Разработка многопоточного кода — это сложное занятие. Действительно сложное. К счастью для упрощения жизни разработчиков давным-давно придуманы высокоуровневые абстракции, например, task-based parallelism, map-reduce/fork-join, CSP, actors и т.д.
Но когда попадаешь на профильные форумы, где общаются C++ники, то складывается ощущение, что многие просто не в курсе наличия чего-то более простого и удобного, чем std::thread в купе с std::mutex+std::condition_variable. Регулярно встречаются вопросы из категории: «Мне нужно запустить несколько рабочих потоков, в одном делается то-то, во втором то-то, а в третьем то-то. Я их запускаю вот так, а информацией между потоками обмениваюсь вот так. Правильно ли я делаю?»
Очевидно, что такие вопросы задают новички. Но, во-первых, количество неопытной молодежи в разработке софта всегда было велико, и с ростом привлекательности отрасли ИТ это количество только увеличивается. При этом печально, что новички знают про std::thread и std::mutex, но не знают про готовые инструменты, которые могли бы упростить им жизнь (вроде Intel TBB, HPX, QP/C++, Boost.Fiber, FastFlow, CAF, SObjectizer и т.д.).
И, во-вторых, среди ответов на такие вопросы довольно редко встречаются советы «возьмите вот этот готовый инструмент, ваша задача с его помощью решается всего в несколько строчек». Гораздо чаще люди обсуждают низкоуровневые детали самодельных реализаций thread-safe очередей сообщений.
Все это наводит на мысль о том, что имеет смысл на простых примерах показывать, как конкретный фреймворк может помочь в решении даже небольших и, казалось бы, несложных задач, связанных с многопоточностью. Поскольку мы развиваем SObjectizer как раз как инструмент для упрощения разработки многопоточных приложений на C++, то сегодня попробуем показать, как реализованные в SObjectizer-е CSP-шные каналы способны избавить разработчика от части головной боли при написании многопоточного кода.
В этой статье мы рассмотрим несложный демонстрационный пример. Маленькое тестовое приложение на главной нити которого ведется «диалог» с пользователем. Когда пользователь вводит слово «exit», работа приложения завершается.
В приложении есть два дополнительных рабочих потока. На одном имитируется периодический «опрос» некого датчика. На втором рабочим потоке «снятая» с датчика информация «записывается» в файл.
Естественно, никакой реальной работы с датчиком и файлами данных не выполняется, вместо этого в программе организуются задержки, блокирующие рабочую нить на некоторое время. Таким образом имитируется синхронная работа с внешними устройствами и файлами.
Пусть такая грубая имитация читателя не смущает. Цель статьи в том, чтобы показать взаимодействие между рабочими потоками через CSP-шные каналы (которые в SObjectizer называются mchains), а не в том, чтобы наполнить рабочие нити актуальным содержимым.
Итак, в нашем примере кроме главной нити есть еще две дополнительных рабочих нити.
Первая рабочая нить, которую мы будем называть meter_reader_thread, предназначена для «опроса» датчика. Этой нити нужно два mchain-а. Первый mchain будет использоваться для отсылки команд самой нити meter_reader_thread. В частности, в этот канал по таймеру будет помещаться сообщение типа acquisition_turn, получив которое meter_reader_thread будет проводить «опрос».
Второй mchain нужен meter_reader_thread для того, чтобы передавать «снятую» с датчика информацию второй рабочей нити. Вторая рабочая нить, которую мы будем называть file_writer_thread, отвечает за «запись» информации в файл. Вторая рабочая нить читает из mchain команды на запись информации и «исполняет» их. Пока команд в mchain-е нет, нить file_writer_thread спит в ожидании новой команды.
Получается вот такая простая схема:
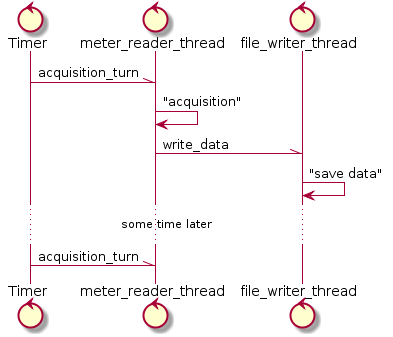
Работа обеих нитей завершается как только mchain-ы закрываются в главном рабочем потоке.
Полный исходный текст простого примера можно посмотреть в созданном для иллюстрации репозитории. Мы же пойдем от простого к сложному. Начнем разбор с функций, выполняющих работу нитей file_writer_thread и meter_reader_thread, после чего посмотрим на реализацию функции main(), в которой нам придется учесть ряд фокусов, связанных с многопоточностью.
Функция file_writer_thread() является самой простой в данном примере. Вот ее полный текст:
Все, что делает file_writer_thread() — это висит внутри вызова receive(). Функция receive() ждет поступления сообщения в канал и, когда сообщение в канал поступает, ищет обработчик для этого сообщения среди тех обработчиков, которые переданы в receive().
В данном случае передается всего один обработчик — для сообщения типа write_data. Когда сообщение такого типа поступает в канал, этот обработчик вызывается. Внутри данного обработчика, по сути, собрана вся «бизнес-логика», т.е. имитация записи прочитанных данных в файл.
У функции receive() в SObjectizer есть две версии. Первая версия, которую мы в данном примере не использовали, ждет и извлекает из канала всего одно сообщение. Вторая же версия, которая и показана выше, извлекает из канала все сообщения и возвращает управление только когда канал закрывается. Т.е. в данном случае выход из file_writer_thread() произойдет только когда завершит свою работу вызов receive(). А это случится когда кто-то закроет канал file_write_ch.
Функция meter_reader_thread несколько сложнее:
Здесь мы, во-первых, определяем тип сигнала acquisition_turn, который будет к нам время от времени приходить для того, чтобы мы выполнили имитацию «опроса» датчика.
Во-вторых, мы запускаем этот самый периодический сигнал acquisition_turn посредством вызова send_periodic(). Благодаря этому SObjectizer раз в 750ms будет отсылать acquisition_turn в timer_ch.
Ну а дальше уже знакомый нам вызов receive() из которого мы выйдем только когда канал timer_ch будет закрыт. Внутри receive() у нас реализован обработчик нашего сигнала acquisition_turn. В этом обработчике мы имитируем «опрос» датчика, а затем даем команду на запись «собранных» данных нити file_writer_thread через отсылку сообщения write_data в канал file_write_ch.
Так что получается, что meter_reader_thread спит все время внутри receive(), периодически просыпается при получении acquisition_turn, после чего отсылает сообщение write_data в file_write_ch (т.е. в нить file_writer_thread) и засыпает вновь до следующего acquisition_turn. Либо же пока timer_ch не будет закрыт.
Прежде чем заглянуть в код main(), нужно описать несколько небольших тонкостей, без обсуждения которых может быть непонятна часть этого кода.
Главная проблема, которую приходится решать при работе с нитями и CSP-шными каналами — это корректное и своевременное завершение рабочих нитей. Т.е. если мы создаем экземпляр std::thread и запускаем с его помощью рабочую нить, то мы должны будем затем вызывать std::thread::join() чтобы дождаться завершения рабочей нити (detached threads здесь не используются). Самый простой способ — это вручную вызвать std::thread::join() в конце функции main(). Что-то вроде:
Но плохо то, что такой наивный подход не защищает нас от исключений или других форм преждевременного выхода из скоупа (например, обычный return).
Тут нам мог бы помощь какой-то вспомогательный класс, который бы вызывал std::thread::join() в своем деструкторе. Например, мы могли бы сделать что-то вроде:
При использовании SObjectizer нет надобности писать такой auto_joiner самостоятельно, поскольку в SObjectizer уже есть подобный инструмент. Мы как раз увидим его использование в коде main(). От показанного выше от отличается тем, что может вызывать join() не для одного объекта std::thread, а для нескольких.
Но кроме вызова std::thread::join() для корректного останова рабочей нити в нашем примере нужно учесть еще один нюанс: чтобы нить, внутри которой вызван receive(), завершила свою работу, следует закрыть mchain. Если этого не сделать, возврата из receive() не произойдет и мы навечно заснем на вызове std::thread::join().
Это значит, что мы должны позаботится об автоматическом закрытии mchain-ов при выходе из main(). И тут мы применим такой же подход, как и с вызовом std::thread::join(): воспользуемся вспомогательным объектом, который в своем деструкторе вызывает close() для mchain-а. Т.е. мы сделаем что-то вроде:
Опять же, свою реализацию этого вспомогательного класса auto_closer нам делать не нужно, т.к. в SObjectizer уже есть готовая.
Мы уже разобрали как снять с себя заботы по вызову join() для рабочих нитей и автоматического закрытия mchain-ов. Но остался еще один очень важный момент: в каком именно порядке эти операции должны выполняться. Поскольку, если мы напишем вот такую самую простую и понятную последовательность:
то мы получим классический дедлок и зависание в деструкторе auto_joiner-а.
Проблема в том, что деструктор auto_joiner-а вызывается до деструктора auto_closer-а. Т.е. мы попробуем сделать join для рабочей нити, которая висит на receive() из еще не закрытого mchain-а.
Поэтому для того, чтобы mchain-ы автоматически закрывались до того, как для рабочей нити будет вызван join(), нужно изменить порядок создания сущностей в программе:
И вот теперь, после объяснения основных нюансов, можно посмотреть на код самой функции main():
Надеюсь, что в основном этот код понятен. И пояснения могут потребоваться разве что для двух небольших моментов.
Во-первых, это создание экземпляра so_5::wrapped_env_t в начале main-а. За этим экземпляром будет скрываться SObjectizer Environment. А SObjectizer Environment нам нужен как для создания mchain-ов, так и для обслуживания таймеров (вызов send_periodic() в meter_reader_thread скрывает в себе обращение к SObjectizer-овскому таймеру).
Во-вторых, это вызов auto_close_drop_content. С одной стороны, с ним понятно: данная функция возвращает объект auto_closer, который автоматически закроет mchain-ы в своем деструкторе. Но, с другой стороны, что значит drop_content в названии этой функции?
Дело в том, что в SObjectizer закрыть mchain можно в двух режимах. В первом режиме mchain закрывается с выбрасыванием всех находящихся в mchain-е сообщений, которые еще не были обработаны функциями receive(). Например, на момент вызова close() в mchain находится 100500 сообщений. Все эти сообщения будут уничтожены и к получателям они не попадут. Этот режим называется drop_content и функция auto_close_drop_content как раз создает auto_closer, который закроет mchain в режиме drop_content.
Второй режим закрытия mchain-а, напротив, сохраняет все сообщения в mchain-е. Что дает возможность функциям receive() завершить обработку содержимого mchain. Но вот новые сообщения в mchain добавить будет уже нельзя, т.к. mchain уже закрыт (для записи). Такой режим называется, соответственно, retain_content.
Оба режима закрытия mchain-ов, drop_content и retain_content, хороши в разных ситуациях. В данном примере нам нужен drop_content, поэтому-то и используется auto_close_drop_content.
Если мы запустим наш первый пример, то увидим вполне ожидаемую картину:

Мы тут видим последовательные «опросы» и «запись» результатов этих «опросов».
Первая версия нашего примера получилась очень уж идеализированной: мы верим в то, что запись «снятых» с датчика данных всегда будет завершаться к следующему «опросу». Но в реальной жизни, скорее всего, время операций с внешними устройствами может «плавать» в довольно широких пределах. Это означает, что нам имело бы смысл позаботиться о ситуации, когда «запись» в файл займет больше времени и в mchain-е с сообщениями write_data начнут скапливаться сообщения.
Для того, чтобы проимитировать подобную ситуацию слегка модифицируем уже показанные выше функции meter_reader_thread() и file_writer_thread(). В meter_reader_thread() всего лишь увеличим темп поступления сигнала acquisition_turn:
А вот в file_writer_thread() сделаем так, чтобы время операции «записи» выбиралось случайным образом из диапазона [295ms, 1s]. Т.е. иногда операция «записи» будет укладываться в интервалы между «опросами», но в большинстве случаев — не будет. Иногда не будет укладываться очень сильно. Итак, вот как мы модифицируем file_writer_thread():
Получается, что теперь в file_write_ch могут скапливаться необработанные сообщения write_data. Возникает широко известная в узких кругах проблема перегрузки: это когда поставщик данных генерирует новые данные с большим темпом, нежели потребитель данных способен обработать. Проблема неприятная, с ней нужно бороться.
Например, можно реализовать механизм «back pressure». Т.е. когда поставщик данных начинает перегружать потребителя, то потребитель тем или иным способом дает поставщику об этом знать. В случае CSP-шных каналов вполне естественным способом реализации «back pressure» будет блокировка поставщика данных на операции записи в канал до тех пор, пока потребитель не освободится настолько, чтобы принять следующую порцию данных от поставщика.
Да.
Для этого нужно задать дополнительные свойства mchain-а при создании mchain-а. В первой версии нашего примера мы создавали mchain самым простым способом, вот так:
В этом случае создается «безразмерный» канал, в такой канал можно запихнуть столько сообщений, сколько позволяет размер свободной оперативной памяти.
Поскольку мы хотим «back pressure», то «безразмерный» канал нас не устраивает. Значит нам нужно ограничить количество сообщений, которые могут ждать в канале своей обработки.
Мы хотим так же, чтобы при попытке записи в заполненный канал поставщик информации «засыпал». С этим нет проблем, но в SObjectizer-е нужно задать верхнюю границу такого ожидания. Например, заснуть на попытке записи в канал, но спать не более пяти секунд (или пяти часов, это от задачи зависит).
SObjectizer требует от разработчика ограничить максимальное время ожидания на запись в заполненный канал потому, что без такого ограничения легко поймать дедлок. Скажем, нить T1 пытается записать сообщение в переполненный канал C1 для нити T2, которая в этот момент пытается записать сообщение в переполненный канал C2 для нити T3. А нить T3 в этот момент пытается записать сообщение в переполненный канал C0 для нити T1. В случае с ограничением на максимальное время ожидания такой дедлок будет со временем разорван автоматически.
Итак, мы задаем размер канала и максимальное время ожидания, но остается вопрос: «Что делать с операцией записи в переполненный канал, если место в канале не освободилось даже после ожидания?»
В SObjectizer можно выбрать, что делать, если место в канале не освободилось даже после ожидания. Например, можно выбросить самое старое сообщение, которое находится в канале. Или можно проигнорировать новое сообщение, которое мы попытались вставить в канал. Или можно сделать так, чтобы функция send() бросила в этом случае исключение.
В нашем примере мы используем такую реакцию, как выбрасывание самого старого сообщения. В данном случае это вполне логично, т.к. у нас уже есть «новые данные» с датчика, их запись актуальнее, чем сохранение старых данных. Поэтому в обновленном примере мы будем создавать канал для сообщений write_data следующим образом:
Дополнительное пояснение можно дать разве что аргументу so_5::mchain_props::memory_usage_t::preallocated. Этот аргумент определяет, как будет выделяться память для организации очереди сообщений внутри самого канала. Т.к. канал у нас имеет фиксированный и небольшой размер, то место под очередь сообщений имеет смысл выделить сразу. Что мы и делаем в данном случае.
Во втором примере мы ограничили размер канала для сообщений write_data. Но ведь у нас так же есть канал для сигналов acquisition_turn. Может имеет смысл его также ограничить?
Действительно, смысл есть. Нам вообще достаточно для acquisition_turn иметь канал емкостью в одно сообщение. Если сигнал acquisition_turn в канале уже есть, то новый добавлять туда нет смысла.
Поэтому мы модифицируем фрагмент кода, в котором мы создаем этот канал:
Мы здесь видим два важных отличия:
При запуске второго примера мы уже можем увидеть следующую картину:

Можно увидеть, что часть номеров из отладочной печати нити file_writer_thread исчезла. Например, после записи data_24.dat следует запись data_26.dat. А записи data_25.dat нет. Это потому, что сообщение write_data для data_25.dat было выброшено из канала при его переполнении.
Кроме того, мы можем видеть, что когда нить file_writer_thread надолго «уходит» в запись, то за это время нить meter_reader_thread успевает провести несколько «опросов».
Пусть главная нить сейчас в процессе диалога с пользователем понимает не только команду 'exit' (завершить работу приложения), но и команды 'inc' (удлинить период опроса в 1.5 раза) и 'dec' (сократить период опроса в 1.5 раза).
Главный вопрос, который нам в этом случае предстоит решить — это вопрос доставки команд inc и dec из главной нити приложения в нить meter_reader_thread. Но на самом деле — это не вопрос. Мы просто заведем два новых сигнала:
Главная нить будет отсылать эти сигналы в соответствующий канал, когда пользователь вводит ту или иную команду:
Но в какой именно канал мы будем отсылать эти сигналы? Вот этот вопрос гораздо интереснее.
В принципе, мы могли бы использовать один и тот же канал и для периодических acquisition_turn, и для inc_/dec_read_period. Но для того, чтобы показать, что еще умеет SObjectizer при работе с mchain-ами, мы будем использовать два разных канала для meter_reader_thread:
Для простоты реализации третьего примера оба эти канала будут создаваться и закрываться в функции main(), а в функцию meter_reader_thread() они будет передаваться как параметры:
Функция meter_reader_thread() существенно вырастет в размере, поскольку теперь она должна выполнять больше действий. И хотя мне самому не очень нравятся функции, текст которых не умещаются на один экран, в данном случае пришлось пойти на написание такой объемной функции, дабы не размазывать фрагменты бизнес-логики по вспомогательным функциям.
По сравнению с первым и вторым примерами, в третьем примере в meter_reader_thread произошло два принципиально важных изменения.
Во-первых, теперь период «опроса» датчика может изменяться. Из-за этого нам невыгодно запускать acquisition_turn в качестве периодического сообщения. Придется каждый раз перезапускать его при изменении периода. Поэтому сейчас мы пойдем другим путем: при обработке очередного acquisition_turn будем засекать время, потраченное на очередной «опрос» и отсылку write_data. После чего либо сразу будем отсылать себе acquisition_turn без задержки, если потратили на «опрос» слишком много времени. Либо же будем отсылать отложенное acquisition_turn, при этом задержка в доставке будет дельтой между текущим периодом опроса и реально затраченным временем.
У нас получится следующий фрагмент по обработке acqusition_turn:
Во-вторых, нам теперь придется ждать сообщения не из одного канала, а из двух сразу. В какой канал сообщение первым пришло, из такого мы должны взять сообщение и обработать взятое сообщение.
Для этого мы будем использовать функцию so_5::select(), которая похожа на ранее показанную so_5::receive(). Но, в отличии от receive(), функция select() может ждать входящие сообщения из нескольких каналов.
В итоге, в meter_reader_thread мы делаем вот такой вызов select() (схематично, опуская детали реализаций обработчиков):
Т.е. мы говорим, что select() должен ждать сообщения из всех ниже перечисленных каналов до тех пор, пока все каналы не будут закрыты. Затем, в секциях case_ идет перечисление каналов (по одному каналу на секцию) и список обработчиков для сообщений из каждого канала.
Так, из канала timer_ch мы обрабатываем только сигнал acquisition_time, а из канала control_ch — сигналы inc_read_period и dec_read_period.
Получается, что в третьем примере функция meter_read_thread() возвращает управление только после того, как управление возвращает select(). А select() завершает свою работу когда и timer_ch, и control_ch будут закрыты. Что происходит в main()-е при завершении работы приложения.
При запуске третьего примера и выдачи нескольких команд inc мы можем увидеть следующую картину:

Мы развиваем SObjectizer как инструмент для упрощения разработки многопоточных приложений, а не как реализацию какого-то одного подхода к проблеме concurrent computing. Поэтому в SObjectizer можно найти следы и Модели Акторов, и Publish/Subscribe, и CSP. Ранее мы больше рассказывали именно про ту часть SObjectizer-а, которая относится к моделям Акторов и Pub/Sub. Сегодня же мы попытались коротко познакомить читателя и с CSP-шными каналами. Это уже вторая попытка, первая была в прошлом году.
Если в нашем рассказе что-то осталось непонятным, то мы с удовольствием ответим на вопросы в комментариях. Если кто-то хочет, чтобы мы проиллюстрировали что-то из рассказанного картинкой/схемой, то скажите что именно — мы постараемся сделать соответствующую иллюстрацию и добавить ее в текст.
Вполне возможно, что показанный пример кому-то покажется неинтересным и оторванным от жизни. Все-таки нашей целью была его понятность. Но, если кто-то из читателей сможет предложить другой, более жизненный пример для того, чтобы проиллюстрировать его решение с помощью CSP-шных каналов, то мы попробуем сделать решение предложенного читателями примера и описать это решение в последующих статьях.
Ну а в завершение статьи предлагаем всем желающим попробовать SObjectizer в деле и поделиться своими впечатлениями. Обратная связь для нас очень важна и именно ваши пожелания/замечания позволяют нам развивать SObjectizer и делать его мощнее и удобнее.
Но когда попадаешь на профильные форумы, где общаются C++ники, то складывается ощущение, что многие просто не в курсе наличия чего-то более простого и удобного, чем std::thread в купе с std::mutex+std::condition_variable. Регулярно встречаются вопросы из категории: «Мне нужно запустить несколько рабочих потоков, в одном делается то-то, во втором то-то, а в третьем то-то. Я их запускаю вот так, а информацией между потоками обмениваюсь вот так. Правильно ли я делаю?»
Очевидно, что такие вопросы задают новички. Но, во-первых, количество неопытной молодежи в разработке софта всегда было велико, и с ростом привлекательности отрасли ИТ это количество только увеличивается. При этом печально, что новички знают про std::thread и std::mutex, но не знают про готовые инструменты, которые могли бы упростить им жизнь (вроде Intel TBB, HPX, QP/C++, Boost.Fiber, FastFlow, CAF, SObjectizer и т.д.).
И, во-вторых, среди ответов на такие вопросы довольно редко встречаются советы «возьмите вот этот готовый инструмент, ваша задача с его помощью решается всего в несколько строчек». Гораздо чаще люди обсуждают низкоуровневые детали самодельных реализаций thread-safe очередей сообщений.
Все это наводит на мысль о том, что имеет смысл на простых примерах показывать, как конкретный фреймворк может помочь в решении даже небольших и, казалось бы, несложных задач, связанных с многопоточностью. Поскольку мы развиваем SObjectizer как раз как инструмент для упрощения разработки многопоточных приложений на C++, то сегодня попробуем показать, как реализованные в SObjectizer-е CSP-шные каналы способны избавить разработчика от части головной боли при написании многопоточного кода.
Простой демонстрационный пример
В этой статье мы рассмотрим несложный демонстрационный пример. Маленькое тестовое приложение на главной нити которого ведется «диалог» с пользователем. Когда пользователь вводит слово «exit», работа приложения завершается.
В приложении есть два дополнительных рабочих потока. На одном имитируется периодический «опрос» некого датчика. На втором рабочим потоке «снятая» с датчика информация «записывается» в файл.
Естественно, никакой реальной работы с датчиком и файлами данных не выполняется, вместо этого в программе организуются задержки, блокирующие рабочую нить на некоторое время. Таким образом имитируется синхронная работа с внешними устройствами и файлами.
Пусть такая грубая имитация читателя не смущает. Цель статьи в том, чтобы показать взаимодействие между рабочими потоками через CSP-шные каналы (которые в SObjectizer называются mchains), а не в том, чтобы наполнить рабочие нити актуальным содержимым.
Принцип работы примера «на пальцах»
Итак, в нашем примере кроме главной нити есть еще две дополнительных рабочих нити.
Первая рабочая нить, которую мы будем называть meter_reader_thread, предназначена для «опроса» датчика. Этой нити нужно два mchain-а. Первый mchain будет использоваться для отсылки команд самой нити meter_reader_thread. В частности, в этот канал по таймеру будет помещаться сообщение типа acquisition_turn, получив которое meter_reader_thread будет проводить «опрос».
Второй mchain нужен meter_reader_thread для того, чтобы передавать «снятую» с датчика информацию второй рабочей нити. Вторая рабочая нить, которую мы будем называть file_writer_thread, отвечает за «запись» информации в файл. Вторая рабочая нить читает из mchain команды на запись информации и «исполняет» их. Пока команд в mchain-е нет, нить file_writer_thread спит в ожидании новой команды.
Получается вот такая простая схема:
Работа обеих нитей завершается как только mchain-ы закрываются в главном рабочем потоке.
Разбор текста простого примера
Полный исходный текст простого примера можно посмотреть в созданном для иллюстрации репозитории. Мы же пойдем от простого к сложному. Начнем разбор с функций, выполняющих работу нитей file_writer_thread и meter_reader_thread, после чего посмотрим на реализацию функции main(), в которой нам придется учесть ряд фокусов, связанных с многопоточностью.
Функция file_writer_thread()
Функция file_writer_thread() является самой простой в данном примере. Вот ее полный текст:
// Нить, которая будет записывать файлы. void file_writer_thread( // Канал из которого будут читаться команды на запись. so_5::mchain_t file_write_ch) { // Читаем все из канала до тех пор, пока канал не закроют. // В этом случае произойдет автоматический выход из receive. receive(from(file_write_ch), // Этот обработчик будет вызван когда в канал попадет // сообщение типа write_data. [&](so_5::mhood_t<write_data> cmd) { // Имитируем запись в файл. std::cout << cmd->file_name_ << ": write started" << std::endl; std::this_thread::sleep_for(350ms); std::cout << cmd->file_name_ << ": write finished" << std::endl; }); }
Все, что делает file_writer_thread() — это висит внутри вызова receive(). Функция receive() ждет поступления сообщения в канал и, когда сообщение в канал поступает, ищет обработчик для этого сообщения среди тех обработчиков, которые переданы в receive().
В данном случае передается всего один обработчик — для сообщения типа write_data. Когда сообщение такого типа поступает в канал, этот обработчик вызывается. Внутри данного обработчика, по сути, собрана вся «бизнес-логика», т.е. имитация записи прочитанных данных в файл.
У функции receive() в SObjectizer есть две версии. Первая версия, которую мы в данном примере не использовали, ждет и извлекает из канала всего одно сообщение. Вторая же версия, которая и показана выше, извлекает из канала все сообщения и возвращает управление только когда канал закрывается. Т.е. в данном случае выход из file_writer_thread() произойдет только когда завершит свою работу вызов receive(). А это случится когда кто-то закроет канал file_write_ch.
Функция meter_reader_thread()
Функция meter_reader_thread несколько сложнее:
// Нить чтения данных с датчика. void meter_reader_thread( // Канал, который нужен этой нити. so_5::mchain_t timer_ch, // Канал, в который будут отсылаться команды на запись файла. so_5::mchain_t file_write_ch) { // Тип для периодического сигнала от таймера. struct acquisition_turn : public so_5::signal_t {}; // Просто счетчик чтений. Нужен для генерации новых имен файлов. int ordinal = 0; // Запускаем таймер. auto timer = so_5::send_periodic<acquisition_turn>(timer_ch, 0ms, 750ms); // Читаем все из канала до тех пор, пока канал не закроют. // В этом случае произойдет автоматический выход из receive. receive(from(timer_ch), // Этот обработчик будет вызван когда в канал попадет // сигнал типа acquire_turn. [&](so_5::mhood_t<acquisition_turn>) { // Имитируем опрос датчика. std::cout << "meter read started" << std::endl; std::this_thread::sleep_for(50ms); std::cout << "meter read finished" << std::endl; // Отдаем команду на запись нового файла. so_5::send<write_data>(file_write_ch, "data_" + std::to_string(ordinal) + ".dat"); ++ordinal; }); }
Здесь мы, во-первых, определяем тип сигнала acquisition_turn, который будет к нам время от времени приходить для того, чтобы мы выполнили имитацию «опроса» датчика.
Во-вторых, мы запускаем этот самый периодический сигнал acquisition_turn посредством вызова send_periodic(). Благодаря этому SObjectizer раз в 750ms будет отсылать acquisition_turn в timer_ch.
Ну а дальше уже знакомый нам вызов receive() из которого мы выйдем только когда канал timer_ch будет закрыт. Внутри receive() у нас реализован обработчик нашего сигнала acquisition_turn. В этом обработчике мы имитируем «опрос» датчика, а затем даем команду на запись «собранных» данных нити file_writer_thread через отсылку сообщения write_data в канал file_write_ch.
Так что получается, что meter_reader_thread спит все время внутри receive(), периодически просыпается при получении acquisition_turn, после чего отсылает сообщение write_data в file_write_ch (т.е. в нить file_writer_thread) и засыпает вновь до следующего acquisition_turn. Либо же пока timer_ch не будет закрыт.
Функция main()
Прежде чем заглянуть в код main(), нужно описать несколько небольших тонкостей, без обсуждения которых может быть непонятна часть этого кода.
Главная проблема, которую приходится решать при работе с нитями и CSP-шными каналами — это корректное и своевременное завершение рабочих нитей. Т.е. если мы создаем экземпляр std::thread и запускаем с его помощью рабочую нить, то мы должны будем затем вызывать std::thread::join() чтобы дождаться завершения рабочей нити (detached threads здесь не используются). Самый простой способ — это вручную вызвать std::thread::join() в конце функции main(). Что-то вроде:
int main() { ... std::thread file_writer{file_writer_thread}; ... file_writer.join(); }
Но плохо то, что такой наивный подход не защищает нас от исключений или других форм преждевременного выхода из скоупа (например, обычный return).
Тут нам мог бы помощь какой-то вспомогательный класс, который бы вызывал std::thread::join() в своем деструкторе. Например, мы могли бы сделать что-то вроде:
class auto_joiner { std::thread & t_; ... // Запрет на копирование/перемещение. public: auto_joiner(std::thread & t) : t_{t} {} ~auto_joiner() { t_.join(); } }; int main() { ... std::thread file_writer{file_writer_thread}; auto_joiner file_writer_joiner{file_writer}; ... }
При использовании SObjectizer нет надобности писать такой auto_joiner самостоятельно, поскольку в SObjectizer уже есть подобный инструмент. Мы как раз увидим его использование в коде main(). От показанного выше от отличается тем, что может вызывать join() не для одного объекта std::thread, а для нескольких.
Но кроме вызова std::thread::join() для корректного останова рабочей нити в нашем примере нужно учесть еще один нюанс: чтобы нить, внутри которой вызван receive(), завершила свою работу, следует закрыть mchain. Если этого не сделать, возврата из receive() не произойдет и мы навечно заснем на вызове std::thread::join().
Это значит, что мы должны позаботится об автоматическом закрытии mchain-ов при выходе из main(). И тут мы применим такой же подход, как и с вызовом std::thread::join(): воспользуемся вспомогательным объектом, который в своем деструкторе вызывает close() для mchain-а. Т.е. мы сделаем что-то вроде:
int main() { ... auto ch = so_5::create_mchain(...); auto_closer ch_closer{ch}; ... }
Опять же, свою реализацию этого вспомогательного класса auto_closer нам делать не нужно, т.к. в SObjectizer уже есть готовая.
Мы уже разобрали как снять с себя заботы по вызову join() для рабочих нитей и автоматического закрытия mchain-ов. Но остался еще один очень важный момент: в каком именно порядке эти операции должны выполняться. Поскольку, если мы напишем вот такую самую простую и понятную последовательность:
int main() { ... auto ch = so_5::create_mchain(...); auto_closer ch_closer{ch}; ... std::thread work_thread{[ch]{ receive(from(ch), ...); }}; auto_joiner work_thread_joiner{work_thread}; ... }
то мы получим классический дедлок и зависание в деструкторе auto_joiner-а.
Проблема в том, что деструктор auto_joiner-а вызывается до деструктора auto_closer-а. Т.е. мы попробуем сделать join для рабочей нити, которая висит на receive() из еще не закрытого mchain-а.
Поэтому для того, чтобы mchain-ы автоматически закрывались до того, как для рабочей нити будет вызван join(), нужно изменить порядок создания сущностей в программе:
int main() { ... // Создаем объект рабочей нити. Но саму рабочую нить пока не стартуем. std::thread work_thread; auto_joiner work_thread_joiner{work_thread}; ... // Теперь можно создать канал для рабочей нити. auto ch = so_5::create_mchain(...); auto_closer ch_closer{ch}; ... // А вот теперь рабочую нить можно запустить. work_thread = std::thread{[ch]{ receive(from(ch), ...); }}; ... }
И вот теперь, после объяснения основных нюансов, можно посмотреть на код самой функции main():
int main() { // Запускаем SObjectizer. so_5::wrapped_env_t sobj; // Объекты-нити создаем заранее специально для того... std::thread meter_reader, file_writer; // ...чтобы можно было создать этот объект joiner. // Именно он будет вызывать join() для нитей при выходе из // main. При этом не важно, по какой причине мы из main выходим: // из-за нормального завершения или из-за ошибки/исключения. auto joiner = so_5::auto_join(meter_reader, file_writer); // Создаем каналы, которые потребуются нашим рабочим нитям. auto timer_ch = so_5::create_mchain(sobj); auto writer_ch = so_5::create_mchain(sobj); // Каналы должны быть автоматически закрыты при выходе из main. // Если этого не сделать, то рабочие нити продолжат висеть внутри // receive() и join() для них не завершится. auto closer = so_5::auto_close_drop_content(timer_ch, writer_ch); // Теперь можно стартовать наши рабочие нити. meter_reader = std::thread(meter_reader_thread, timer_ch, writer_ch); file_writer = std::thread(file_writer_thread, writer_ch); // Программа продолжит работать пока пользователь не введет exit или // пока не закроет стандартный поток ввода. std::cout << "Type 'exit' to quit:" << std::endl; std::string cmd; while(std::getline(std::cin, cmd)) { if("exit" == cmd) break; else std::cout << "Type 'exit' to quit" << std::endl; } // Просто завершаем main. Все каналы будут закрыты автоматически // (благодаря объекту closer), все нити также завершаться автоматически // (благодаря объекту joiner). return 0; }
Надеюсь, что в основном этот код понятен. И пояснения могут потребоваться разве что для двух небольших моментов.
Во-первых, это создание экземпляра so_5::wrapped_env_t в начале main-а. За этим экземпляром будет скрываться SObjectizer Environment. А SObjectizer Environment нам нужен как для создания mchain-ов, так и для обслуживания таймеров (вызов send_periodic() в meter_reader_thread скрывает в себе обращение к SObjectizer-овскому таймеру).
Во-вторых, это вызов auto_close_drop_content. С одной стороны, с ним понятно: данная функция возвращает объект auto_closer, который автоматически закроет mchain-ы в своем деструкторе. Но, с другой стороны, что значит drop_content в названии этой функции?
Дело в том, что в SObjectizer закрыть mchain можно в двух режимах. В первом режиме mchain закрывается с выбрасыванием всех находящихся в mchain-е сообщений, которые еще не были обработаны функциями receive(). Например, на момент вызова close() в mchain находится 100500 сообщений. Все эти сообщения будут уничтожены и к получателям они не попадут. Этот режим называется drop_content и функция auto_close_drop_content как раз создает auto_closer, который закроет mchain в режиме drop_content.
Второй режим закрытия mchain-а, напротив, сохраняет все сообщения в mchain-е. Что дает возможность функциям receive() завершить обработку содержимого mchain. Но вот новые сообщения в mchain добавить будет уже нельзя, т.к. mchain уже закрыт (для записи). Такой режим называется, соответственно, retain_content.
Оба режима закрытия mchain-ов, drop_content и retain_content, хороши в разных ситуациях. В данном примере нам нужен drop_content, поэтому-то и используется auto_close_drop_content.
Результат работы первого примера
Если мы запустим наш первый пример, то увидим вполне ожидаемую картину:
Мы тут видим последовательные «опросы» и «запись» результатов этих «опросов».
Усложнение простого примера: контролируем нагрузку на file_writer_thread
Полный исходный текст второго примера может быть найден здесь.
Первая версия нашего примера получилась очень уж идеализированной: мы верим в то, что запись «снятых» с датчика данных всегда будет завершаться к следующему «опросу». Но в реальной жизни, скорее всего, время операций с внешними устройствами может «плавать» в довольно широких пределах. Это означает, что нам имело бы смысл позаботиться о ситуации, когда «запись» в файл займет больше времени и в mchain-е с сообщениями write_data начнут скапливаться сообщения.
Для того, чтобы проимитировать подобную ситуацию слегка модифицируем уже показанные выше функции meter_reader_thread() и file_writer_thread(). В meter_reader_thread() всего лишь увеличим темп поступления сигнала acquisition_turn:
auto timer = so_5::send_periodic<acquisition_turn>(timer_ch, 0ms, 300ms);
А вот в file_writer_thread() сделаем так, чтобы время операции «записи» выбиралось случайным образом из диапазона [295ms, 1s]. Т.е. иногда операция «записи» будет укладываться в интервалы между «опросами», но в большинстве случаев — не будет. Иногда не будет укладываться очень сильно. Итак, вот как мы модифицируем file_writer_thread():
// Нить, которая будет записывать файлы. void file_writer_thread( // Канал из которого будут читаться команды на запись. so_5::mchain_t file_write_ch) { // Вспомогательные инструменты для генерации случайных значений. std::mt19937 rd_gen{std::random_device{}()}; // Значения для задержки рабочей нити будут браться из // диапазона [295ms, 1s]. std::uniform_int_distribution<int> rd_dist{295, 1000}; // Читаем все из канала до тех пор, пока канал не закроют. // В этом случае произойдет автоматический выход из receive. receive(from(file_write_ch), // Этот обработчик будет вызван когда в канал попадет // сообщение типа write_data. [&](so_5::mhood_t<write_data> cmd) { // Выбираем случайную длительность операции "записи". const auto pause = rd_dist(rd_gen); // Имитируем запись в файл. std::cout << cmd->file_name_ << ": write started (pause:" << pause << "ms)" << std::endl; std::this_thread::sleep_for(std::chrono::milliseconds{pause}); std::cout << cmd->file_name_ << ": write finished" << std::endl; }); }
Получается, что теперь в file_write_ch могут скапливаться необработанные сообщения write_data. Возникает широко известная в узких кругах проблема перегрузки: это когда поставщик данных генерирует новые данные с большим темпом, нежели потребитель данных способен обработать. Проблема неприятная, с ней нужно бороться.
Например, можно реализовать механизм «back pressure». Т.е. когда поставщик данных начинает перегружать потребителя, то потребитель тем или иным способом дает поставщику об этом знать. В случае CSP-шных каналов вполне естественным способом реализации «back pressure» будет блокировка поставщика данных на операции записи в канал до тех пор, пока потребитель не освободится настолько, чтобы принять следующую порцию данных от поставщика.
Кстати говоря, в этом плане Модель CSP в каких-то сценариях обработки данных сильно удобнее Модели Акторов. Ведь в Модели Акторов обмен данными между поставщиком и потребителем осуществляется только посредством асинхронных сообщений. Т.е. поставщик, отсылая очередное сообщение потребителю, не знает, насколько потребитель нагружен, приведет ли очередное сообщение к перегрузке и, если приведет, то сколько времени нужно подождать, прежде чем отсылать следующее сообщение. Тогда как в Модели CSP поставщика можно «усыпить» на операции записи в канал и «разбудить» поставщика после того как потребитель разобрался со своей нагрузкой.Итак, мы бы хотели, чтобы поставщик, т.е. meter_reader_thread в нашем случае, засыпал, если file_writer_thread не успевает разбирать и обрабатывать ранее отосланные в file_write_ch сообщения. Могут ли SObjectizer-овские mchain-ы это нам обеспечить?
Да.
Для этого нужно задать дополнительные свойства mchain-а при создании mchain-а. В первой версии нашего примера мы создавали mchain самым простым способом, вот так:
auto writer_ch = so_5::create_mchain(sobj);
В этом случае создается «безразмерный» канал, в такой канал можно запихнуть столько сообщений, сколько позволяет размер свободной оперативной памяти.
Поскольку мы хотим «back pressure», то «безразмерный» канал нас не устраивает. Значит нам нужно ограничить количество сообщений, которые могут ждать в канале своей обработки.
Мы хотим так же, чтобы при попытке записи в заполненный канал поставщик информации «засыпал». С этим нет проблем, но в SObjectizer-е нужно задать верхнюю границу такого ожидания. Например, заснуть на попытке записи в канал, но спать не более пяти секунд (или пяти часов, это от задачи зависит).
SObjectizer требует от разработчика ограничить максимальное время ожидания на запись в заполненный канал потому, что без такого ограничения легко поймать дедлок. Скажем, нить T1 пытается записать сообщение в переполненный канал C1 для нити T2, которая в этот момент пытается записать сообщение в переполненный канал C2 для нити T3. А нить T3 в этот момент пытается записать сообщение в переполненный канал C0 для нити T1. В случае с ограничением на максимальное время ожидания такой дедлок будет со временем разорван автоматически.
Итак, мы задаем размер канала и максимальное время ожидания, но остается вопрос: «Что делать с операцией записи в переполненный канал, если место в канале не освободилось даже после ожидания?»
В SObjectizer можно выбрать, что делать, если место в канале не освободилось даже после ожидания. Например, можно выбросить самое старое сообщение, которое находится в канале. Или можно проигнорировать новое сообщение, которое мы попытались вставить в канал. Или можно сделать так, чтобы функция send() бросила в этом случае исключение.
В нашем примере мы используем такую реакцию, как выбрасывание самого старого сообщения. В данном случае это вполне логично, т.к. у нас уже есть «новые данные» с датчика, их запись актуальнее, чем сохранение старых данных. Поэтому в обновленном примере мы будем создавать канал для сообщений write_data следующим образом:
// Канал для записи измерений будет ограничен по размеру, с паузой // при попытке записать в полный mchain и с выбрасыванием самых старых // команд, если канал даже после паузы не освободился. auto writer_ch = so_5::create_mchain(sobj, // Ждем освобождения места не более 300ms. 300ms, // Ждать в mchain-е могут не более 2-х сообщений. 2, // Память под mchain выделяем сразу. so_5::mchain_props::memory_usage_t::preallocated, // Если место в mchain-е не освободилось даже после ожидания, // то выбрасываем самое старое сообщение из mchain-а. so_5::mchain_props::overflow_reaction_t::remove_oldest);
Дополнительное пояснение можно дать разве что аргументу so_5::mchain_props::memory_usage_t::preallocated. Этот аргумент определяет, как будет выделяться память для организации очереди сообщений внутри самого канала. Т.к. канал у нас имеет фиксированный и небольшой размер, то место под очередь сообщений имеет смысл выделить сразу. Что мы и делаем в данном случае.
Ограничение для канала нити meter_reader_thread
Во втором примере мы ограничили размер канала для сообщений write_data. Но ведь у нас так же есть канал для сигналов acquisition_turn. Может имеет смысл его также ограничить?
Действительно, смысл есть. Нам вообще достаточно для acquisition_turn иметь канал емкостью в одно сообщение. Если сигнал acquisition_turn в канале уже есть, то новый добавлять туда нет смысла.
Поэтому мы модифицируем фрагмент кода, в котором мы создаем этот канал:
// Канал для периодических сигналов будет ограничен по размеру, // без паузы при попытке записать в полный mchain и с выбрасыванием // самых новых сообщений. auto timer_ch = so_5::create_mchain(sobj, // Отводим место всего под одно сообщение. 1, // Память под mchain выделяем сразу. so_5::mchain_props::memory_usage_t::preallocated, // Если канал полон, то самое новое сообщение игнорируется. so_5::mchain_props::overflow_reaction_t::drop_newest);
Мы здесь видим два важных отличия:
- во-первых, нет ожидания на попытке добавить сообщение в заполненный канал. Это ожидание лишено смысла. Кроме того, т.к. acquisition_turn помещается в канал таймером SObjectizer-а. А этот таймер в принципе не может «засыпать» на попытке добавить сообщение в полный канал (иначе таймер не сможет нормально выполнять свою работу);
- во-вторых, в качестве реакции на переполнение мы предписываем игнорирование самого нового сообщения. Т.е. если таймер попробует добавить новый экземпляр сигнала acquisition_turn в полный канал, то этот новый экземпляр будет проигнорирован, как будто его и не было вовсе.
Результат работы второго примера
При запуске второго примера мы уже можем увидеть следующую картину:
Можно увидеть, что часть номеров из отладочной печати нити file_writer_thread исчезла. Например, после записи data_24.dat следует запись data_26.dat. А записи data_25.dat нет. Это потому, что сообщение write_data для data_25.dat было выброшено из канала при его переполнении.
Кроме того, мы можем видеть, что когда нить file_writer_thread надолго «уходит» в запись, то за это время нить meter_reader_thread успевает провести несколько «опросов».
Усложняем пример еще раз: добавляем управление meter_reader_thread
Полный исходный текст третьего примера может быть найден здесь.Нельзя отказать себе в соблазне усложнить пример еще раз: на этот раз добавить возможность управлять нитью meter_reader_thread. Действительно, почему бы не сделать возможность увеличивать или уменьшать период «опроса» датчика? Давайте это и сделаем.
Пусть главная нить сейчас в процессе диалога с пользователем понимает не только команду 'exit' (завершить работу приложения), но и команды 'inc' (удлинить период опроса в 1.5 раза) и 'dec' (сократить период опроса в 1.5 раза).
Главный вопрос, который нам в этом случае предстоит решить — это вопрос доставки команд inc и dec из главной нити приложения в нить meter_reader_thread. Но на самом деле — это не вопрос. Мы просто заведем два новых сигнала:
// Сигнал, который отсылается нити чтения данных с датчика для // уменьшения периода опроса. struct dec_read_period : public so_5::signal_t {}; // Сигнал, который отсылается нити чтения данных с датчика для // увеличения периода опроса. struct inc_read_period : public so_5::signal_t {};
Главная нить будет отсылать эти сигналы в соответствующий канал, когда пользователь вводит ту или иную команду:
// Программа продолжит работать пока пользователь не введет exit или // пока не закроет стандартный поток ввода. bool stop_execution = false; while(!stop_execution) { std::cout << "Type 'exit' to quit, 'inc' or 'dec':" << std::endl; std::string cmd; if(std::getline(std::cin, cmd)) { if("exit" == cmd) stop_execution = true; else if("inc" == cmd) so_5::send<inc_read_period>(control_ch); else if("dec" == cmd) so_5::send<dec_read_period>(control_ch); } else stop_execution = true; }
Но в какой именно канал мы будем отсылать эти сигналы? Вот этот вопрос гораздо интереснее.
В принципе, мы могли бы использовать один и тот же канал и для периодических acquisition_turn, и для inc_/dec_read_period. Но для того, чтобы показать, что еще умеет SObjectizer при работе с mchain-ами, мы будем использовать два разных канала для meter_reader_thread:
- первый канал, под условным названием control_ch, будет использоваться для команд inc_/dec_read_period. Это будет самый простой mchain без каких-либо ограничений;
- второй канал, под условным названием timer_ch, будет использоваться для сигналов acquisition_turn. Это уже будет канал с фиксированным размером и политикой игнорирования новых сообщений при переполнении.
Для простоты реализации третьего примера оба эти канала будут создаваться и закрываться в функции main(), а в функцию meter_reader_thread() они будет передаваться как параметры:
// Создаем каналы, которые потребуются нашим рабочим нитям. // Управляющий канал для meter_reader_thread. Без каких-либо ограничений. auto control_ch = so_5::create_mchain(sobj); // Канал, который будет использоваться для отсылки acquisition_turn. auto timer_ch = so_5::create_mchain(control_ch->environment(), // Отводим место всего под одно сообщение. 1, // Память под mchain выделяем сразу. so_5::mchain_props::memory_usage_t::preallocated, // Если канал полон, то самое новое сообщение игнорируется. so_5::mchain_props::overflow_reaction_t::drop_newest); ... // Каналы должны быть автоматически закрыты при выходе из main. // Если этого не сделать, то рабочие нити продолжат висеть внутри // receive() и join() для них не завершится. auto closer = so_5::auto_close_drop_content(control_ch, timer_ch, writer_ch); // Теперь можно стартовать наши рабочие нити. meter_reader = std::thread(meter_reader_thread, control_ch, timer_ch, writer_ch); ...
Модифицированная версия функции meter_reader_thread()
Функция meter_reader_thread() существенно вырастет в размере, поскольку теперь она должна выполнять больше действий. И хотя мне самому не очень нравятся функции, текст которых не умещаются на один экран, в данном случае пришлось пойти на написание такой объемной функции, дабы не размазывать фрагменты бизнес-логики по вспомогательным функциям.
По сравнению с первым и вторым примерами, в третьем примере в meter_reader_thread произошло два принципиально важных изменения.
Во-первых, теперь период «опроса» датчика может изменяться. Из-за этого нам невыгодно запускать acquisition_turn в качестве периодического сообщения. Придется каждый раз перезапускать его при изменении периода. Поэтому сейчас мы пойдем другим путем: при обработке очередного acquisition_turn будем засекать время, потраченное на очередной «опрос» и отсылку write_data. После чего либо сразу будем отсылать себе acquisition_turn без задержки, если потратили на «опрос» слишком много времени. Либо же будем отсылать отложенное acquisition_turn, при этом задержка в доставке будет дельтой между текущим периодом опроса и реально затраченным временем.
У нас получится следующий фрагмент по обработке acqusition_turn:
// Этот обработчик будет вызван когда в канал попадет // сигнал типа acquire_turn. [&](so_5::mhood_t<acquisition_turn>) { // Нам потребуется узнать, сколько времени мы потратили на // всю операцию. Поэтому делаем засечку. const auto started_at = std::chrono::steady_clock::now(); // Имитируем опрос датчика. std::cout << "meter read started" << std::endl; std::this_thread::sleep_for(50ms); std::cout << "meter read finished" << std::endl; // Отдаем команду на запись нового файла. so_5::send<write_data>(file_write_ch, "data_" + std::to_string(ordinal) + ".dat"); ++ordinal; // Теперь можем вычислить сколько же всего времени было // потрачено. const auto duration = std::chrono::steady_clock::now() - started_at; // Если потратили слишком много, то инициируем следующий // опрос сразу же. if(duration >= current_period) { std::cout << "period=" << current_period.count() << "ms, no sleep" << std::endl; so_5::send<acquisition_turn>(timer_ch); } else { // В противном случае можем позволить себе немного "поспать". const auto sleep_time = to_ms(current_period - duration); std::cout << "period=" << current_period.count() << "ms, sleep=" << sleep_time.count() << "ms" << std::endl; so_5::send_delayed<acquisition_turn>(timer_ch, current_period - duration); } }
Во-вторых, нам теперь придется ждать сообщения не из одного канала, а из двух сразу. В какой канал сообщение первым пришло, из такого мы должны взять сообщение и обработать взятое сообщение.
Для этого мы будем использовать функцию so_5::select(), которая похожа на ранее показанную so_5::receive(). Но, в отличии от receive(), функция select() может ждать входящие сообщения из нескольких каналов.
В итоге, в meter_reader_thread мы делаем вот такой вызов select() (схематично, опуская детали реализаций обработчиков):
// Читаем все из каналов до тех пор, пока каналы не закроют. so_5::select(so_5::from_all(), // Обработчик для сигналов от таймера. case_(timer_ch, // Этот обработчик будет вызван когда в канал попадет // сигнал типа acquire_turn. [&](so_5::mhood_t<acquisition_turn>) { ... // Код обработчика. }), // Обработчик сигналов из управляющего канала. case_(control_ch, // Обрабатываем увеличение интервала опроса. [&](so_5::mhood_t<inc_read_period>) { ... // Код обработчика. }, // Обрабатываем уменьшение интервала опроса. [&](so_5::mhood_t<dec_read_period>) { ... // Код обработчика. }) );
Т.е. мы говорим, что select() должен ждать сообщения из всех ниже перечисленных каналов до тех пор, пока все каналы не будут закрыты. Затем, в секциях case_ идет перечисление каналов (по одному каналу на секцию) и список обработчиков для сообщений из каждого канала.
Так, из канала timer_ch мы обрабатываем только сигнал acquisition_time, а из канала control_ch — сигналы inc_read_period и dec_read_period.
Получается, что в третьем примере функция meter_read_thread() возвращает управление только после того, как управление возвращает select(). А select() завершает свою работу когда и timer_ch, и control_ch будут закрыты. Что происходит в main()-е при завершении работы приложения.
Результат работы третьего примера
При запуске третьего примера и выдачи нескольких команд inc мы можем увидеть следующую картину:
Заключение
Мы развиваем SObjectizer как инструмент для упрощения разработки многопоточных приложений, а не как реализацию какого-то одного подхода к проблеме concurrent computing. Поэтому в SObjectizer можно найти следы и Модели Акторов, и Publish/Subscribe, и CSP. Ранее мы больше рассказывали именно про ту часть SObjectizer-а, которая относится к моделям Акторов и Pub/Sub. Сегодня же мы попытались коротко познакомить читателя и с CSP-шными каналами. Это уже вторая попытка, первая была в прошлом году.
Если в нашем рассказе что-то осталось непонятным, то мы с удовольствием ответим на вопросы в комментариях. Если кто-то хочет, чтобы мы проиллюстрировали что-то из рассказанного картинкой/схемой, то скажите что именно — мы постараемся сделать соответствующую иллюстрацию и добавить ее в текст.
Вполне возможно, что показанный пример кому-то покажется неинтересным и оторванным от жизни. Все-таки нашей целью была его понятность. Но, если кто-то из читателей сможет предложить другой, более жизненный пример для того, чтобы проиллюстрировать его решение с помощью CSP-шных каналов, то мы попробуем сделать решение предложенного читателями примера и описать это решение в последующих статьях.
Ну а в завершение статьи предлагаем всем желающим попробовать SObjectizer в деле и поделиться своими впечатлениями. Обратная связь для нас очень важна и именно ваши пожелания/замечания позволяют нам развивать SObjectizer и делать его мощнее и удобнее.

