
Задача фото-фиксации грузов на различных этапах транспортировки является типовой для транспортной компании. Сотрудники компании фотографируют груз, загружают изображение в ERP-систему, из которой он попадает в электронный архив (ЭА). Каждая фотография сопровождается метаинформацией: отделение отправитель, получатель, код и индекс рейса, и т.д. Основная задача электронного архива – организация гибкого, удобного и, главное, быстрого поиска фотографий по метаинформации за последние 3 года.
Как это часто бывает, нашелся поставщик, который предложил коробочное решение — гибкую ЕСМ-систему на платформе Alfresco Community Edition 4.2.x, достаточно быстро внедрил ее и даже прошел успешное испытание на одном филиале. И они даже MS SQL Server прикрутили к Community Edition. Насчет протокола взаимодействия с ERP, в нашем случае это 1С, никто особо не задумывался, заказчик пожелал максимально удобный для себя способ — выгружать файлы в папку на сервере, поэтому стали использовать старый добрый FTP.
Хьюстон, у нас проблемы…
Самое интересное началось потом, когда запустили тиражирование на 120 филиалов. Система регулярно зависала по причине не валидных индексов Lucene. При возникновении данной ситуации приходилось вручную перестраивать индексы, что приводило к недоступности системы на сутки. А для логистической компании федерального масштаба — это довольно критичный срок. Во время перестройки файлы оставались на шаре, и с каждым сбоем прогружать “убегающую” дельту было всё сложнее. Максимум файлов, которые мы могли принять в день, для нас составлял 40-60 тысяч. Веб-интерфейс также не отличался высокой скоростью поиска: максимальное количество пользователей при работающей загрузке составляло 20 человек. Про масштабируемость и вовсе упоминать не стоит — система не справлялась с текущими объемами. Встал вопрос о правильности выбора платформы. И на этом этапе началось наше сотрудничество с данным заказчиком.
Документации на систему не было, но реверс инжиниринг никто не отменял. Разобрались в коде, нашли ошибки и множество костылей, по которым понятно, что система просто не была готова к высоким нагрузкам: файлы сначала складировались на сервере, после этого, самописный шедулер просматривает целевую папку, загружал файлы в память и после обрабатывал их. Само собой тюнинг механизмов Alfresco тоже никто не делал. Например, при загрузке файлов можно было разносить действия с документами по разным транзакциям. Но, к сожалению, управлением транзакциями никто не занимался.
И тут мы допустили роковую ошибку — мы начали доделывать существующую систему.
Нам удалось запуститься на всех 120 филиалах, и несколько месяцев мы тюнинговали систему, в которой работают пользователи. Пытались оптимизировать работу Lucene, меняли размеры одного файла, параметры запуска слияния индексов, изменяли параметры Java машины и т.д.
За это время объемы выросли в разы до 100 тысяч документов в день, размер индексов увеличился до критической отметки в 100 гб, после которой, даже стандартное перестроение индексов, которое раньше нас выручало, уже завершалось не всегда успешно — процесс повисал на этапе слияния. И мы поняли — дальше так жить нельзя! Было решено полностью переписать решение. Кто же не любит бросить старое плохое и чужое решение и с высоты пережитого опыта написать свое хорошее? Но задача осложнялась тем, что нужно было поддерживать работу существующего решения, пока разрабатываем новое, а потом еще сделать миграцию данных. Задача казалась реалистичной, и настроены мы были оптимистично.
Вид сверху: архитектура решения
Весь код был переписан на java (часть бэкенд-кода была написана на встроенном в Alfresco JavaScript). Также было принято решение поменять основную СУБД c MS SQL на Postgresql (фактически это первое что приходит на ум, когда мы говорим про свободно-распространяемые реляционные БД). Полностью переделана архитектура решения. Полностью отказались от использования интерфейса Alfresco Share, разработали удобный кастомизированный веб-интерфейс, который обращается к разработанными нами веб-сервисам для получения данных. Теперь Alfresco служит в качестве REST API. Добавлена репликация основной БД встроенными средствами Postgresql, что позволило строить отчеты с репликации, не нагружая основную БД. Поиск и загрузка данных разнесена на 2 сервера. Были развернуты 2 копии Alfresco вместо одной: одна отвечает за поиск данных и их отображение, другая — за загрузку.
Обе копии Alfresco используют одну и ту же базу. За счёт разделения загрузки и просмотра, длительные операции при загрузке не влияют на просмотр данных, также просмотр и загрузка могут работать независимо друг от друга. В конечном итоге это добавило производительности системе. Пропускная способность системы выросла и позволяла загружать до 200к фотографий в день, а количество одновременных пользователей увеличилось до 70-80.
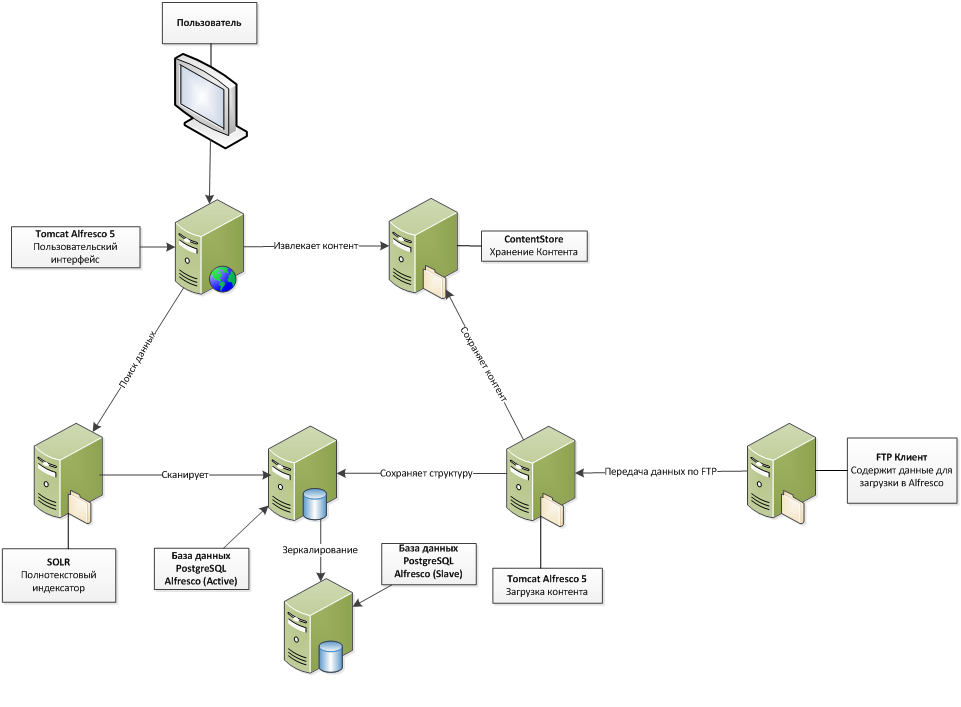
Рисунок 1. Архитектура решения
Ускоряем загрузку
Для того чтобы оптимизировать производительность системы мы:
- Переработали механизм загрузки файлов по FTP;
- Распараллелили обработку XML файлов;
- Использовали новый поисковый движок, встроенный в Alfresco 5.
FTP
Был переработан механизм загрузки файлов по FTP. Был реализован виртуальный FTP-сервер через Apache FTPServer. Так как у нас обычный maven проект, мы можем подключать любые библиотеки. Теперь файлы не складируется на сервере, а обрабатываются сразу при поступлении, в зависимости от папки назначения определяется тип документа. Это значительно повысило производительность.
Сразу скажу, что CMIS не использовали, потому что для заказчика было важно взаимодействие с системой через FTP.
Обработка XML
Также распараллелили обработку маленьких блоков xml файлов, вручную определили начало и конец транзакции, по умолчанию, все действия с нодами (так называются все объекты в Alfresco) выполняются в одной транзакции.
Новый поисковый движок
Переход на Alfresco 5 обеспечил более надежный поисковый движок. В нашей структуре данных необходимы консистентные запросы, то есть при загрузке могут потребоваться объекты, которые были загружены секунду назад. SOLR такие запросы не поддерживает, так как ему необходимо время на перестройку своих индексов. Ранее в Alfresco 4 данные запросы поддерживались через Lucene, но как описано ранее, он имеет свои проблемы. В Alfresco 5 такие запросы выполняются напрямую в БД (запрос трансформируется в HQL запрос, который в свою очередь трансформируется в SQL в зависимости от указанного диалекта). Данное нововведение значительно повысило скорость загрузки и отказоустойчивость системы.
Вкалывает робот: распознавание штрих-кодов
Поступила задача на внедрение системы распознавания штрих-кодов. Так как фотографии обрабатываются и сохраняются сразу, задача решилась простой установкой библиотеки Zbar на сервер загрузки. Был реализован пул запущенных процессов Zbar, размер пула равен количеству ядер на сервере (количество потоков регулируется отдельно). При загрузке фотографии, фото сначала «прогоняется» через Zbar, в ответе от него получаем распознанный штрих-код (в виде строки), и если в системе загружен документ, в метаданных которого присутствует данный штрих-код, то такой документ привязывается с фотографией, что в дальнейшем позволяет увидеть фотографию на веб-интерфейсе при поиске документа.
Контролируем полет: приборы
После переноса на Alfresco 5, а также переписывания исходников стало возможным нормально поддерживать и развивать систему, добавляя новый функционал. Первым делом после оптимизации загрузки необходимо было решить вопрос с мониторингом систем. Размер хипа, дисковая активность и прочие стандартные показатели поставили на мониторинг через Zabbix средствами JMX. Оставался вопрос с мониторингом прикладных метрик: скорость загрузки, скорость отклика REST API Alfresco, количество активных пользователей и т.д. Для решения данной задачи был написан JMX bean, собирающий количество пользователей и имеющие активные тикеты.

Для мониторинга загрузки и отклика веб-интерфейса были написаны 2 веб-сервиса, которые вызываются заббиксом:
Возвращающий количество (загруженных файлов или количество обращений в REST API)
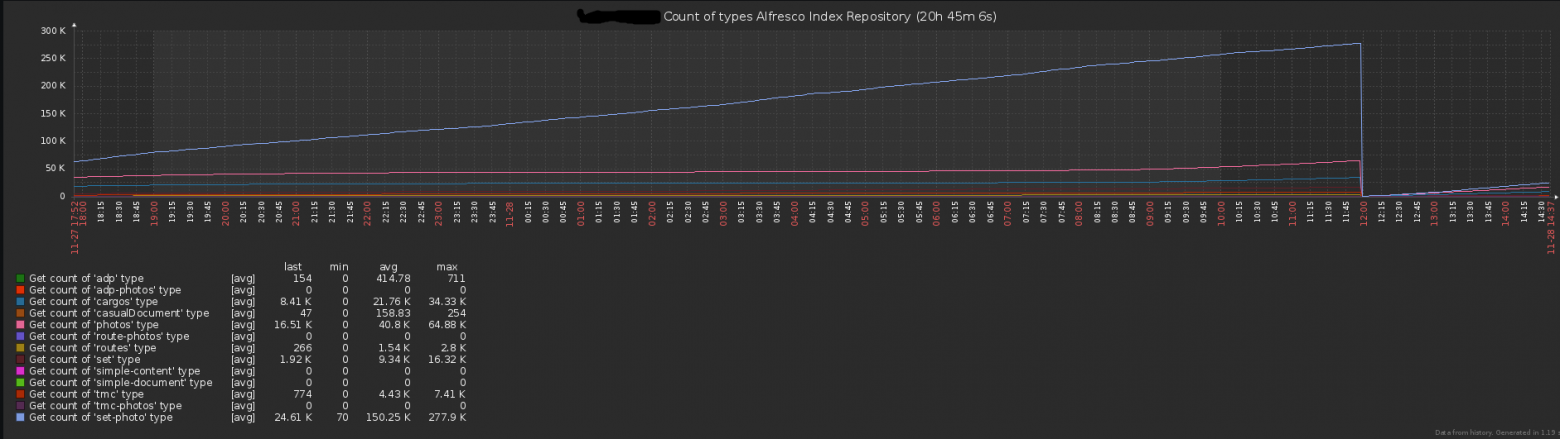
Рисунок 2. Количество загружаемых файлов
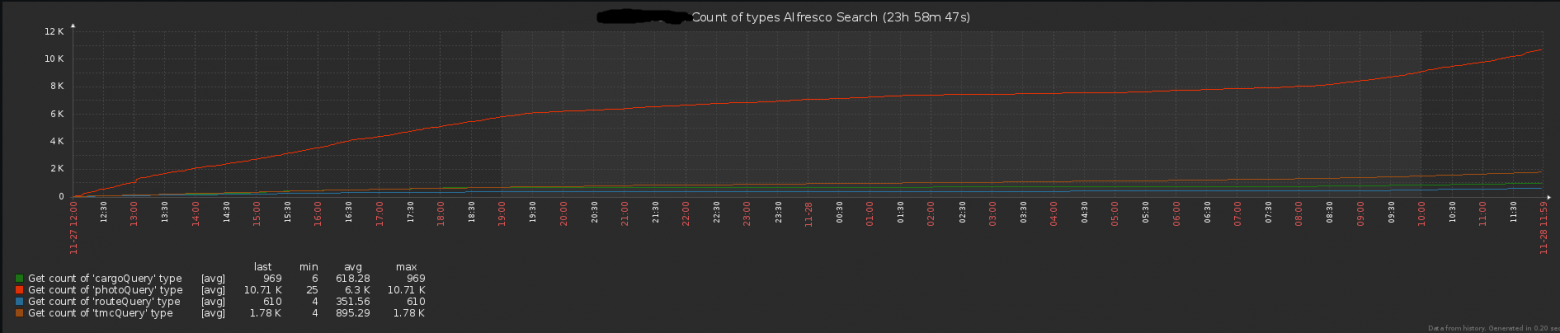
Рисунок 3. Количество запросов в REST API
Возвращающий среднее время (в миллисекундах)

Рисунок 4. Время ответа REST API
Рисунок 5. Время загрузки файлов
Тип запрашиваемого объекта передается в виде get параметра.
Космическая одиссея продолжается
Собственные оптимизации и доработки системы и переход на Alfresco 5 позволили увеличить пропускную способность загрузки до 400 000 фотографий в день, с учетом того, что 300 000 из них проходят через систему распознавания. Также среднее количество активных пользователей, на настоящий момент, возросло до 120. Это все при условии того, что размер базы составляет около 700GB и суммарный размер контента 19TB. У нас в системе более 90 000 000 документов!
Alfresco Community Edition можно использовать в качестве платформы для Электронного Архива. Большие, масштабные космические экспедиции ей по плечу. Но, важно отметить, что успех экспедиции зависит от качества подготовительных работ предшествующих запуску и слаженной работе экипажа во время сопровождения.
А наш полет продолжается, но уже на других скоростях!
В дальнейшем мы планируем еще больше оптимизировать веб-интерфейс: сделать так называемую ленивую загрузку объектов, что позволит ускорить операции поиска, и оптимизировать экранные формы с точки зрения пользовательского опыта. (User Experience) Также мы планируем реализовать управление жизненным циклом документа, в частности сделать архивирование документов на медленные носители.

