
Вы уже наверняка слышали про domain fronting, особенно в контексте блокировки РКН серверов Google, отвечающих за сам google.com, и дальше последовавший запрет Google и AWS на использование их доменов для обхода блокировок.
Что же такое прикрытие доменом?
Domain fronting, или, в вольном переводе, прикрытие доменом — это способ обойти фильтры и блокировки, скрыв конечную цель соединения, использующий особенности CDN. Этот способ возможен потому что современные CDN содержат в себе две принципиальные части, которые существуют независимо друг от друга и, как правило, взаимодействуют друг с другом лишь в части установки TCP соединения друг с другом:
- Есть внешняя часть, отвечающая за установку защищенного соединения с передачей данных SSL сертификата.
- Есть внутренняя часть, отвечающая за обработку непосредственно отправленного запроса после расшифровки. Обычно — HTTP запроса.
Так как эти две части не имеют связи между собой, можно при обращении к первой части обратиться к одному сайту, а после установки защищенного соединения отправить запрос к другому сайту. Если это касается частных CDN, то обычно тут нет никакой проблемы, за редким исключением в виде доступа к внутренним ресурсам, к которым обычно доступа нет. Если это касается публичных CDN, в которых можно купить членство, вроде AWS CloudFront или аналогов от других компаний, то здесь всё сразу становится много интересней.
Как цензор видит CDN
В задачу цензора входит ограничение доступа к определённым ресурсам из списка. В случае простого HTTP эта задача не представляет из себя особой проблемы даже с точностью до конкретного адреса страницы. Конечно, даже в такой простой задаче есть широкое поле для глупых ошибок, которые порождают множество красивых способов обойти блокировки, которые возможны из-за принципиальной устойчивости сети к всевозможным проблемам связи, какую особенность просто неспособны осознать люди, придумавшие блокировать сайты от беспомощности и неспособности сладить с критикой в сети.
В случае использования шифрования задача усложняется. Блокировка конкретного адреса страницы становится невозможной. Простейшим решением задачи блокировки сайта за HTTPS будет блокировка по IP. Даже если не используется CDN эта задача содержит ряд очень неприятных побочных эффектов. Если же используется CDN, то блокировка по IP становится зачастую невозможной: не сколько потому что на одном IP в CDN может быть много сайтов (РКН это не очень останавливало до сих пор), сколько потому что у сайта на CDN может быть много разных IP, которые невозможно знать заранее.
На выручку цензорам приходят совеременные браузеры, которые до установки защищенного соединения всегда посылают открытым текстом имя сайта, на который вы хотите зайти. Провайдерские и операторские DPI могут без проблем увидеть с каким именно сайтом устанавливается соединение, затем оборвать соединение или иным образом помешать.
Эксперимент
Давайте посмотрим, как установку соединения видит цензор, и как мы можем обвести цензора вокруг пальца. Для демонстрации мы используем tshark, хотя ту же демонстрацию можно провести с помощью tcpdump или через GUI в Wireshark.
В экспериментах используем этот же сайт, на котором вы читаете эту статью, так как он находится за CDN от QRATOR, которая обладает всеми необходимыми особенностями для демонстрации этого способа обхода цензуры. Сама эта демонстрация не говорит о том, что у используемой CDN от QRATOR есть какая-то уязвимость или проблема в безопасности: так до сих пор работали все CDN, и всё ещё работает большинство CDN. Точно такая же особенность есть, например, у CDN у Яндекса.
В одной консоли запустим:
tshark -T fields -Y 'tcp.dstport == 443 and ssl.handshake.extensions_server_name' -e ssl.handshake.extensions_server_name
Под Debian эта проблема исправляется тремя командами:
sudo dpkg-reconfigure wireshark-common sudo gpasswd -a $USER wireshark newgrp wireshark
Под другими дистрибутивами YMMV. При прочих равных используйте sudo.
В соседней консоли обратимся к какому-нибудь сайту по HTTPS:
curl -sI https://habr.com
В первой консоли в логе мы увидим имя сайта, к которому мы только что обращались, несмотря на использование HTTPS:
Capturing on 'eno1' habr.com
Сюрприз для цензора
Не закрывая логгирование SNI, попробуем сэмулировать тот запрос, который посылает cURL:
(echo HEAD / HTTP/1.1 echo Host: habr.com echo Connection: close echo) | openssl s_client -quiet -servername habr.com -connect habr.com:443
Мы увидим тот же самый ответ, что и ранее, при вызове curl -sI https://habr.com. В выводе tshark всё так же: логгируется соединение с habr.com.
А теперь, не меняя заголовки запроса, обратимся не к habr.com, а по старому имени сайта:
(echo HEAD / HTTP/1.1 echo Host: habr.com echo Connection: close echo) | openssl s_client -quiet -servername habrahabr.ru -connect habrahabr.ru:443
Сюрприз, сюрприз! Ответ мы получили ровно тот же самый, что и раньше, но в логе tshark и в выводе openssl s_client значится что мы обращались к habrahabr.ru, а не к habr.com:
depth=0 OU = Domain Control Validated, OU = PositiveSSL Multi-Domain, CN = habrahabr.ru
Такой же трюк можно сделать в обратную сторону:
(echo HEAD / HTTP/1.1 echo Host: habrahabr.ru echo Connection: close echo) | openssl s_client -quiet -servername habr.com -connect habr.com:443
В логах будет указано что мы обращались к habr.com, однако ответ будет соответствовать выводу:
curl -I https://habrahabr.ru
Не Хабром единым
Чтобы далеко не ходить, точно такой же трюк работает для сайтов Яндекса, использующих их собственную CDN:
(echo GET / HTTP/1.1 echo Host: music.yandex.kz echo Connection: close echo) | openssl s_client -quiet -servername music.yandex.ru -connect music.yandex.ru:443 | grep -Eo '<meta[^>]*?og:url[^>]*?>'
Лог цензора покажет что мы обращались к music.yandex.ru, а команда покажет что нам открылась главная страница music.yandex.kz:
<meta property="og:url" content="https://music.yandex.kz/home"/>
Что здесь вообще происходит?
На блок-схеме наши запросы выглядят примерно так:
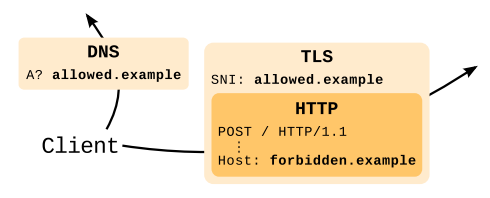
С точки зрения соединения мы подключаемся к одному сайту, например, google.com, но с точки зрения протокола HTTP запрос делаем к совершенно другому сайту, который лишь по случаю находится в той же CDN.
(Иллюстрация выше — из большой обзорной статьи на английском, рассматривающей историю вопроса, возможные альтернативы и прочие подробности использования доменного прикрытия.)
Что тут можно сказать?
Мы на практике убедились что мы можем отправить запрос к одному сайту за HTTPS, а цензор увидит что мы обращались к совершенно другому сайту. Именно таким образом Signal больше года обходил блокировку в Египте и некоторых других странах, прикрываясь google.com, пока сначала Google и затем Amazon не запретили им использовать свои сайты и сайты своих клиентов для обхода цензуры.
Телеграм тоже использует этот метод обхода цензуры. Желающие могут без особого труда найти в исходниках официальных клиентов как именно это делается в Телеграме, и какие CDN используются.
Понятно что от доменного прикрытия на CDN Хабра и Яндекса нет ровным счётом никакой практической пользы если у вас нет своего сайта, который использует ту же самую CDN, потому, ещё раз повторюсь, эта особенность CDN пока не считается уязвимостью произвольной CDN как таковой. Не спешите бежать на HackerOne заводить отчёты: your report сlosed as not applicable — это всё, что вы, пока, получите.
Такая ситуация приводит к тому, что большинство современных CDN в той или иной мере могут быть использованы для прикрытия чужим доменом.
Задача поиска доменов с высокой репутацией, размещенных на CDN, заблокировать которые решится не всякий цензор, требует лишь времени и упорства. Например, на CDN находятся многие популярные домены вроде media.tumblr.com, images.instagram.com, cdn.zendesk.com и cdn.atlassian.com, которые могут использоваться для доменного прикрытия. Никакого недостатка в таких популярных, а значит подходящих, доменах нет.
Служат ли злу Google и Amazon?
Возникает законный вопрос: если Google и Amazon не хотят помогать обходить цензуру, то означает ли что они прислуживают всемирному злу? На этот ответ нельзя дать однозначный ответ, так как есть факты использования доменного прикрытия не только для обхода цензуры, но и для несанкционированного удалённого доступа при взломах.
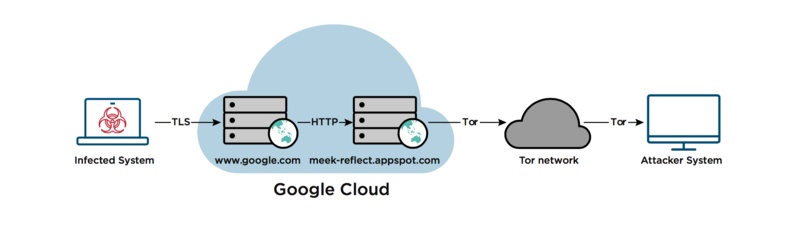
Понятное дело Google и Amazon не хотят иметь никакого отношения к взломщикам и прочему криминальному элементу, использующему их порядочные домены для своих грязных дел.
Последнее наблюдение говорит о том, что, к сожалению, можно ожидать что все другие CDN постепенно последуют вслед за Google и Amazon, запретив или ограничив у себя описанные возможности для обхода цензуры и блокировок.
Если вы администрируете свою собственную CDN, подумайте, может ли кто-нибудь использовать ваши услуги для подобных, несоответствующих ожидаемым, целям, и как вы к этому относитесь. Если не запрещать, то стоит хотя бы знать, что что-то такое может делаться на вашей территории.

