

У нас есть набор систем хранения как традиционных, так и программно определяемых. Они используются в формате блочных хранилищ для хранения виртуальных машин, баз данных и других ресурсов.
На втором этапе мы стали использовать объектное хранение, то есть хранение без иерархии каталогов. Все данные лежат на одном уровне, и каждый файл может быть доступен по своему ключу. Метаданные хранятся рядом с файлом. Для доступа используются простые команды уровня PUT — GET — MODIFY, есть возможность обратиться к каждому файлу по собственному URI, обеспечены лёгкость управления правами и лёгкость размещения самых разных данных и доступа к ним.
Минус данных решений — невозможность обращения к части (сегменту) файла, поэтому для приложений вроде баз данных такие хранилища не используются. Оптимальное применение — сложить туда картинки веб-сайта, файловую помойку, архивы или бэкап данных. На базе объектного хранилища мы построили свой S3 — систему хранения не очень часто изменяемых данных. С прямой совместимостью с Amazon S3.
А ещё классические протоколы доступа, использующиеся внутри компаний для файлового доступа (CIFS или NFS), не предназначены для обмена большими данными через сеть Интернет. Это ещё одна из причин, почему и зачем мы создали своё объектное хранилище.
Стояла задача сделать его не просто работающим отовсюду, но и дешёвым.
С чего началось
Когда заказчики начали массово мигрировать с западных облачных провайдеров в Россию, была очень востребована совместимость с Amazon API. В частности, для хранения данных. У очень многих прикладное ПО было написано для работы с объектными хранилищами и пользовалось их универсальностью, то есть работало с файлами как файлами и не особо заморачивалось, откуда они приходят и где лежат. Естественно, переписывать свой софт из-за нового облачного провайдера никто не торопился. Поэтому была нужна объектная система хранения данных.
Процесс развития портфеля услуг можно сравнить со строительством дома. Сначала закладывается фундамент, необходимый для твёрдой основы и последующего строительства комнат, этажей, балкона, гаража и т. д. Так же и портфель услуг формируется постепенно. С появлением новых услуг всё чаще появлялись вопросы по организации хранения. Заказчики спрашивали:
— У нас отчётность хранится годами. Можно что-то придумать, чтобы хранить её дешевле?
— Мы используем write-only-бэкап. В смысле за пять лет его ни разу не использовали. Можно его хранить дешевле?
— А можно бэкап пойдёт автоматически, но храниться будет не в общей хранилке?
— А у вас можно просто хранить данные? А то у нас есть фотобанк для маркетинга, который…
И внутренний вопрос был в том, можно ли сделать горизонтально масштабируемую платформу. Для решения мы сделали отдельное хранилище, которое ориентировано на низкую стоимость хранения, доступ к данным как изнутри облака Техносерв, так и через Интернет. Ещё решение имеет интерфейс предоставления доступа, уже принятый рынком, имеющий поддержку в продуктах, используемых нашими заказчиками. Читай — S3. Потому что были реальные запросы.
Нативная S3-совместимость
Объектное хранилище — это способ хранения данных без иерархии, который обычно используется в облачной среде. В отличие от других способов хранения данных, объектное хранилище не использует иерархию каталогов. Отдельные единицы данных (объекты) сосуществуют в пуле данных на одном уровне. Каждый объект имеет уникальный идентификатор, используемый приложением для обращения к нему. Кроме того, каждый объект может содержать метаданные, получаемые вместе с ним.
Рассматривались как опенсорсные, так и коммерческие решения. Всего было опробовано (проведено стендирование и тестирование основных функций) шесть с половиной решений. В итоге выбрали Cloudian HyperStore. Вот почему.
- Гарантированная производителем 100%-я совместимость с протоколом Amazon S3 API. Cloudian гарантирует, что HyperStore имеет 100%-ю совместимость с API Amazon S3, и это позволяет нашим заказчикам, которые ранее использовали сервисы хранения Amazon или имеют решения, поддерживающие работу по S3, использовать наш сервис без каких-либо доработок или корректировок программного обеспечения.
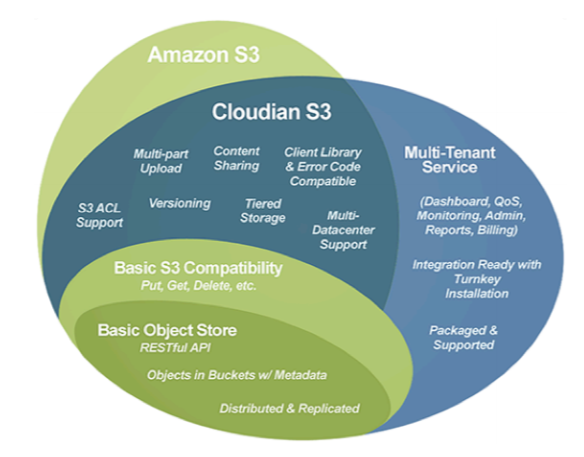
- Масштабирование. HyperStore позволяет создать децентрализованную облачную платформу хранения данных с возможностью гранулярного управления различными политиками, например, отчётности и администрирования. Решение способно масштабироваться до тысяч узлов и миллиардов объектов в одной корзине и в кратчайшие сроки может быть гибко масштабировано до требуемого количества петабайтов.
- Безопасность и шифрование. HyperStore даёт шифровать данные при передаче и хранении. Предусмотрены функционал настройки прав доступа и логирование всех операций с файлами, а также возможность шифрования данных на стороне хранилища ключом клиента.
- Поддержка изолированных доменов (MULTI-TENANCY). Надо передавать управление ресурсами заказчику, потому что это повышает скорость исполнения базовых операций (например, завести нового пользователя, оценить объём потребляемых ресурсов и т. д.) и снижает нагрузку на службу эксплуатации, которой не надо отвлекаться на простые операции. Изначальная поддержка изолированных доменов в продукте позволяет обеспечить безопасное разделение ресурсов между клиентами и гарантировать, что пользователи не смогут своими действиями повлиять на работу других клиентов. В смысле нам не надо забивать костыли в код, и это прекрасно.
- Управление уровнем сервиса (QoS). Для каких-то клиентов требуется выделить гарантированную полосу или поток операций для соблюдения работы их сервисов, а у кого-то, наоборот, нет требований, да ещё и неоптимизированный сервис является очень «голодным» и будет «кушать» столько, сколько сможет получить.
- Динамическое резервирование с использованием Реплик и ERASURE CODING. HyperStore поддерживает несколько уровней резервирования с использованием Реплик и Erasure Coding (ЕС).

Количество реплик задаётся самостоятельно и может достигать трёх. ЕС позволяет задавать уровень резервирования в довольно широком диапазоне и дополнительно регулировать требуемый уровень надёжности.

Уровень защиты задаётся гранулярно, то есть на определённый сегмент данных, нет ограничения, что на всю систему требуется выбрать единую политику защиты. По умолчанию для нашей системы выбрана политика резервирования 5+3, что связано с текущей конфигурацией нашей платформы.
Гранулярность защиты очень удобна для эксплуатации. К примеру, у нас есть заказчик, который размещает десяток миллионов ну очень маленьких файлов (буквально 10–30 Кб каждый), в случае использования ЕС мы столкнулись с большим ростом метаинформации и проседанием части операций для этих данных. Перевод защиты с использованием копий позволил исправить ситуацию и снизить общую нагрузку на систему (в части операций данного заказчика).
А что со стоимостью?
Ниже Amazon, начиная с определённого объёма потребления. То есть для среднего и крупного бизнеса — выгоднее западных решений.
Платформа стала базовой для части наших сервисов. Она существует как самостоятельная услуга для внешних заказчиков STaaS (Storage as a Service, к примеру, размещение архивов, копий или контента для интернет-сайтов), как базовое хранилище внутренних долгосрочных архивов и холодных данных, как хранилище резервных копий услуги BaaS (Backup as a Service). Конфигурация BaaS и форматы взаимодействия с объектным хранилищем достойны отдельного рассказа, если интересно — могу рассказать детали.
Текущая конфигурация платформы состоит из восьми серверов хранения Dell R730xd и двух серверов балансировки на базе HAproxy. Серверы имеют следующие характеристики:
- 2 процессора E5-2620 v4 (8 ядер, 2.1 ГГц);
- 128 ГБ ОЗУ;
- адаптер NIC (Ethernet) Intel X520 2 ports 10 Gbps;
- адаптер NIC (Ethernet) Broadcom 5720 4 ports 1 Gbps;
- 12 жёстких дисков SATA 8 Тб;
- 2 диска SSD 480 Гб.

Эта конфигурация позволяет обеспечить до 20 Gbps (на основании нагрузочного тестирования) потока данных и имеет возможность увеличения показателей за счёт масштабирования.
Сейчас есть два основных тарифа, соответствующих вариантам предоставляемого хранилища. Базовые варианты — «Горячий доступ» и «Холодный доступ». Тариф «Горячий доступ» для хранения файлов, к которым предполагается частое обращение, а также большого количества мелких файлов (<500 Кбайт). При выборе данного тарифа для хранения файлов будет использоваться политика хранения «Реплика 3», то есть хранение файлов в трёх копиях. В системе (панели управления услугой) обозначается как R3.
В отличие от предыдущего тарифа, «Холодный доступ», наоборот, предназначен для хранения файлов, к которым не требуется частое обращение. Как правило, это резервные копии. При выборе данных для хранения файлов используется политика хранения «Erasure Coding 5+3», то есть любой файл кодируется на восемь частей на разные серверы, причём для считывания файла достаточно любых пяти частей.
То есть один набор данных хранится в восьми разных местах и любые три из этих мест можно потерять.
При пользовании услугой «Облачное объектное хранилище» оплата может осуществляться по системе Pay as you go — в этом случае оплата осуществляется только за фактически потреблённые ресурсы согласно выбранному тарифу. Другой вариант предоставления услуги — по системе фиксированного объёма. При данной схеме использования пользователю предоставляется строго фиксированный объём дискового пространства, который он оплачивает согласно выбранному тарифу.
Немного о самих ценах:
| Наименование |
Цена за единицу, с НДС, руб./мес. |
|---|---|
| Тариф «Частый доступ» |
|
| Хранение информации, Гб |
1,65 |
| Скачивание информации, за Гб |
2,36 |
| Запросы PUT/POST, пакет по 10 000 шт. |
3,54 |
| Запросы GET/HEAD, пакет по 10 000 шт. |
0,28 |
| Тариф «Редкий доступ» |
|
| Хранение информации, Гб |
1,06 |
| Скачивание информации, за Гб |
7,38 |
| Запросы PUT/POST, пакет по 10 000 шт. |
7,08 |
| Запросы GET/HEAD, пакет по 10 000 шт. |
0,71 |
Важно! В ближайшее время планируется пересмотр тарифной сетки в сторону снижения стоимости.
Наконец мы вплотную подошли к сравнению тарифов Amazon и Техносерв для случая, когда клиент планирует использовать Облачное Хранилище для хранения контента сайта. В данном случае целесообразнее использовать тарифы «Частый доступ» от Техносерв и Стандартное хранилище S3 от Amazon (Восток США, Северная Вирджиния).
| Наименование | Техносерв | Amazon |
|---|---|---|
| Тариф «Частый доступ» | Amazon стандарт | |
| Стоимость хранения 1 Гб информации | 1,65 | 1,45 |
| Стоимость скачивания 1 Гб информации | 2,36 | 5,36 |
| Стоимость пакета запросов put, 10 000 шт. | 3,54 | 3,15 |
| Стоимость пакета запросов get, 10 000 шт. | 0,28 | 0,2 |
| Наименование | Кол-во | Техносерв | Amazon |
| Тариф «Частый доступ» | Amazon стандарт | ||
| Объём хранимой в месяц информации, гб | 100 000 | 165 000 | 144 900 |
| Объём скачиваемой в месяц информации, гб | 40 000 | 94 400 | 214 200 |
| Количество запросов PUT в месяц, шт. | 50 000 000 | 17 700,00 | 15 750,00 |
| Количество запросов GET в месяц, шт. | 40 000 000 | 1 120,00 | 1 008,00 |
| Cтоимость в месяц | 278 220 | 375 858 | |
Важно, что объектная хранилка презентуется не только на облако, но и для предоставления файлов наружу. В частности, это важно, когда нужна толстая труба через Интернет — сейчас через Интернет мы не можем ходить классическими корпоративными протоколами (CIFS или NFS), поскольку это превращается в цепочку гейтов-конвертеров и невероятно замедляется, особенно когда речь идёт про шифрованный VPN. Всё это почти идеально обходится объектными хранилищами. Собственно, в результате мы патчим Интернет — используем объектные протоколы для обмена. Когда нужен классический файловый доступ, можно поставить маленький клиент, который реализует протоколы CIFS или NFS и дальше презентует данные внутри компании.
Конечно, с развитием Интернета ситуация поменяется. Однажды мы поборем пережитки 80-х годов и стандарты, завязанные на ширину крупа лошади, и у нас будет быстрый обмен данными. Уже скоро. Но пока вот такой патч.
Из-за блокировок пострадал очень большой пул адресов Amazon Web Services. Кто-то испытывал только неудобства или нестабильность работы, а кто-то полностью лишался доступа к bussines-critical-системам и нёс финансовые потери. Следствием этой ситуации стали лавинообразный спрос на размещение в российских облаках и возможность использования нативных протоколов (в частности, S3), что позволило проводить миграцию без изменения систем новых заказчиков. Так что оказалось очень полезно иметь нативный S3.
