таким образом, наш выбор пал на ANTLR, который лучше всего подходит под наши требования, так как содержит грамматики практически для всех языков программирования.
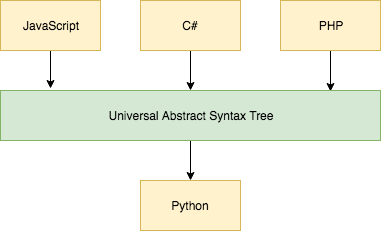
Как альтернативу можно рассмотреть Babelfish, который анализирует любой файл на любом поддерживаемом языке, извлекает из него AST и преобразовывает его в UAST, в котором узлы не привязаны к синтаксису исходного языка. На входе мы можем иметь JavaScript или C#, но на уровне UAST мы не увидим никаких различий. В терминологии компиляторов за процесс приведения AST к универсальному типу отвечает процесс трансформации.
Начинающего автора компилятора может также заинтересовать Astexplorer, интерфейс позволяющий увидеть, каким может быть синтаксическое дерево для заданного фрагмента кода и соответствующего выбранному языку парсеру. Может пригодиться для дебага или формирования общего представления о структуре AST.
Создание компилятора
ANTLR (Another Tool For Language Recognition — еще один инструмент для распознавания языков) — генератор парсеров написанный на Java. На вход он принимает фрагмент текста, затем анализирует его на основе грамматик и преобразует в организованную структуру, которая в свою очередь может быть использована для создания абстрактного синтаксического дерева. ANTLR 3 брал на себя и эту задачу — генерировал AST. Однако ANTLR 4 исключил этот функционал в пользу использования StringTemplates и оперирует только таким понятием как “дерево разбора” (Parse Tree).
За дополнительной информаций можно обратиться к документации, или прочитать отличную статью The ANTLR Mega Tutorial, в которой объясняется, что такое парсер, зачем он нужен, как настроить ANTLR, полезные функции ANTLR и многое другое с тонной примеров.
Более подробно про создание грамматик можно почитать здесь:
Для трансформации одного языка программирования в другой мы решили использовать ANTLR 4 и одну из его грамматик, а именно ECMAScript.g4. Мы выбрали JavaScript потому, что его синтаксис соответствует языку Mongo Shell а также является языком разработки Compass приложения. Интересный факт: мы можем строить дерево разбора, используя Lexer и Parser C#, но обходить его по узлам грамматики ECMAScript.
Этот вопрос требует более детального исследования. С полной уверенностью можно сказать, что не любая структура кода будет верно распознана по умолчанию. Нужно будет расширять функционал обхода новыми методами и проверками. Однако уже сейчас очевидно, что ANTLR отличный инструмент, когда речь идет о поддержке нескольких парсеров в рамках одного приложения.
ANTLR создает для нас перечень вспомогательных файлов для работы с деревьями. Содержимое этих файлов непосредственно зависит от правил, указанных в грамматике. Поэтому, при любых изменения грамматики, эти файлы должны быть сгенерированы заново. Это значит, что мы не должны использовать их напрямую для написания кода, иначе мы потеряем наши изменения при следующей итерации. Мы должны создавать свои классы и наследовать их от классов, производимых ANTLR.
Сгенерированный в результате работы ANTLR код помогает при создании дерева разбора, которое в свою очередь является основополагающим средством формирования нового кода. Суть заключается в вызове дочерних узлов слева направо (при условии, что это порядок исходного текста), чтобы вернуть отформатированный текст, который они представляют.
Если узел является литералом, нам нужно вернуть его фактическое значение. Это сложнее, чем кажется, если вы хотите, чтобы результат был точным. В этом случае вы должны предусмотреть возможность вывода чисел с плавающей точкой без потери точности, а также чисел в различных системах счисления. Для строковых литералов стоит обдумать, какой тип кавычек вы поддерживаете, а также не забыть об escape-последовательностях символов, которые должны быть экранированы. Поддерживаете ли вы комментарии кода? Хотите ли вы сохранять формат пользовательского ввода (пробелы, пустые строки), либо же вы хотите приводить текст к более стандартному легче читаемому виду. С одной стороны, второй вариант будет выглядеть более профессионально, с другой — пользователь вашего компилятора может быть в итоге не доволен, так как он, вероятно, хочет получить на выходе идентичный его вводу формат. Для этих проблем нет универсального решения, и они требует более детального изучения области применения вашего компилятора.
Мы же рассмотрим более упрощенный пример, чтобы сконцентрироваться на основах написания компилятора с использованием ANTLR.
Установка ANTLR
$ brew cask install java $ cd /usr/local/lib $ curl -O http://www.antlr.org/download/antlr-4.7.1-complete.jar $ export CLASSPATH=".:/usr/local/lib/antlr-4.7.1-complete.jar:$CLASSPATH" $ alias antlr4='java -Xmx500M -cp "/usr/local/lib/antlr-4.7.1-complete.jar:$CLASSPATH" org.antlr.v4.Tool' $ alias grun='java org.antlr.v4.gui.TestRig'
Чтобы убедиться, что все ваши установки прошли успешно, наберите в терминале:
$ java org.antlr.v4.Tool
Вам должна отобразиться информация о версии ANTLR, а также help по командам.

Создание проекта на Node.js с использованием ANTLR
$ mkdir js-runtime $ cd js-runtime $ npm init
Установим JavaScript runtime, для этого нам потребуется npm пакет antlr4 — JavaScript target for ANTLR 4.
$ npm i antlr4 --save
Скачаем ECMAScript.g4 грамматику, которую скормим в дальнейшем нашему ANTLR.
$ mkdir grammars $ curl --http1.1 https://github.com/antlr/grammars-v4/blob/master/ecmascript/ECMAScript.g4 --output grammars/ECMAScript.g4
Кстати, на сайте ANTLR в разделе Development Tools можно найти ссылки на плагины для таких IDE как Intellij, NetBeans, Eclipse, Visual Studio Code, and jEdit. Цветовые темы, проверка семантических ошибок, визуализация с помощью диаграмм облегчают написание и тестирование грамматик.
Наконец, запустим ANTLR.
$ java -Xmx500M -cp '/usr/local/lib/antlr-4.7.1-complete.jar:$CLASSPATH' org.antlr.v4.Tool -Dlanguage=JavaScript -lib grammars -o lib -visitor -Xexact-output-dir grammars/ECMAScript.g4
Добавим этот скрипт в package.json, чтобы всегда иметь к нему доступ. При любом изменении файла грамматики, нам нужно перезапускать ANTLR, чтобы применить внесенные изменения.
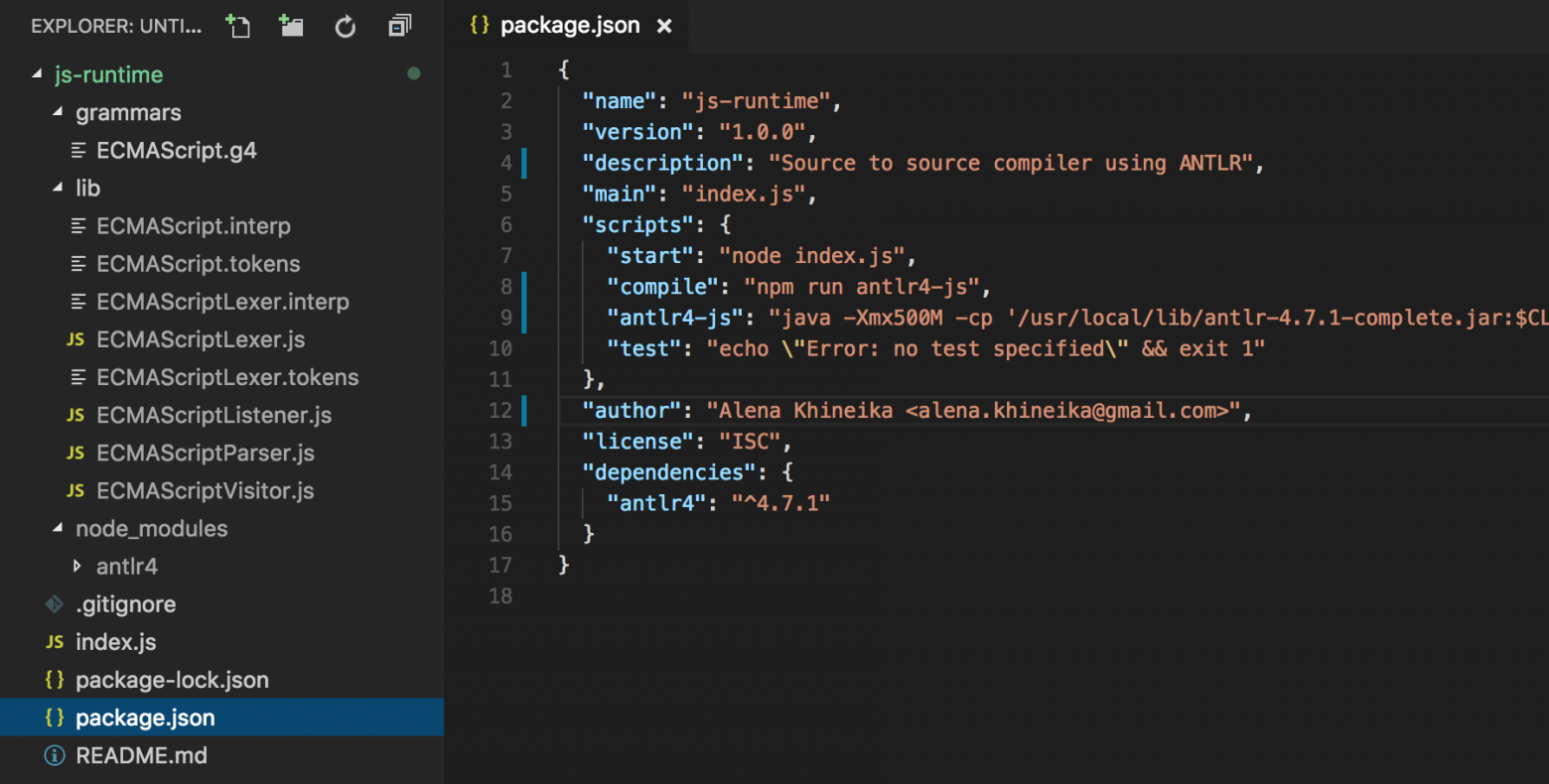
Идем в папку lib и видим, что ANTLR создал для нас перечень файлов. Давайте остановимся более подробно на трех из них:
- ECMAScriptLexer.js разбивает поток символов исходного кода на поток токенов в соответствии с правилами, указанными в грамматике.
- ECMAScriptParser.js из потока токенов строит абстрактную связную древовидную структуру, называемую деревом разбора.
- ECMAScriptVisitor.js отвечает за обход построенного дерева. Теоретически, мы могли бы самостоятельно обработать данное дерево с помощью рекурсивного обхода потомков в глубину. Однако при большом количестве типов узлов и сложной логике их обработки, лучше посещать каждый тип узла своим уникальным методом, как это делает визитор.
Обратите внимание, что по умолчанию ANTLR не создает *Visitor.js. Стандартным способом обхода деревьев в ANTLR занимается Listener. Если вы хотите сгенерировать и затем использовать Visitor вместо Listener, вам нужно явно это указать с помощью флага ‘
-visitor’, как мы это сделали в нашем скрипте:$ java -Xmx500M -cp '/usr/local/lib/antlr-4.7.1-complete.jar:$CLASSPATH' org.antlr.v4.Tool -Dlanguage=JavaScript -lib grammars -o lib -visitor -Xexact-output-dir grammars/ECMAScript.g4
Суть работы обоих методов, впрочем как и результат, весьма схожи, однако с Visitor ваш код выглядит более чистым и у вас появляется больше контроля над процессом трансформации. Вы можете устанавливать в каком порядке посещать узлы дерева и посещать ли их вообще. Также вы можете изменять существующие узлы во время обхода и вам не нужно хранить информацию о посещенных узлах. В статье Antlr4 — Visitor vs Listener Pattern эта тема рассмотрена более подробно и на примерах.
Анализ исходного кода и построение синтаксического дерева
Давайте же наконец приступим к программированию. Пример похожего кода вы найдете буквально везде если будете искать по сочетанию ANTLR и JavaScript.
const antlr4 = require('antlr4'); const ECMAScriptLexer = require('./lib/ECMAScriptLexer.js'); const ECMAScriptParser = require('./lib/ECMAScriptParser.js'); const input = '{x: 1}'; const chars = new antlr4.InputStream(input); const lexer = new ECMAScriptLexer.ECMAScriptLexer(chars); lexer.strictMode = false; // не использовать JavaScript strictMode const tokens = new antlr4.CommonTokenStream(lexer); const parser = new ECMAScriptParser.ECMAScriptParser(tokens); const tree = parser.program(); console.log(tree.toStringTree(parser.ruleNames));
Что мы сейчас сделали: используя лексер и парсер, которые сгенерировал для нас ANTLR, мы привели нашу исходную строку к виду дерева в формате LISP (это стандартный формат вывода деревьев в ANTLR 4). Согласно грамматике, корневым узлом ECMAScript дерева является правило `
program`, поэтому его мы выбрали в качестве стартовой точки обхода в нашем примере. Однако это не значит, что этот узел всегда должен быть первым. Для исходной строки `{x: 1}` совершенно справедливо было бы начать обход с `expressionSequence`.const tree = parser.expressionSequence();

Если вы уберете форматирование `
.toStringTree()`, то сможете увидеть внутреннюю структуру объекта дерева.Условно весь процесс трансформации одного языка программирования в другой можно разделить на три этапа:
- Анализ исходного кода.
- Построение синтаксического дерева.
- Генерация нового кода.
Как мы видим, благодаря ANTLR мы значительно упростили себе работу и несколькими строками кода охватили целых два этапа. Конечно, мы будем к ним еще возвращаться, обновлять грамматики, трансформировать дерево, но тем не менее хорошая основа уже заложена. Грамматики, которые скачиваются из репозитория, также могут быть неполноценными или даже с ошибками. Но, возможно, в них уже исправлены те ошибки, которые вы бы еще только допустили, если бы начинали писать грамматику с нуля самостоятельно. Смысл такой, не стоит слепо верить коду, написанному другими разработчиками, но можно сэкономить время написания идентичных правил на усовершенствование уже существующих. Возможно следующее поколение молодых ANTLR-вцев скачает уже вашу более идеальную версию грамматики.
Генерация кода
Создадим в проекте новую директорию `
codegeneration` и в ней новый файл PythonGenerator.js.$ mkdir codegeneration $ cd codegeneration $ touch PythonGenerator.js
Как вы уже догадались, в качестве примера, мы трансформируем что-нибудь из JavaScript в Python.
Сгенерированный ECMAScriptVisitor.js файл содержит огромный перечень методов, каждый из которых автоматически вызывается во время обхода дерева, если посещается соответствующий узел. И именно в этот момент мы можем изменить текущий узел. Для этого создадим класс, который будет наследоваться от ECMAScriptVisitor и переопределять нужные нам методы.
const ECMAScriptVisitor = require('../lib/ECMAScriptVisitor').ECMAScriptVisitor; /** * Visitor проходит по дереву, сгенерированному ANTLR * с целью трансформировать JavaScript код в Python код * * @returns {object} */ class Visitor extends ECMAScriptVisitor { /** * Начальная точка обхода дерева * * @param {object} ctx * @returns {string} */ start(ctx) { return this.visitExpressionSequence(ctx); } } module.exports = Visitor;
Кроме методов, соответствующих синтаксическим правилам грамматики, ANTLR также поддерживает четыре специальных паблик метода:
- visit() отвечает за обход дерева.
- visitChildren() отвечает за обход узлов.
- visitTerminal() отвечает за обход токенов.
- visitErrorNode() отвечает за обход некорректных токенов.
Реализуем в нашем классе методы `
visitChildren()`, `visitTerminal()` а также `visitPropertyExpressionAssignment()`./* * Посещает потомков текущего узла * * @param {object} ctx * @returns {string} */ visitChildren(ctx) { let code = ''; for (let i = 0; i < ctx.getChildCount(); i++) { code += this.visit(ctx.getChild(i)); } return code.trim(); } /** * Посещает лист дерева (узел без потомков) и возвращает строку * * @param {object} ctx * @returns {string} */ visitTerminal(ctx) { return ctx.getText(); } /** * Посещает узел, отвечающий за присваивание значения параметру * * @param {object} ctx * @returns {string} */ visitPropertyExpressionAssignment(ctx) { const key = this.visit(ctx.propertyName()); const value = this.visit(ctx.singleExpression()); return `'${key}': ${value}`; }
Функция `
visitPropertyExpressionAssignment` посещает узел, отвечающий за присваивание значения `1` параметру `x`. В Python строковые параметры объекта должны быть заключены в кавычки, в отличие от JavaScript, где они опциональны. В данном случае это единственная модификация, которая требуется для трансформации фрагмента JavaScript кода в Python код.
Добавим в index.js вызов нашего PythonGenerator.
console.log('JavaScript input:'); console.log(input); console.log('Python output:'); const output = new PythonGenerator().start(tree); console.log(output);
В результате выполнения программы мы видим, что наш компилятор успешно справился со своей задачей и преобразовал JavaScript объект в Python объект.

Мы начинаем обход дерева от родителя к потомку, постепенно спускаясь к его листам. А затем идем в обратном порядке и подставляем отформатированные значения на уровень выше, таким образом заменяя всю цепочку узлов дерева на их текстовое представление, соответствующее синтаксису нового языка программирования.
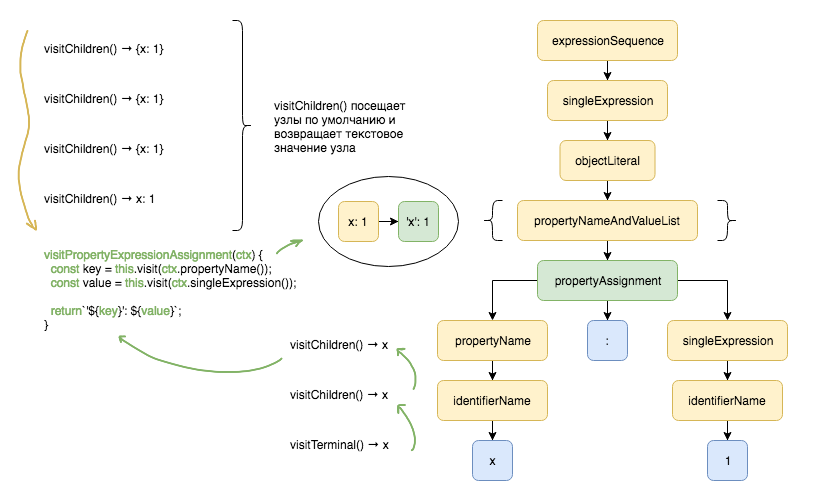
Добавим немного дебага в нашу `
visitPropertyExpressionAssignment` функцию.// Текстовое значение узла console.log(ctx.getText()); // Кол-во узлов потомков console.log(ctx.getChildCount()); // console.log(ctx.propertyName().getText()) Параметр x console.log(ctx.getChild(0).getText()); // : console.log(ctx.getChild(1).getText()); // console.log(ctx.singleExpression().getText()) Значение 1 console.log(ctx.getChild(2).getText());
К потомкам можно обращаться как по имени, так и по порядковому номеру. Потомки также являются узлами, поэтому, чтобы получить их текстовое значение, а не объектное представление, мы использовали метод `
.getText()`.Дополним ECMAScript.g4 и научим наш компилятор распознавать ключевое слово `
Number`.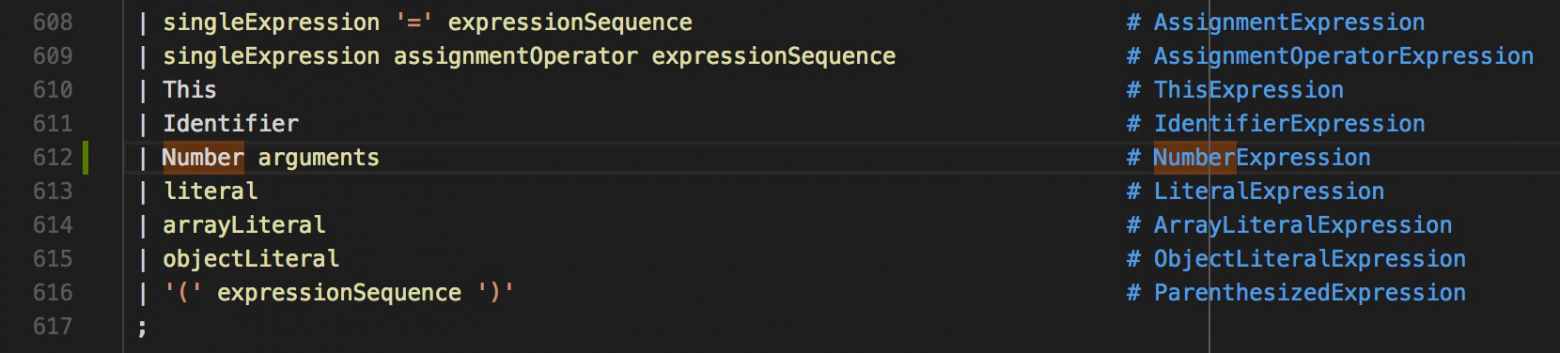
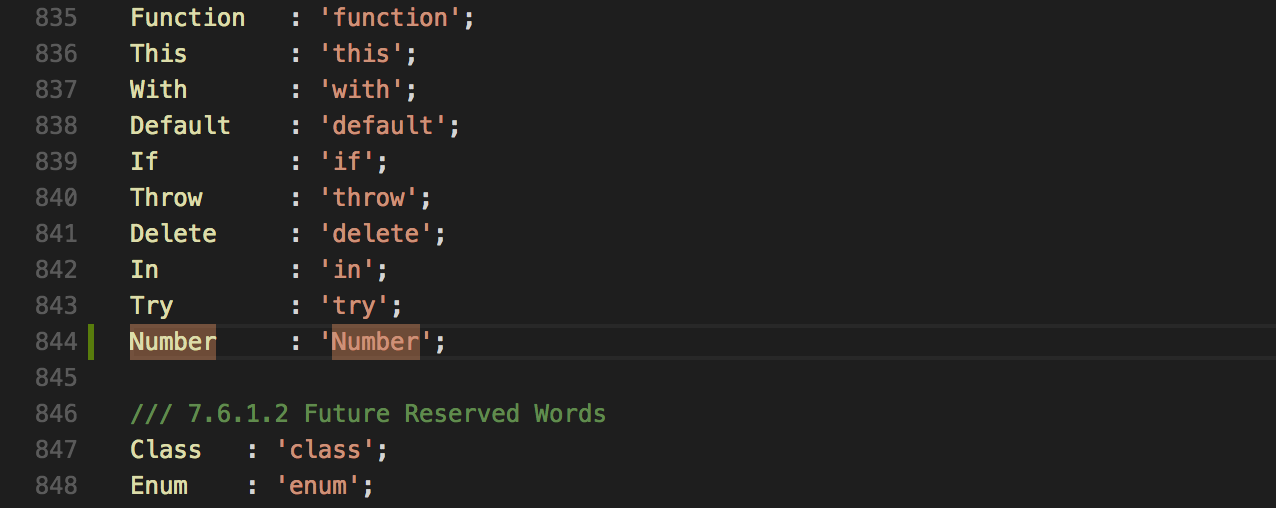
Перегенерируем визитор, чтобы подтянуть изменения, сделанные в грамматике.
$ npm run compile
Теперь вернемся к нашему файлу PythonGenerator.js и добавим в него перечень новых методов.
/** * Удаляет ключевое слово `new` * * @param {object} ctx * @returns {string} */ visitNewExpression(ctx) { return this.visit(ctx.singleExpression()); } /** * Посещает узел с ключевым словом `Number` * * @param {object} ctx * @returns {string} */ visitNumberExpression(ctx) { const argumentList = ctx.arguments().argumentList(); // JavaScript Number требует один аргумент, // в противном случае метод возвращает сообщение об ошибке if (argumentList === null || argumentList.getChildCount() !== 1) { return 'Error: Number требует один аргумент'; } const arg = argumentList.singleExpression()[0]; const number = this.removeQuotes(this.visit(arg)); return `int(${number})`; } /** * Удаляет символы кавычек в начале и в конце строки * * @param {String} str * @returns {String} */ removeQuotes(str) { let newStr = str; if ( (str.charAt(0) === '"' && str.charAt(str.length - 1) === '"') || (str.charAt(0) === '\'' && str.charAt(str.length - 1) === '\'') ) { newStr = str.substr(1, str.length - 2); } return newStr; }
В Python не используется ключевое слово `
new` при вызове конструктора, поэтому мы его удаляем, а точнее, в узле `visitNewExpression` продолжаем обход дерева исключив первого потомка. Затем заменяем ключевое слово `Number` на `int`, что является его эквивалентом в Python. Так как `Number` это выражение (Expression), у нас появляется доступ к его аргументам посредством метода `.arguments()`.
Аналогичным образом мы можем пройти по всем перечисленным в ECMAScriptVisitor.js методам и трансформировать все доступные для JavaScript литералы, символы, правила и тому подобное в их эквиваленты для Python (или любого другого языка программирования).
Обработка ошибок
ANTLR по умолчанию валидирует инпут на соответствие синтаксису, указанному в грамматике. В случае несоответствия в консоль будет выдана информация о возникшей проблеме, при этом ANTLR также вернет строку в том виде, как сумел ее распознать. Если удалить из исходной строки `{x: 2}` двоеточие, ANTLR заменит нераспознанные узлы на `undefined`.
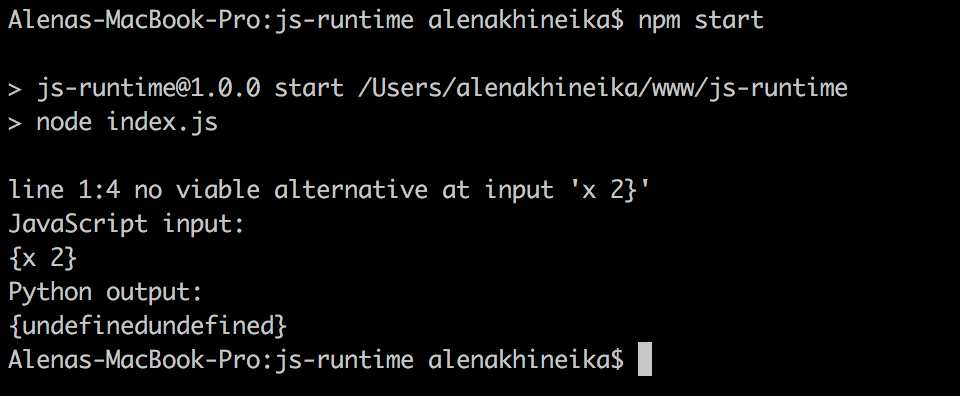
Мы можем повлиять на это поведение и вместо битой строки вывести детализированную информацию об ошибке. Для начала создадим новый модуль в корне нашего приложения, отвечающий за формирование пользовательских типов ошибок.
$ mkdir error $ cd error $ touch helper.js $ touch config.json
Я не буду подробно останавливаться на особенностях реализации данного модуля, так как это выходит за рамки темы про компиляторы. Вы можете скопировать готовый вариант, приведенный ниже, либо же написать свой вариант, более подходящий под инфраструктуру вашего приложения.
Все типы ошибок, которые вы хотите использовать в своем приложении, указываются в config.json.
{ "syntax": {"generic": {"message": "Something went wrong"}}, "semantic": { "argumentCountMismatch": { "message": "Argument count mismatch" } } }
Затем error.js циклически проходит список из конфига и для каждой записи в нем создает отдельный класс, наследуемый от Error.
const config = require('./config.json'); const errors = {}; Object.keys(config).forEach((group) => { Object.keys(config[group]).forEach((definition) => { // Имя ошибке присваивается автоматически на основании конфига const name = [ group[0].toUpperCase(), group.slice(1), definition[0].toUpperCase(), definition.slice(1), 'Error' ].join(''); const code = `E_${group.toUpperCase()}_${definition.toUpperCase()}`; const message = config[group][definition].message; errors[name] = class extends Error { constructor(payload) { super(payload); this.code = code; this.message = message; if (typeof payload !== 'undefined') { this.message = payload.message || message; this.payload = payload; } Error.captureStackTrace(this, errors[name]); } }; }); }); module.exports = errors;
Обновим `
visitNumberExpression` метод и теперь вместо текстового сообщения с пометкой `Error` будем выбрасывать ошибку `SemanticArgumentCountMismatchError`, которую легче отловить и тем самым начать различать успешный и проблемный результат работы нашего приложения.const path = require('path'); const { SemanticArgumentCountMismatchError } = require(path.resolve('error', 'helper')); /** * Посещает узел с ключевым словом `Number` * * @param {object} ctx * @returns {string} */ visitNumberExpression(ctx) { const argumentList = ctx.arguments().argumentList(); if (argumentList === null || argumentList.getChildCount() !== 1) { throw new SemanticArgumentCountMismatchError(); } const arg = argumentList.singleExpression()[0]; const number = this.removeQuotes(this.visit(arg)); return `int(${number})`; }
Теперь займемся ошибками, непосредственно относящимися к работе ANTLR, а именно теми, которые возникают во время синтаксического анализа кода. В директории codegeneration создадим новый файл ErrorListener.js а в нем класс, наследуемый от `antlr4.error.ErrorListener`.
const antlr4 = require('antlr4'); const path = require('path'); const {SyntaxGenericError} = require(path.resolve('error', 'helper')); /** * Пользовательский обработчик ошибок на стадии разбора строки * * @returns {object} */ class ErrorListener extends antlr4.error.ErrorListener { /** * Проверяет на синтаксические ошибки * * @param {object} recognizer Структура, используемая для распознавания ошибок * @param {object} symbol Символ, вызвавший ошибку * @param {int} line Строка с ошибкой * @param {int} column Позиция в строке * @param {string} message Текст ошибки * @param {string} payload Трассировка стека */ syntaxError(recognizer, symbol, line, column, message, payload) { throw new SyntaxGenericError({line, column, message}); } } module.exports = ErrorListener;
Для переопределения стандартного способа вывода ошибок воспользуемся двумя методами, доступными парсеру ANTLR:
- parser.removeErrorListeners() удаляет стандартный ConsoleErrorListener.
- parser.addErrorListener() добавляет пользовательский ErrorListener.
Это должно быть сделано после создания парсера, но перед его вызовом. Полный код обновленного index.js будет выглядеть следующим образом:
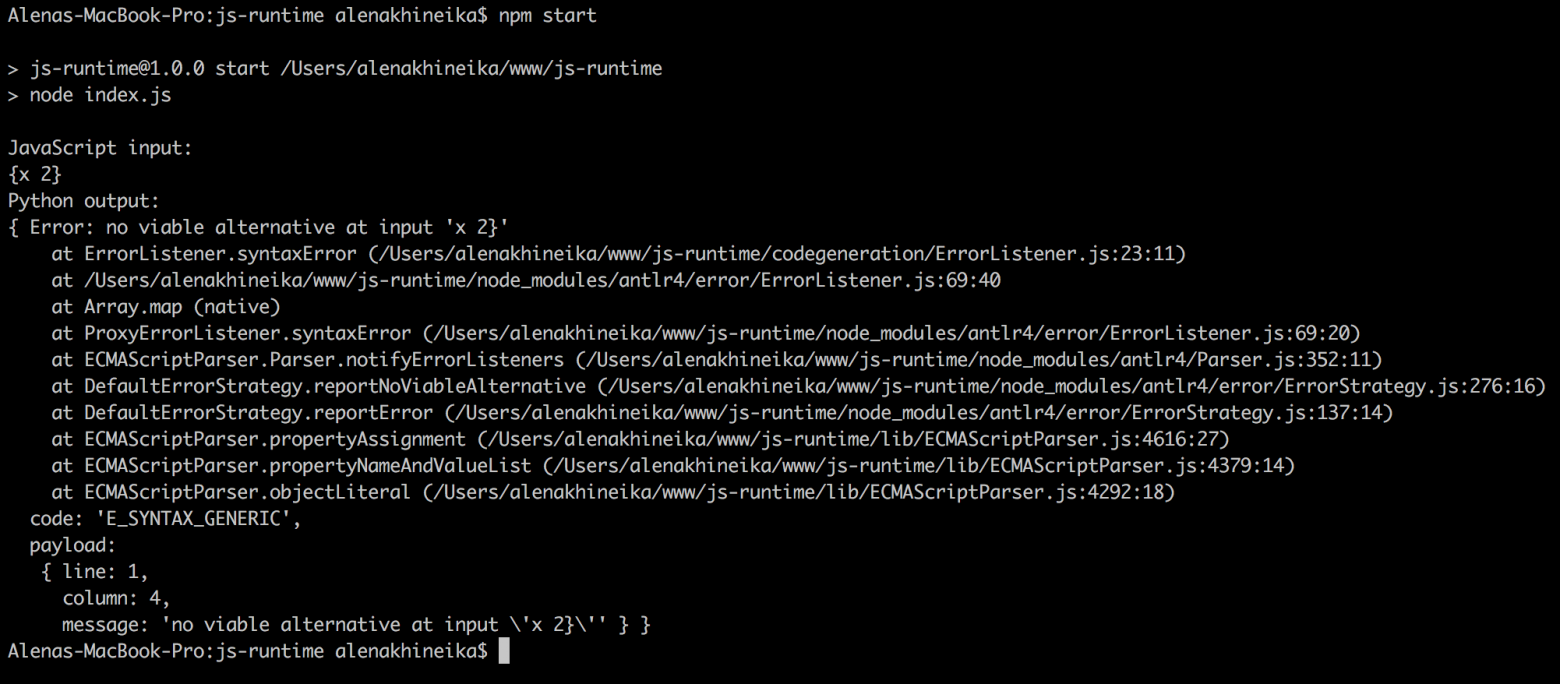
const antlr4 = require('antlr4'); const ECMAScriptLexer = require('./lib/ECMAScriptLexer.js'); const ECMAScriptParser = require('./lib/ECMAScriptParser.js'); const PythonGenerator = require('./codegeneration/PythonGenerator.js'); const ErrorListener = require('./codegeneration/ErrorListener.js'); const input = '{x 2}'; const chars = new antlr4.InputStream(input); const lexer = new ECMAScriptLexer.ECMAScriptLexer(chars); lexer.strictMode = false; // не использовать JavaScript strictMode const tokens = new antlr4.CommonTokenStream(lexer); const parser = new ECMAScriptParser.ECMAScriptParser(tokens); const listener = new ErrorListener(); parser.removeErrorListeners(); parser.addErrorListener(listener); console.log('JavaScript input:'); console.log(input); console.log('Python output:'); try { const tree = parser.expressionSequence(); const output = new PythonGenerator().start(tree); console.log(output); // console.log(tree.toStringTree(parser.ruleNames)); } catch (error) { console.log(error); }
Благодаря информации, которая теперь содержится в объекте ошибки мы можем решить как корректно обработать возникшее исключение, прервать или продолжить выполнение программы, завести информативный лог или, что не последнее по значимости, написать тесты, поддерживающие корректные и некорректные исходные данные для компилятора.
Заключение
Если вам кто-то предложит написать компилятор, сразу соглашайтесь! Это очень интересно и скорее всего значительно отличается от ваших привычных задач в программировании. Мы рассмотрели только самые простые узлы, чтобы в общих чертах сформировать представление о процессе написания компилятора на JavaScript с помощью ANTLR. Функционал же можно расширить валидацией типов передаваемых аргументов, добавить в грамматику поддержку Extended JSON или BSON, применить таблицу идентификаторов для распознавания таких методов как toJSON(), toString(), getTimestamp() и так далее. На самом деле возможности безграничны.
На момент написания статьи работа над MongoDB компилятором находится на начальном этапе. Вполне вероятно, что данный подход трансформации кода со временем будет изменен, или появятся более оптимальные решения, и тогда я, возможно, напишу новую статью с более актуальной информацией.
Сегодня я очень увлечена написанием компилятора и хочу сохранить полученные в процессе знания, которые возможно, будут полезны кому-то еще.
Если вы хотите сильнее углубится в тему, могу порекомендовать следующие ресурсы для прочтения:
- The language of languages by Matt Might
- Compiler Construction by Niklaus Wirth
- Компиляторы. Принципы, технологии и инструментарий авторов Альфреда В. Ахо, Моники С. Лам, Рави Сети, Джеффри Д. Ульман
- Tree structures processing and unified AST by Ivan Kochurkin, Positive Technologies
- Лекция «Основы компиляторов» авторов А. Ахо, Р. Сети, Дж. Ульман
И ссылки на ресурсы, используемые в статье:
- Super Tiny Compiler by James Kyle
- Implementing a Simple Compiler on 25 Lines of JavaScript by Minko Gechev
- How to write a simple interpreter in JavaScript by Peter Olson
- Parsing in JavaScript: Tools and Libraries by Gabriele Tomassetti
- The ANTLR Mega Tutorial by Gabriele Tomassetti
- Грамматика MySQL на ANTLR 4 автора Худяшова Ивана
- Обработка древовидных структур и унифицированное AST автора Ивана Кочуркина
- Теория и практика парсинга исходников с помощью ANTLR и Roslyn автора Ивана Кочуркина
- Antlr4 — Visitor vs Listener Pattern by Saumitra Srivastav
Спасибо моей команде Compass и, в частности, Anna Herlihy за менторство и вклад в написание компилятора, ревьюверам Алексу Комягину, Мише Тюленеву за рекомендации о структуре статьи, и за леттеринг к заглавной иллюстрации Оксане Наливайко.
Английская версия статьи на Medium: Compiler in JavaScript using ANTLR

