(издание 2018)
Miguel Grinberg


Это двадцать вторая часть Мега-Учебника, в которой я расскажу вам, как создавать фоновые задания, которые работают независимо от веб-сервера.
Под спойлером приведен список всех статей серии 2018 года.
- Глава 1: Привет, мир!
- Глава 2: Шаблоны
- Глава 3: Веб-формы
- Глава 4: База данных
- Глава 5: Пользовательские логины
- Глава 6: Страница профиля и аватары
- Глава 7: Обработка ошибок
- Глава 8: Подписчики, контакты и друзья
- Глава 9: Разбивка на страницы
- Глава 10: Поддержка электронной почты
- Глава 11: Реконструкция
- Глава 12: Дата и время
- Глава 13: I18n и L10n
- Глава 14: Ajax
- Глава 15: Улучшение структуры приложения
- Глава 16: Полнотекстовый поиск
- Глава 17: Развертывание в Linux
- Глава 18: Развертывание на Heroku
- Глава 19: Развертывание на Docker контейнерах
- Глава 20: Магия JavaScript
- Глава 21: Уведомления пользователей
- Глава 22: Фоновые задачи (Эта статья)
- Глава 23: Интерфейсы прикладного программирования (API)
Примечание 1: Если вы ищете старые версии данного курса, это здесь.
Примечание 2: Если вдруг Вам захотелось бы выступить в поддержку моей(Мигеля) работы, или просто не имеете терпения дожидаться статьи неделю, я (Мигель Гринберг)предлагаю полную версию данного руководства(на английском языке) в виде электронной книги или видео. Для получения более подробной информации посетите learn.miguelgrinberg.com.
Эта глава посвящена реализации длительных или сложных процессов, которые должны выполняться как часть приложения. Эти процессы не могут выполняться синхронно в контексте запроса, поскольку блокируют ответ клиенту на время выполнения задачи. Я кратко коснулся этой темы в главе 10, переместив отправку сообщений электронной почты в фоновые потоки, чтобы клиенту не приходилось ждать в течение тех 3-4 секунд, которые требуются для отправки электронной почты. Хотя использование потоков для сообщений электронной почты является приемлемым, это решение плохо масштабируется, когда рассматриваемые процессы намного длиннее. Общепринятой практикой является выгрузка длинных задач в рабочий процесс или, скорее всего, в пул.
Чтобы оправдать необходимость в длительных задачах, я собираюсь ввести функцию экспорта в Microblog, через которую пользователи смогут запрашивать файл данных со всеми своими сообщениями в блоге. Когда пользователь использует эту опцию, приложение должно экспортировать все сообщения пользователя в файл JSON, а затем отправить его пользователю по электронной почте. Пока все это происходит, пользователь увидит уведомление, показывающее процент завершения.
Ссылки GitHub для этой главы: Browse, Zip, Diff.
Введение в очереди задач
Очереди задач (Task queues) предоставляют приложению удобное решение для запроса выполнения задачи рабочим процессом. Рабочие процессы выполняются независимо от приложения и даже могут располагаться в другой системе. Связь между приложением и обработчиком осуществляется через очередь сообщений (message queue). Приложение отправляет задание, а затем отслеживает его выполнение, взаимодействуя с очередью. На следующей схеме показана типичная реализация:

Самая популярная очередь задач для Python — Celery. Это довольно сложный пакет, который имеет множество опций и поддерживает несколько очередей сообщений. Другой популярный вариант очереди задач Python — Redis Queue или просто RQ, который поддерживает только очередь сообщений Redis, но гораздо проще настраивается по сравнению с Celery.
Как Celery, так и RQ вполне подходят для поддержки фоновых задач в приложении Flask, поэтому моему выбору для этого приложения будет способствовать простота RQ. Тем не менее, реализация такой же функциональности с Celery не сильно сложнее. Если вас интересует Celery больше, чем RQ, вы можете прочитать статью Использование Celery с Flask, которую я написал в своем блоге.
Использование RQ
RQ — стандартный пакет Python, который устанавливается через pip:
(venv) $ pip install rq (venv) $ pip freeze > requirements.txt
Как я уже упоминал ранее, связь между приложением и обработчиком RQ будет осуществляться в очереди сообщений Redis, поэтому вам нужно запустить сервер Redis. Есть много вариантов установки и запуска сервера Redis в один клик для загрузки установщиков исходного кода и компиляции его непосредственно в вашей системе. Если Вы используете Windows, то Microsoft поддерживает установщики здесь. В Linux вы, вероятно, можете получить его как пакет через менеджер пакетов вашей операционной системы. Пользователи Mac OS X могут запустить brew install redis, а затем запустить службу вручную с помощью команды redis-server.
Вам не нужно будет взаимодействовать с Redis во всем, кроме проверки, что служба запущена и доступна для RQ.
Создание Task (Задачи)
Я покажу вам, как выполнить простую задачу через RQ, чтобы вы ознакомились с ней. Task-это не более чем функция Python. Вот пример задачи, которую я собираюсь реализовать в новом модуле app/tasks.py:
app/tasks.py: Пример фоновой задачи.
import time def example(seconds): print('Starting task') for i in range(seconds): print(i) time.sleep(1) print('Task completed')
Эта задача принимает число секунд в качестве аргумента, а затем ожидает это время, печатая счетчик один раз в секунду.
Запуск RQ Worker
Теперь, когда задача готова, обработчик может стартовать. Это делается с помощью команды rq worker:
(venv) $ rq worker microblog-tasks 18:55:06 RQ worker 'rq:worker:miguelsmac.90369' started, version 0.9.1 18:55:06 Cleaning registries for queue: microblog-tasks 18:55:06 18:55:06 *** Listening on microblog-tasks...
Рабочий процесс теперь подключен к Redis и отслеживает все задания, которые могут быть ему назначены в очереди с именем microblog-tasks. В случаях, когда требуется, чтобы несколько обработчиков имели большую пропускную способность, все, что вам нужно сделать, это запустить больше экземпляров rq worker, все подключенные к одной очереди. Затем, когда задание появится в очереди, его выберет любой из доступных рабочих процессов. В рабочей среде (production environment), вероятно, потребуется иметь по крайней мере столько рабочих процессоров, сколько доступно в CPU.
Выполнение Задач
Теперь откройте второе окно терминала и активируйте в нем виртуальную среду. Я собираюсь использовать сеанс оболочки, чтобы запустить задачу example() в worker:
>>> from redis import Redis >>> import rq >>> queue = rq.Queue('microblog-tasks', connection=Redis.from_url('redis://')) >>> job = queue.enqueue('app.tasks.example', 23) >>> job.get_id() 'c651de7f-21a8-4068-afd5-8b982a6f6d32'
Класс Queue из RQ представляет очередь задач со стороны приложения. Он принимает два аргумента, — это имя очереди и объект соединения Redis, который в этом случае я инициализирую с URL-адресом по умолчанию. Если сервер Redis работает на другом хосте или порту, необходимо использовать другой URL-адрес.
Метод enqueue() используется для добавления задания в очередь. Первый аргумент-это имя задачи, которую вы хотите выполнить, заданное непосредственно как объект функции или как строка импорта. Я нахожу опцию string гораздо более удобной, так как это делает ненужным импорт функции на стороне приложения. Все оставшиеся аргументы, данные enqueue(), будут переданы функции, запущенной в worker.
Как только будет сделан вызов enqueue(), вы заметите некоторую активность в первом окне терминала, в котором запущен worker RQ. Вы увидите, что функция example() теперь работает и печатает счетчик один раз в секунду. В то же время, ваш другой терминал не заблокирован, и вы можете продолжить вычисление выражений в оболочке. В приведенном выше примере я назвал метод job.get_id(), чтобы получить уникальный идентификатор задачи. Еще одно интересное выражение, которое можно попробовать использовать с объектом job, — проверить, закончилась ли работа функции на рабочем месте:
>>> job.is_finished False
Если вы передали 23 как я сделал в моем примере выше, то функция будет работать около 23 секунд. После этого времени, job.is_finished станет True. Разве это не здорово?! Мне очень нравится простота RQ!
Как только функция завершает работу, обработчик (worker) возвращается к ожиданию новых заданий, так что вы можете повторить вызов enqueue() с другими аргументами, если вы хотите побольше поэкспериментировать. Данные, которые хранятся в очереди относительно задачи, останутся там на некоторое время (по умолчанию 500 секунд), но в конечном итоге будут удалены. Это важно, очередь задач не сохраняет историю выполненных заданий.
Отчет о ходе выполнения задачи
Пример задачи, который я использовал выше, нереально прост. Как правило в процессе длительной задачи вы хотите, чтобы какая-то информация о ходе выполнения была доступна приложению, которое, в свою очередь, может показать ее пользователю. RQ поддерживает это с помощью атрибута объекта задания meta. Позвольте мне переписать задачу example() для записи отчетов о ходе выполнения:
app/tasks.py: Пример фоновой задачи с отчетом о ходе выполнения.
import time from rq import get_current_job def example(seconds): job = get_current_job() print('Starting task') for i in range(seconds): job.meta['progress'] = 100.0 * i / seconds job.save_meta() print(i) time.sleep(1) job.meta['progress'] = 100 job.save_meta() print('Task completed')
Эта новая версия example() использует функцию RQ get_current_job() для получения экземпляра задания, аналогичного тому, который возвращается приложению при отправке задачи. Атрибут объекта задания meta-это словарь, в котором задача может записывать любые пользовательские данные, которые она хочет передать приложению. В этом примере для записи я использую элемент progress, представляющий процент выполнения задачи. Каждый раз, когда прогресс обновляется, я называю job.save_meta() для указания RQ записать данные в Redis, где приложение может их найти.
На стороне приложения (в настоящее время только оболочка Python) я могу запустить эту задачу, а затем отслеживать ход выполнения следующим образом:
>>> job = queue.enqueue('app.tasks.example', 23) >>> job.meta {} >>> job.refresh() >>> job.meta {'progress': 13.043478260869565} >>> job.refresh() >>> job.meta {'progress': 69.56521739130434} >>> job.refresh() >>> job.meta {'progress': 100} >>> job.is_finished True
Как вы можете видеть выше, на этой стороне атрибут meta доступен для чтения. Для обновления содержимого из Redis необходимо вызвать метод refresh().
Представление задач в базе данных
Для приведенного выше примера было достаточно запустить задачу и посмотреть, как она выполняется. Для веб-приложения все становится немного сложнее, потому что как только одна из этих задач запускается как часть запроса, этот запрос завершается, и весь контекст для этой задачи будет потерян. Поскольку я хочу, чтобы приложение отслеживало, какие задачи выполняет каждый пользователь, мне нужно использовать таблицу базы данных для поддержания некоторого состояния. Ниже вы можете увидеть новую реализацию модели Task:
app/models.py: Task model.
# ... import redis import rq class User(UserMixin, db.Model): # ... tasks = db.relationship('Task', backref='user', lazy='dynamic') # ... class Task(db.Model): id = db.Column(db.String(36), primary_key=True) name = db.Column(db.String(128), index=True) description = db.Column(db.String(128)) user_id = db.Column(db.Integer, db.ForeignKey('user.id')) complete = db.Column(db.Boolean, default=False) def get_rq_job(self): try: rq_job = rq.job.Job.fetch(self.id, connection=current_app.redis) except (redis.exceptions.RedisError, rq.exceptions.NoSuchJobError): return None return rq_job def get_progress(self): job = self.get_rq_job() return job.meta.get('progress', 0) if job is not None else 100
Интересным отличием этой модели от предыдущих является то, что поле первичного ключа id является строкой, а не целым числом. Это потому, что для этой модели я не собираюсь полагаться на собственную генерацию первичного ключа базой данных, а вместо этого буду использовать идентификаторы заданий, созданные RQ.
Модель будет хранить полное имя задачи (переданное в RQ), описание задачи, подходящее для отображения пользователям, связь с пользователем, запросившим задачу, и логическое значение, указывающее, завершена задача или нет. Цель поля complete-отделить завершенные задачи от задач, которые активно выполняются, так как выполняемые задачи требуют специальной обработки для отображения хода выполнения обновлений.
Метод get_rq_job() является вспомогательным методом, который загружает экземпляр RQ Job из заданного идентификатора задачи, который я могу получить из модели. Это делается с помощью Job.fetch(), который загружает экземпляр задания из данных, существующих в Redis. Метод get_progress() строится поверх метода get_rq_job() и возвращает процент выполнения задачи. Этот метод имеет несколько интересных предположений. Если идентификатор задания из модели не существует в очереди RQ, это означает, что задание уже завершено, а срок действия данных истек и было удалено из очереди, поэтому в этом случае возвращается 100 процентов. С другой стороны, если задание существует, но нет никакой информации, связанной с атрибутом meta, то можно с уверенностью предположить, что задание запланировано на выполнение, но еще не было возможности начать, поэтому в этой ситуации возвращается 0 как прогресс.
Чтобы применить изменения к схеме базы данных, необходимо создать новую миграцию, а затем обновить базу данных:
(venv) $ flask db migrate -m "tasks" (venv) $ flask db upgrade
Новая модель также может быть добавлена в контекст оболочки, чтобы сделать ее доступной в сеансах оболочки без необходимости её импорта:
microblog.py: Добавляем модель задачи в контекст оболочки.
from app import create_app, db, cli from app.models import User, Post, Message, Notification, Task app = create_app() cli.register(app) @app.shell_context_processor def make_shell_context(): return {'db': db, 'User': User, 'Post': Post, 'Message': Message, 'Notification': Notification, 'Task': Task}
Интеграция RQ с приложением Flask
В конфигурацию необходимо добавить URL-адрес подключения для службы Redis:
class Config(object): # ... REDIS_URL = os.environ.get('REDIS_URL') or 'redis://'
Как всегда, URL-адрес подключения Redis будет получен из переменной окружения, и если переменная не определена, будет использоваться URL-адрес по умолчанию, который предполагает, что служба работает на том же узле и порту по умолчанию.
Функция фабрики применения будет отвечать за инициализацию Redis и RQ:
app/_init_.py: RQ интеграция.
# ... from redis import Redis import rq # ... def create_app(config_class=Config): # ... app.redis = Redis.from_url(app.config['REDIS_URL']) app.task_queue = rq.Queue('microblog-tasks', connection=app.redis) # ...
app.task_queue будет очередью, в которой будут представлены задачи. Наличие очереди, прикрепленной к приложению, удобно, потому что в любом месте приложения я могу использовать current_app.task_queue для доступа к нему. Чтобы облегчить отправку или проверку какой-либо части приложения, я могу создать несколько вспомогательных методов в модели User:
app/models.py: Вспомогательные методы задачи в пользовательской модели.
# ... class User(UserMixin, db.Model): # ... def launch_task(self, name, description, *args, **kwargs): rq_job = current_app.task_queue.enqueue('app.tasks.' + name, self.id, *args, **kwargs) task = Task(id=rq_job.get_id(), name=name, description=description, user=self) db.session.add(task) return task def get_tasks_in_progress(self): return Task.query.filter_by(user=self, complete=False).all() def get_task_in_progress(self, name): return Task.query.filter_by(name=name, user=self, complete=False).first()
Метод launch_task() передаёт задачу в очередь RQ вместе с добавлением её в базу данных. Аргумент name является именем функции, как определено в app/tasks.py. При отправке в RQ функция добавляет к app.tasks.name что бы построить полное имя функции. Аргумент description-это внятное описание задачи, которое может быть представлено пользователям. Для функции, экспорта сообщения в блоге, я буду использовать имя export_posts и описания Exporting posts.... Остальные аргументы являются позиционными и ключевыми аргументами, которые будут переданы задаче. Функция начинается с вызова метода очереди enqueue() для отправки задания. Возвращаемый объект задания содержит id задачи, назначенный RQ, поэтому я могу использовать его для создания соответствующего объекта задачи в своей базе данных.
Обратите внимание, что launch_task() добавляет, но не фиксит новый объект Task в сеансе. В общем случае лучше всего работать с сеансом базы данных в функциях более высокого уровня, так как это позволяет объединить несколько обновлений, сделанных функциями более низкого уровня, в одну транзакцию. Это не строгое правило, и далее в этой главе вы увидите исключение, в котором фиксация выполняется в дочерней функции.
Метод get_tasks_in_progress() возвращает полный список функций, которые выдаются пользователю. Позже вы увидите, что я использую этот метод для включения информации о выполняемых задачах на страницах, которая отображаются пользователю.
Наконец, get_task_in_progress() является более простой версией предыдущей, которая возвращает конкретную задачу. Я запрещаю пользователям запускать две или более задачи одного типа одновременно, поэтому перед запуском задачи я могу использовать этот метод, чтобы узнать, выполняется ли предыдущая задача в настоящее время.
Отправка сообщений электронной почты из RQ Task
Это может показаться отступлением от основной темы, но как я уже сказал выше, с завершением фоновой задача экспорта, пользователю будет отправлено электронное письмо с файлом JSON, который содержит все сообщения. Функциональность электронной почты, которую я представил в главе 11, должна быть расширена двумя способами. Во-первых, мне нужно добавить поддержку вложений файлов, чтобы я мог прикрепить файл JSON. Во-вторых, функция send_email() отправляет письма асинхронно, используя фоновый поток. Когда я собираюсь отправить электронное письмо из фоновой задачи, которая уже асинхронна, наличие фоновой задачи второго уровня, основанной на потоке, имеет мало смысла, поэтому мне нужно поддерживать как синхронную, так и асинхронную отправку электронной почты.
К счастью, Flask-Mail поддерживает вложения, поэтому все, что мне нужно сделать, это расширить функцию send_email(), чтобы взять их(вложения) в дополнительный аргумент, а затем настроить их в объекте Message. И дополнительно отправить письмо как приоритетную задачу, мне просто нужно добавить логический аргумент sync:
app/email.py: Отправка писем с вложениями.
# ... def send_email(subject, sender, recipients, text_body, html_body, attachments=None, sync=False): msg = Message(subject, sender=sender, recipients=recipients) msg.body = text_body msg.html = html_body if attachments: for attachment in attachments: msg.attach(*attachment) if sync: mail.send(msg) else: Thread(target=send_async_email, args=(current_app._get_current_object(), msg)).start()
Метод attach() класса Message принимает три аргумента, определяющих вложение: Имя файла, Тип носителя и фактические данные файла. Имя файла — это просто имя, которое увидит получатель, связанное с вложением, оно не должно быть реальным файлом. Тип носителя определяет, какой это тип вложения, что помогает читателям электронной почты отображать его соответствующим образом. Например, если вы отправляете jpg/png в качестве типа носителя, читатель электронной почты будет знать, что вложение является изображением, и в этом случае он может показать его как таковое. Для файла данных записи блога я собираюсь использовать Формат JSON, который использует тип мультимедиа application/json. Третий и последний аргумент-это строка или последовательность байтов с содержанием вложения.
Чтобы сделать его простым, аргумент attachments для send_email() будет списком кортежей, и каждый кортеж будет иметь три элемента, которые соответствуют трем аргументам attach(). Поэтому для каждого элемента в этом списке, необходимо отправить кортеж в качестве аргумента attach(). В Python, если у вас есть список или кортеж с аргументами, которые вы хотите отправить в функцию, вы можете использовать func(*args), чтобы этот список был расширен в фактический список аргументов, вместо того, чтобы использовать более утомительный синтаксис, такой как func(args[0], args[1], args[2]). Например, если у вас args = [1, 'foo'], вызов отправит два аргумента, как если бы вы вызвали func (1, 'foo'). Без * вызов имел бы единственный аргумент, который был бы списком.
Что касается синхронной отправки электронной почты, то мне нужно было просто вернуться к вызову mail.send(msg) непосредственно, когда sync is True.
Task Helpers
Хотя задача example(), которую я использовал выше, была простой автономной функцией, функция, которая экспортирует сообщения в блоге, потребует некоторых функций, которые у меня есть в приложении, как доступ к базе данных и функции отправки электронной почты. Поскольку это будет выполняться в отдельном процессе, мне нужно инициализировать Flask-SQLAlchemy и Flask-Mail, которые, в свою очередь, нуждаются в экземпляре приложения Flask, из которого можно получить их конфигурацию. Поэтому я собираюсь добавить экземпляр приложения Flask и контекст приложения в верхней части модуля app/tasks.py:
app/tasks.py: Создание приложения и контекста.
from app import create_app app = create_app() app.app_context().push()
Приложение создается в этом модуле, так как это единственный модуль, который будет импортировать RQ worker. При использовании команды flask модуль microblog.py в корневом каталоге создает приложение, но RQ worker ничего об этом не знает, поэтому ему необходимо создать собственный экземпляр приложения, если это необходимо функциям задачи. Вы видели метод app.app_context() уже в нескольких местах, нажатие контекста делает приложение "текущим" экземпляром приложения, и это позволяет таким расширениям, как Flask-SQLAlchemy, использовать current_app.config для получения их конфигурации. Без контекста выражение current_app возвращает ошибку.
Затем я задумался о том, каким образом я буду сообщать о ходе выполнения этой функции. В дополнении к передаче информации о ходе работы через словарь job.meta, я хотел бы отправить уведомления клиенту, чтобы можно было динамически обновлять процент завершения без необходимости обновления страницы. Для этого я собираюсь использовать механизмы уведомления похожие на те, которые я создал в главе 21. Обновления будут работать похожим образом на значок непрочитанных сообщений. Когда сервер отображает шаблон, он будет включать "статическую" информацию о ходе выполнения, полученную из job.meta, но затем, как только страница появится в браузере клиента, уведомления будут динамически обновлять процент с помощью уведомлений. Из-за уведомлений обновление хода выполнения запущенной задачи будет немного более сложным, чем то, как я это сделал в предыдущем примере, поэтому я собираюсь создать функцию-декоратор, посвященную обновлению хода выполнения:
app/tasks.py: Установка хода выполнения задачи.
from rq import get_current_job from app import db from app.models import Task # ... def _set_task_progress(progress): job = get_current_job() if job: job.meta['progress'] = progress job.save_meta() task = Task.query.get(job.get_id()) task.user.add_notification('task_progress', {'task_id': job.get_id(), 'progress': progress}) if progress >= 100: task.complete = True db.session.commit()
Задача экспорта может вызвать _set_task_progress() для записи процента выполнения. Функция сначала записывает процент в словарь job.meta и сохраняет его в Redis, затем загружает соответствующий объект task из базы данных и использует task.user для отправки уведомления пользователю, запросившему задачу, используя существующий метод add_notification(). Уведомление будет называться task_progress, и данные, связанные с ним, будут словарем с двумя элементами, идентификатором задачи и номером индикатора хода выполнения (progress number). Позже я добавлю код JavaScript, чтобы действовать на этот новый тип уведомления.
Функция проверяет, показывает ли индикатора хода выполнения, что функция завершена, и в этом случае также обновляет complete атрибут объекта задачи в базе данных. Вызов коммита базы данных гарантирует, что задача и объект уведомления, добавленные add_notification(), будут немедленно сохранены в базе данных. Мне нужно было быть очень осторожным в том, как я разработал родительскую задачу, чтобы не изменять какие-либо базы данных, так как этот коммит также записывал бы эти изменения.
Реализация задачи экспорта
Теперь все части на месте и можно написать функцию экспорта. Структура верхнего уровня этой функции будет выглядеть следующим образом:
app/tasks.py: Общая структура экспорта сообщений.
def export_posts(user_id): try: # читать сообщения пользователей из базы данных # отправить письмо с данными пользователю except: # обработки непредвиденных ошибок
Зачем переносить всю задачу в блок try/except? Код приложения, который существует в обработчиках запросов, защищен от непредвиденных ошибок, потому что сам Flask перехватывает исключения, а затем обрабатывает их, наблюдая за любыми обработчиками ошибок и конфигурацией ведения журнала, которые я настроил для приложения. Эта функция, однако, будет выполняться в отдельном процессе, который управляется RQ, а не Flask, поэтому, если возникнут непредвиденные ошибки, задача будет прервана, RQ отобразит ошибку на консоли, а затем вернется к ожиданию новых заданий. Поэтому, если вы не смотрите вывод RQ worker или не записываете его в лог-файл, вы никогда не узнаете, что произошла ошибка.
Давайте расмотрим три раздела отмеченные комментариями выше, по порядку с самого простого, которым является обработка ошибок в самом конце:
app/tasks.py: Обработка ошибок экспорта записей.
import sys # ... def export_posts(user_id): try: # ... except: _set_task_progress(100) app.logger.error('Unhandled exception', exc_info=sys.exc_info())
Всякий раз, когда возникает непредвиденная ошибка, я буду помечать задачу как завершенную, установив прогресс на 100%, а затем используя объект logger из приложения Flask регистрировать ошибку вместе с трассировкой стека, которая предоставляется вызовом sys.exc_info(). Приятным известием является то, что при использовании flask Application logger любые механизмы ведения журнала, которые вы реализовали для приложения Flask будут соблюдаться и здесь. Например, в главе 7 я настроил отправку ошибок на адрес электронной почты администратора. Просто с помощью app.logger я также получаю такое поведение для этих ошибок.
Затем я закодирую фактический экспорт, который просто выдает запрос к базе данных и просматривает результаты в цикле, накапливая их в словаре:
app/tasks.py: Чтение сообщений пользователей из базы данных.
import time from app.models import User, Post # ... def export_posts(user_id): try: user = User.query.get(user_id) _set_task_progress(0) data = [] i = 0 total_posts = user.posts.count() for post in user.posts.order_by(Post.timestamp.asc()): data.append({'body': post.body, 'timestamp': post.timestamp.isoformat() + 'Z'}) time.sleep(5) i += 1 _set_task_progress(100 * i // total_posts) # отправить письмо с данными пользователю except: # ...
Для каждого поста функция будет включать словарь с двумя элементами, телом поста и временем написания поста. Время будет записано в стандарте ISO 8601. Объекты datetime Python, которые я использую, не хранят часовой пояс, поэтому после экспорта времени в формате ISO я добавляю "Z", что указывает на UTC.
Код немного усложняется из-за необходимости отслеживать прогресс. Я поддерживаю счетчик i, и мне нужно выполнить дополнительный запрос к базе данных, прежде чем я войду в цикл для total_posts, чтобы получить количество сообщений. С помощью i и total_posts каждая итерация цикла может обновлять ход выполнения задачи числом от 0 до 100.
Возможно, вы заметили, что я также добавил вызов time.sleep(5) в каждой итерации цикла. Основная причина, по которой я добавил sleep, заключается в том, чтобы сделать задачу экспорта более длительной и иметь возможность видеть рост прогресса, даже когда экспорт охватывает всего несколько сообщений в блоге.
Ниже вы можете увидеть последнюю часть функции, которая отправляет пользователю электронное письмо со всей информацией, собранной в data в качестве вложения:
app/tasks.py: Сообщения электронной почты для пользователя.
import json from flask import render_template from app.email import send_email # ... def export_posts(user_id): try: # ... send_email('[Microblog] Your blog posts', sender=app.config['ADMINS'][0], recipients=[user.email], text_body=render_template('email/export_posts.txt', user=user), html_body=render_template('email/export_posts.html', user=user), attachments=[('posts.json', 'application/json', json.dumps({'posts': data}, indent=4))], sync=True) except: # ...
Это просто вызов функции send_email(). Вложение определяется как кортеж с тремя элементами, которые затем передаются методу attach() объекта Flask-Mail's Message. Третий элемент в кортеже-это содержимое вложения, которое создается с помощью функции Python json.dumps().
Есть пара новых шаблонов, указанных здесь, которые обеспечивают содержание сообщения в текстовом и HTML виде. Вот текстовый шаблон:
app/templates/email/export_posts.txt: Export posts text email template.
Dear {{ user.username }}, Please find attached the archive of your posts that you requested. Sincerely, The Microblog Team
Вот HTML-версия письма:
app/templates/email/export_posts.html: Export posts HTML email template.
<p>Dear {{ user.username }},</p> <p>Please find attached the archive of your posts that you requested.</p> <p>Sincerely,</p> <p>The Microblog Team</p>
Экспорт функциональности в приложении
Все основные части для поддержки фоновых задач экспорта теперь на месте. Остается подключить эту функциональность к приложению, чтобы пользователи могли размещать запросы на отправку сообщений по электронной почте.
Ниже вы можете увидеть новую функцию просмотра export_posts:
app/main/routes.py: Export posts route and view function.
@bp.route('/export_posts') @login_required def export_posts(): if current_user.get_task_in_progress('export_posts'): flash(_('An export task is currently in progress')) else: current_user.launch_task('export_posts', _('Exporting posts...')) db.session.commit() return redirect(url_for('main.user', username=current_user.username))
Функция сначала проверяет, есть ли у пользователя невыполненная задача экспорта, и в этом случае просто мигает сообщение. На самом деле нет смысла иметь две задачи экспорта для одного и того же пользователя одновременно, поэтому это предотвращается. Я могу проверить это условие, используя метод get_task_in_progress(), который я реализовал ранее.
Если пользователь еще не запустил экспорт, то для его запуска вызывается launch_task(). Первый аргумент-это имя функции, которое будет передано RQ worker с префиксом app.tasks.. Второй аргумент-это просто текстовое описание, которое будет показано пользователю. Оба значения записываются в объект Task в базе данных. Функция завершается перенаправлением на страницу профиля пользователя.
Теперь мне нужно предоставить ссылку на этот маршрут, к которому пользователь может получить доступ для запроса экспорта. Я думаю, что самое подходящее место для этого на странице профиля пользователя, где ссылка может быть показана только при просмотре своей страницы, прямо под "Редактировать профиль":
app/templates/user.html: Ссылка Экспорт на странице профиля пользователя.
... <p> <a href="{{ url_for('main.edit_profile') }}"> {{ _('Edit your profile') }} </a> </p> {% if not current_user.get_task_in_progress('export_posts') %} <p> <a href="{{ url_for('main.export_posts') }}"> {{ _('Export your posts') }} </a> </p> ... {% endif %}
Эта ссылка привязана к условию, потому что я не хочу, чтобы она отображалась, когда пользователь уже выполняет экспорт.
На этом этапе фоновые задания должны быть функциональными, но без обратной связи с пользователем. Если вы хотите попробовать это, вы можете запустить приложение и RQ worker следующим образом:
- Убедитесь, что Redis запущен
- В первом окне терминала, запустите один или несколько экземпляров обработчиков RQ. Для этого необходимо использовать команду
rq worker microblog-tasks - Во втором окне терминала запустите Приложение Flask, набрав
flask run(не забудьте сначала установитьFLASK_APP)
Уведомления о ходе выполнения
В завершении этой функции, я хочу предоставить пользователю во время выполнении фоновой задачи процент её завершения. Просматривая параметры компонента Bootstrap, я решил использовать для этого предупреждение под панелью навигации. Предупреждения-это цветные горизонтальные полосы, отображающие информацию для пользователя. Синие окна оповещения-это то, что я использую для отображения мигающих сообщений. Теперь я собираюсь добавить зеленый, чтобы показать статус прогресса. Ниже Вы можете увидеть, как это будет выглядеть:
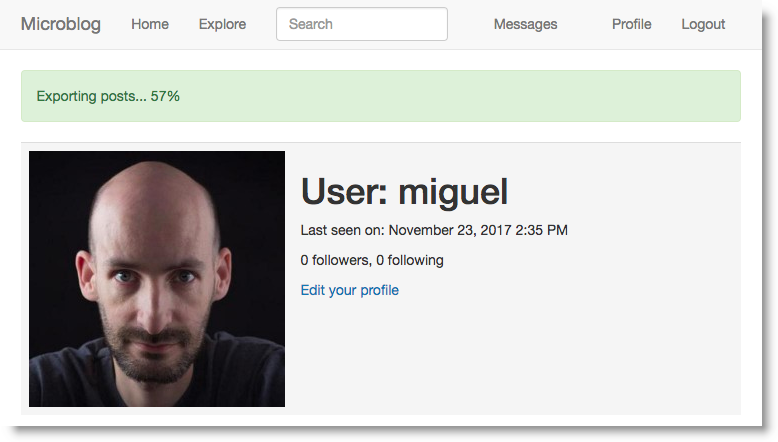
app/templates/base.html: Оповещение о ходе выполнения Экспорта в базовом шаблоне.
... {% block content %} <div class="container"> {% if current_user.is_authenticated %} {% with tasks = current_user.get_tasks_in_progress() %} {% if tasks %} {% for task in tasks %} <div class="alert alert-success" role="alert"> {{ task.description }} <span id="{{ task.id }}-progress">{{ task.get_progress() }}</span>% </div> {% endfor %} {% endif %} {% endwith %} {% endif %} ... {% endblock %} ...
Метод отображения оповещений задачи практически идентичен этим мигающим флешевым сообщениям. Внешнее условие пропускает всю связанную с предупреждением разметку если пользователь не вошел в систему. Для зарегистрированных пользователей я получаю текущий список задач, вызывая метод get_tasks_in_progress(), который я создал ранее. В текущей версии приложения я получу только один результат, так как я не разрешаю более одного активного экспорта за раз, но в будущем я могу захотеть поддерживать другие типы задач, которые могут сосуществовать, поэтому написание этого общим способом может сэкономить мне время позже.
Для каждой задачи я пишу элемент alert на страницу. Цвет оповещения контролируется вторым стилем CSS, который в данном случае является alert-success, в то время как в случае мигающих Сообщений был alert-info. Документация Bootstrap содержит подробные сведения о структуре HTML для оповещений. Текст включает описание полей, хранящихся в модели задач, а затем завершение в процентах.
Процент обернут в элемент <span>, который имеет атрибут id. Причина этого заключается в том, что я собираюсь обновить процент JavaScript при получении уведомления. Идентификатор, который я использую для данной задачи, создается как идентификатор задачи с добавлением -progress в конце. Когда приходит уведомление, оно будет содержать идентификатор задачи, поэтому я могу легко найти правильный элемент <span> для обновления с помощью селектора для #<task.id> - progress.
Если вы попробуете приложение на этом этапе, вы увидите "статические" обновления хода выполнения, при каждом переходе на новую страницу. Вы заметите, что после запуска задачи экспорта вы можете свободно переходить на разные страницы приложения, и состояние запущенной задачи всегда будет вызываться.
Чтобы подготовить динамические обновления к элементам процента <span>, я напишу небольшую вспомогательную функцию на JavaScript:
app/templates/base.html: Вспомогательная функция для динамического обновления индикатора хода выполнения задачи.
... {% block scripts %} ... <script> ... function set_task_progress(task_id, progress) { $('#' + task_id + '-progress').text(progress); } </script> ... {% endblock %}
Эта функция принимает id задачи и значение хода выполнения и использует jQuery для поиска элемента <span> для этой задачи и записи нового хода выполнения в качестве его содержимого. На самом деле нет необходимости проверять, существует ли элемент на странице, потому что jQuery ничего не будет делать, если элементы не расположены с данным селектором.
Уведомления уже поступают в браузер, так как функция _set_task_progress() в app/tasks.py вызывает add_notification() при каждом обновлении хода выполнения. Если вас смущает то, как эти уведомления могут достигать браузера без необходимости что-либо делать, это действительно потому, что в главе 21 я был достаточно предусмотрителен, чтобы реализовать функцию уведомлений в совершенно общем виде. Любые уведомления, добавляемые с помощью метода add_notification(), будут видны браузеру, когда он периодически запрашивает у сервера обновления уведомлений.
Но код JavaScript, который обрабатывает эти уведомления, распознает только те, которые имеют имя unread_message_count, и игнорирует остальные. Теперь мне нужно развернуть эту функцию, чтобы также обрабатывать уведомления task_progress, вызывая функцию set_task_progress(), которую я определил выше. Вот обновленная версия цикла, который обрабатывает уведомления из JavaScript:
app/templates/base.html: Обработчик уведомлений.
for (var i = 0; i < notifications.length; i++) { switch (notifications[i].name) { case 'unread_message_count': set_message_count(notifications[i].data); break; case 'task_progress': set_task_progress( notifications[i].data.task_id, notifications[i].data.progress); break; } since = notifications[i].timestamp; }
Теперь, когда мне нужно обработать два разных уведомления, я решил заменить оператор if, который проверял имя уведомления unread_message_count, оператором switch, который содержит один раздел для каждого уведомления, которое мне теперь нужно поддерживать. Если вы не особо знакомы с семейством языков "C", возможно, вы не встречали операторы switch раньше. Они предоставляют удобный синтаксис, который заменяет длинную цепочку операторов if/elseif. Это удобно для поддержания большого числа уведомлений, я могу просто продолжать добавлять их в качестве дополнительных блоков.
Если вы помните, данные, которые задача RQ прикрепляет к уведомлению task_progress, являются словарем с двумя элементами task_id и progress, которые являются двумя аргументами предназначенными для вызова set_task_progress().
Если вы запустите приложение сейчас, индикатор выполнения в зеленом окне оповещения будет обновляться каждые 10 секунд, так как уведомления доставляются клиенту.
Поскольку в этой главе я ввел новые строки пользовательского интерфейса, которые надо бы перевести, то файлы переводов необходимо обновить. Если вы поддерживаете файл, не относящийся к английскому языку, вам необходимо использовать Flask-Babel для обновления ваших файлов перевода, а затем добавить новые переводы:
(venv) $ flask translate update
Если вы используете перевод на испанском языке, то я сделал перевод для вас, поэтому вы можете просто извлечь файлы app/translations/es/LC_MESSAGES/messages.po из пакета загрузки для этой главы и добавить его в свой проект.
После того, как переводы выполнены, вам необходимо скомпилировать файлы перевода:
(venv) $ flask translate compile
Рекомендации по развертыванию
В завершении этой главы обсудим изменения в развертывании приложения. Для поддержки фоновых задач я добавил в стек два новых компонента: сервер Redis и один или несколько обработчиков RQ. Очевидно, что они должны быть включены в стратегию развертывания, поэтому я кратко расскажу о различных вариантах развертывания, о которых я рассказывал в предыдущих главах, и о том, как на них повлияли эти изменения.
Развертывание на сервере Linux
Если приложение выполняется на сервере Linux, добавление Redis должно быть таким же простым, как установка этого пакета из операционной системы. Для Ubuntu Linux необходимо запустить sudo apt-get install redis-server.
Чтобы запустить рабочий процесс RQ, вы можете следовать разделу "Настройка Gunicorn и Supervisor" в главе 17, чтобы создать вторую конфигурацию Supervisor, в которой вы запускаете микроблог rq worker-tasks вместо gunicorn. Если вы хотите запустить более одного обработчика (и, вероятно, должны для production), вы можете использовать директиву numprocs Супервизора, чтобы указать, сколько экземпляров вы хотите запустить одновременно.
Развертывание на Heroku
Чтобы развернуть приложение на Heroku, вам нужно добавить службу Redis в свою учетную запись. Это похоже на процесс, который я использовал для добавления базы данных Postgres. Redis также имеет халявный уровень, который можно добавить с помощью следующей команды:
$ heroku addons:create heroku-redis:hobby-dev
URL-адрес доступа для новой службы redis будет добавлен в среду Heroku в качестве переменной REDIS_URL, что является именно тем, что ожидает приложение.
Бесплатный план в Heroku позволяет один web-dyno и один worker dyno, так что вы можете разместить одного обработчика rq вместе с вашим приложением, не неся никаких расходов. Для этого вам нужно будет объявить обработчик в отдельной строке в вашем procfile:
web: flask db upgrade; flask translate compile; gunicorn microblog:app worker: rq worker microblog-tasks
После развертывания с этими изменениями можно запустить рабочий процесс с помощью следующей команды:
$ heroku ps:scale worker=1
Развертывание на Docker
При развертывании приложения в контейнерах Docker сначала необходимо создать контейнер Redis. Для этого можно использовать один из официальных образов Redis из реестра Docker:
$ docker run --name redis -d -p 6379:6379 redis:3-alpine
При запуске приложения необходимо связать контейнер redis и задать переменную окружения REDIS_URL, аналогично тому, как связан контейнер MySQL. Вот полная команда для запуска приложения, включая ссылку redis:
$ docker run --name microblog -d -p 8000:5000 --rm -e SECRET_KEY=my-secret-key \ -e MAIL_SERVER=smtp.googlemail.com -e MAIL_PORT=587 -e MAIL_USE_TLS=true \ -e MAIL_USERNAME=<your-gmail-username> -e MAIL_PASSWORD=<your-gmail-password> \ --link mysql:dbserver --link redis:redis-server \ -e DATABASE_URL=mysql+pymysql://microblog:<database-password>@dbserver/microblog \ -e REDIS_URL=redis://redis-server:6379/0 \ microblog:latest
Наконец, необходимо запустить один или несколько контейнеров для обработчиков RQ. Поскольку рабочие процессы основаны на том же коде, что и основное приложение, можно использовать тот же образ контейнера, который используется для приложения, переопределив команду start up, чтобы обработчик запускался вместо веб-приложения. Вот пример команды docker run, которая запускает worker:
$ docker run --name rq-worker -d --rm -e SECRET_KEY=my-secret-key \ -e MAIL_SERVER=smtp.googlemail.com -e MAIL_PORT=587 -e MAIL_USE_TLS=true \ -e MAIL_USERNAME=<your-gmail-username> -e MAIL_PASSWORD=<your-gmail-password> \ --link mysql:dbserver --link redis:redis-server \ -e DATABASE_URL=mysql+pymysql://microblog:<database-password>@dbserver/microblog \ -e REDIS_URL=redis://redis-server:6379/0 \ --entrypoint venv/bin/rq \ microblog:latest worker -u redis://redis-server:6379/0 microblog-tasks
Переопределение команды запуска по умолчанию образа Docker немного сложнее, потому как команда должна быть задана в двух частях. Аргумент--entrypoint принимает только имя исполняемого файла, но аргументы (если таковые имеются) должны быть заданы после образа и тега в конце командной строки. Заметьте что rq нужно дать как venv/bin/rq так, что оно будет работать без активации виртуальной среды.

